
Evaluate Clustering Performance Without Ground Truth Labels
Three reliable methods for clustering evaluation.

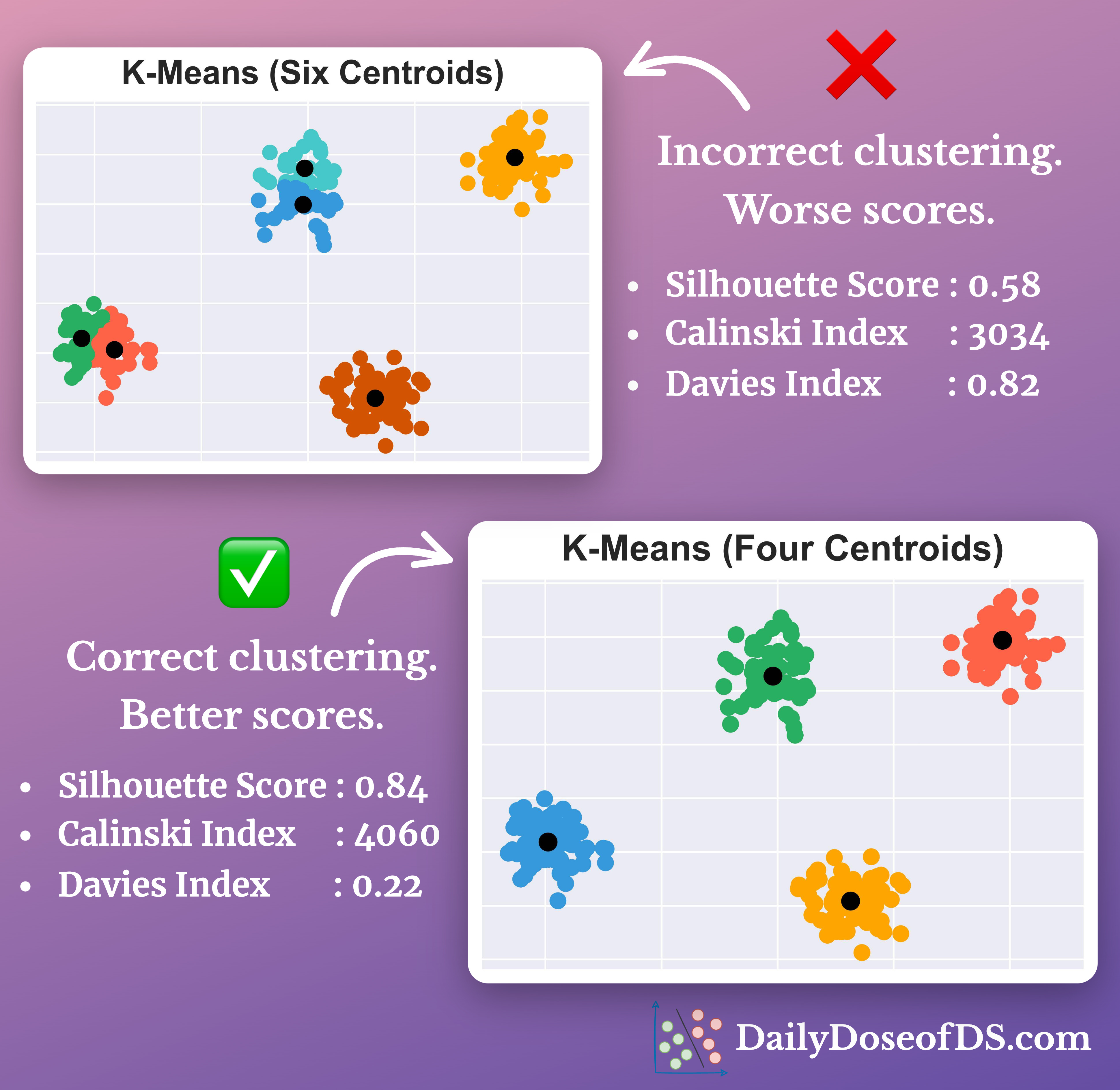
In the absence of ground truth labels, evaluating clustering performance is difficult.
Yet, there are a few performance metrics that can help.
Using them, you can compare multiple clustering results, say, those obtained with a different number of centroids.
This is especially useful for high-dimensional datasets, as visual evaluation is difficult.
Silhoutte Coefficient:
for every point, find average distance to all other points within its cluster (A)
for every point, find average distance to all points in the nearest cluster (B)
score for a point is (B-A)/max(B, A)
compute the average of all individual scores to get the overall clustering score
computed on all samples, thus, it's computationally expensive
a higher score indicates better and well-separated clusters.
I covered this here if you wish to understand Silhoutte Coefficient with diagrams: The Limitations Of Elbow Curve And What You Should Replace It With.
Calinski-Harabasz Index:
A: sum of squared distance between all centroids and overall dataset center
B: sum of squared distance between all points and their specific centroid
metric is computed as A/B (with an additional scaling factor)
relatively faster to compute
it is sensitive to scale
a higher score indicates well-separated clusters
Davies-Bouldin Index:
measures the similarity between clusters
thus, a lower score indicates dissimilarity and better clustering
Luckily, they are neatly integrated with sklearn too.
👉 Over to you: What are some other ways to evaluate clustering performance in such situations?
👉 Read what others are saying about this post on LinkedIn and Twitter.
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
👉 If you love reading this newsletter, feel free to share it with friends!
👉 Sponsor the Daily Dose of Data Science Newsletter. More info here: Sponsorship details.
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.
You have so succinctly summarized what I have been trying to explain for days. Thank you.
Would you please share this on LinkedIn? I want to share it but I want all the credit to go to you.
Superb Guide! :)