
Every LangGraph User We know is Making the Same Mistake!
...covered with a simple solution.

Lightning’s Model APIs now leading the benchmarks on Artificial Analysis

Lightning’s Model APIs let you access open and proprietary models in one multi-cloud platform, optimized for performance and cost.
It is now rated as the top performer by Artificial Analysis. Train, deploy, and scale your models with confidence.
The following visual depicts its quick usage:
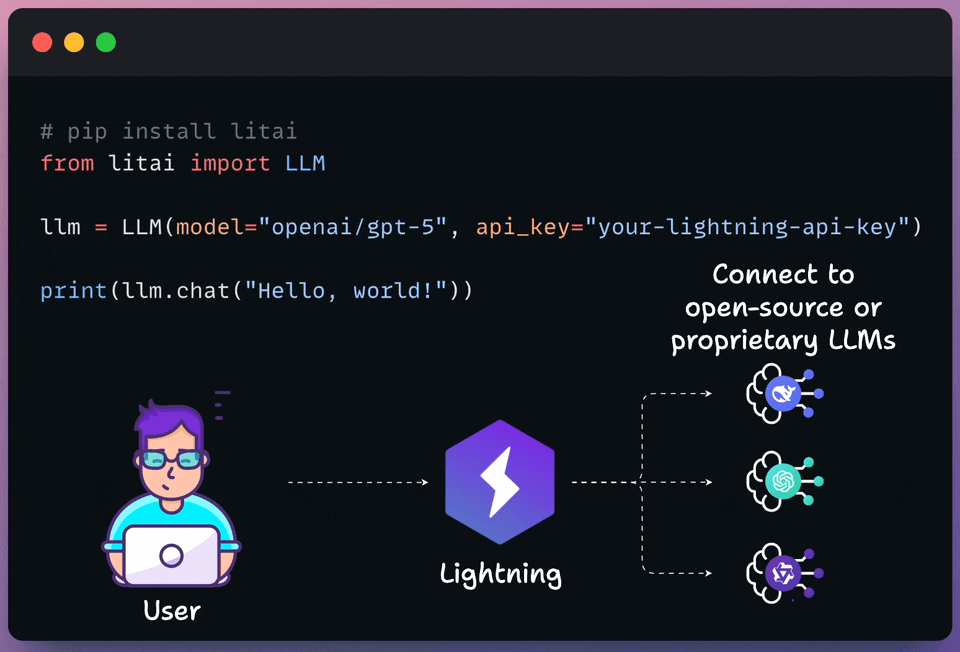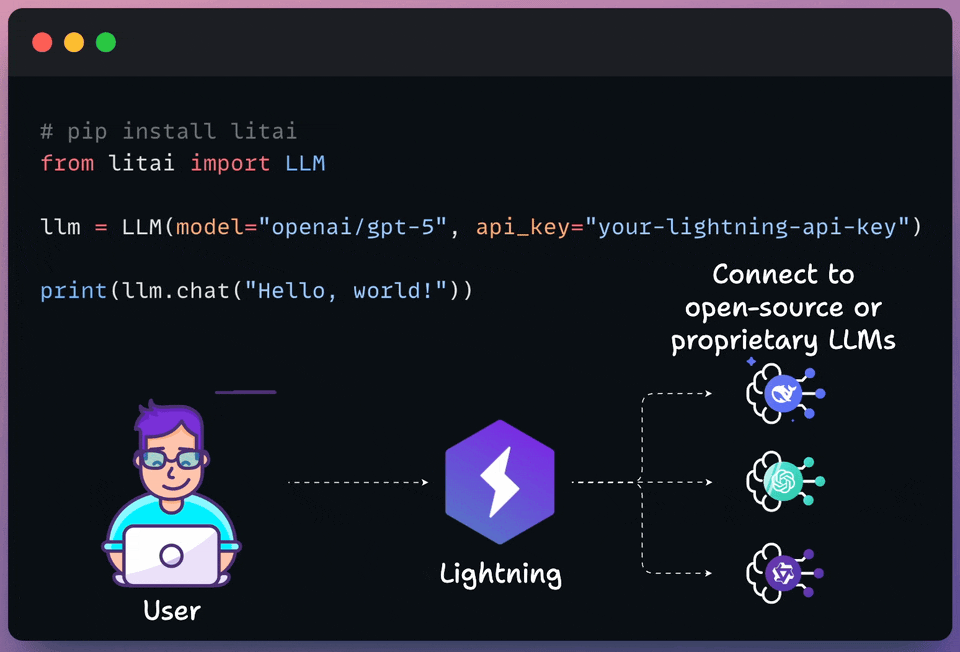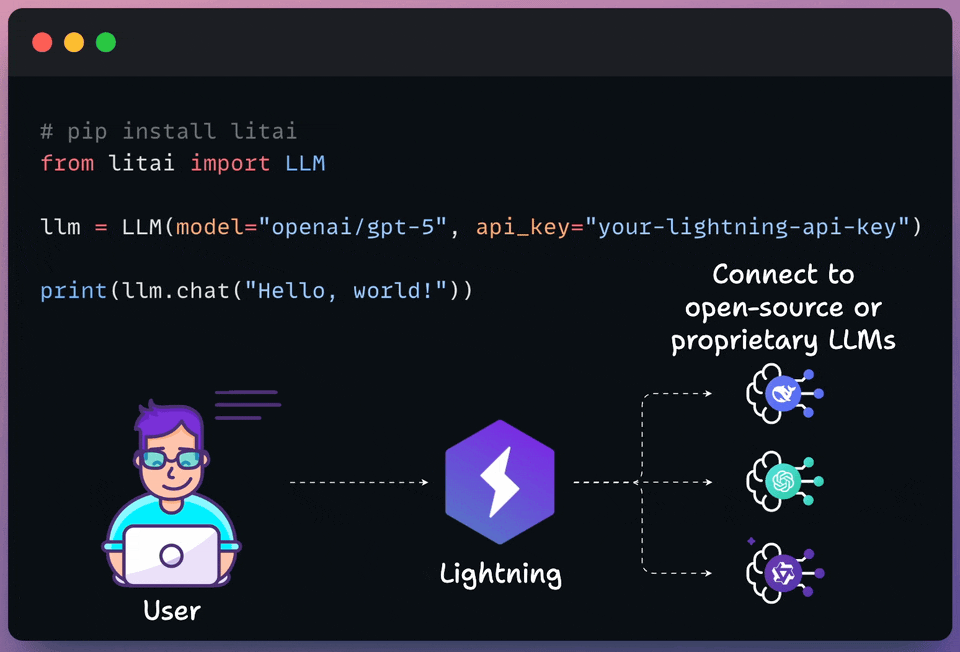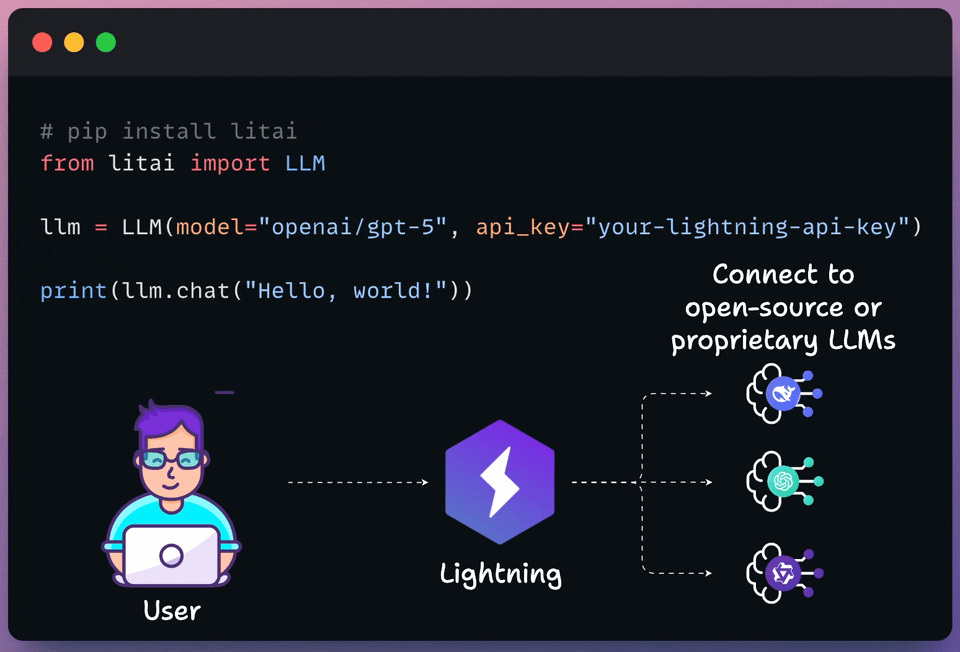
Thanks to Lightning for partnering today!
Every LangGraph user we know is making the same mistake!
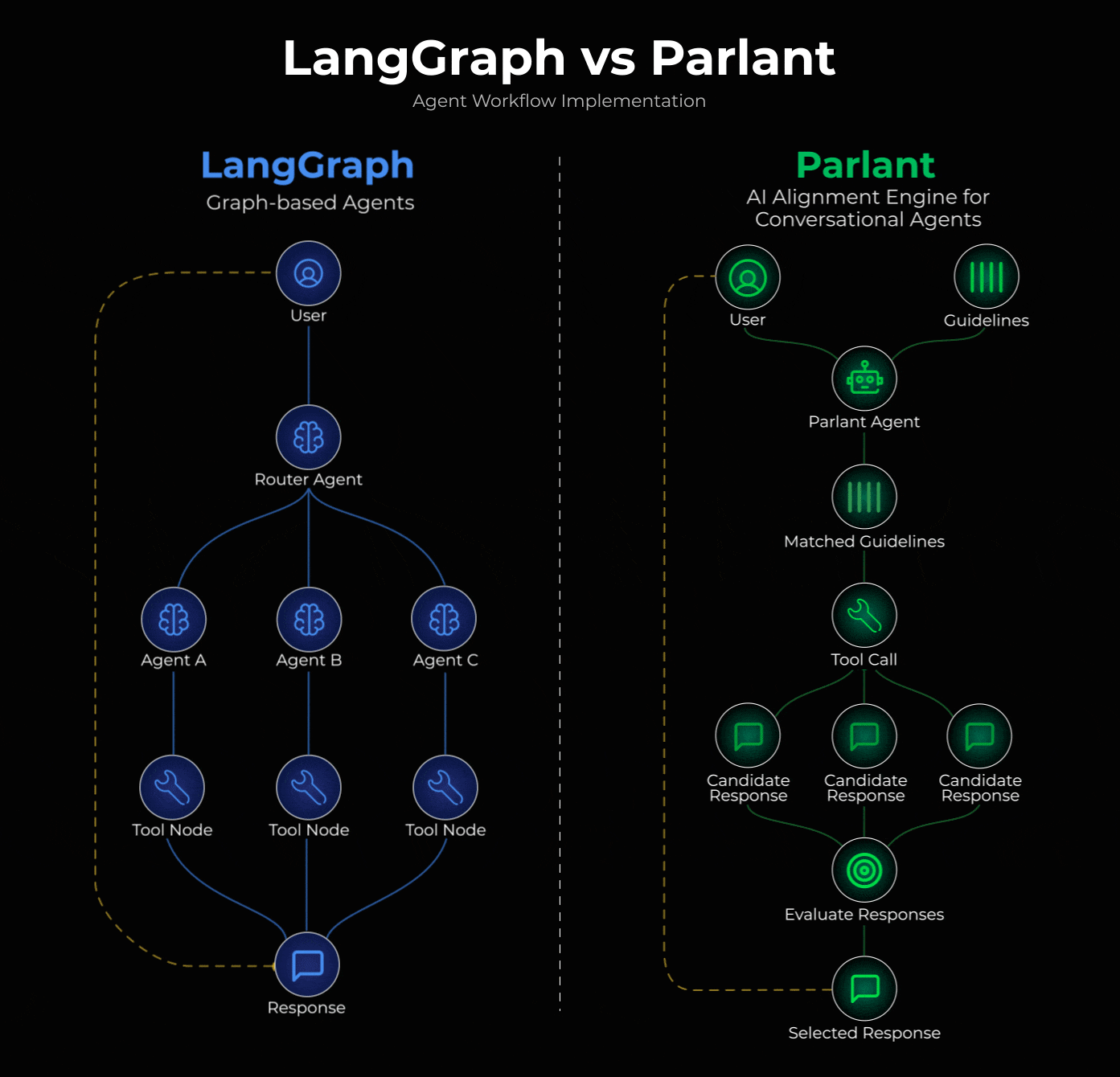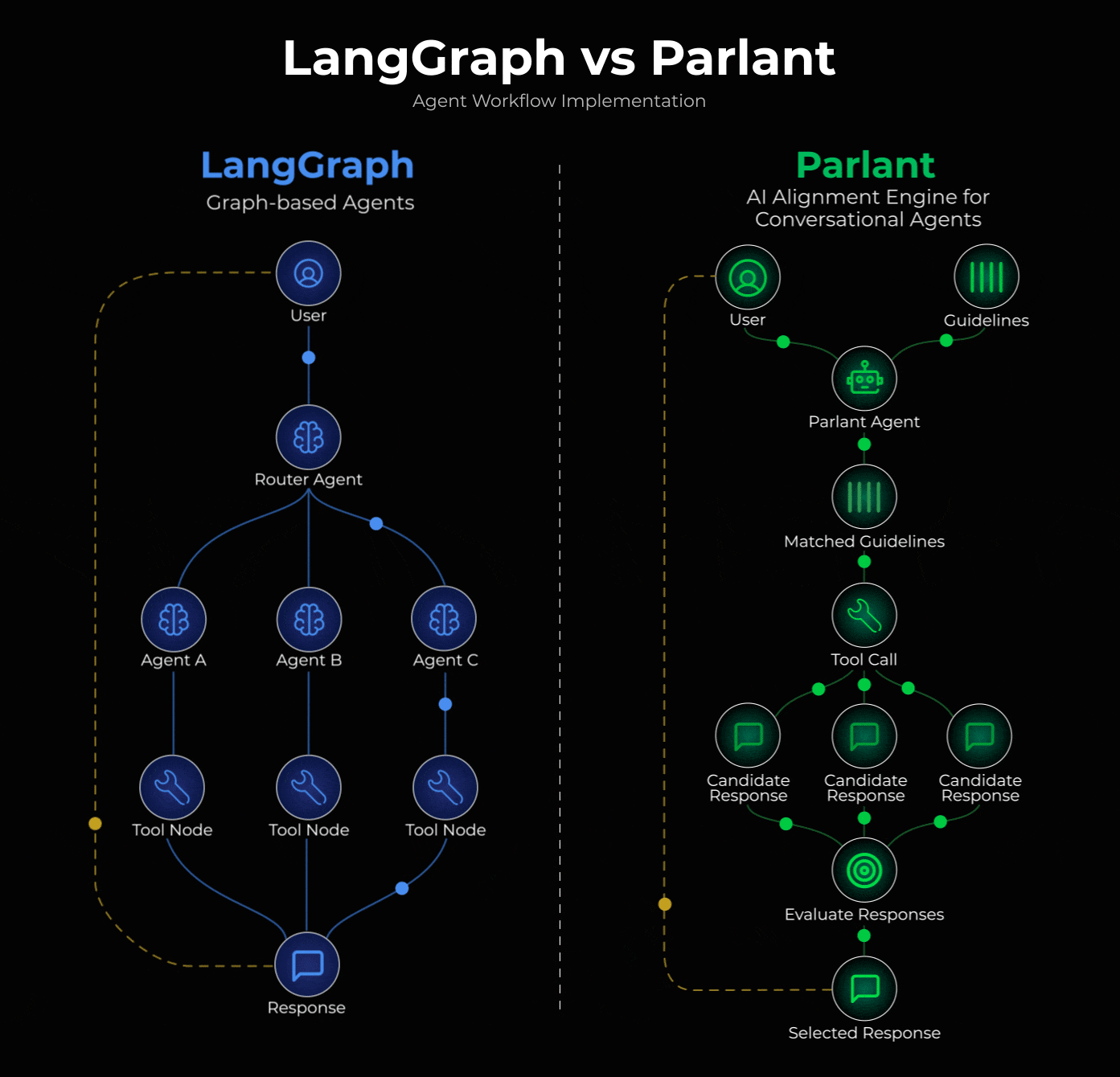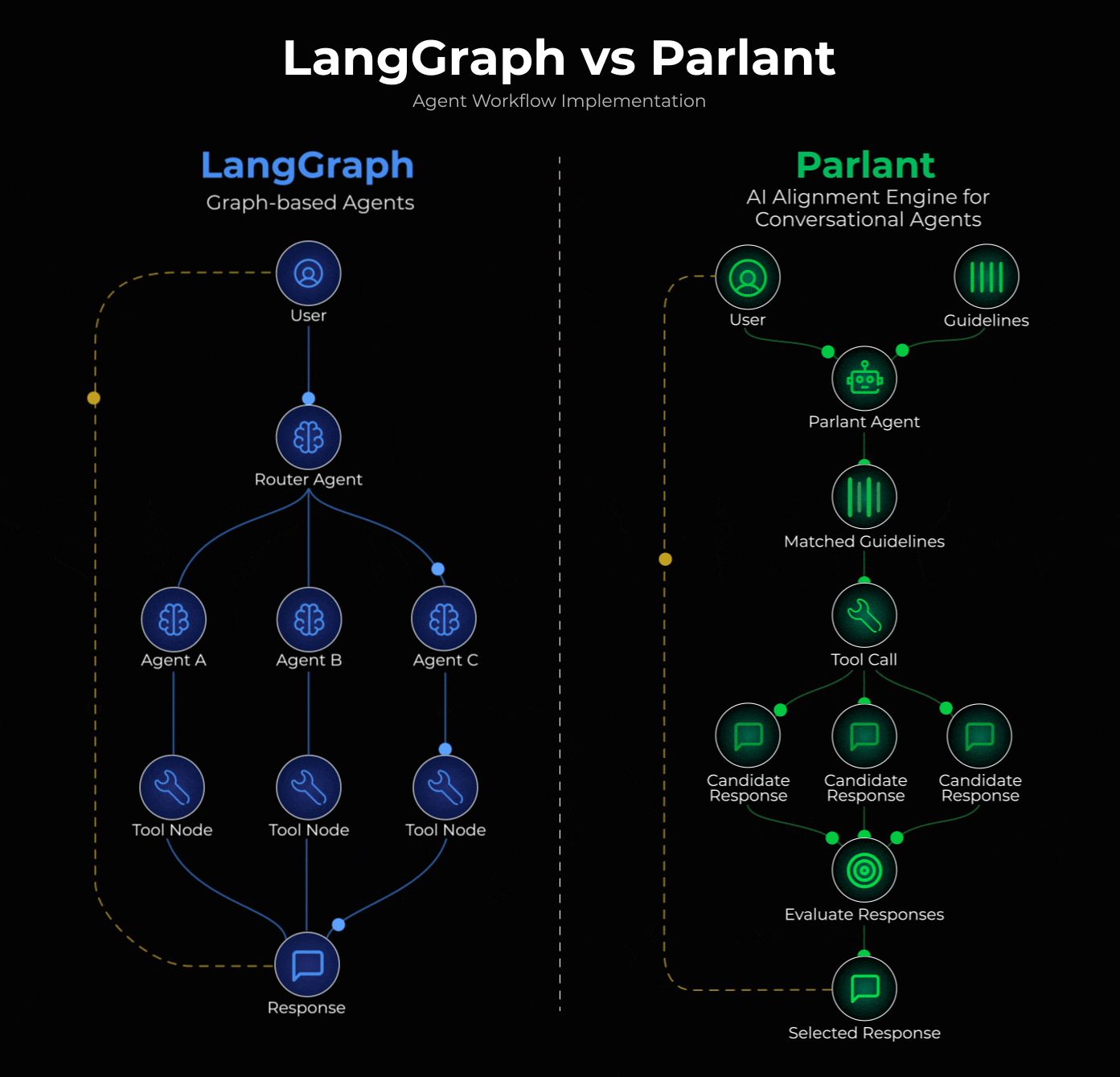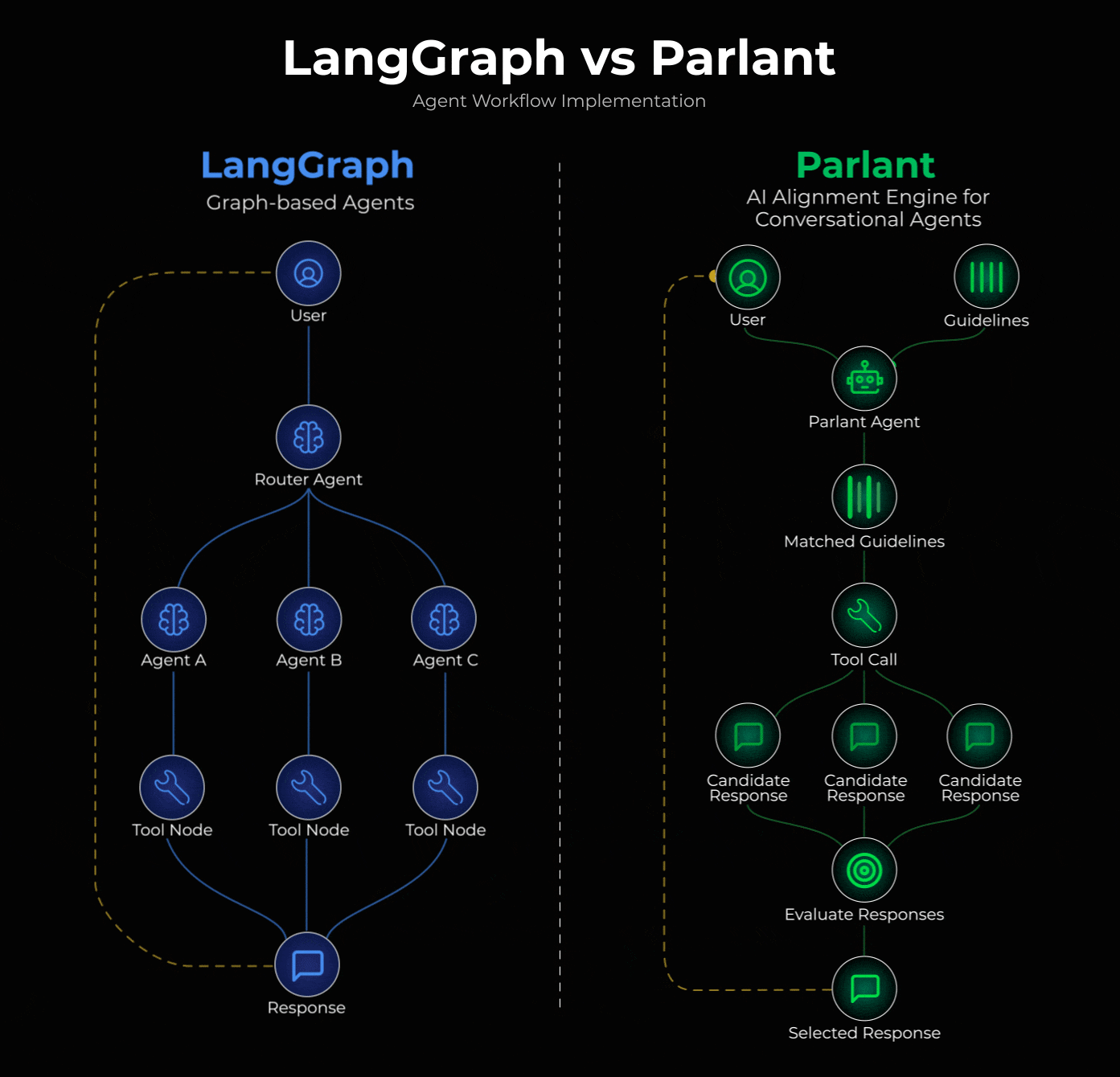
LangGraph users use the popular supervisor pattern to build conversational agents.
The pattern defines a supervisor agent that analyzes incoming queries and routes them to specialized sub-agents. Each sub-agent handles a specific domain (returns, billing, technical support) with its own system prompt.
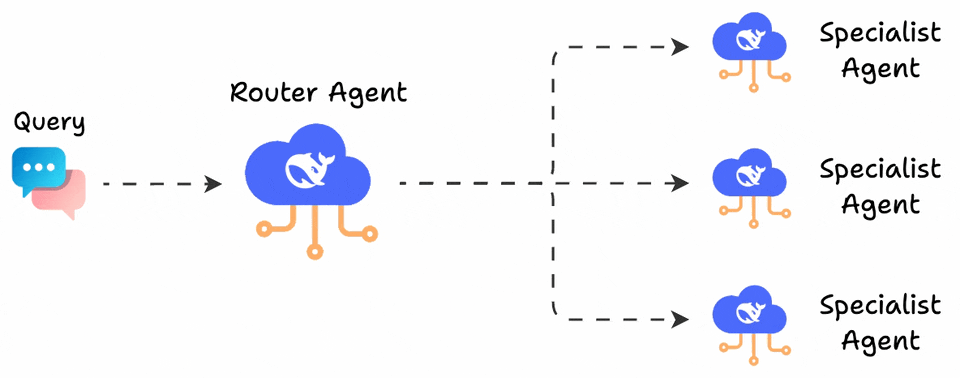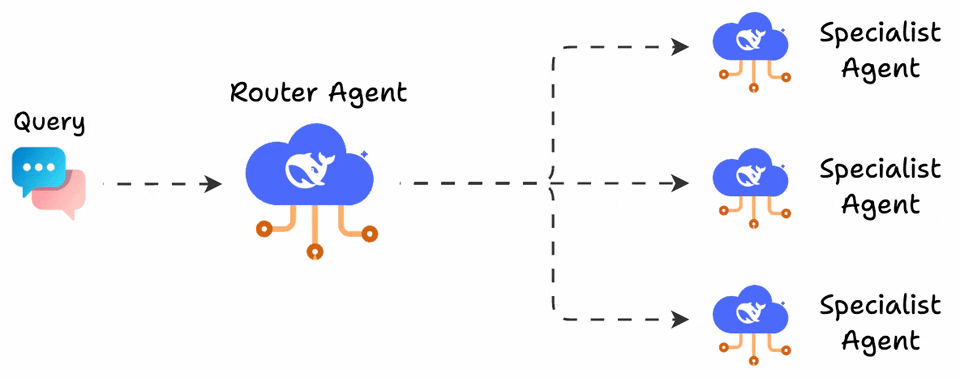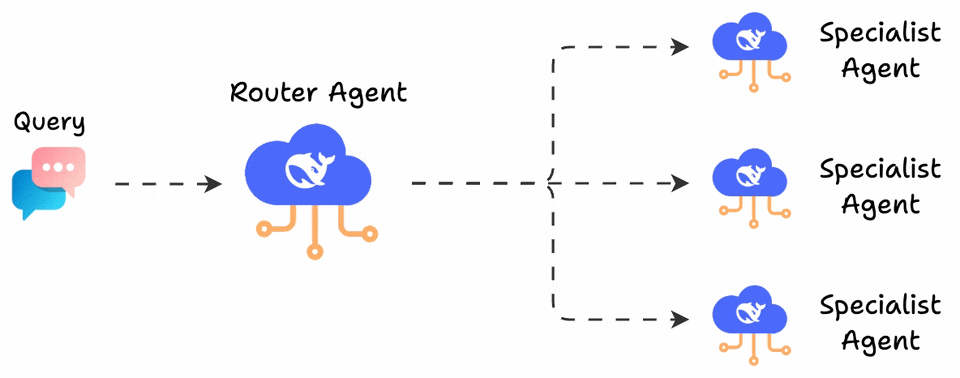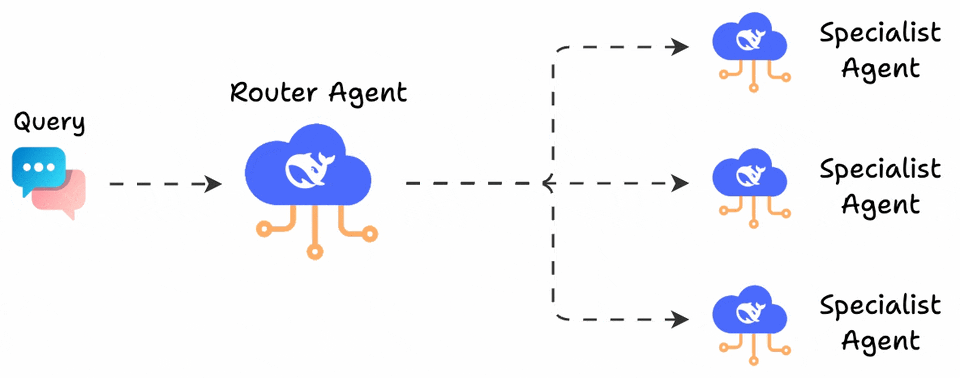
This works beautifully when there’s a clear separation of concerns.
The problem is that it always selects just one route.
For instance, if a customer asks: “I need to return this laptop. Also, what’s your warranty on replacements?”
The supervisor routes this to the Returns Agent, who knows returns perfectly but has no idea about warranties.
So it either ignores the warranty question, admits it can’t help, or even worse, hallucinates an answer. None of these options is desired.
This gets worse as conversations progress because real users don’t think categorically. They mix topics, jump between contexts, and still expect the agent to keep up.
This isn’t a bug you can fix since this is fundamentally how router patterns work.
Now, let’s see how we can solve this problem.
Instead of routing between Agents, first, define some Guidelines.
Think of Guidelines as modular pieces of instructions, like this:
agent.create_guideline(
condition=”Customer asks about refunds”,
action=”Check order status first to see if eligible”,
tools=[check_order_status],
)Each guideline has two parts:
Condition: When it gets activated?
Action: What should the agent do?
Based on the user’s query, relevant guidelines are dynamically loaded into the Agent’s context.
For instance, when a customer asks about returns AND warranties, both guidelines get loaded into context simultaneously, enabling coherent responses across multiple topics without artificial separation.
This approach is actually implemented in Parlant, a recently trending open-source framework (15k+ stars).
Instead of routing between specialized agents, Parlant uses dynamic guideline matching. At each turn, it evaluates ALL your guidelines and loads only the relevant ones, maintaining coherent flow across different topics.
You can see the full implementation and try it yourself.
That said, LangGraph and Parlant are not competitors.
LangGraph is excellent for workflow automation where you need precise control over execution flow. Parlant is designed for free-form conversation where users don’t follow scripts.
The best part? They work together beautifully. LangGraph can handle complex retrieval workflows inside Parlant tools, giving you conversational coherence from Parlant and powerful orchestration from LangGraph.
You can find the GitHub repo here →
If you think we can do the same in LangGraph…
Yes, you can implement similar flows in LangGraph, but you need to understand the costs associated and the engineering effort required to do so.
Firstly, dynamic guideline matching ≠ intent routing.
Routing “returns” vs “warranty” is intent classification.
Guideline matching needs a scoring and conflict-resolution engine that can evaluate multiple conditions per turn, distinguish continuous vs one-time actions, handle partial fulfillment and re-application, and weigh conflicting rules based on priorities and scope of the conversation.
So you’ll have to design schemas, thresholds, and lifecycle rules, not just edges between nodes.
Secondly, verification and revision loops are essential (especially in high-stakes environments).
If you want consistent behavior, you’d need to add a structured self-check: “Did I break any high-priority rules? Are all facts sourced from the allowed context?”
That implies a JSON-logged revision cycle, not just a single LLM call per node.
Thirdly, token budgeting is another problem.
Loading all relevant instructions is easy to say and hard to do without blowing context. You’ll need ordering policies (recency > global), deduplication, summarization, slot-filling, and hard budgets per turn so the model stays focused and costs/latency remain predictable.
Lastly, the reasoning technique used by Parlant (called ARQ) is precisely built to get precise control over Agents.
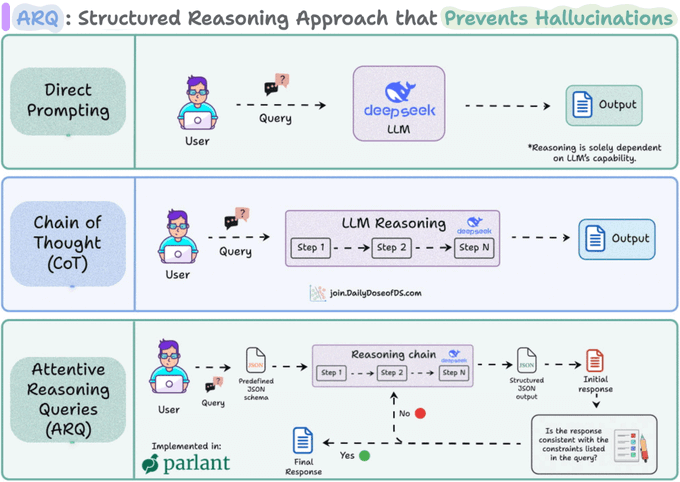
In a gist, instead of letting LLMs reason freely, ARQs guide the Agent through explicit, domain-specific questions. For instance, before it makes a recommendation or decides on a tool call, the LLM is prompted to fill structured keys like:
{
“current_context”: “Customer asking about refund eligibility”,
“active_guideline”: “Always verify order before issuing refund”,
“action_taken_before”: false,
“requires_tool”: true,
“next_step”: “Run check_order_status()”
}This helps reinstate critical instructions by keeping the LLM aligned mid-conversation and avoiding hallucinations. So by the time the LLM generates the final response, it’s already walked through a sequence of controlled reasoning steps, without doing any free-form reasoning that happens in techniques like CoT or ToT.
If your interaction is narrow, guided, or truly workflow-like, LangGraph alone is ideal. If your interaction is open-ended, multi-topic, and compliance-sensitive, you’ll end up re-implementing a large portion of the above to keep conversations coherent.

You can see the full implementation on GitHub and try it yourself.
You can find the GitHub repo here →
Thanks for reading!