
Evolution of Agent Landscape From 2022-26
From weights → context → harness engineering.

Verify AI-generated code before it blocks your PR
AI agents write code without knowing your dependency graph, quality profiles, or security rules. So when something goes wrong, CI catches it minutes later.
SonarQube Agentic Analysis moves that verification into the agent's inner loop.
During a regular CI run, SonarQube stores full project context, like dependencies, compiled artifacts, type information, and build configuration.
When the agent writes a file, it invokes SonarQube Agentic Analysis mid-workflow.
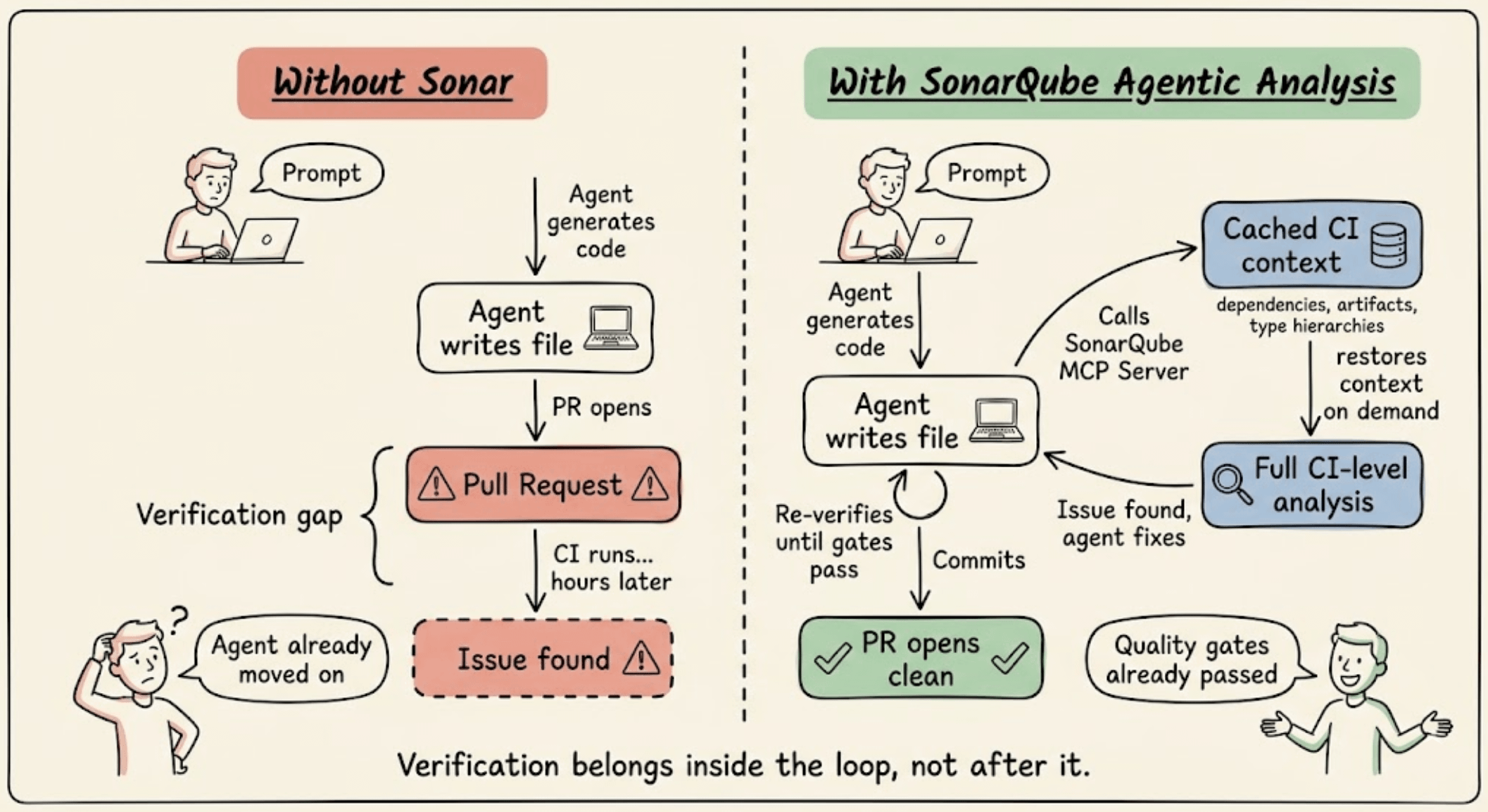
The engine restores that cached context, applies your team's quality profiles and security rules, and runs the same analysis your pipeline uses. Same precision as a full CI scan, in seconds.
The agent generates, verifies, fixes, re-verifies, and commits. PRs that pass quality gates the first time, without the back and forth.
Compatible with Claude Code, Cursor, Codex, Gemini CLI, and VS Code with Copilot. Direct API available for automated pipelines.
Core analysis is free during the beta period with a SonarQube Cloud Teams or Enterprise plan.
Get started with SonarQube Agentic Analysis here →
Thanks to Sonar for partnering today!
Evolution of Agent Landscape From 2022-26
The biggest shift in AI agents hasn’t been about making models smarter.
They do have their part but it has been more about making the environment around them smarter.
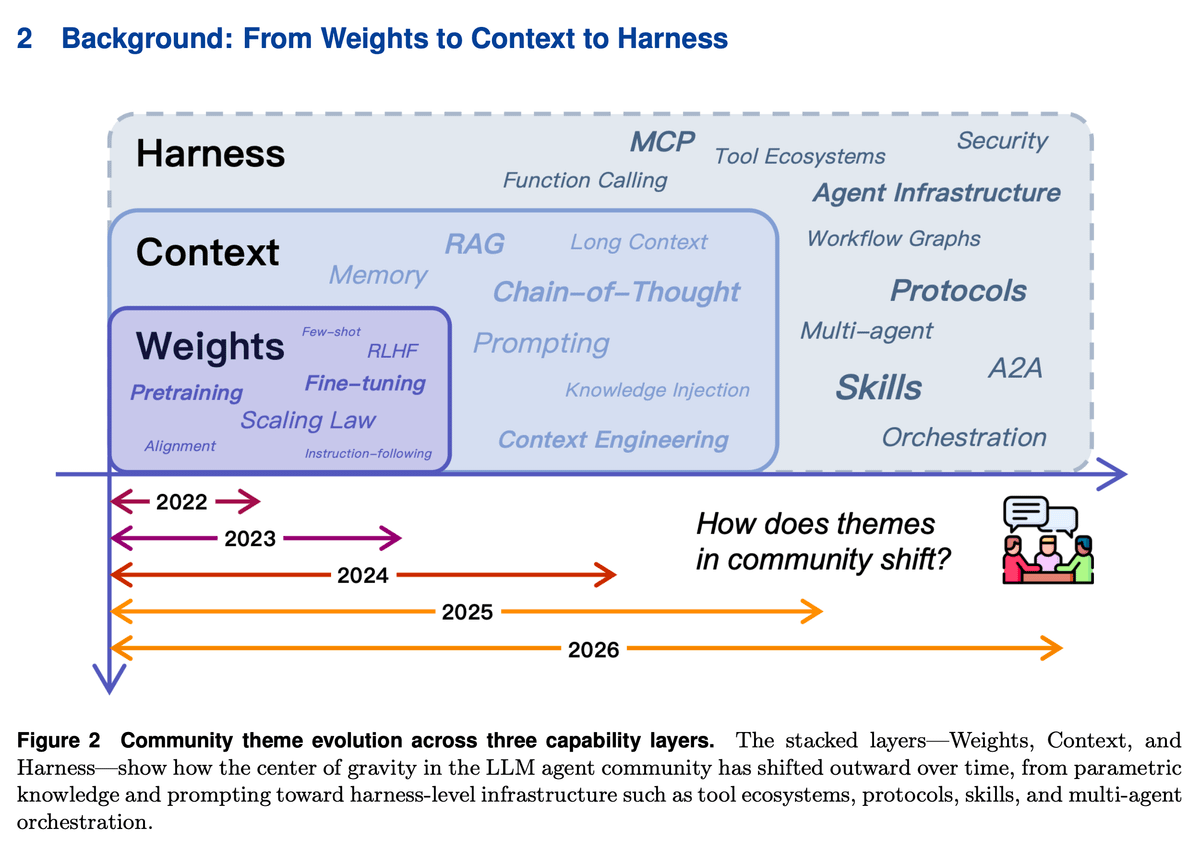
Here’s how agent engineering evolved in just 4 years, across three distinct phases:
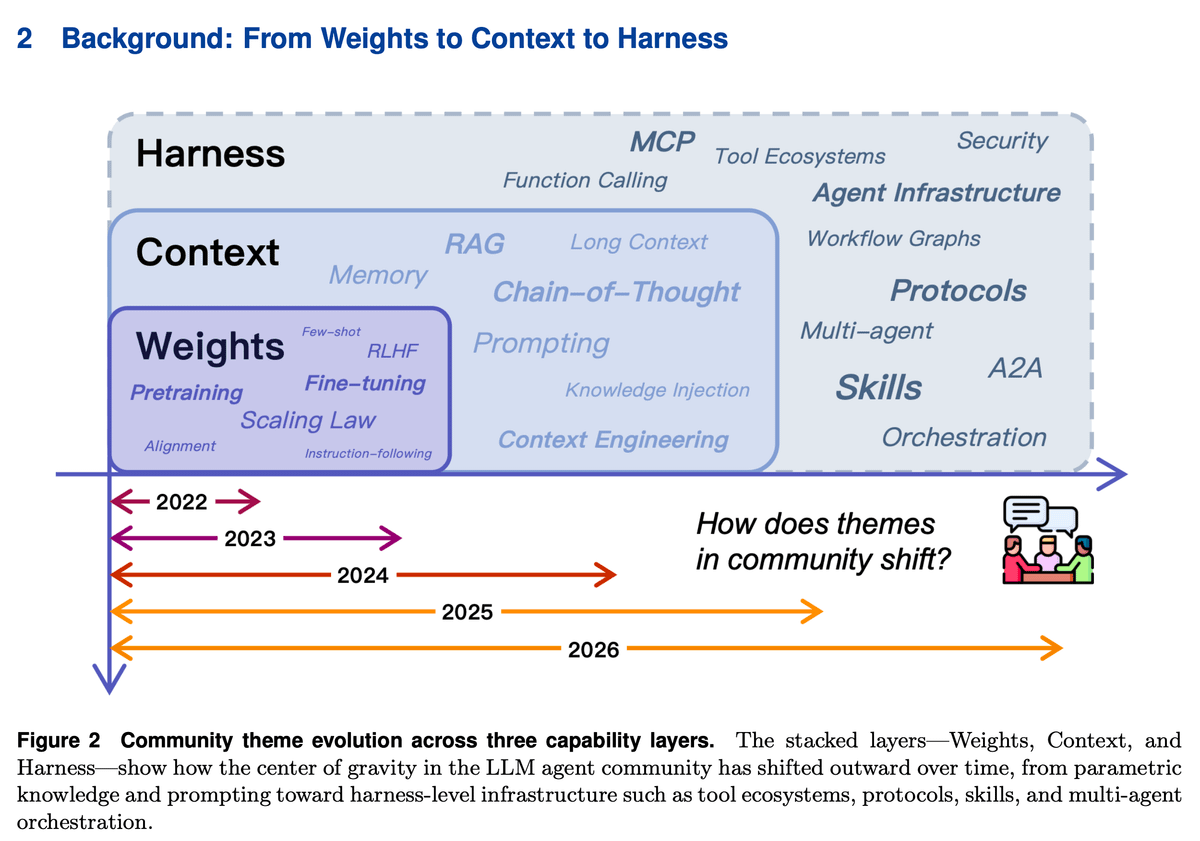
Phase 1: weights (2022)
Everything was about the model itself. Bigger models, more data, better training. Scaling laws suggested that progress will come from more parameters.
RLHF and fine-tuning shaped behavior in this phase.
If you wanted a better agent, you trained a better model. This worked great for single-turn tasks.
But it hit a wall fast. Updating one fact meant retraining. Auditing behavior was nearly impossible. And personalization across millions of users from one frozen set of weights didn’t happen.
Phase 2: context (2023-2024)
A key realization that happened in this phase was that you don’t always need to change the model.
You can change what the model sees.
Prompt engineering, few-shot examples, chain-of-thought, and RAG led the way here.
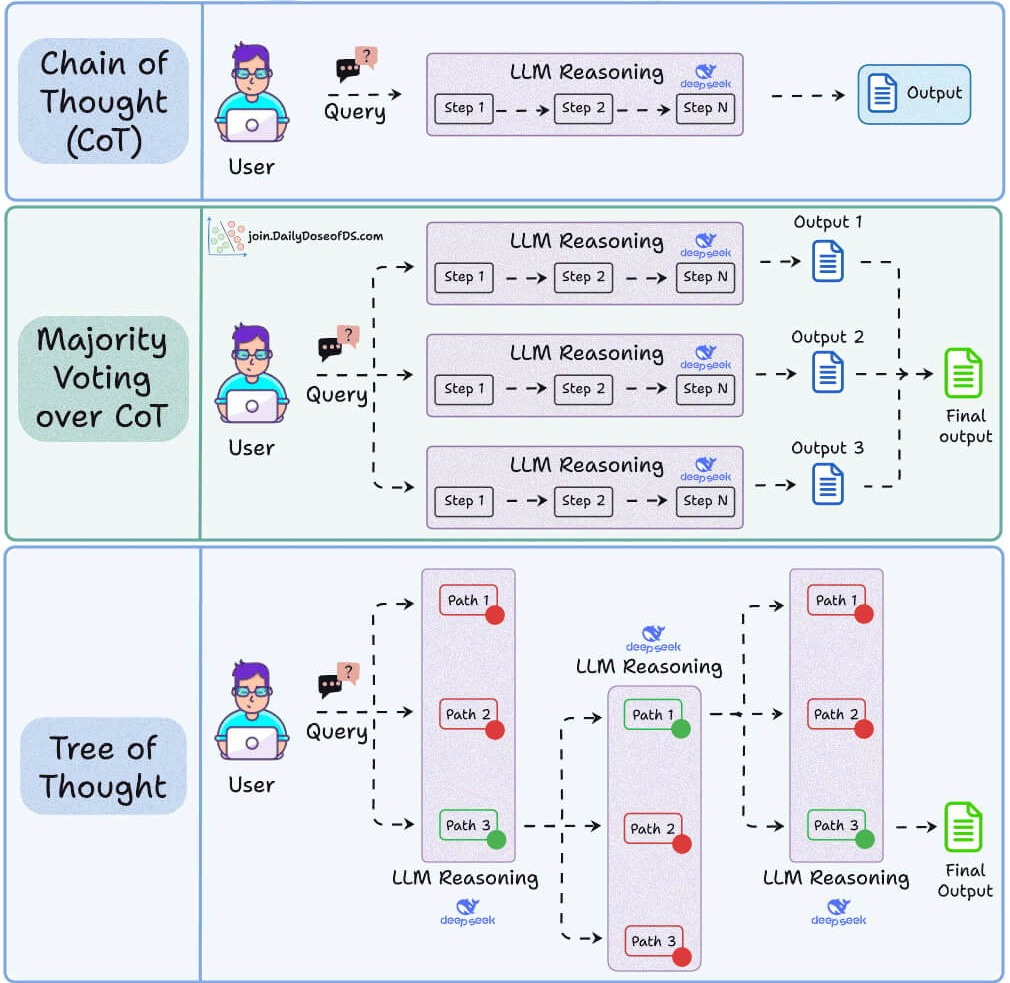
Suddenly, the same frozen model could behave completely differently based on what you put in front of it.
Developers stopped fine-tuning and started iterating on prompts and retrieval pipelines instead. It was cheaper, faster, and surprisingly effective.
But context windows are finite. Long prompts get noisy. Models attend unevenly (the “lost in the middle” problem is real).
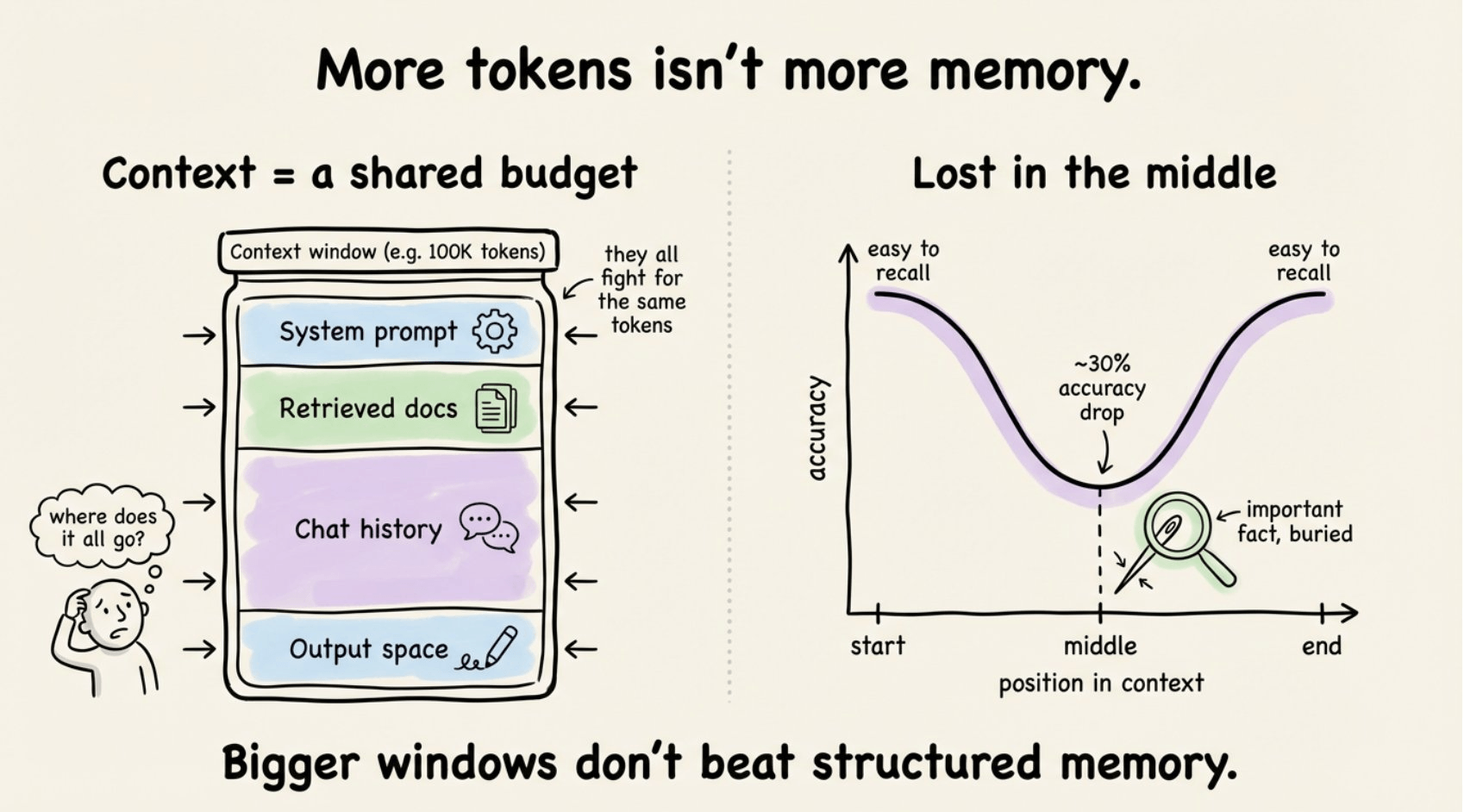
And every new session starts fresh with zero memory of what happened before.
Context made agents flexible. It didn’t make them reliable.
Phase 3: Harness engineering (2025-2026)
This is where we are now.
The question changed from “what should we tell the model?” to “what environment should the model operate in?”
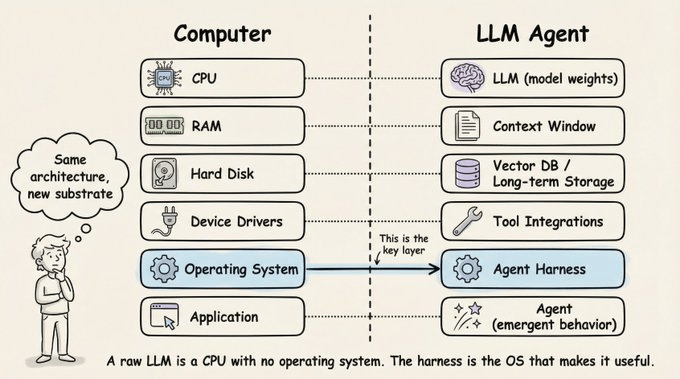
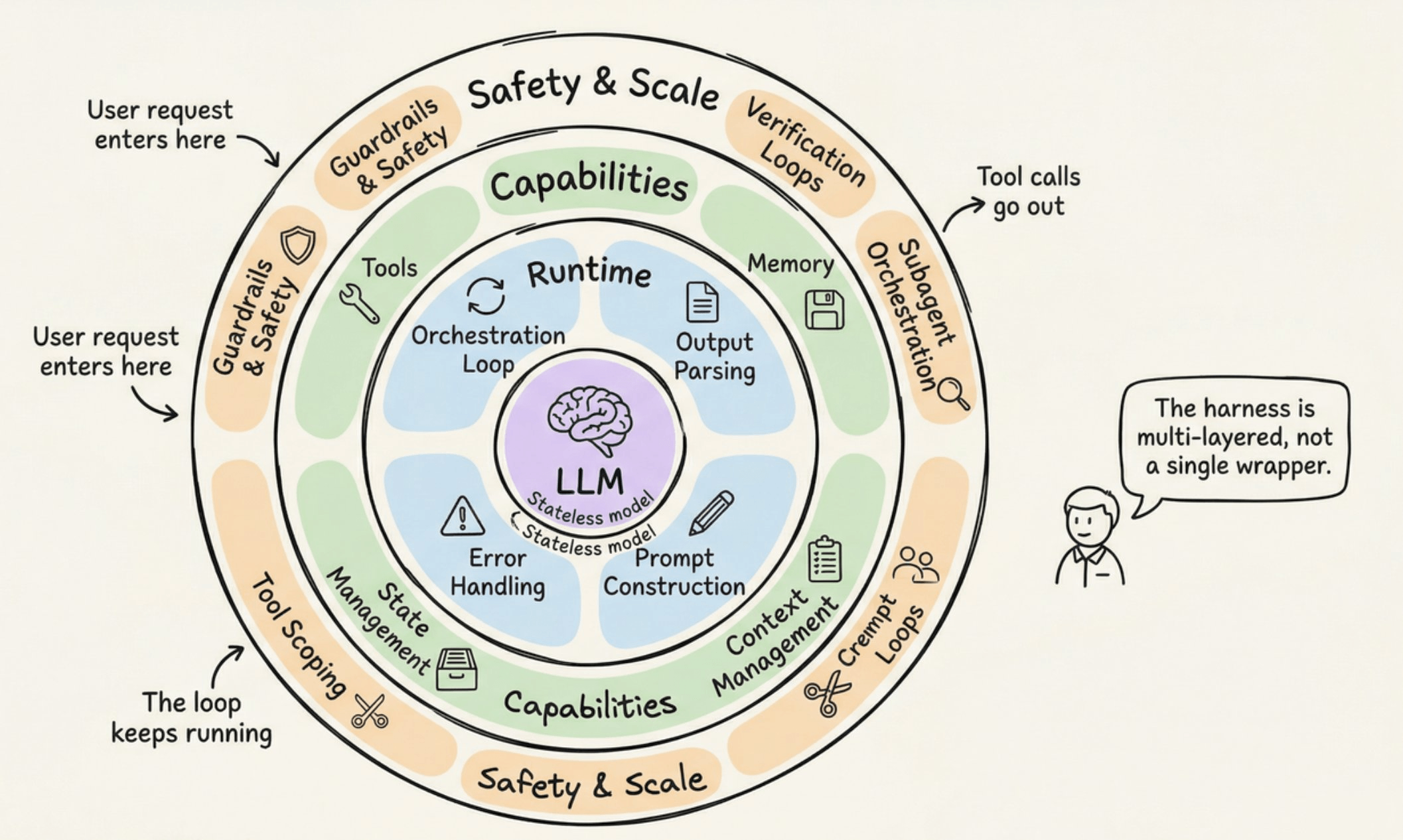
The model is no longer the sole location of intelligence. It sits inside a harness that includes persistent memory, reusable skills, standardized protocols (like MCP and A2A), execution sandboxes, approval gates, and observability layers.
The model stays the same. What changes is the task it’s being asked to solve.
An example could be a coding agent asked to implement a feature, run tests, and open a PR.
Without a harness, the model must keep repo structure, project conventions, workflow state, and tool interactions all inside a fragile prompt.
With a harness, persistent memory supplies context, skill files encode conventions, protocolized interfaces enforce correct schemas, and the runtime sequences steps and handles failures.
So you have the same model but completely different reliability.
The pattern across all three phases is simple:
weights encoded knowledge in parameters (fast but rigid)
context staged knowledge in prompts (flexible but ephemeral)
harnesses externalized knowledge into persistent infrastructure (reliable and governable)
Each phase didn’t replace the previous one but rather built on top of what existed.
Weights still matter and so does context engineering. But the center of gravity has moved outward.
The most consequential improvements in agent reliability today rarely come from changing the base model.
They come from better memory retrieval, sharper skill loading, tighter execution governance, and smarter context budget management.
Building better agents increasingly means building better environments for models to operate in.
There’s a great paper on this titled Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering.
We also published this deep dive (article) on agent harness engineering, covering the orchestration loop, tools, memory, context management, and everything else that transforms a stateless LLM into a capable agent.
You can read the Agent Harness article here →
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.