
Extending the Context Length of LLMs
Key techniques, explained in simple terms.

Important announcement (in case you missed it)
We have started sending the newsletter through our new platform.
Switch for free here: https://switch.dailydoseofds.com.
You will receive an email to confirm your account.

Due to deliverability concerns, we can’t move everyone ourselves in one go, so this transition will be slow. But you can join yourself to avoid waiting.
To upgrade your reading experience, please join below:
Let’s get to today’s post now!
Extend the context length of LLMs
Consider this:
GPT-3.5-turbo had a context window of 4,096 tokens.
Later, GPT-4 took that to 8,192 tokens.
Claude 2 reached 100,000 tokens.
Llama 3.1 → 128,000 tokens.
Gemini → 1M+ tokens.
We have been making great progress in extending the context window of LLMs.
Today, let's understand some techniques that help us unlock this.
What's the challenge?
In a traditional transformer, a model processing 4,096 tokens requires 64 times more computation (quadratic growth) than one handling 512 tokens due to the attention mechanism.
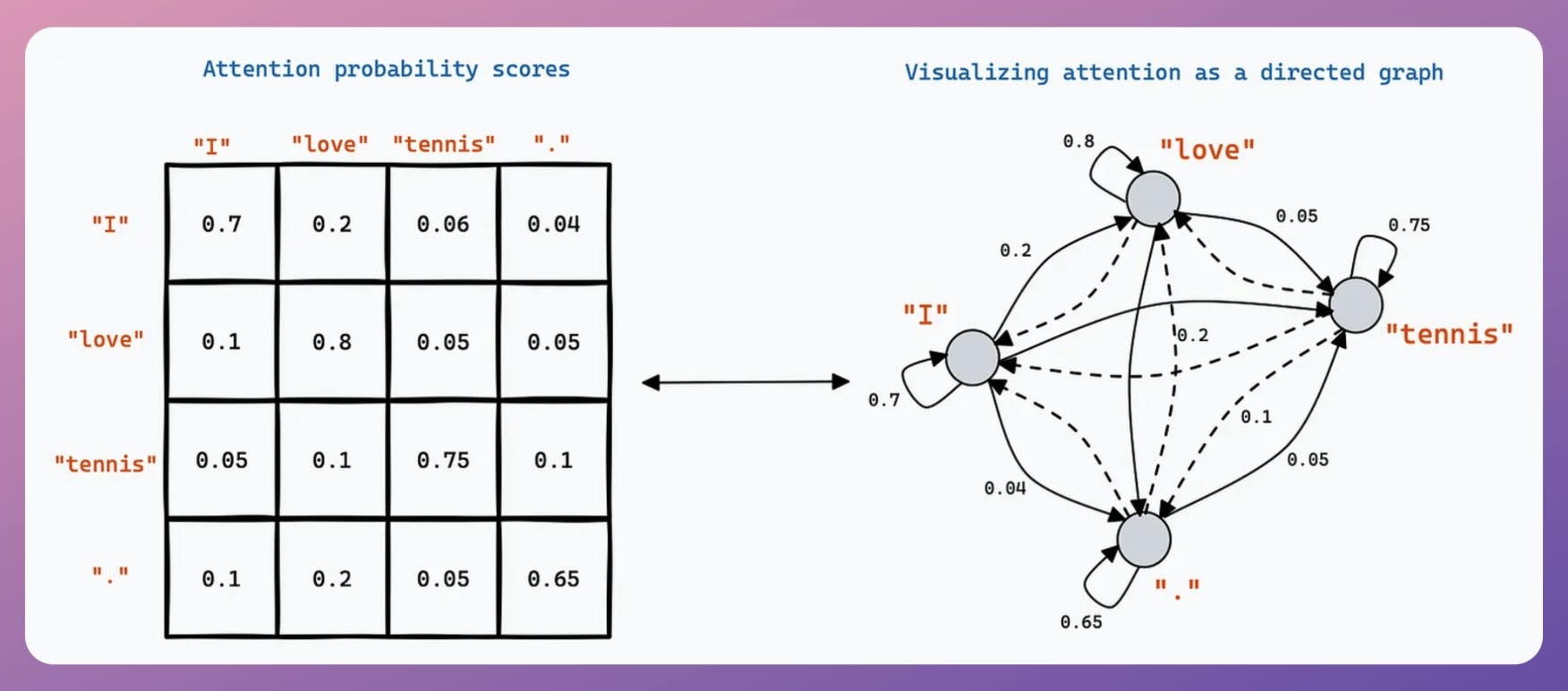
Thus, having a longer context window isn't just as easy as increasing the size of the matrices, if you will.
But at least we have narrowed down the bottleneck.
If we can optimize this quadratic complexity, we have optimized the network.
A quick note: This bottleneck was already known way back in 2017 when transformers were introduced. Since GPT-3, most LLMs have utilized non-quadratic approaches for attention computation.
1) Approximate attention using Sparse Attention
Instead of computing attention scores between all pairs of tokens, sparse attention limits that to a subset of tokens, which will reduce the computations.
There are two common ways:
Use local attention, where tokens attend only to their neighbors.
Let the model learn which tokens to focus on.
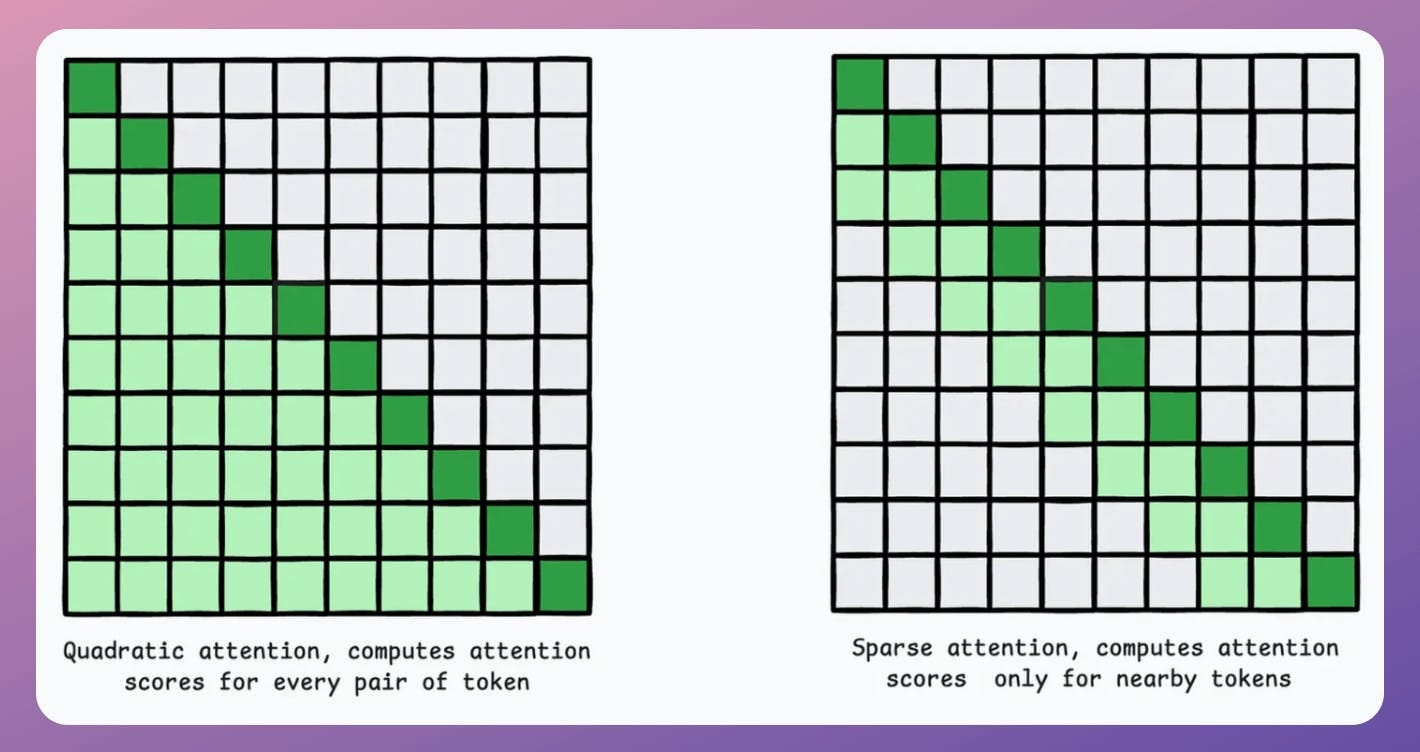
As you may have guessed, there's a trade-off between computational complexity and performance.
2) Flash Attention
This is a fast and memory-efficient method that retains the exactness of traditional attention mechanisms.
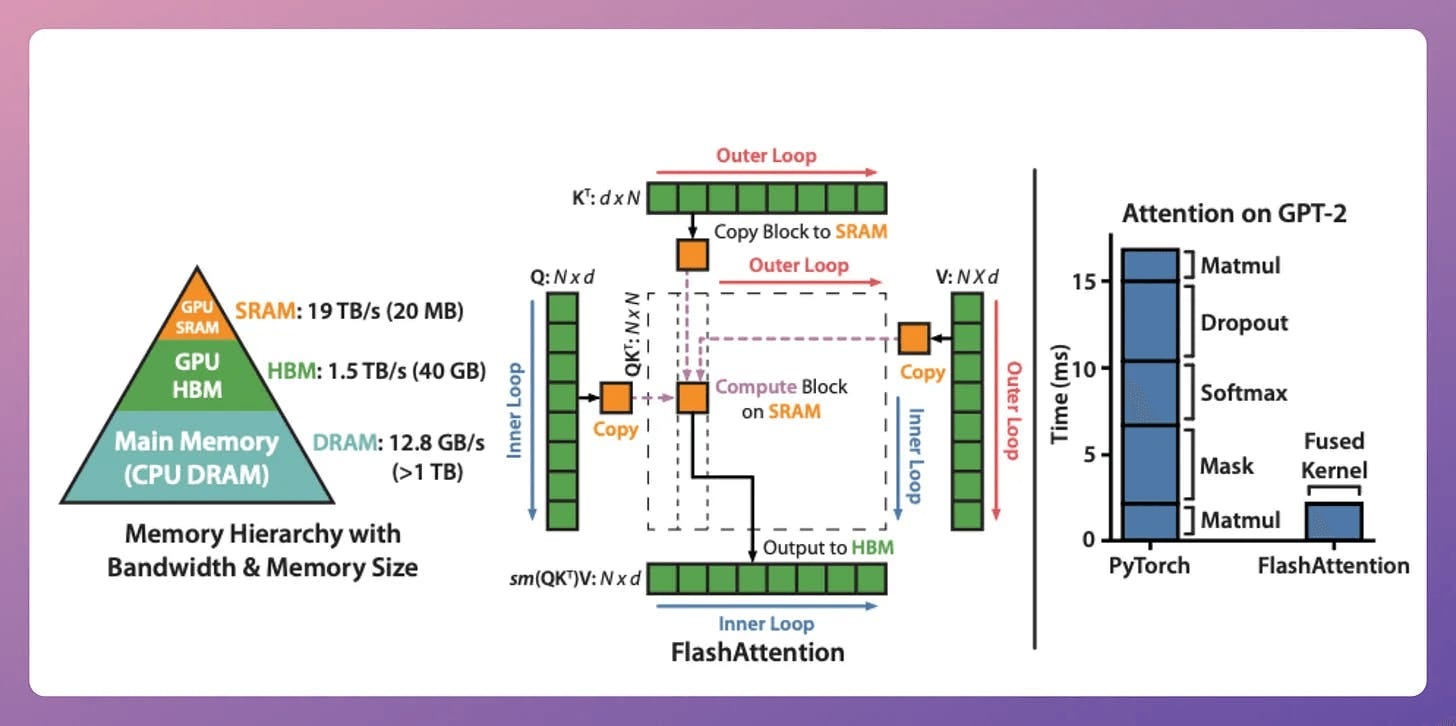
The whole idea revolves around optimizing the data movement within GPU memory. Here are some background details and how it works.
In a GPU:
A thread is the smallest unit of execution.
A group of threads is called a block.
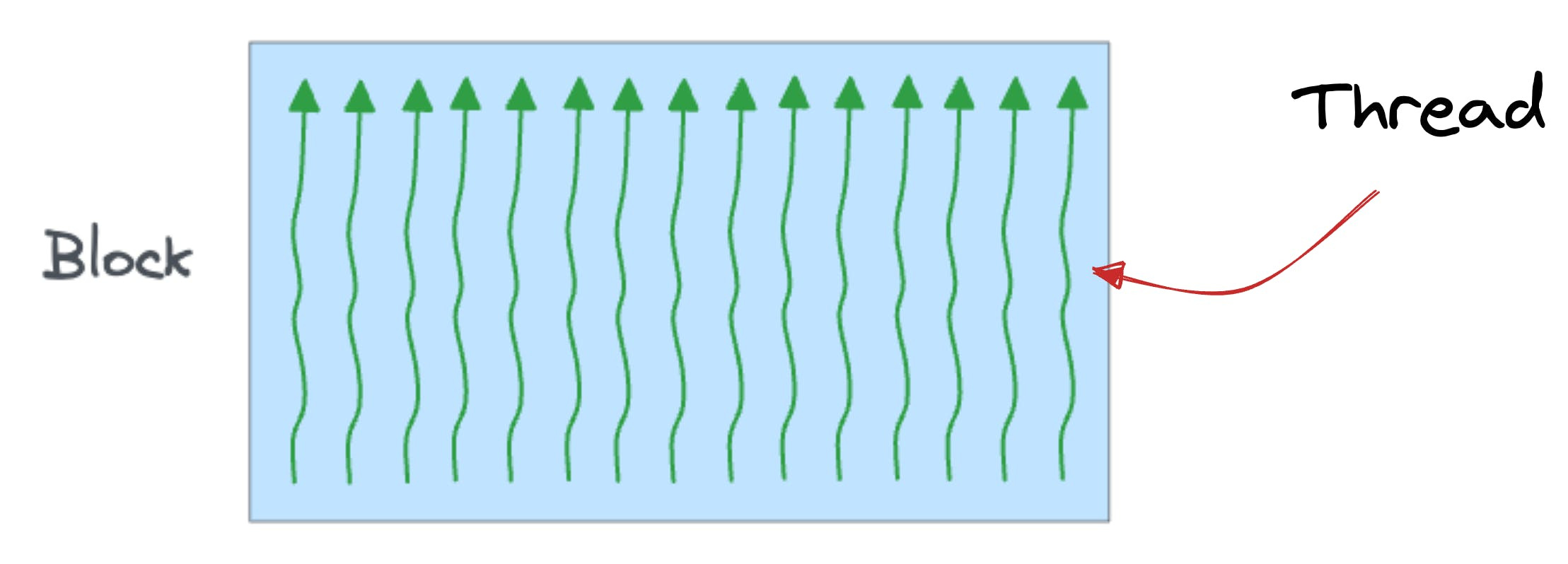
Also:
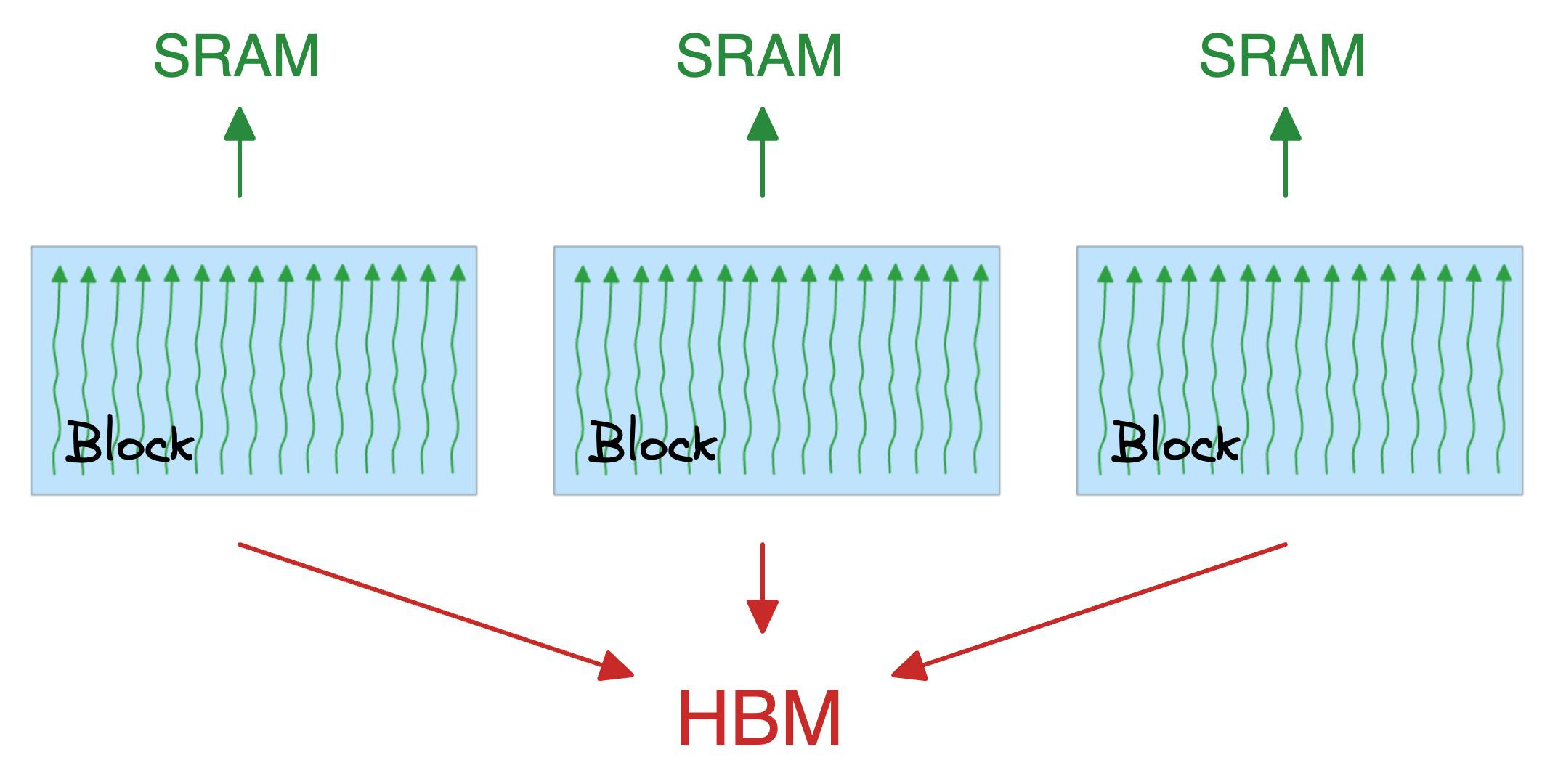
A block executes the same kernel (function, to simplify) and its threads cooperate by sharing a fast memory block called SRAM.
Also, all blocks together can access a shared global memory block in the GPU called HBM.
A note about SRAM and HBM:
SRAM is scarce but extremely fast.
HBM is much more abundant but slow (typically 8-15x slower).
The quadratic attention and typical optimizations involve plenty of movement of large matrices between SRAM and HBM:

First, the product of query (Q) and key (K) is distributed to threads, computed, and brought back to HBM.
Next, the above result is again distributed to threads to compute the softmax of the product and brought back to HBM once it is done.
Flash attention reduces the repeated movements by utilizing SRAM to cache the intermediate results.
This way, redundant movements are reduced, and typically, this offers a speed up of up to 7.6x over standard attention methods.
Also, it scales linearly with sequence length, which is also great.
While reducing the computational complexity is crucial, this is not sufficient.
See, using the above optimization, we have made it practically feasible to pass longer contexts without drastically increasing the computation cost.
However, the model must know how to comprehend longer contexts and the relative position of tokens.
That is why selecting the right positional embeddings is crucial.

Rotary positional embeddings (RoPE) usually work the best since they preserve both the relative position and the relation.
If you want to learn more about RoPE, let us know. We can cover it in another issue.
In the meantime, if you want to get into the internals of CUDA GPU programming and understand the internals of GPU, how it works, and learn how CUDA programs are built, we covered it here: Implementing (Massively) Parallelized CUDA Programs From Scratch Using CUDA Programming.
👉 Over to you: What are some other ways to extend the context length of LLMs?
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 110k+ data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
great read .. Would love to know more about Rotary positional embeddings (RoPE).