
Faster Neighbor Search Using Inverted File Index
...actively used in vector DBs.

Search and scrape web results in an LLM-ready format
Firecrawl’s latest /search endpoint provides Agents the simplest way to discover the web.
You can search the web and scrape all results in an LLM-ready format with just one API call. Here’s the code:

The endpoint is live on API, MCP, and all other integrations like n8n, Zapier, etc!
Start searching the web here →
Thanks to Firecrawl for partnering today!
ANN search using inverted file index
kNN performs an exhaustive search, which is inefficient at scale!
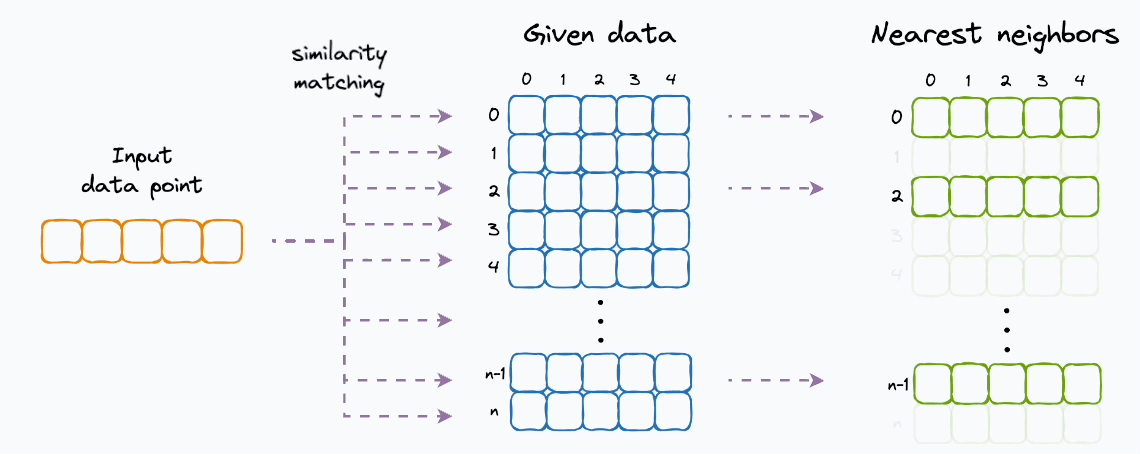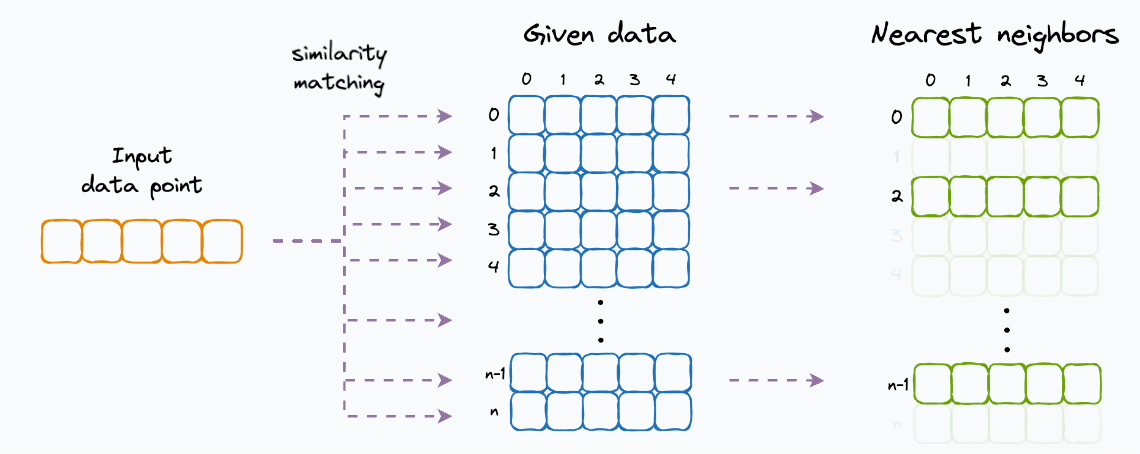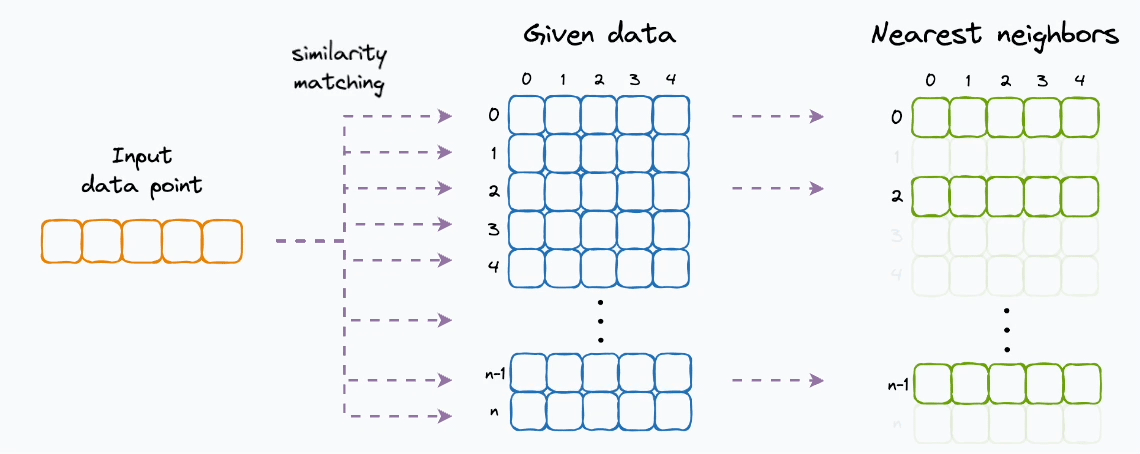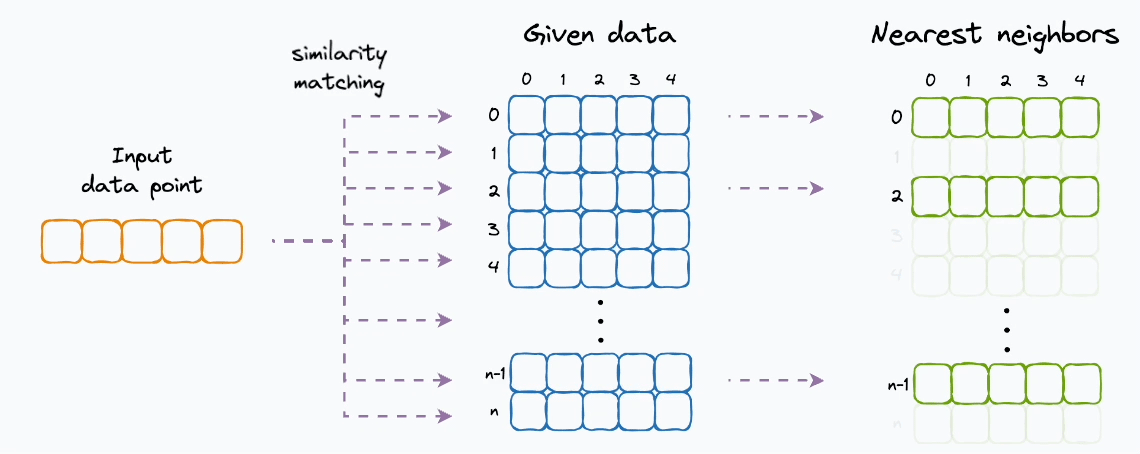
Approximate nearest neighbor search algorithms solve this.
The core idea is to narrow down the search space using indexing techniques, which improves the run-time performance.

Inverted file index (IFV) is one of the simplest and intuitive techniques to do this.
Steps for indexing:
Partition the given data using techniques like k-means.

Each partition gets a centroid, and each data point gets associated with only one partition.

A map holds all the data points that belong to a centroid’s partition.

Indexing done!
Here’s how we search.
First, find the closest centroid to the query:

Next, find the nearest neighbor among only those data points that belong to the closest centroid’s partition:

This drastically reduces the run-time.
Consider:
There are
Ndata points.Each data point is
D-dimensional.We create
Kpartitions.Lastly, for simplicity, let’s assume that each partition gets equal data points.
In kNN, the query data point is matched to all N data points, which makes the time complexity → O(ND).
In IFV, however, there are two steps:
Match to all centroids →
O(KD).Find the nearest neighbor in the nearest partition →
O(ND/K).
The final time complexity comes out to be the following:

…which is significantly lower than that of kNN.
Assume → N=10M and k=100:
The search complexity of kNN will be proportional to 10M.
With IFV, the search complexity will be proportional to
100 + 100k = 100100, which is nearly 100 times faster.
That said, ANN is not always accurate.
If some data points are actually close to the query data point but not in the same partition, they may still get missed:

We willingly accept such trade-offs to reduce latency.
In the deep dives on vector databases (open access), we discussed 4 such techniques, along with an entirely beginner-friendly and thorough discussion on Vector Databases.
Check it out here if you haven’t already: A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
Thanks for reading!