
Feature Discretization in Machine Learning
A linear model can learn non-linear patterns.

Introducing Spark 1 Pro and Spark 1 Mini!
Firecrawl has released two new models that power the /agent endpoint, their state-of-the-art agent that searches, navigates, and extracts web data from a prompt.
Mini is 60% cheaper, and Pro delivers higher accuracy, making it the most powerful extraction endpoint yet.
Here’s Spark 1 benchmarked against similar extraction tools:
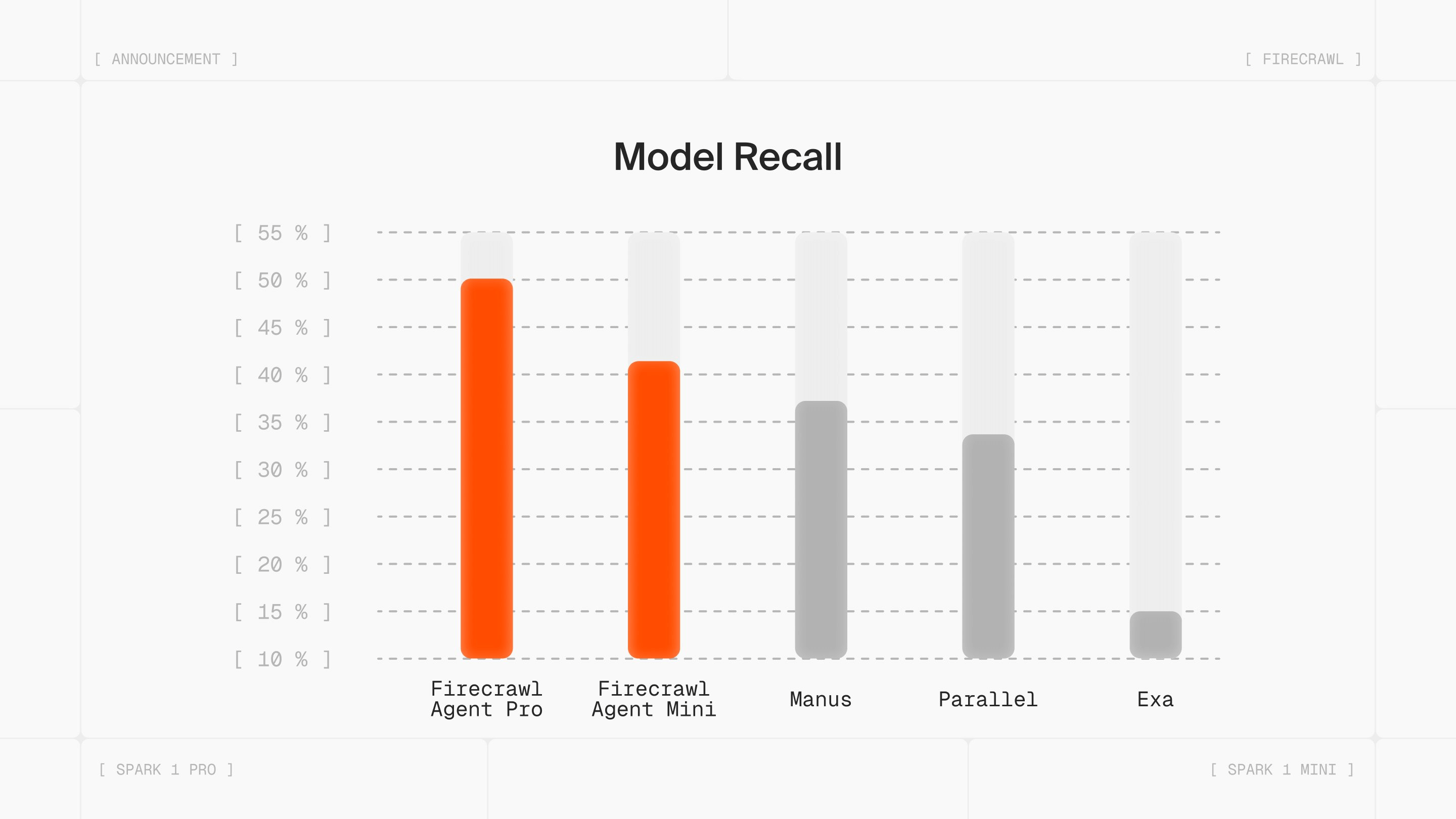
Pro leads on recall at a fraction of the cost. Mini delivers strong accuracy at the lowest price point.
Both outperform tools costing 4-7x more per task.
Try it live in the playground here →
Thanks to Firecrawl for partnering today!
Feature Discretization in Machine Learning
During model development, one overlooked technique to experiment with is feature discretization.
The idea is to transform a continuous feature into discrete features to improve explainability and performance.
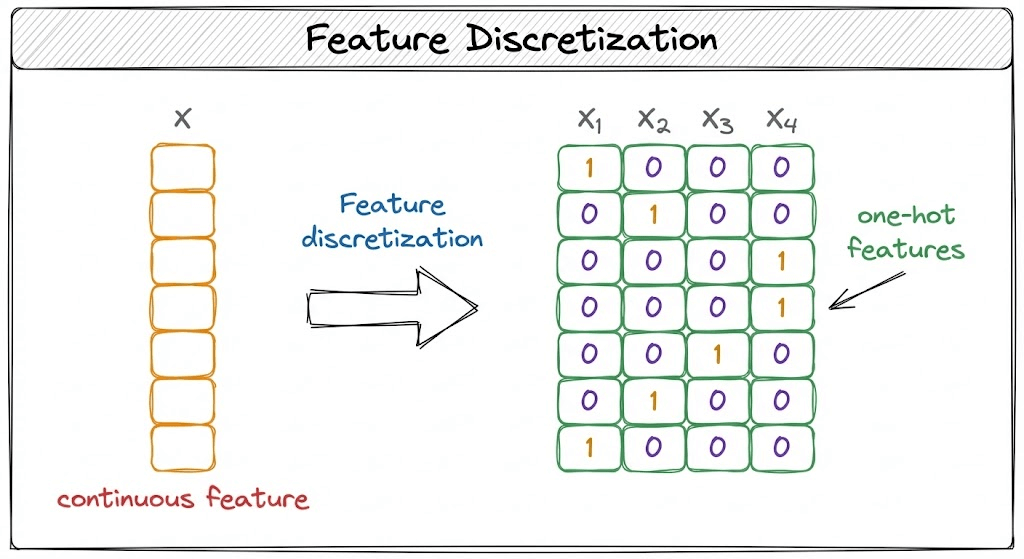
Let’s understand this today!
Motivation for feature discretization
Consider a transaction dataset that has an age feature:

In many use cases, like understanding spending behavior based on transaction history, such continuous variables are better understood when they are discretized into meaningful groups → youngsters, adults, and seniors.
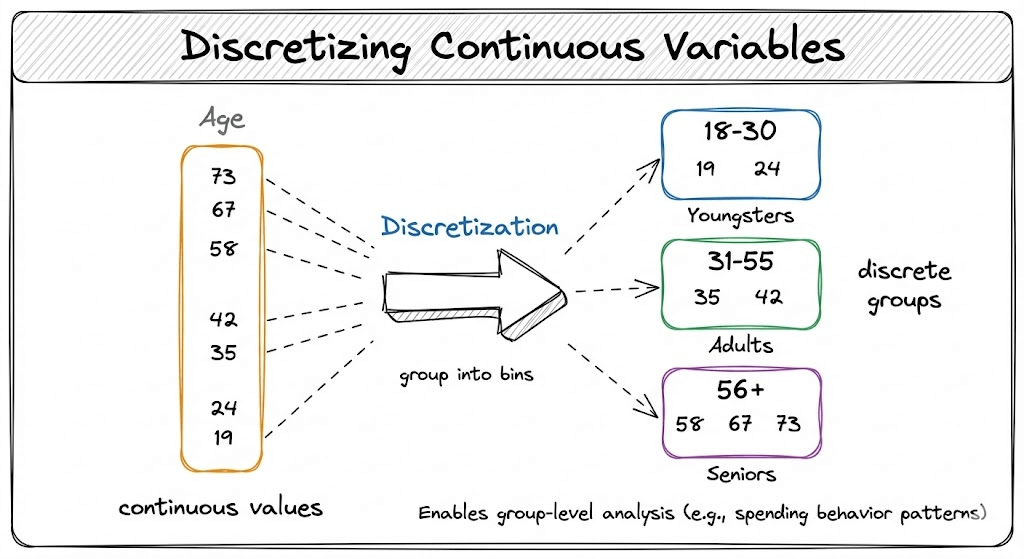
To understand better, think about how a model interprets raw age values.
To the model, the difference between age 29 and 30 is the same as the difference between 59 and 60. But in reality, these age transitions carry very different meanings for spending behavior.
When you discretize age into groups, you’re essentially telling the model: “Don’t treat every single year as equally important. Instead, focus on these broader life stages that actually influence behavior.”
This helps in two ways:
First, it reduces noise. Minor variations within a group (like age 32 vs 35) often don’t meaningfully change behavior patterns. Discretization smooths out these irrelevant fluctuations.
Second, it captures non-linear relationships more naturally. Spending patterns don’t change linearly with age. A discretized feature can model this as “step-change” behavior without forcing the model to learn complex nonlinear boundaries on its own.
2 common techniques for feature discretization
Now that we understand the rationale, here are 2 common techniques:
The first way decomposes a feature into equally sized bins.

The second way decomposes a feature into equal frequency bins:

After that, the discrete values are one-hot encoded.
Feature discretization enables non-linear behavior even if a model is linear:
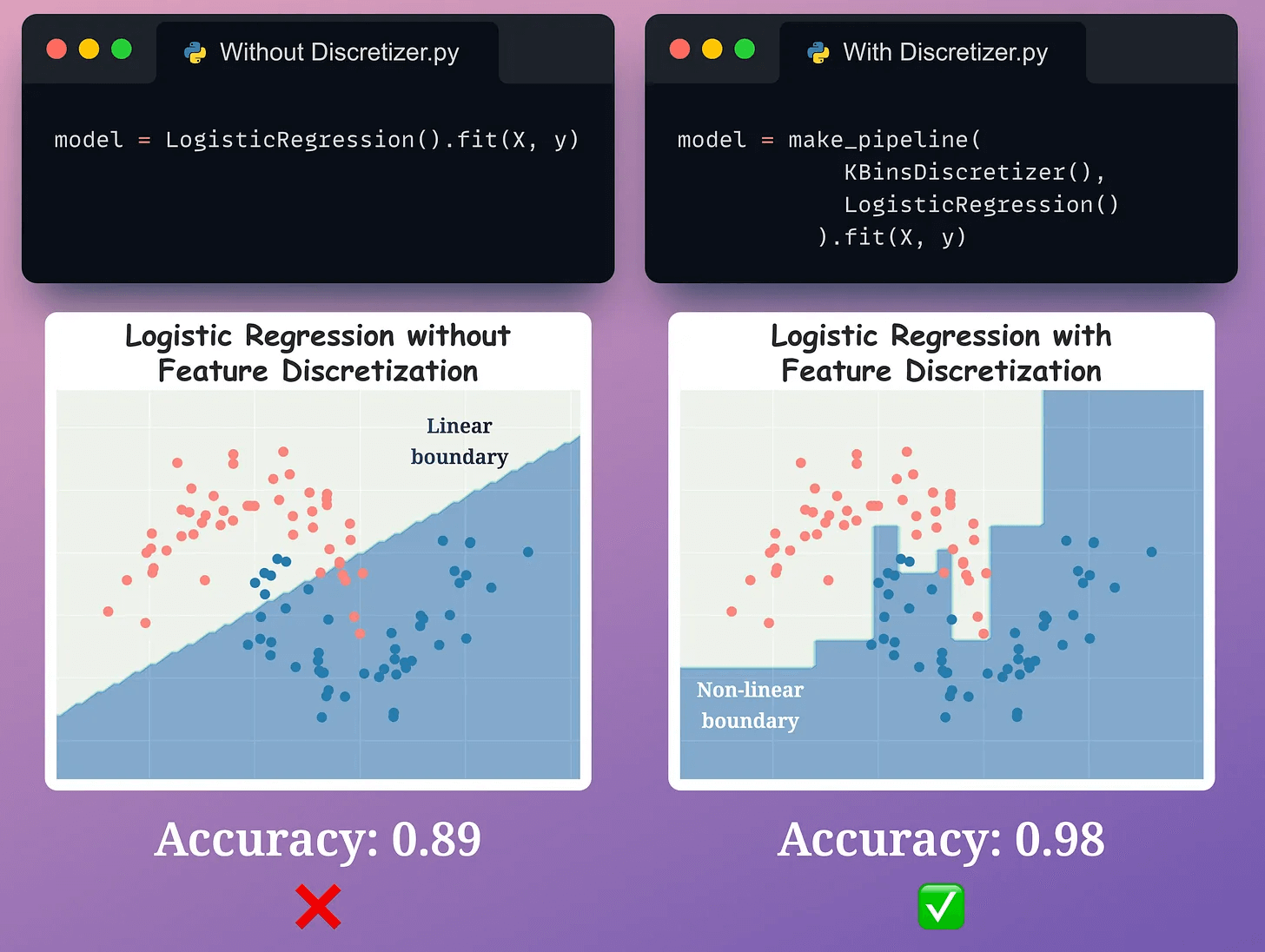
So despite using a simple linear model, you get to learn non-linear patterns.
Another advantage is that it improves the signal-to-noise ratio.
Signal is the meaningful or valuable information in the data.
Binning a feature helps us mitigate the influence of minor fluctuations, which are often mere noise.
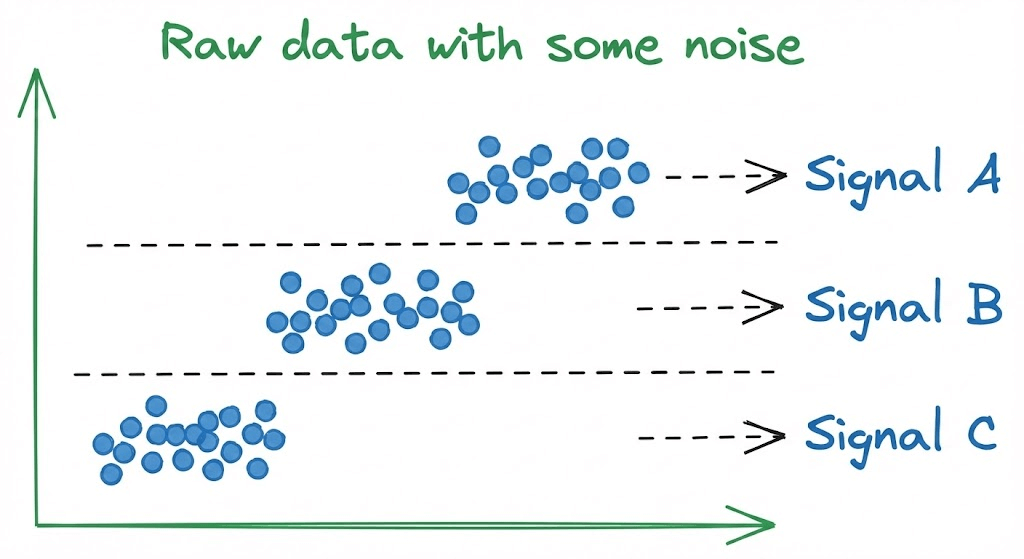
Each bin smooths out the noise.
That said, note that feature discretization increases the data dimensionality.
And, as we progress towards higher dimensions, data becomes more easily linearly separable. Thus, feature discretization can lead to overfitting.
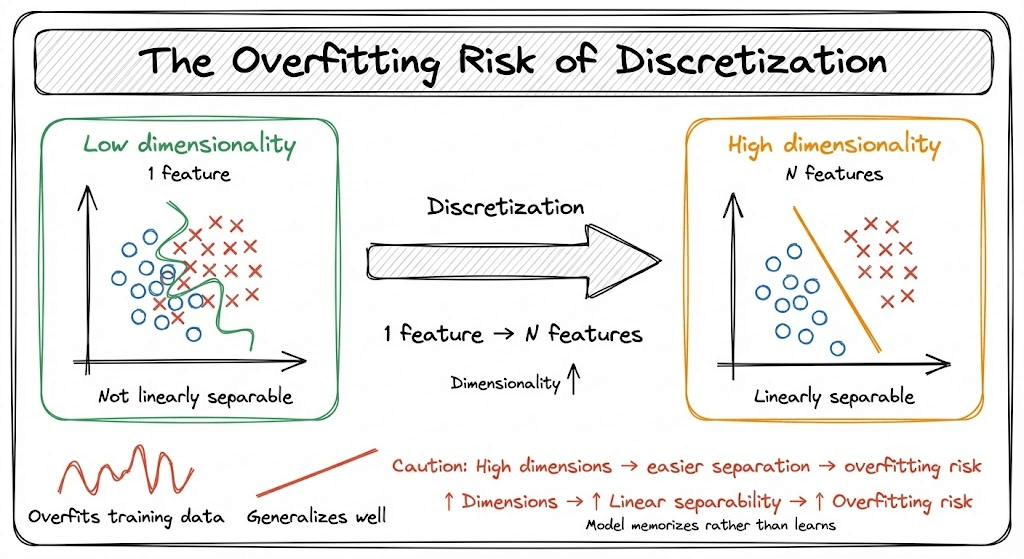
To avoid this, you should not overly discretize features.
Instead, use it when it makes intuitive sense based on the problem at hand.
The utility can vastly vary from one application to another, but we have found that:
Discretizing geospatial data like latitude and longitude is useful.
Discretizing age/weight-related data is useful.
Features that are typically constrained between a range makes sense, like savings/income, etc.
As further reading, learn about:
👉 Over to you: What are some other things to take care of when using feature discretization?