
Feature Tracking Made Simple In Sklearn Transformers

Recently, scikit-learn announced the release of one of the most awaited improvements. In a gist, sklearn can now be configured to output Pandas DataFrames.
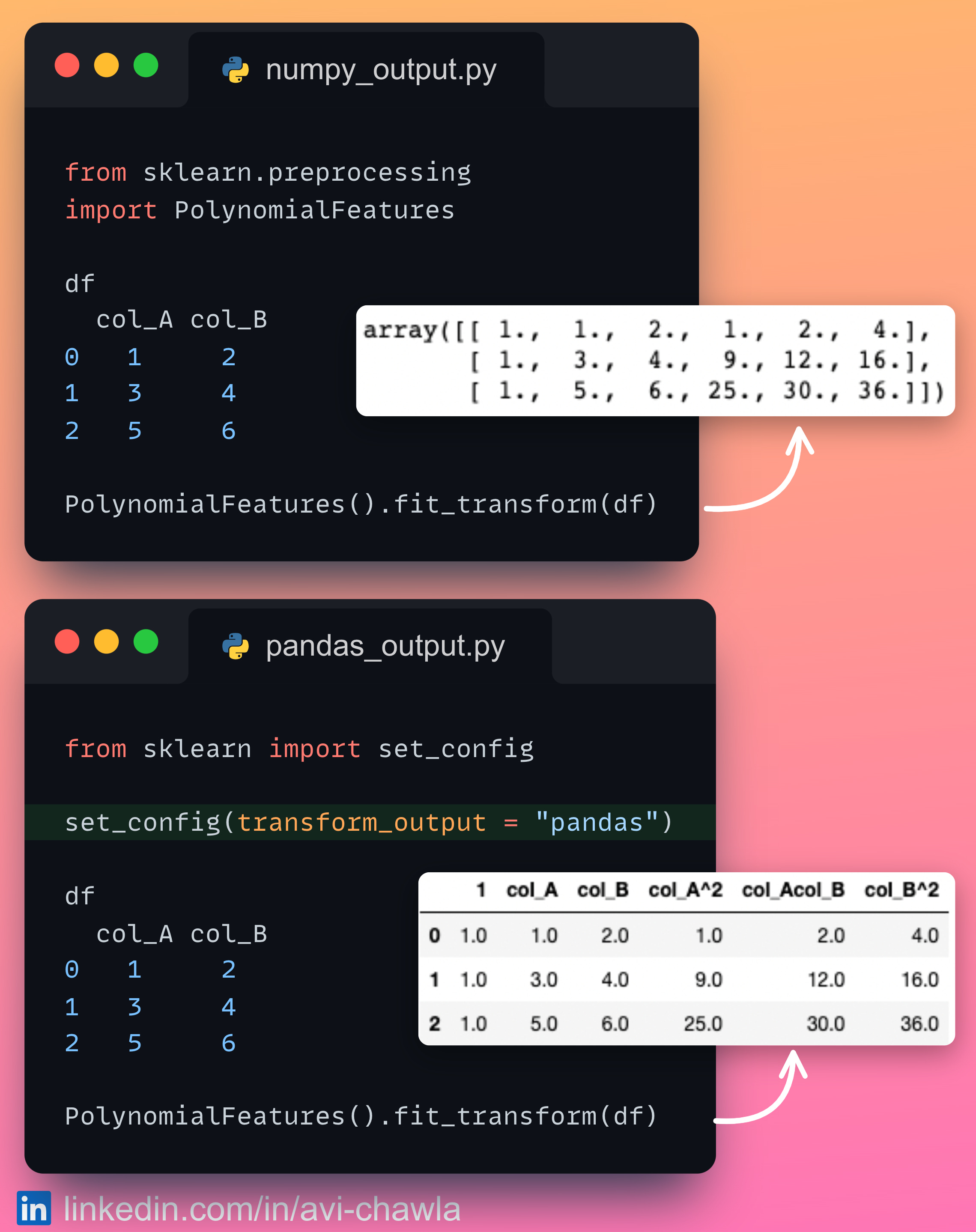
Until now, Sklearn's transformers were configured to accept a Pandas DataFrame as input. But they always returned a NumPy array as an output. As a result, the output had to be manually projected back to a Pandas DataFrame. This, at times, made it difficult to track and assign names to the features.
For instance, consider the snippet above.
In 𝗻𝘂𝗺𝗽𝘆_𝗼𝘂𝘁𝗽𝘂𝘁.𝗽𝘆, it is tricky to infer the name (or computation) of a column by looking at the NumPy array.
However, in the upcoming release, the transformer can return a Pandas DataFrame (𝗽𝗮𝗻𝗱𝗮𝘀_𝗼𝘂𝘁𝗽𝘂𝘁.𝗽𝘆). This makes tracking feature names incredibly simple.
P.S. The feature is in dev and will be rolled out soon!
Read more: Release page.
I like to explore, experiment and write about data science concepts and tools. You could connect with me on LinkedIn.