
Federated Learning: An Overlooked ML Technique That Deserves More Attention
A step towards privacy-preserving ML.

Last week, we discussed four critical model training paradigms used in training many real-world ML models.
Here’s the visual from that post for a quick recap:
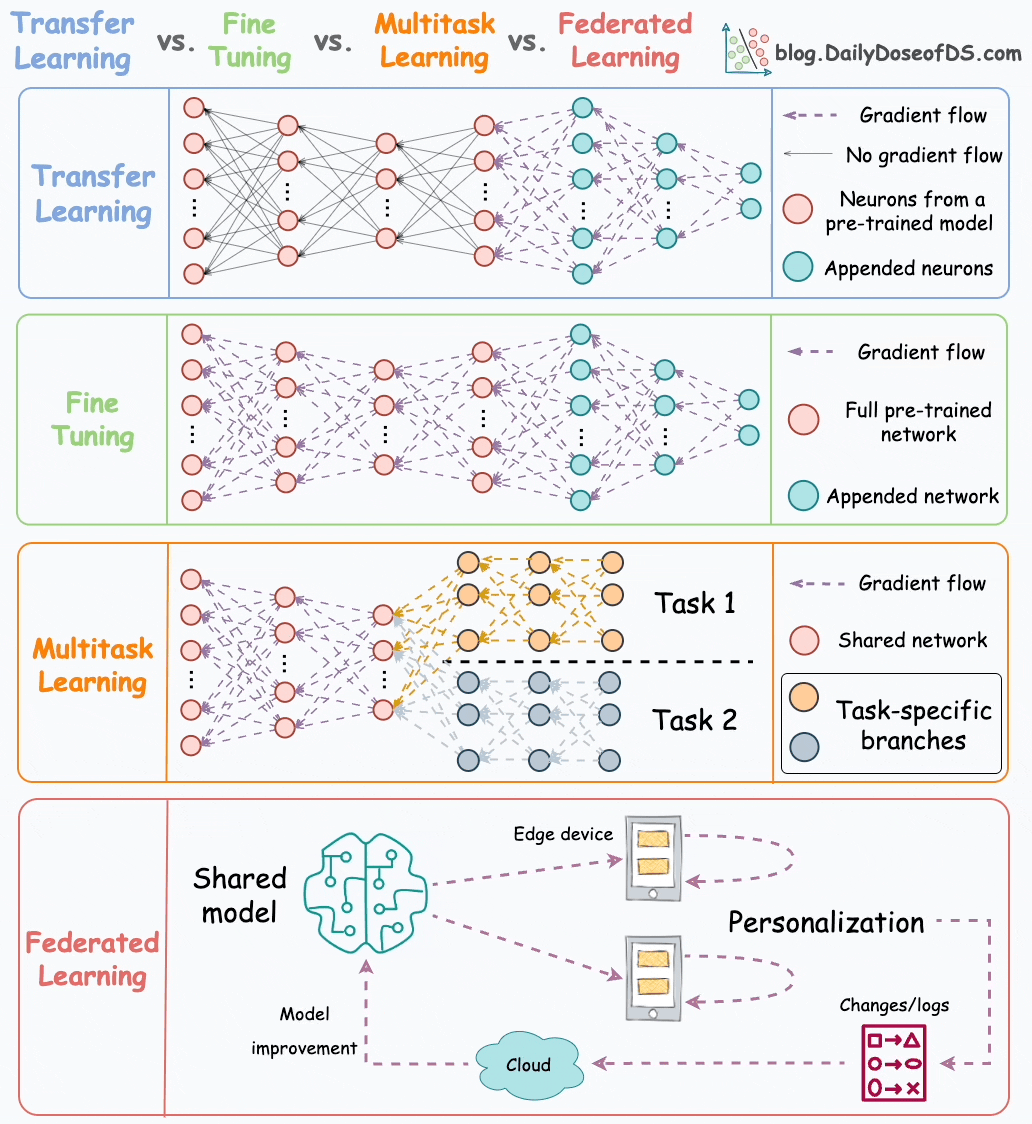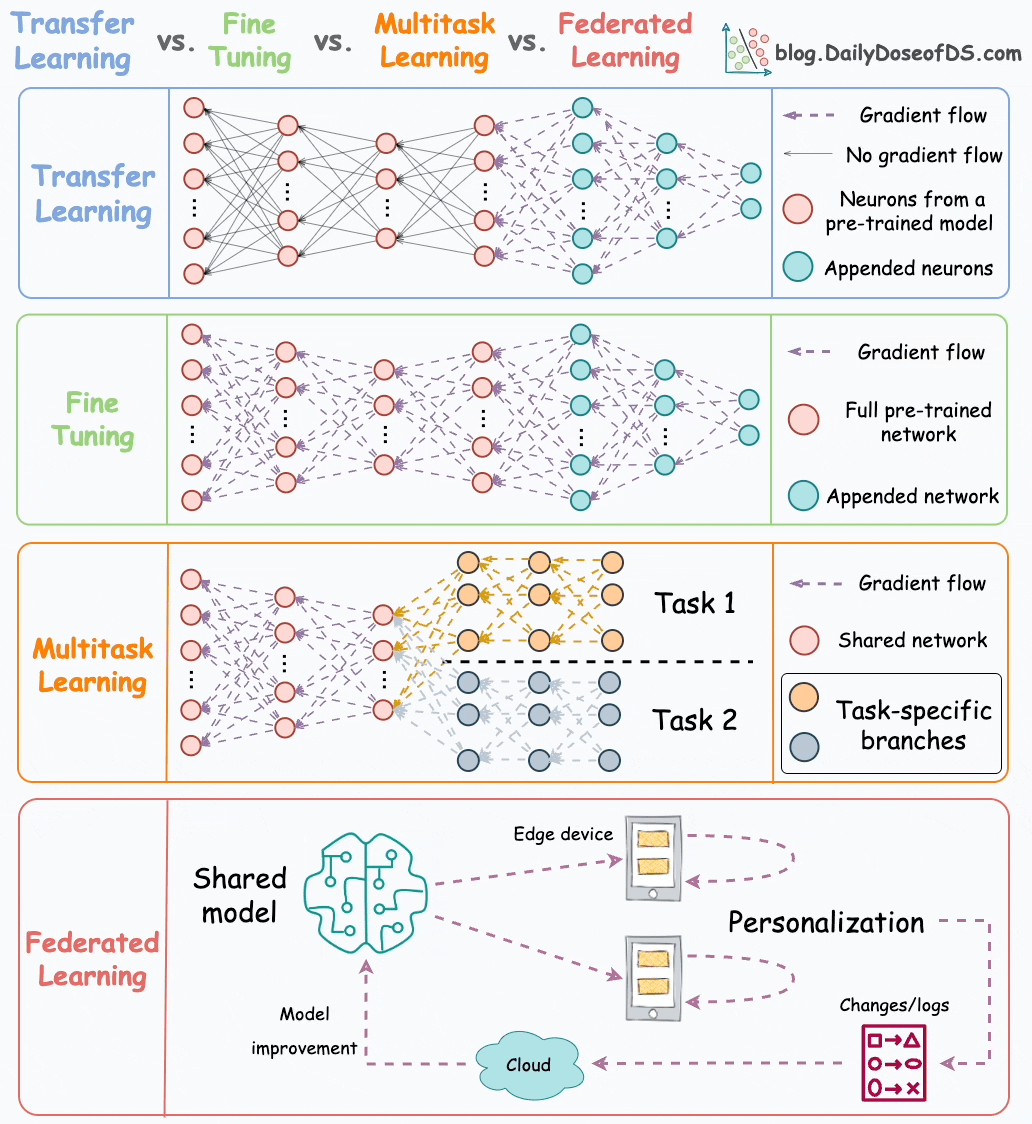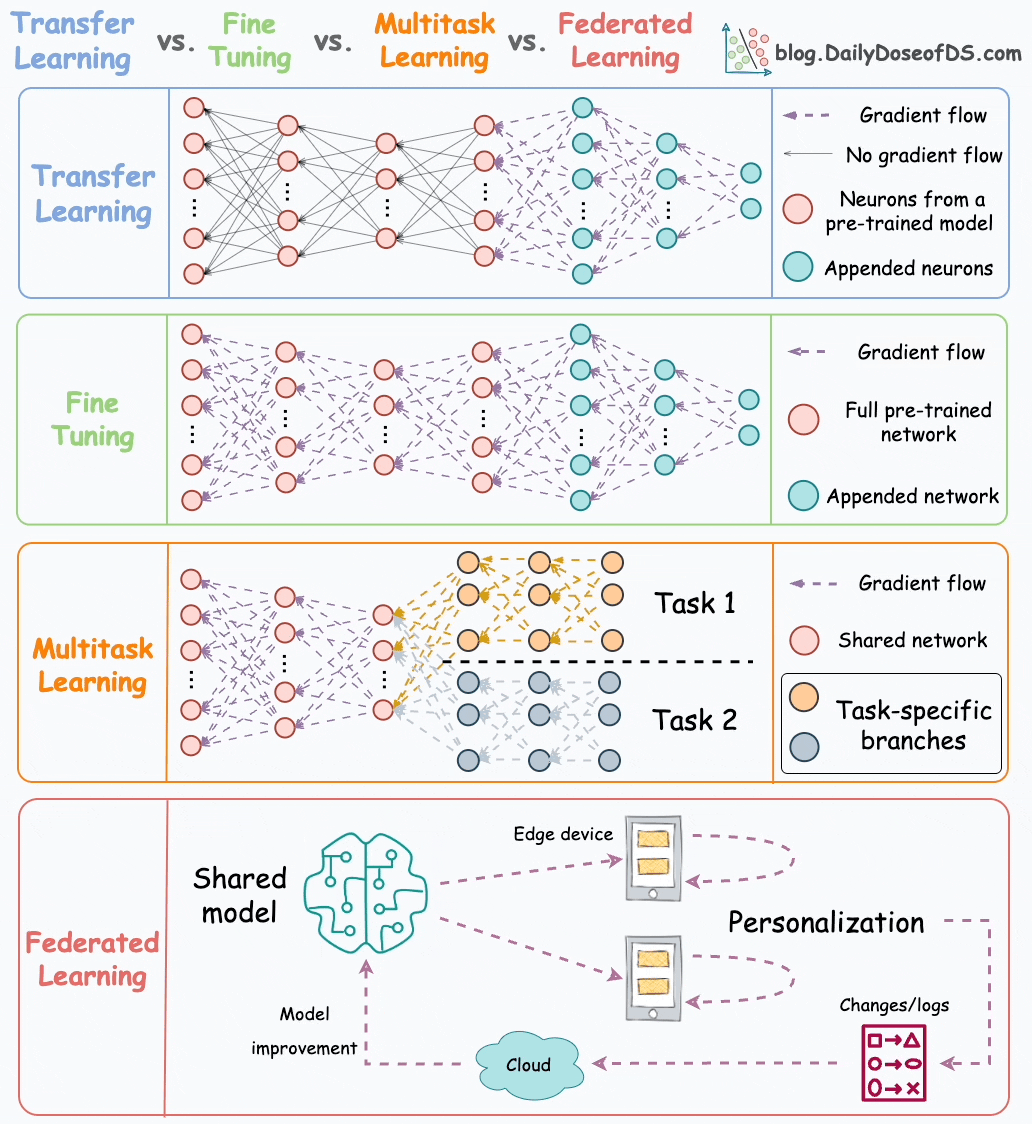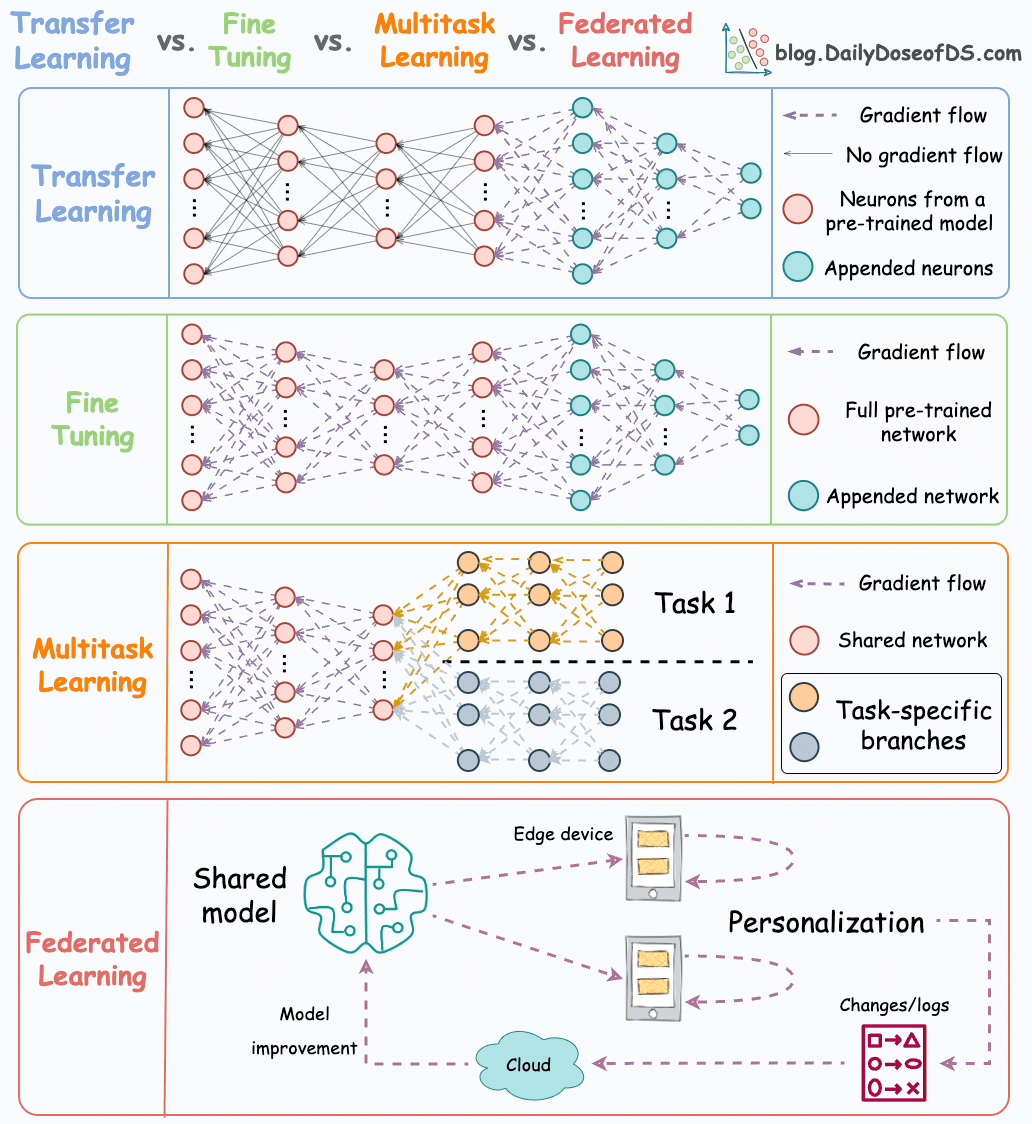
In this graphic, transfer learning, fine-tuning, and multi-task learning are pretty mainstream and widely used in ML.
But I genuinely believe that federated learning is among those very powerful techniques that is not given the true attention it deserves.
Let’s understand this today.
The problem
Modern devices (like smartphones) have access to a wealth of data that can be suitable for ML models.
To get some perspective, consider the number of images you have on your phone right now, the number of keystrokes you press daily, etc.
That’s plenty of data, isn’t it?
And this is just about one user — you.
But applications can have millions of users. The amount of data we can train ML models on is unfathomable.
So what is the problem here?
The problem is that almost all data available on modern devices is private.
Images are private.
Messages you send are private.
Voice notes are private.
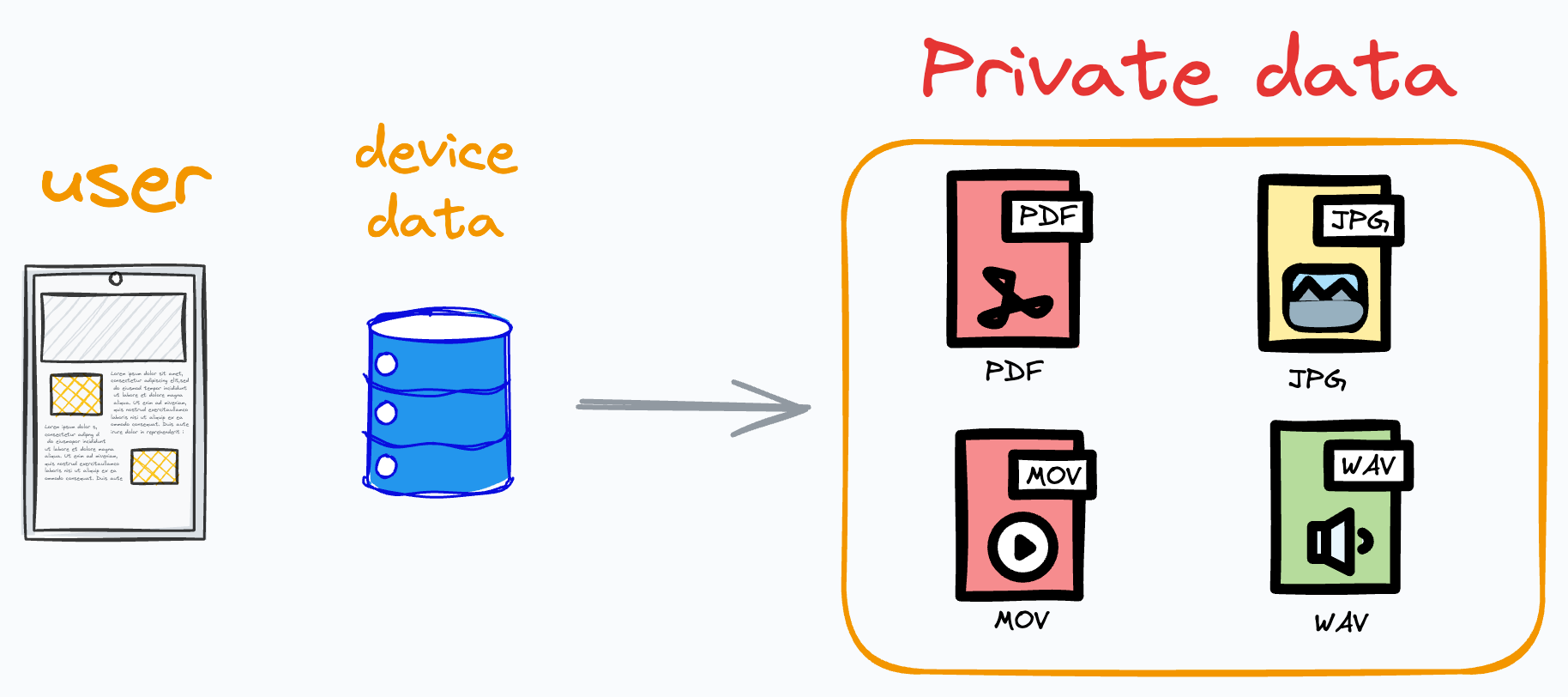
Being private, this data can NEVER be aggregated in a central location, as traditionally, ML models are always trained on centrally located datasets.
The solution
But this data is still valuable to us, isn’t it?
We want to utilize it in some way.
Federated learning smartly addresses this challenge of training ML models on private data.
Here’s the core idea:
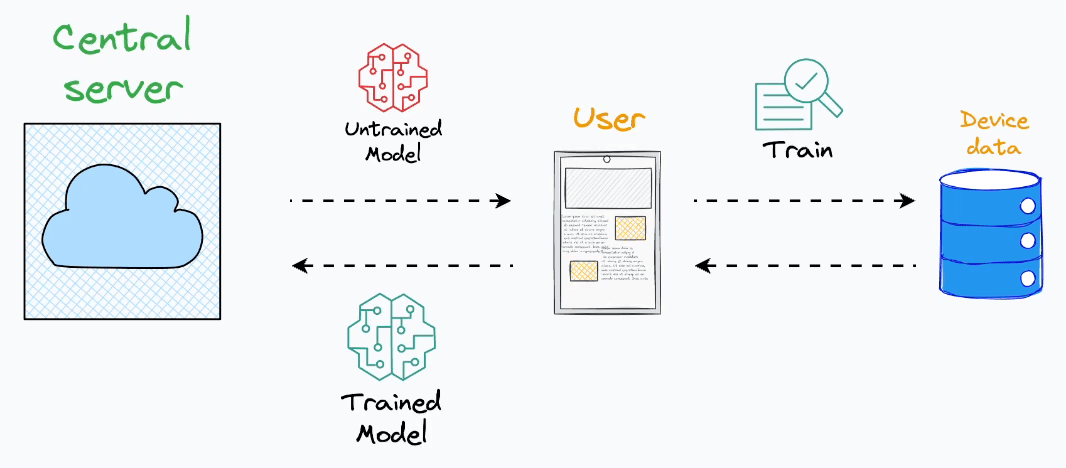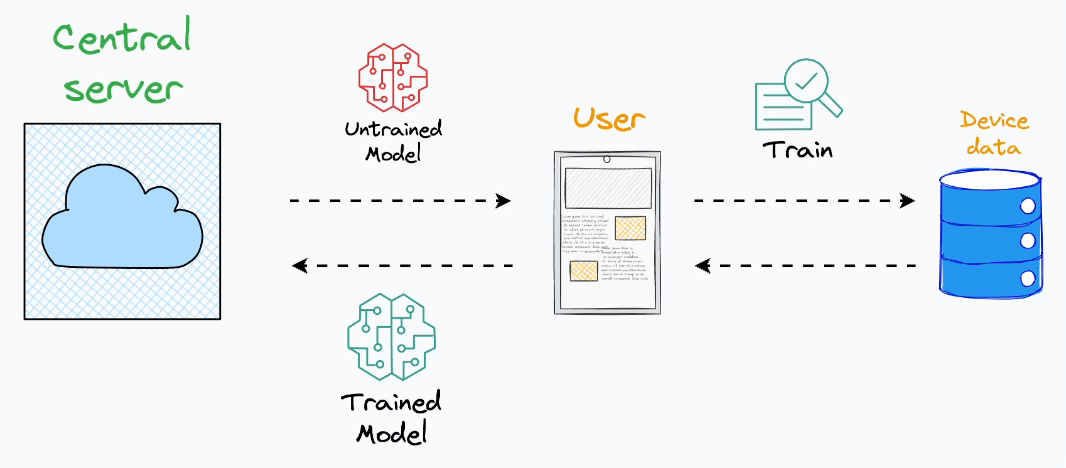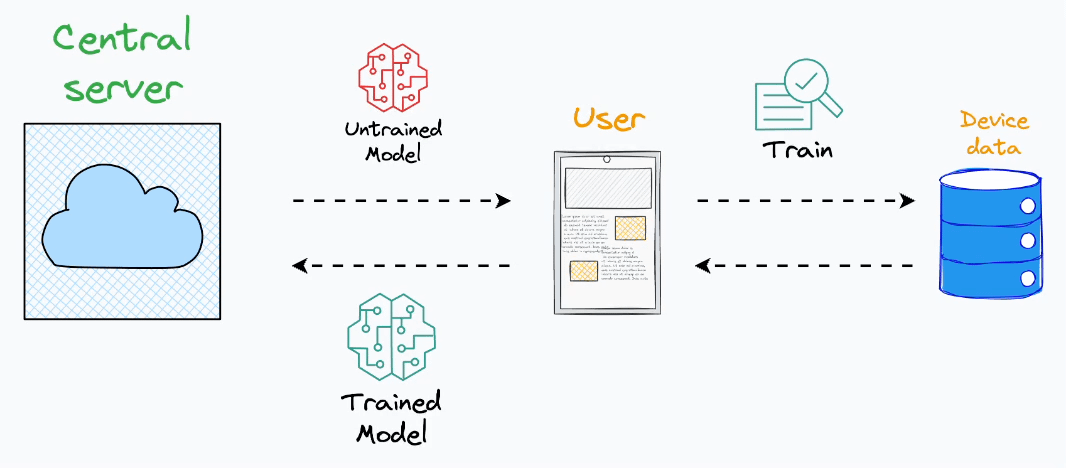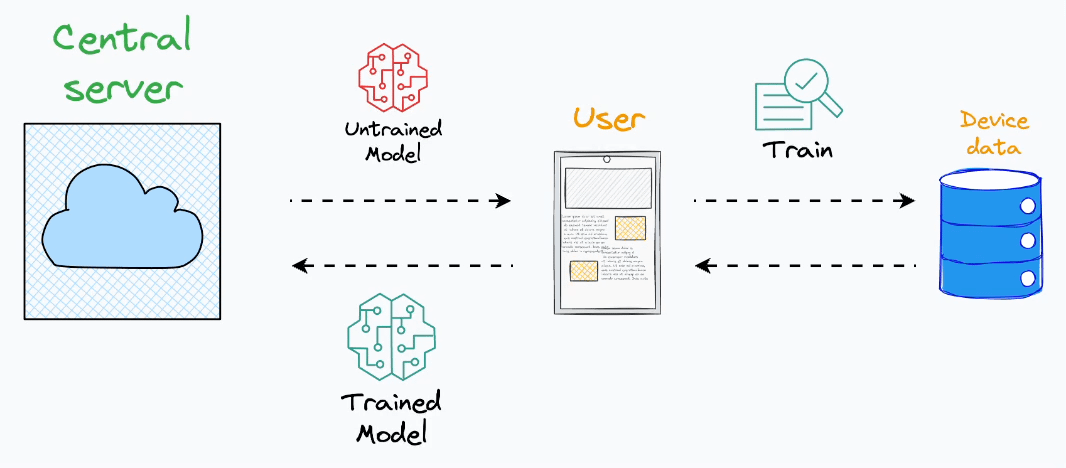
Instead of aggregating data on a central server, dispatch a model to an end device.
Train the model on the user’s private data on their device.
Fetch the trained model back to the central server.
Aggregate all models obtained from all end devices to form a complete model.
That’s an innovative solution because each client possesses a local training dataset that remains exclusively on their device and is never uploaded to the server.
Yet, we still get to train a model on this private data.
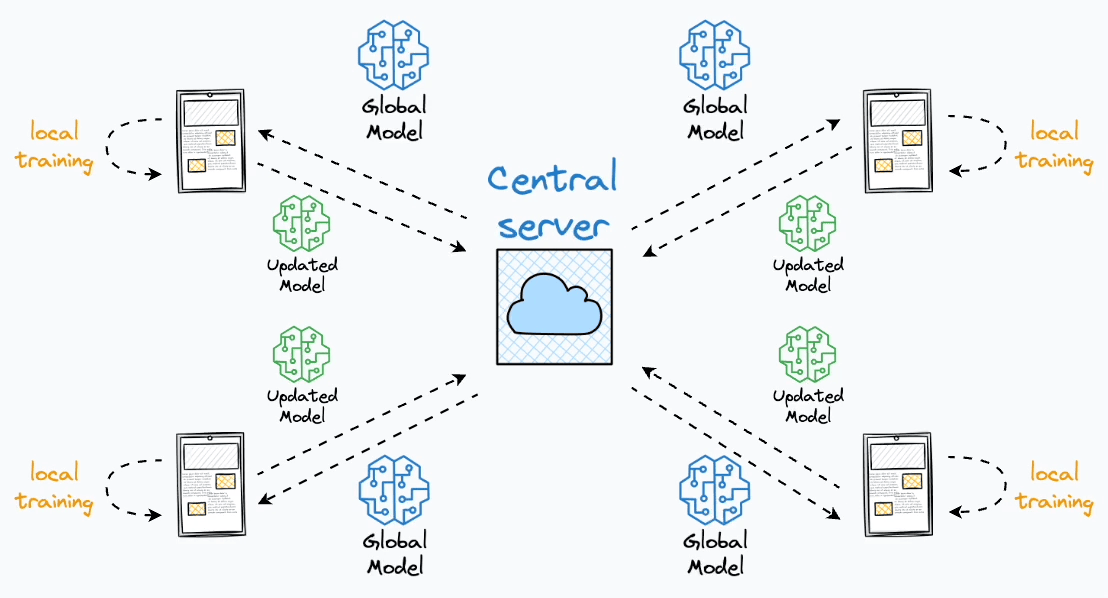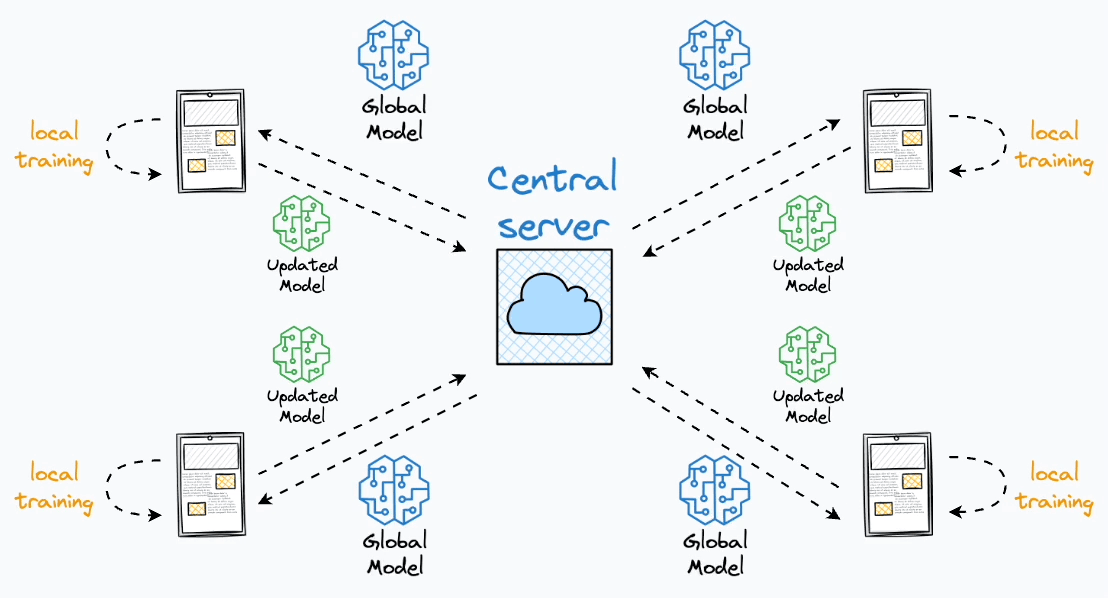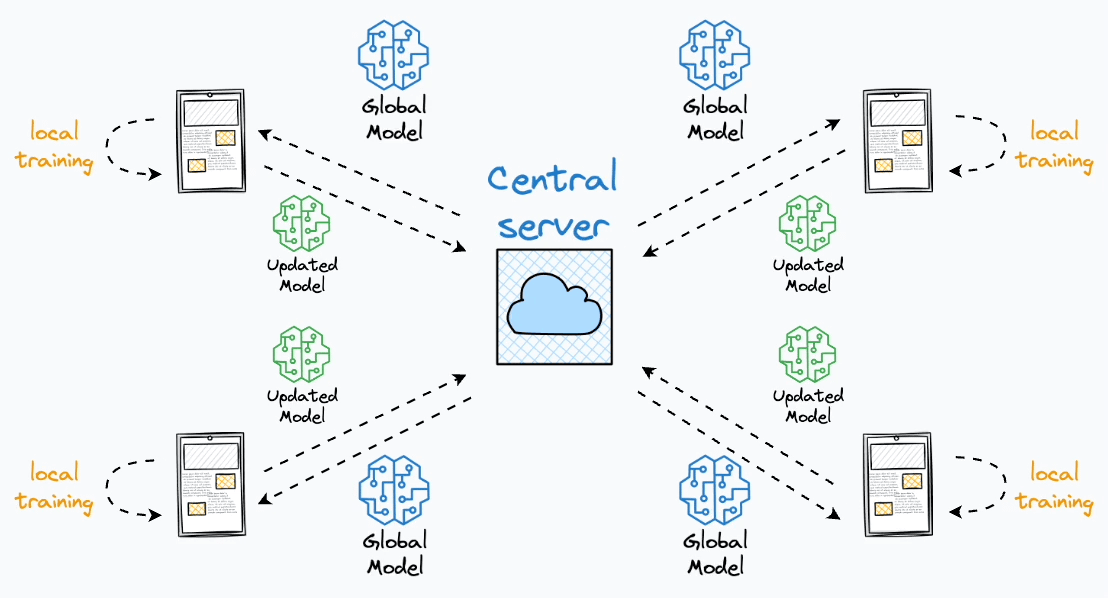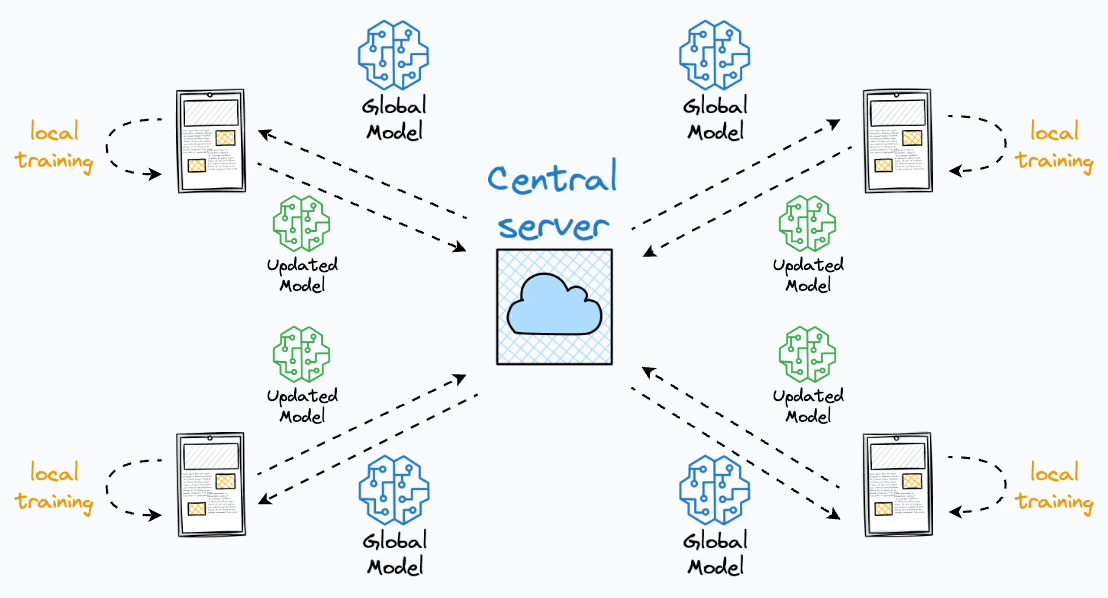
Furthermore, federated learning distributes most computation to a user’s device.
As a result, the central server does not need the enormous computing that it would have demanded otherwise.
Cool technique, isn’t it?
Of course, there are many challenges to federated learning:
How do we decide whether federated learning is actually suitable for us?
As the model is trained on the client side, how to reduce its size?
How do we aggregate different models received from the client side?
[IMPORTANT] Privacy-sensitive datasets are always biased with personal likings and beliefs. For instance, in an image-related task:
Some clients may only have pet images.
Some clients may only have car images.
Some clients may love to travel, so most images they have are travel-related.
How do we handle such skewness in client data distribution?
What are the considerations for federated learning?
Lastly, how do we implement federated learning models?
Can you answer these questions?
If not, then this is precisely what we are discussing in the latest real-world ML deep dive: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning:

The idea behind federated learning appeared to be extremely compelling and smart to me when I first used it in a project at Mastercard.
In my experience, federated learning is one of those training paradigms that deserves much more attention.
I see a great utility for this technique in the near future.
This is because, lately, more and more users have started caring about their privacy.
Thus, more and more ML teams are resorting to federated learning to build ML models, while still preserving user privacy.
In this article, I have put down everything I learned during that exploration.
So, even if you know nothing about federated learning, you are good to go :)
👉 Curious folks can read it here: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!