
Federated Learning in ML
...explained visually.

Fine-tune DeepSeek-OCR on a new language (100% locally on a single GPU)!
DeepSeek-OCR is a 3B-parameter vision model that achieves 97% precision while using 10× fewer vision tokens than text-based LLMs.
It handles tables, papers, and handwriting without killing your GPU or budget.
Why it matters:
Most vision models treat documents as massive sequences of tokens, making long-context processing expensive and slow.
DeepSeek-OCR uses context optical compression to convert 2D layouts into vision tokens, enabling efficient processing of complex documents.
You can easily fine-tune it for your specific use case on a single GPU.

We used Unsloth to run this experiment on Persian text and saw an 88.26% improvement in character error rate.
Base model: 149% character error rate (CER)
Fine-tuned model: 60% CER (57% more accurate)
Training time: 60 steps on a single GPU
Persian was just the test case. You can swap in your own dataset for any language, document type, or specific domain you’re working with.
You can find the complete guide (code, notebooks, and environment) in a single click setup here →
Everything is 100% open-source!
Federated Learning in ML explained visually!
Federated learning is among those ML techniques that’s super powerful and compelling, but it does not get the true attention it deserves.
Here’s a visual that depicts how it works:
Let’s understand this in detail today and how it works!
We covered this in more detail with implementation here: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
The problem
Modern devices (like smartphones) host a ton of data for ML models.
To get some perspective, consider the number of images you have on your phone right now, the number of keystrokes you press daily, etc.
And this is just about one user: you.
But applications have millions of users, so the amount of data is unfathomable.
The problem is that data on modern devices is mostly private.
Images are private.
Messages you send are private.
Voice notes are private.
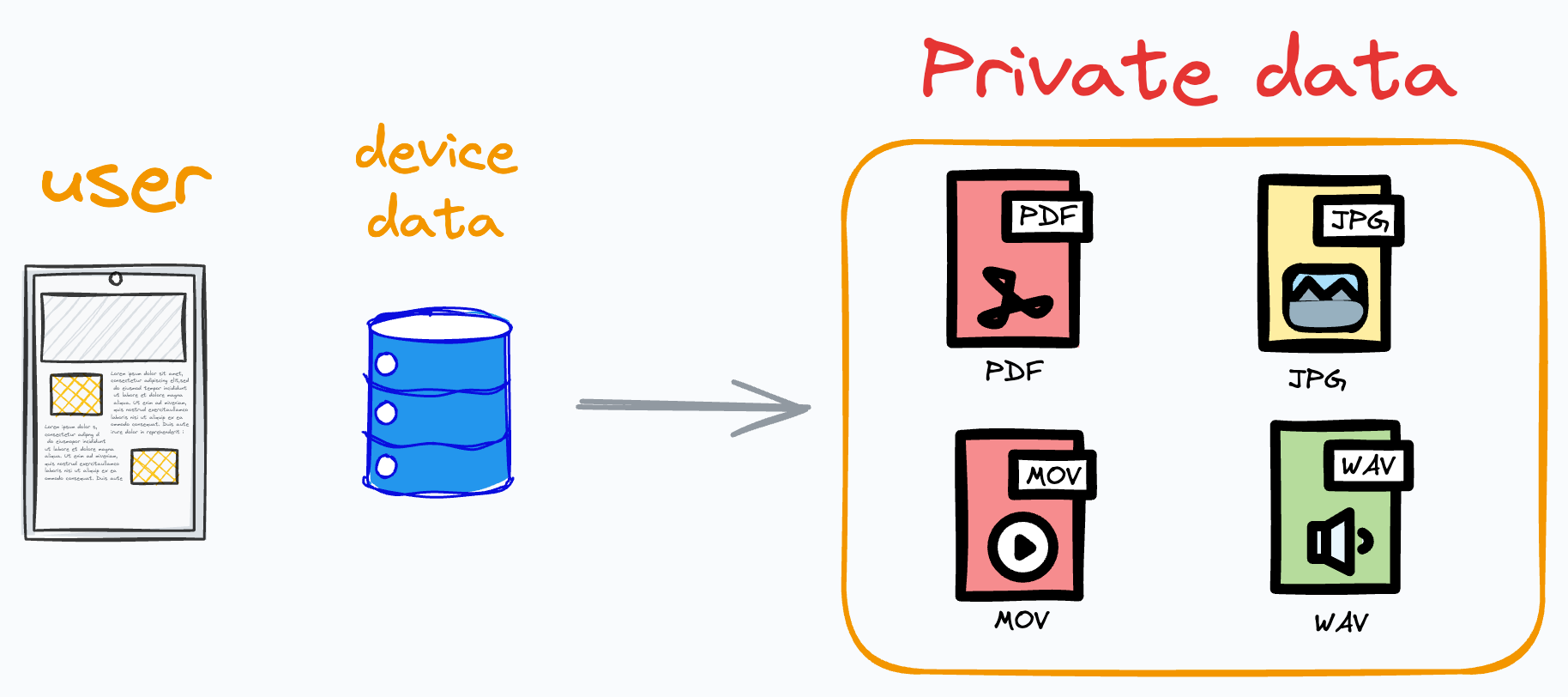
So it cannot be aggregated in a central location to centrally train ML models.
The solution
Federated learning smartly addresses this challenge.
Here’s the core idea:
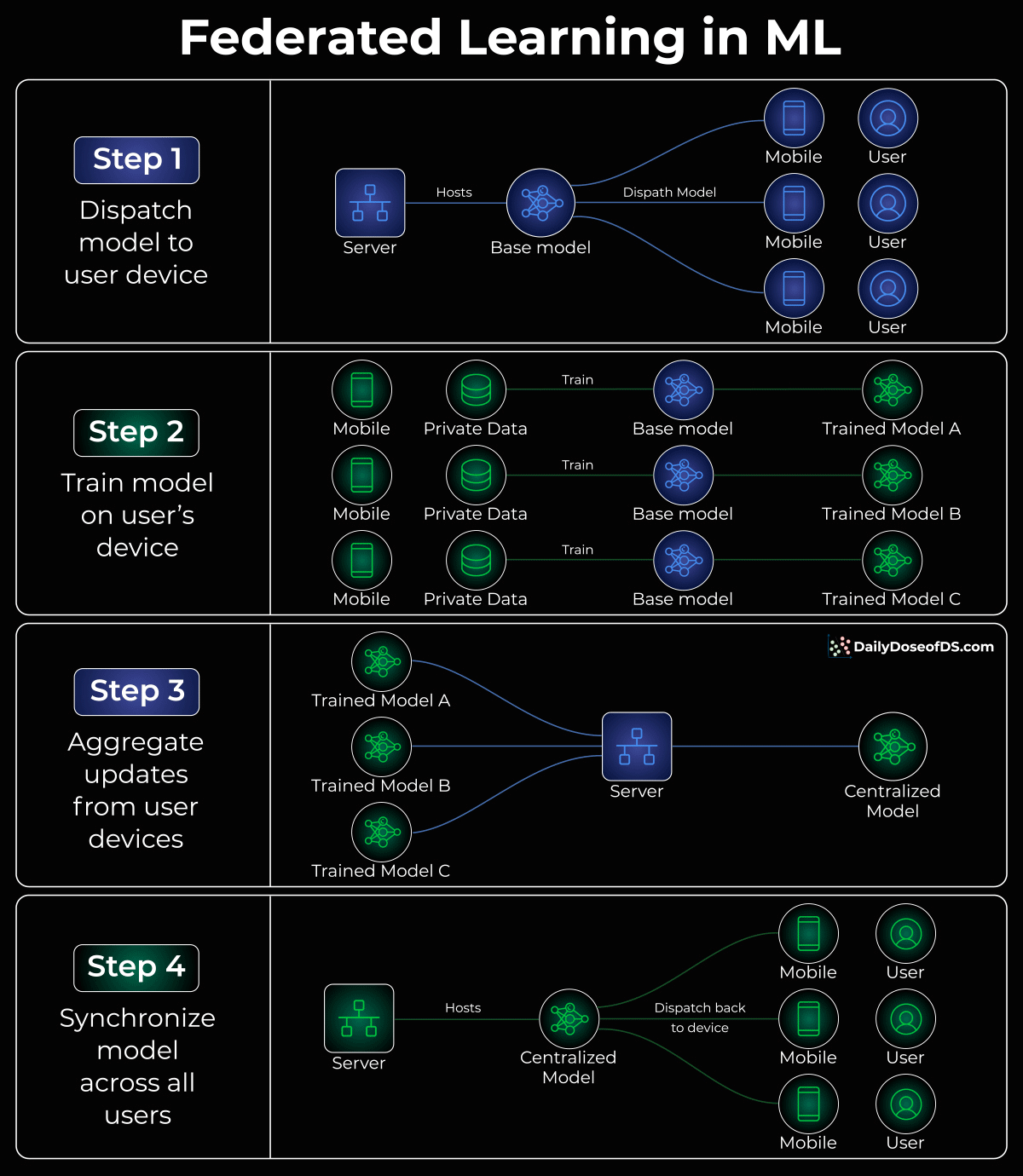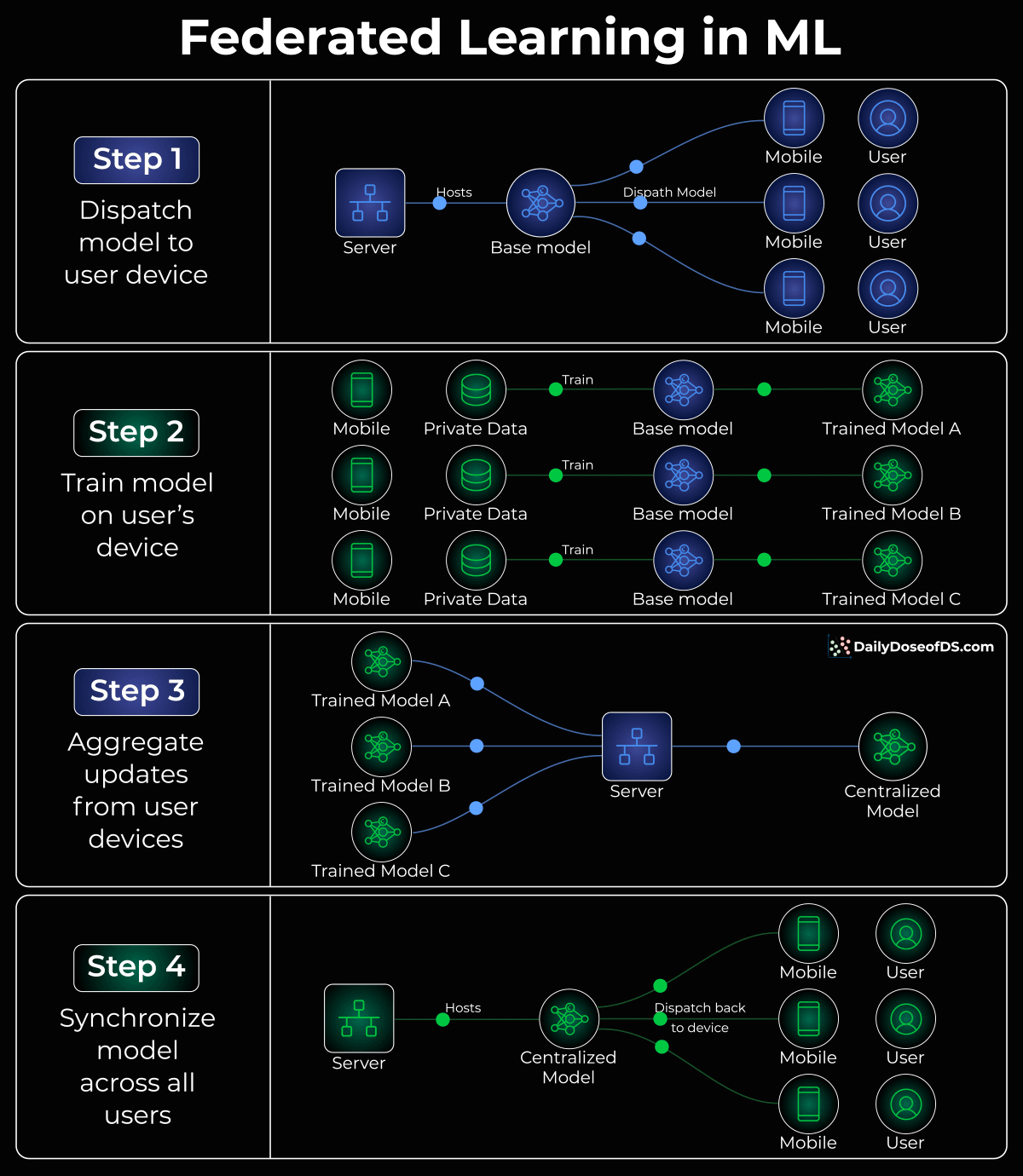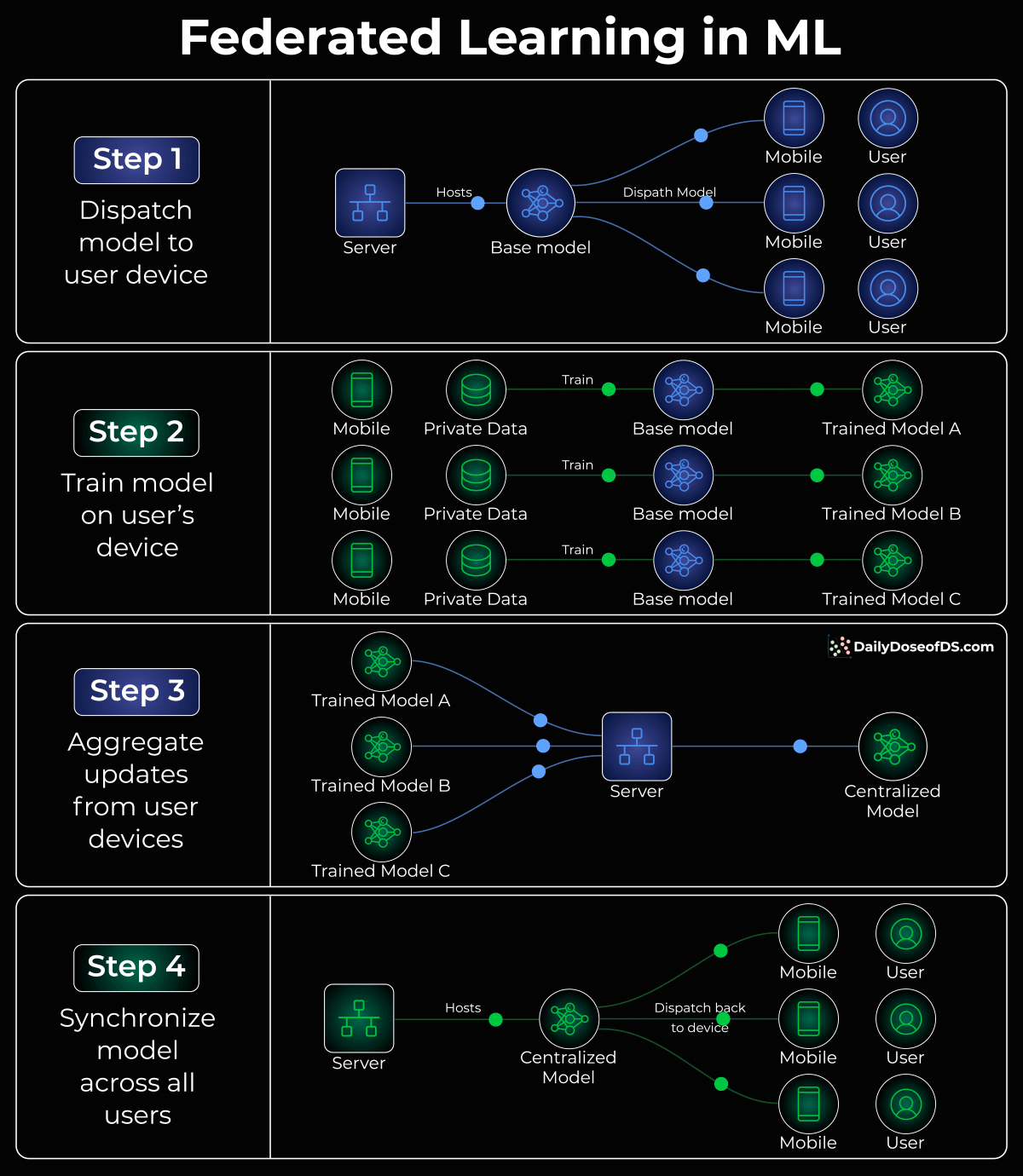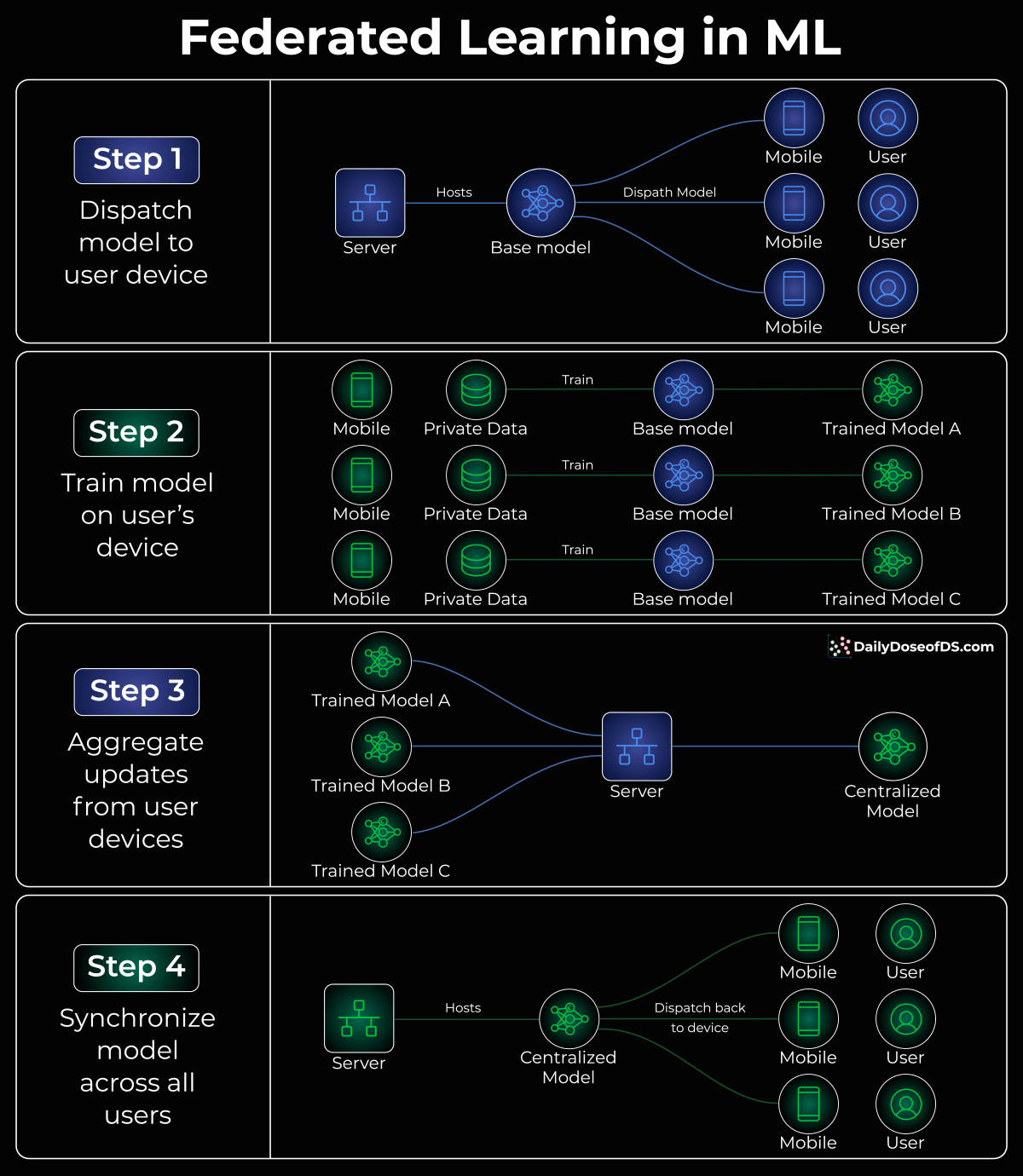
Instead of aggregating data on a central server, dispatch a model to an end device.
Train the model on the user’s private data on their device.
Fetch the trained model back to the central server.
Aggregate all models obtained from all end devices to form a complete model.
This setup ensures private data remains exclusively on the user’s device.
Furthermore, federated learning distributes most computation to a user’s device, reducing computation requirements on the server side.
This is how federated learning works!
The challenges
Of course, there are many challenges to federated learning:
As the model is trained on the client side, how can to reduce its size?
How do we aggregate different models received from the client side?
[IMPORTANT] Privacy-sensitive datasets are always biased with personal likings and beliefs. For instance, in an image-related task:
Some clients may have several pet images.
Some clients may have several car images.
Some clients may love to travel, so most images they have are travel-related.
How do we handle such skewness in client data distribution?
What are the considerations for federated learning?
Lastly, how do we implement federated learning models?
If you want to learn more, we covered it here: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Why care?
We find the idea behind federated learning extremely compelling and see a great utility for this technique in the near future.
This is because, lately, more and more users have started caring about their privacy.
Thus, more and more ML teams are resorting to federated learning to build ML models, while still preserving user privacy.
👉 Over to you: What are some other challenges with privacy-driven ML?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.