
Finally, AI’s Most Human Interface is Here!
...explained with code.

Every few years, AI gets a new interface.
Vision had its ImageNet moment. Text had transformers.
And finally, voice is having a similar moment now.
Just for context, building voice apps has been super tough because in production, people talk over each other, switch languages mid-sentence, and use domain terms. Some have poor mics, background noise, and accents. There are privacy requirements, profanity filtering, and whatnot, all of which require a hefty engineering effort to build a reliable system.
In today’s issue, let’s look at some of the latest updates from AssemblyAI that address this to build production-grade Voice AI apps over 99 languages.
AssemblyAI’s models are not open-source but you get 300+ hrs of free transcription to access their production-grade models. You can get your 300+ hours of free transcription here →
Let’s begin!
Speaker Identification
Most models diarize (“who spoke what and when”) but can’t identify precise speaker names, which ideally, could be inferred from the audio itself.
So we end up mapping “Speaker 1/2/3” by hand or via brittle heuristics.
Speaker Identification can now infer names/roles directly from speech and lets you seed known values if available.
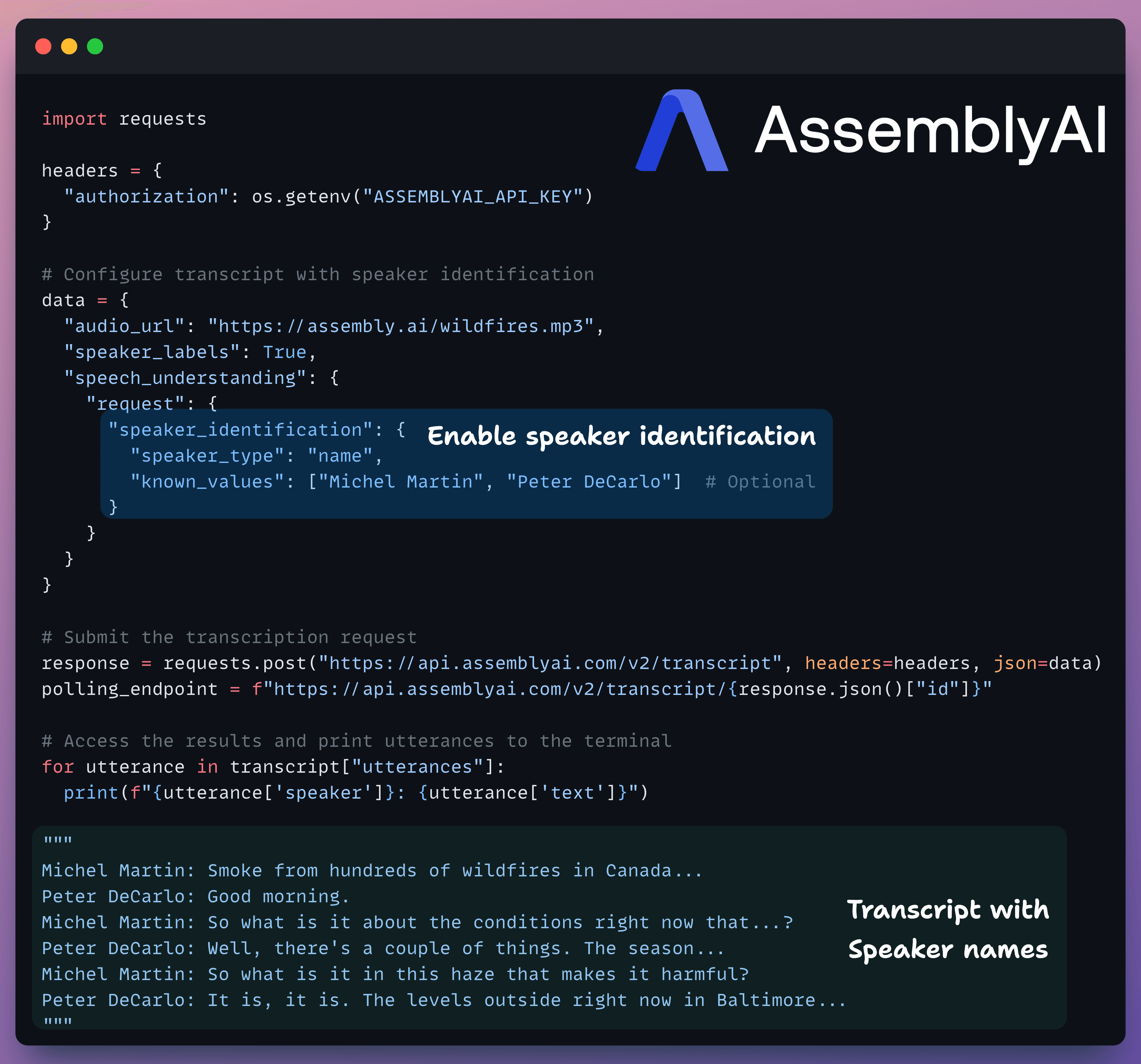
Instead of identifying speakers by name as shown in the examples above, you can also identify speakers by role.
This can be useful in customer service calls, AI interactions, or any scenario where you may not know the specific names of the speakers but still want to identify them by something more than a generic identifier like A, B, or C.
More about it in the docs here →
Receive a translated transcript in 89 supported languages
With this update, you can translate speaker utterances into one or more target languages without any second pass through another API.
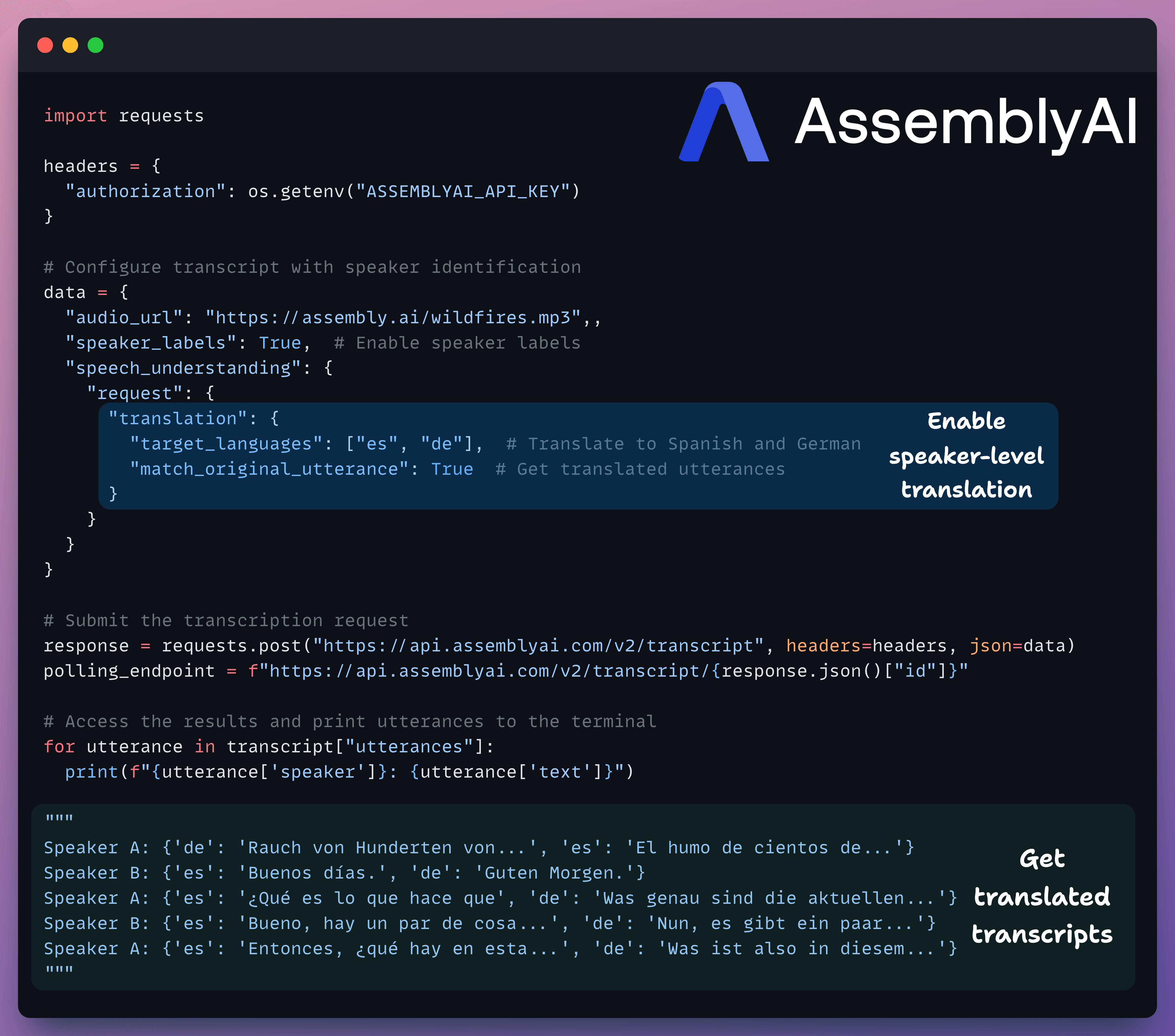
More about it in the docs here →
Custom formatting
Receiving well-formatted transcripts is important if some downstream automation deals with dates, emails, phone numbers, or financial records.
This update allows you to define domain-specific output formats so that transcripts are immediately machine-usable.
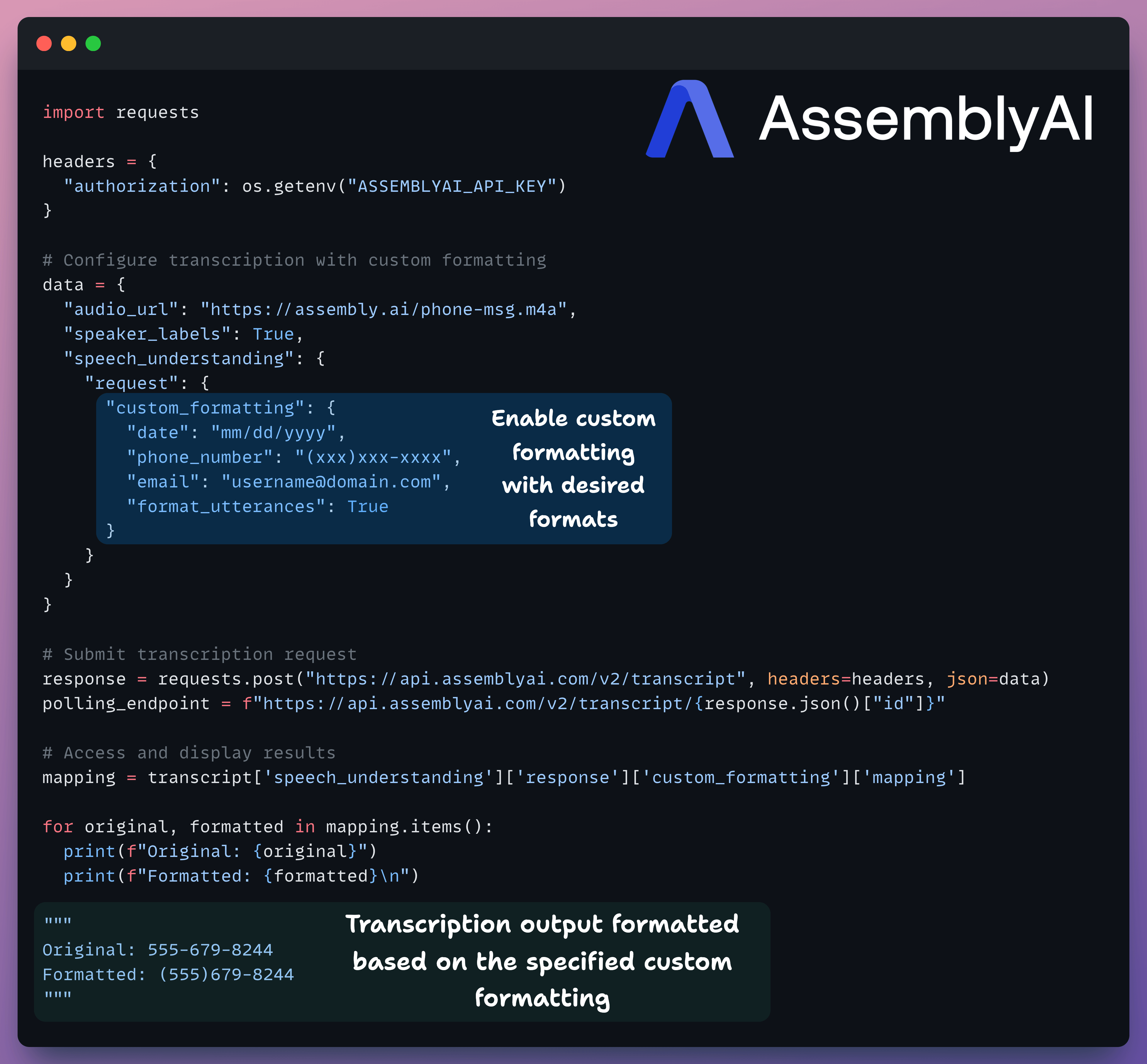
This saves time spent writing regex scripts or any other post-processing steps.
More about it in the docs here →
Guardrails
When you’re processing human speech at scale, you’re bound to encounter profanity, personal data, or unsafe content.
Guardrails solve this so that you can keep applications safe, compliant, and clean before the data reaches any downstream system.
There are three major types of guardrails you can enable.
For instance, PII Redaction lets you automatically detect and remove personally identifiable info, like names, addresses, organizations, etc., from transcripts:

There are two more ways that you can learn more about in the docs:
Profanity Filtering: This lets you keep transcripts professional by automatically detecting and removing offensive language.
Content moderation: Using this, you can automatically classify unsafe or sensitive content (like violence, health issues, disasters) with confidence scores and timestamps.
LLM Gateway
Typically, once you have a transcript, you may send it to another LLM API for summarization, sentiment analysis, or insight extraction.
This requires more integrations, costs, and latency.
LLM Gateway lets you send prompts directly from your transcripts to models like GPT or Gemini without requiring any additional API keys:
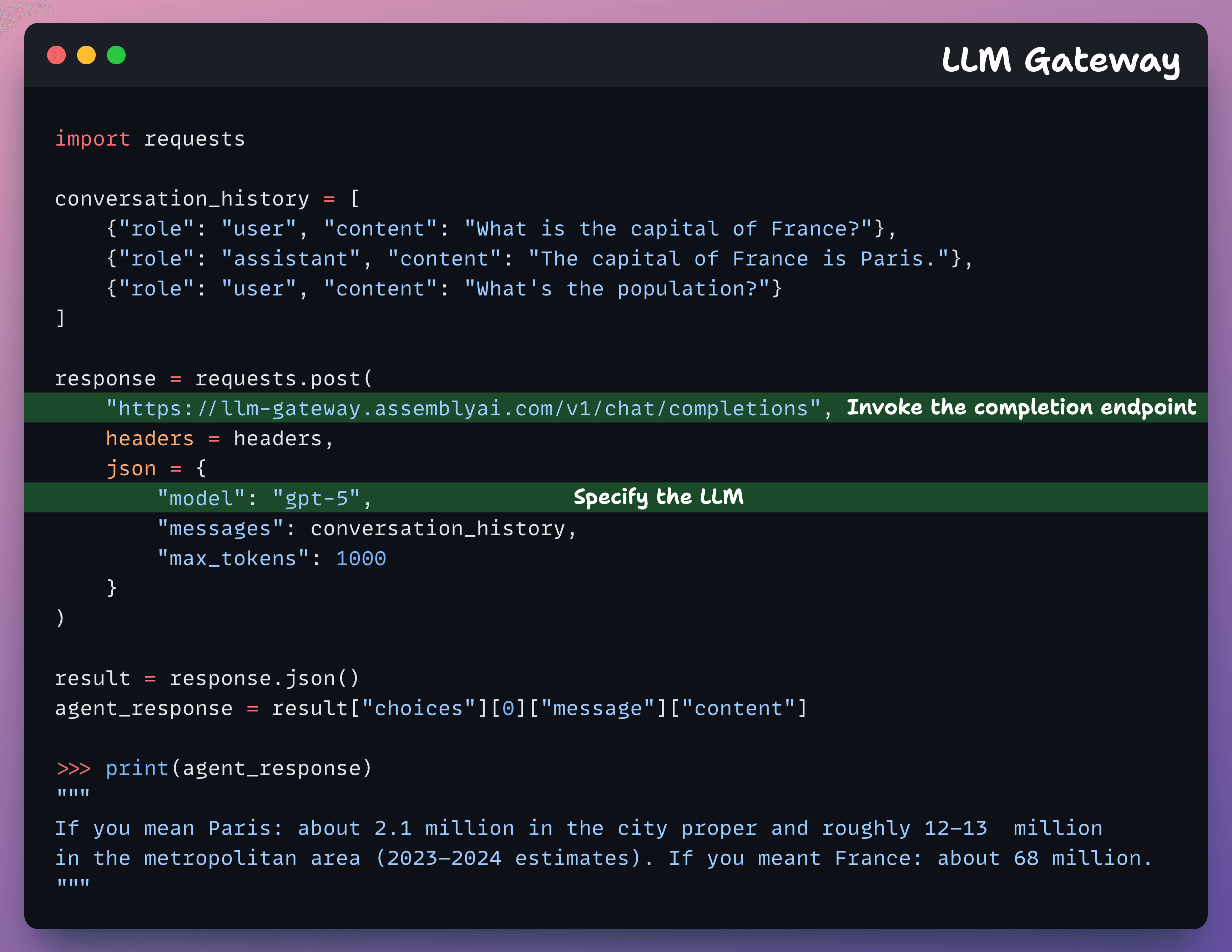
This way, you can:
Apply LLMs to audio files
Ask questions about your audio data
Build Agentic workflows
Do basic chat completions
Run multi-turn conversations
Execute tool calling
More about LLM Gateway in the docs here →
Ironically, we’ve had great speech recognition for years.
But most models stopped at transcription, and what we actually needed was understanding, since when people talk to machines, they expect understanding.
Nonetheless, every wave of AI (vision, text, or speech) has always started with basic capabilities before leaping into understanding.
Computer vision moved from detecting pixels to describing scenes.
Language models moved from predicting words to generating reasoning chains.
And now, voice AI has gone from transcription to comprehension.
AssemblyAI is turning transcriptions into a full-blown voice intelligence layer.
For instance, Universal-2 is now giving higher-quality speech-to-text with significant improvements:

It can automatically detect speech in 99 languages.
It supports automatic code-switching between English and other languages.
It now has 64% lower speaker counting errors in speech data.
You can get started with Assembly here: AssemblyAI.
Also, their API docs are available here if you want to explore their services: AssemblyAI API docs.
🙌 Also, a big thanks to AssemblyAI, who very kindly partnered with us today!
👉 Over to you: What would you use AssemblyAI for?
Thanks for reading!