
Fine-tuning Gemma 3 270M Locally
A step towards hyper-efficient local AI

Building production-grade software just got simpler
Factory 1.5 has introduced a fully redesigned Session interface, simplified to reduce friction and keep you in control.
It supports three different phases of your work with Droids:
Specification: Distraction-free, chat-only scoping.
Management: Full context view without breaking review flow.
Review: Instant unified diffs, no folder hunting.
Start here, and also redeem your 10M FREE GPT-5 tokens to build production-grade software here →
Thanks to Factory for partnering today!
Fine-tuning Gemma 3 270M Locally
Google released Gemma 3 270M, a new model for hyper-efficient local AI!
You can run it locally on just 0.5 GB RAM.
Today, let’s learn how to fine-tune this model and make it smart at playing chess and predicting the next move.
Our tech stack:
Unsloth for efficient fine-tuning.
HuggingFace transformers to run it locally.
Load the model
We start by loading the Gemma 3 270M and its tokenizer using Unsloth.

Define LoRA config
We'll use LoRA for efficient fine-tuning.
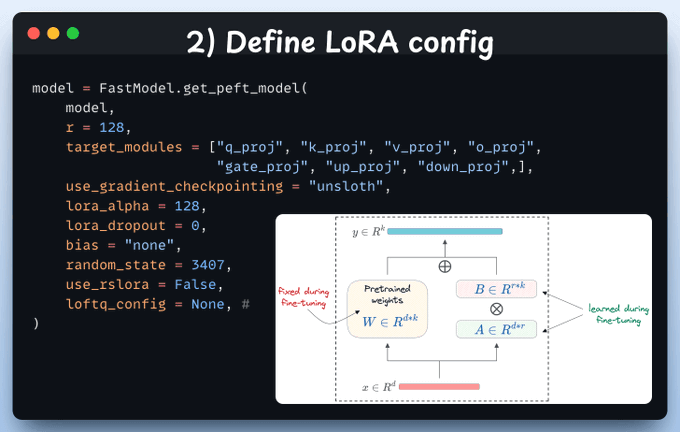
To do this, we use Unsloth's PEFT and specify:
The model
LoRA low-rank (r)
Layers for fine-tuning (target_modules)
Load dataset
We'll fine-tune Gemma 3 to make it extremely smart at playing chess.
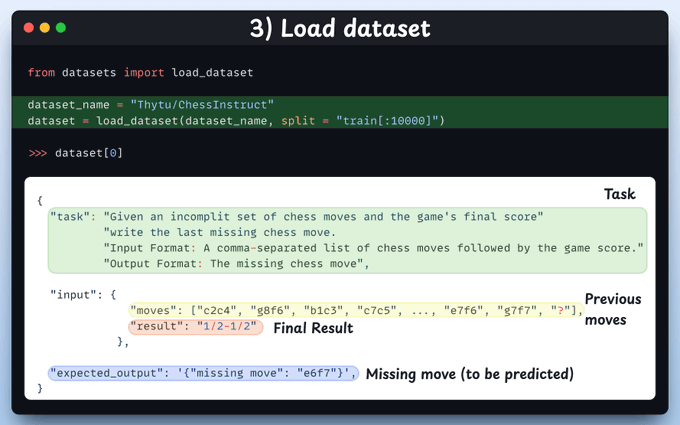
Given a set of previous moves (one move missing) & the final result, it has to predict the missing move.
In order to do this, we're using the ChessInstruct dataset from HuggingFace.
Prepare dataset
Next, we use a conversation-style dataset to fine-tune Gemma 3.

The standardize_data_formats method converts the dataset to the correct format for fine-tuning purposes!
Define Trainer
Here, we create a Trainer object by specifying the training config, like learning rate, model, tokenizer, and more.

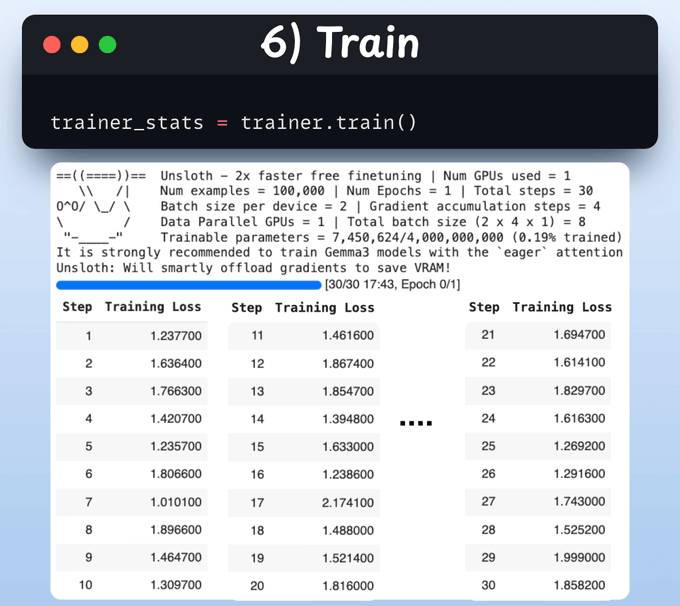
Train
With that done, we initiate training.
The loss is generally decreasing with steps, which means the model is being fine-tuned correctly.
Finally, this image shows prompting the LLM before and after fine-tuning:
After fine-tuning, the model is able to find the exact missing chess move instead of randomly generating some moves.
That was simple, wasn’t it?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.
This code has errors and there is missing code to make it work. Is there any GitHub repo with the right and complete code?