
FireDucks with Seaborn
Speed + Seamless third-party integration.

Cartesia Sonic 2.0: Build Real-Time Voice AI Agents
Cartesia just launched industry-leading voice models featuring 40ms latency and best-in-class voice quality.

Get instant cloning with just 3 seconds of audio.
A voice changer for fine-grained control.
Audio infilling to generate personalized content at scale.
Join over 50k developers and build your voice product with Cartesia today →
Thanks to Cartesia for partnering today!
FireDucks with Seaborn
We have talked about FireDucks a few times before.
For starters, while Pandas is the most popular DataFrame library, it is terribly slow.
It only uses a single CPU core.
It has bulky DataFrames.
It eagerly executes code, which prevents any possible optimization.
FireDucks is a highly optimized, drop-in replacement for Pandas with the same API.
You just need to change one line of code → 𝐢𝐦𝐩𝐨𝐫𝐭 𝗳𝗶𝗿𝗲𝗱𝘂𝗰𝗸𝘀.𝐩𝐚𝐧𝐝𝐚𝐬 𝐚𝐬 𝐩𝐝
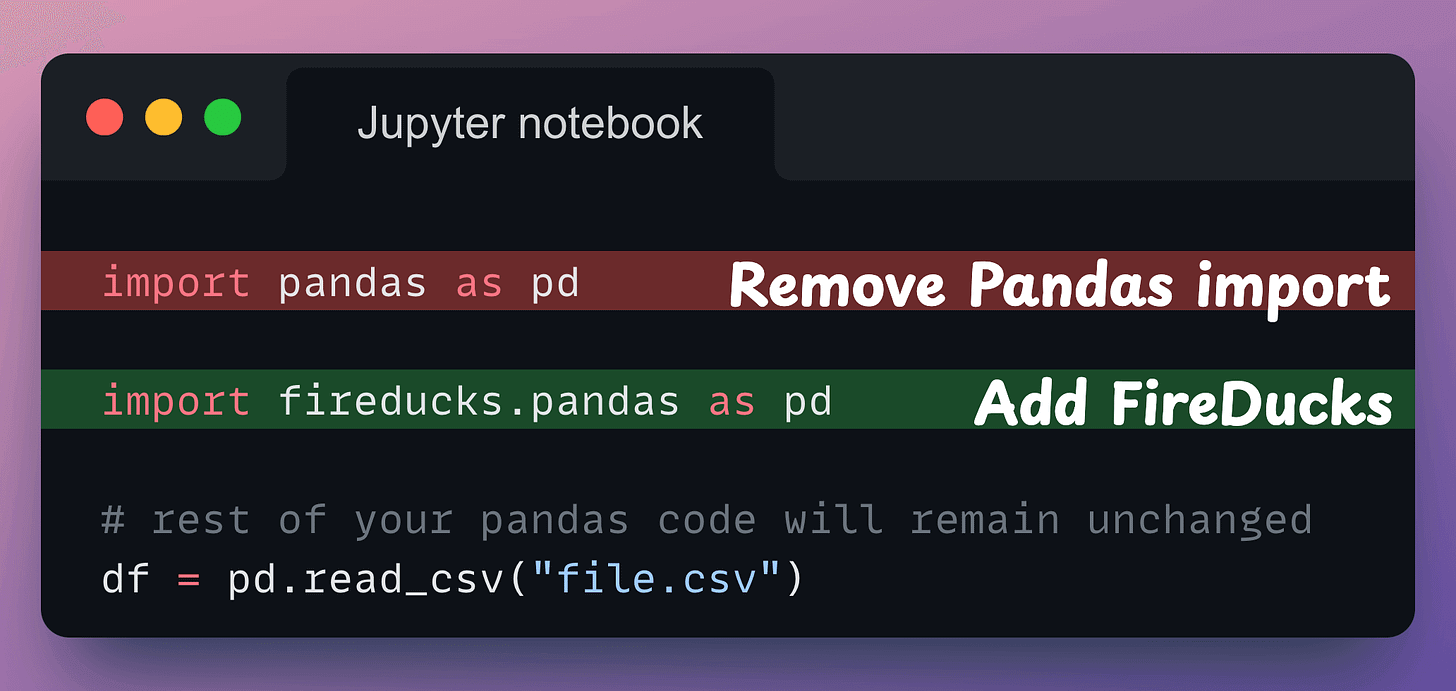
Done!
One thing we haven’t covered yet is its seamless integration with third-party libraries like Seaborn.
Let’s look at a quick demo below (here’s the Colab notebook with code).
We start by installing it:

Next, we download a sample dataset to work with.

Moving on, we load this data with Pandas and FireDucks:

Creating a correlation heatmap on the Pandas DataFrame takes 4.36 seconds:

Doing the same on FireDucks DataFrame takes over 60% less time:

Technically, Seaborn doesn't recognize a FireDucks DataFrame.
However, because of the import-hook (via %load_ext fireducks.pandas), FireDucks can be integrated seamlessly with a third-party library like Seaborn that expects a Pandas DataFrame.
And everything while accelerating the overall computation.
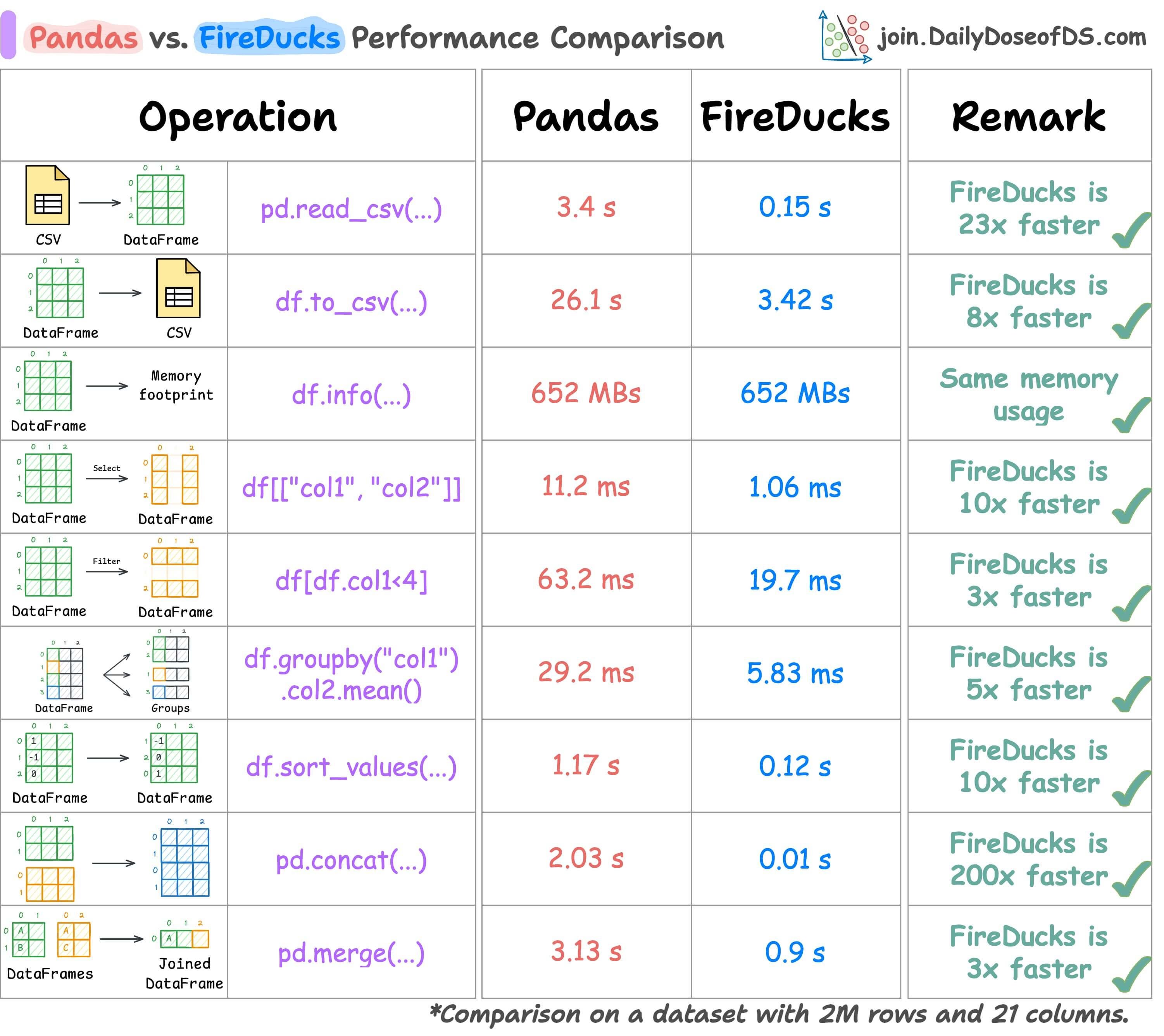
We have several benchmarking before and in all tests, FireDucks comes out to be the fastest:
Here's Pandas and FireDucks head-to-head on several common tabular operations under eager evaluation.
Here's Pandas vs. cuDF (a GPU DataFrame library):

And here's FireDucks vs. Pandas vs. DuckDB vs. Polars:

In all cases, FireDucks is the fastest.
You can find the Colab notebook for Seaborn integration here →
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.