
Focal Loss vs. Binary Cross Entropy Loss
Which one to prefer?

Binary classification tasks are typically trained using the binary cross entropy (BCE) loss function:

For notational convenience, if we define pₜ as the following:
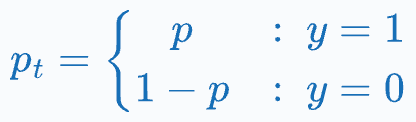
…then we can also write the cross-entropy loss function as:

That said, one overlooked limitation of BCE loss is that it weighs probability predictions for both classes equally, which is also evident from the symmetry of the loss function:

For more clarity, consider the table below, which depicts two instances, one from the minority class and another from the majority class, both with the same loss value:
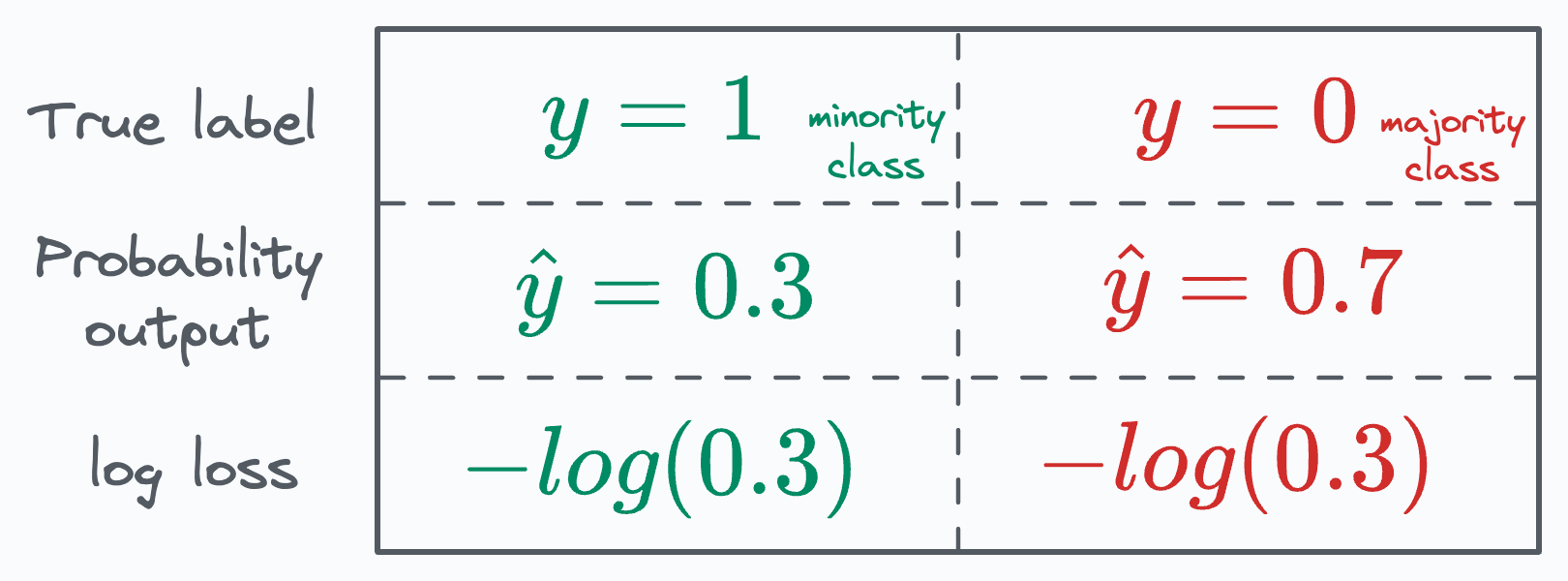
This causes problems when we use BCE for imbalanced datasets, wherein most instances from the dominating class are “easily classifiable.”
Thus, a loss value of, say, -log(0.3) from the majority class instance should (ideally) be weighed LESS than the same loss value from the minority class.

Focal loss is a pretty handy and useful alternative to address this issue. It is defined as follows:

As depicted above, it introduces an additional multiplicative factor called downweighing, and the parameter γ (Gamma) is a hyperparameter.
Plotting BCE (class y=1) and Focal loss (for class y=1 and γ=3), we get the following curve:

As shown in the figure above, focal loss reduces the contribution of the predictions the model is pretty confident about.
Also, the higher the value of γ (Gamma), the more downweighing takes place, which is evident from the plot below:

Moving on, while the Focal loss function reduces the contribution of confident predictions, we aren’t done yet.
If we consider the focal loss function now, we notice that it is still symmetric like BCE:

To address this, we must add another weighing parameter (α), which is the inverse of the class frequency, as depicted below:
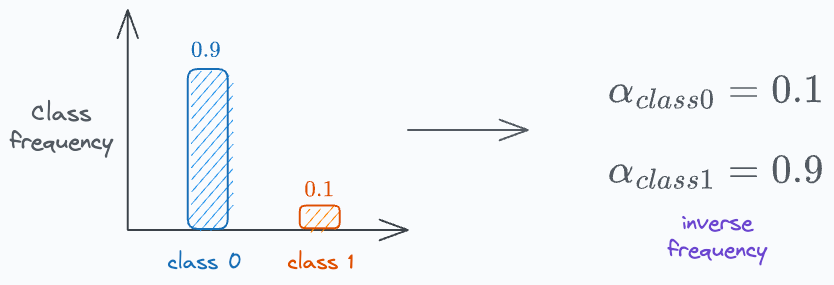
Thus, the final loss function comes out to be the following:

By using both downweighing and inverse weighing, the model gradually learns patterns specific to the hard examples instead of always being overly confident in predicting easy instances.
To test the efficacy of focal loss in a class imbalance setting, I created a dummy classification dataset with a 90:10 imbalance ratio:

Next, I trained two neural network models (with the same architecture of 2 hidden layers):
One with BCE loss
Another with Focal loss
The decision region plot and test accuracy for these two models is depicted below:

It is clear that:
The model trained with BCE loss (left) always predicts the majority class.
The model trained with focal loss (right) focuses relatively more on minority class patterns. As a result, it performs better.
The implementation along with several other techniques to robustify your ML models is available below:
👉 Over to you: What are some other alternatives to BCE loss under class imbalance?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 87,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
@avichawla, is it possible to share the code for the focal loss implementation with me please ?
Great post Avi, as always. I’m wondering if it would be possible to use focal lost together with xgboost in a multi label classification problem. Do you have any insights on this?