
Foundations of AI Engineering and LLMOps
The full LLMOps course (with code).

Last month, we concluded the MLOps course with 18 parts and started the LLMOps series.
Part 3 of the full LLMOps course is now available, where we further study the key components of LLMs, focusing on the attention mechanism, architectures like transformers and mixture-of-experts, and the fundamentals of pretraining and fine-tuning.
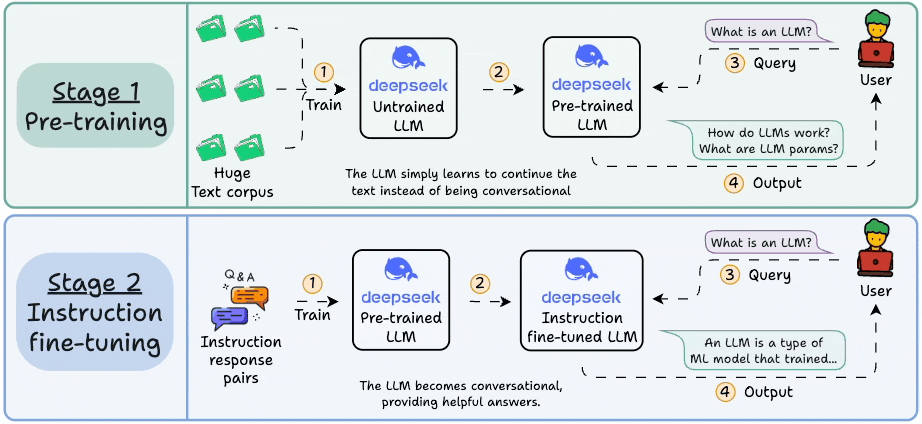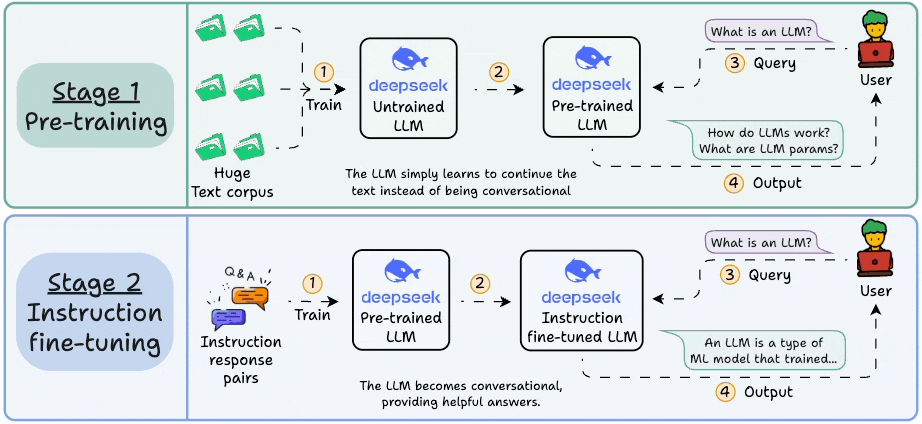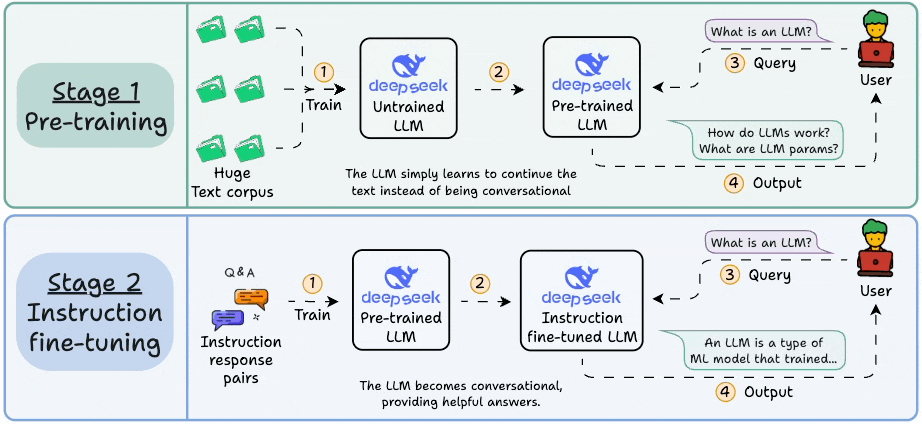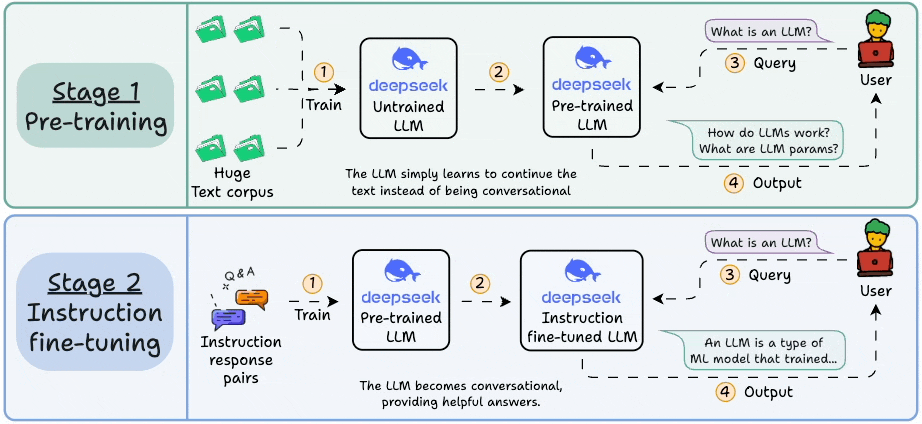
It also covers hands-on code demos to understand token prediction tasks and model behaviour in pretraining and fine-tuning.
While learning MLOps, we primarily explored traditional ML models and systems and learned how to take them from experimentation to production using the principles of MLOps.
But what happens when the “model” is no longer a custom-trained classifier, but a massive foundation model like Llama, GPT, or Claude?

Are the same principles enough?
Not quite.
Modern AI apps are increasingly powered by LLMs, which introduce an entirely new set of engineering challenges that traditional MLOps does not fully address.
This is where LLMOps come in.
It involves specialized practices for managing and maintaining LLMs and LLM-based applications in production, ensuring they remain reliable, accurate, secure, and cost-effective.
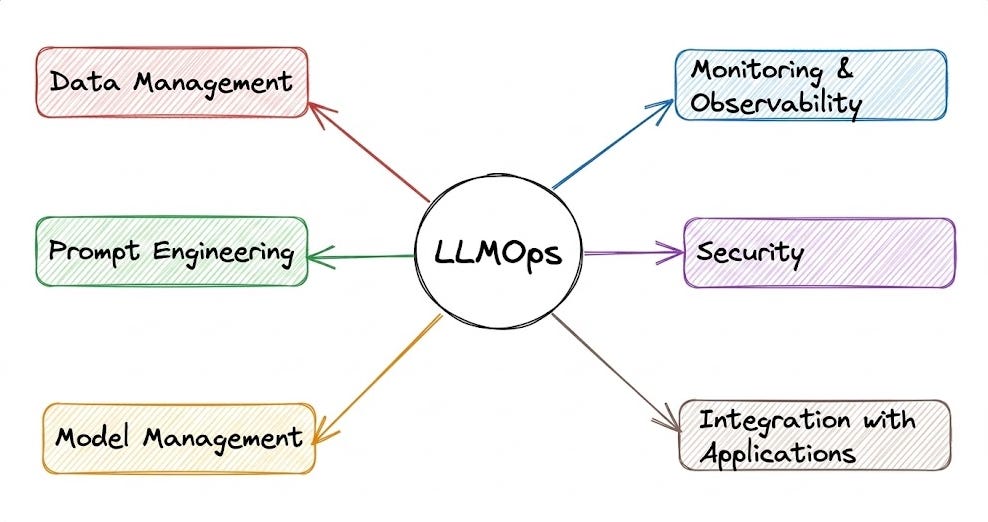
The aim is to provide you with a thorough explanation and systems-level thinking to build LLM apps for production settings.
Just like the MLOps course, each chapter will clearly explain necessary concepts, provide examples, diagrams, and implementations.
As we progress, we will see how we can develop the critical thinking required for taking our applications to the next stage and what exactly the framework should be for that.
👉 Over to you: What would you like to learn in the LLMOps course?
Thanks for reading!