
Foundations of AI Engineering and LLMOps
The full LLMOps blueprint (with code).

Recently, we concluded the MLOps crash course with 18 parts and started the LLMOps series.
Part 2 of the full LLMOps crash course is now available, which covers the core building blocks of LLMs, analyzing each component and stage in detail, like Tokenizers, Embeddings, Attention layers, Encoder-Decoder, and more.
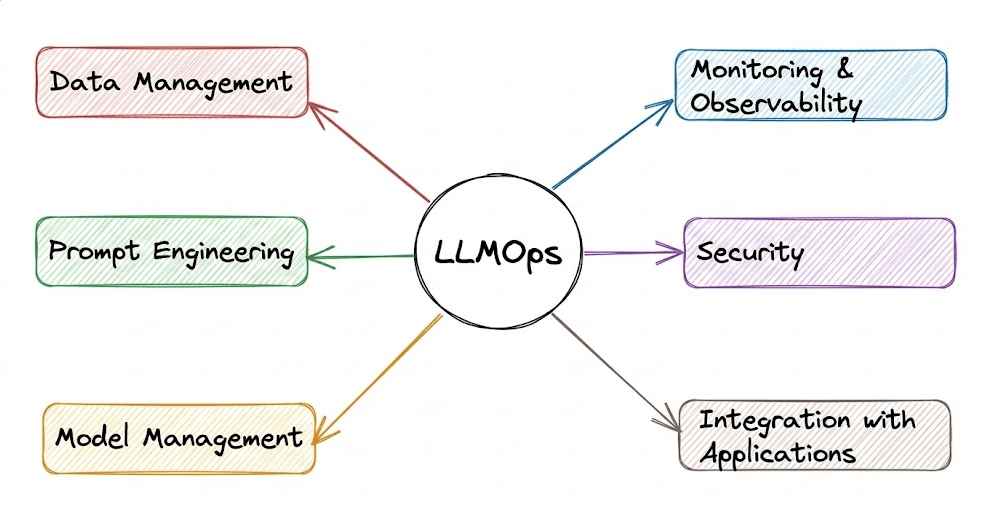
While learning MLOps, we primarily explored traditional ML models and systems and learned how to take them from experimentation to production using the principles of MLOps.
But what happens when the “model” is no longer a custom-trained classifier, but a massive foundation model like Llama, GPT, or Claude?

Are the same principles enough?
Not quite.
Modern AI apps are increasingly powered by LLMs, which introduce an entirely new set of engineering challenges that traditional MLOps does not fully address.
This is where LLMOps come in.
It involves specialized practices for managing and maintaining LLMs and LLM-based applications in production, ensuring they remain reliable, accurate, secure, and cost-effective.
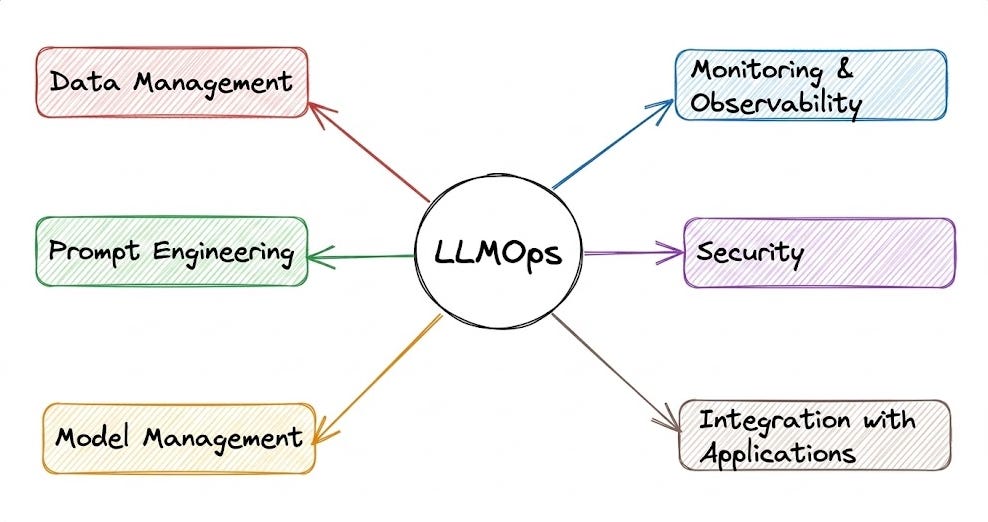
The aim is to provide you with a thorough explanation and systems-level thinking to build LLM apps for production settings.
Just like the MLOps crash course, each chapter will clearly explain necessary concepts, provide examples, diagrams, and implementations.
As we progress, we will see how we can develop the critical thinking required for taking our applications to the next stage and what exactly the framework should be for that.
👉 Over to you: What would you like to learn in the LLMOps crash course?
12 MCP, RAG, and Agents Cheat Sheets for AI Engineers
Here’s a recap of several visual summaries posted in the Daily Dose of Data Science newsletter.
1) Function calling & MCP for LLMs:
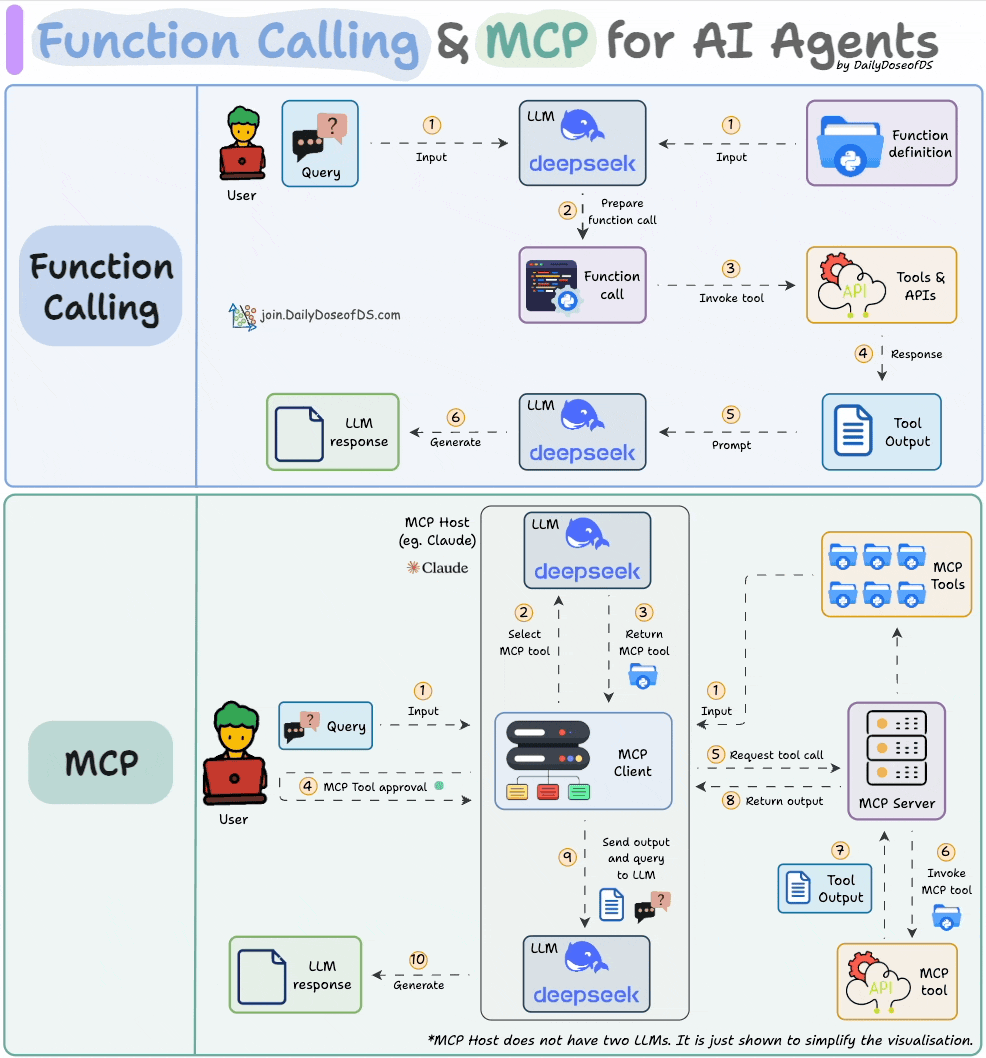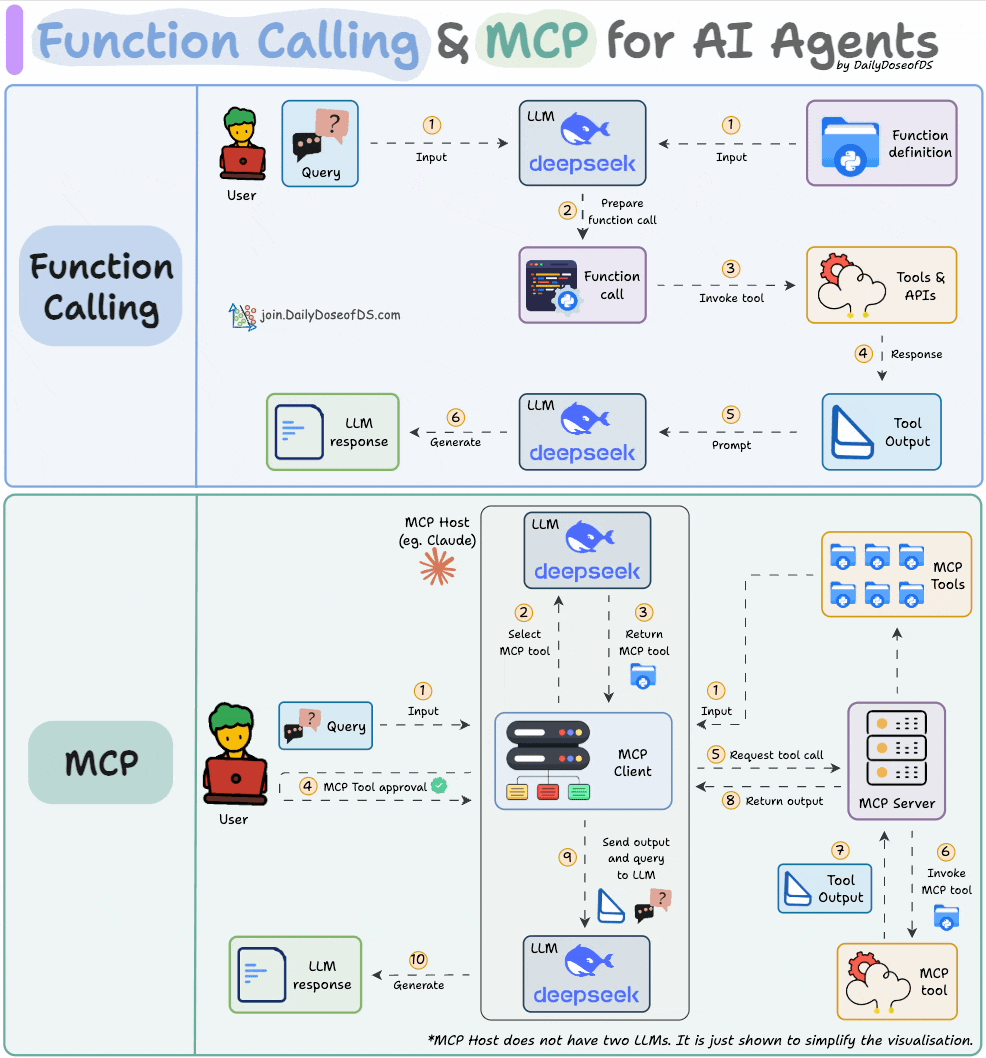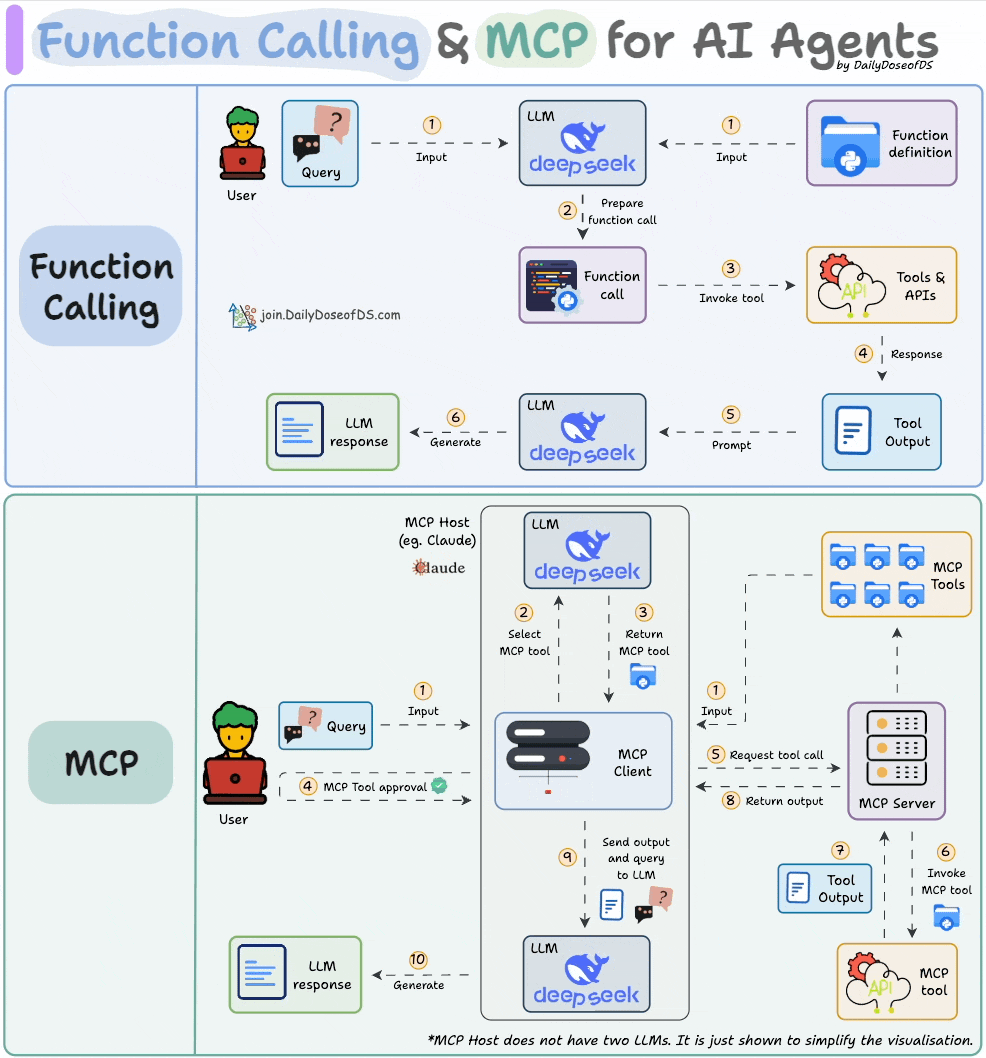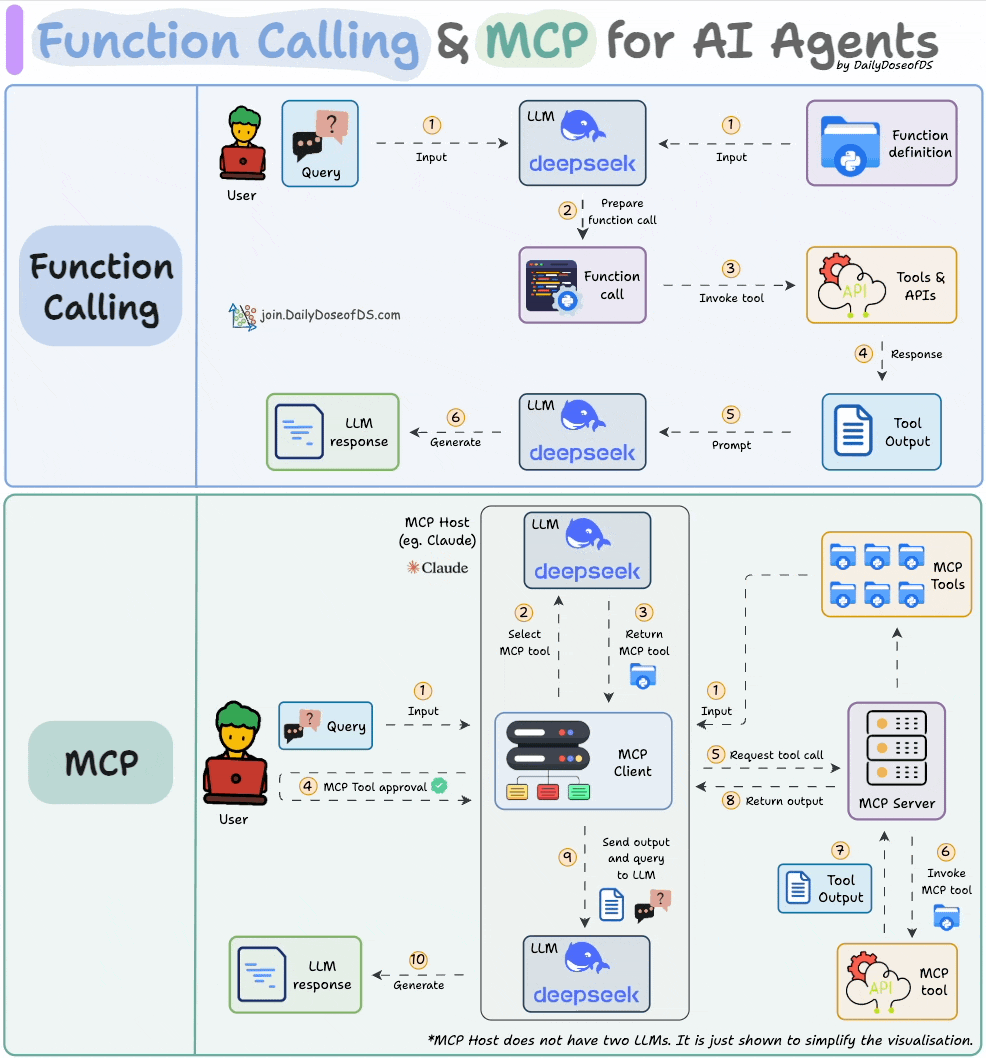
Before MCPs became popular, AI workflows relied on traditional Function Calling for tool access.
Now, MCP (Model Context Protocol) is introducing a shift in how developers structure tool access and orchestration for Agents.
2) 4 stages of training LLMs from scratch
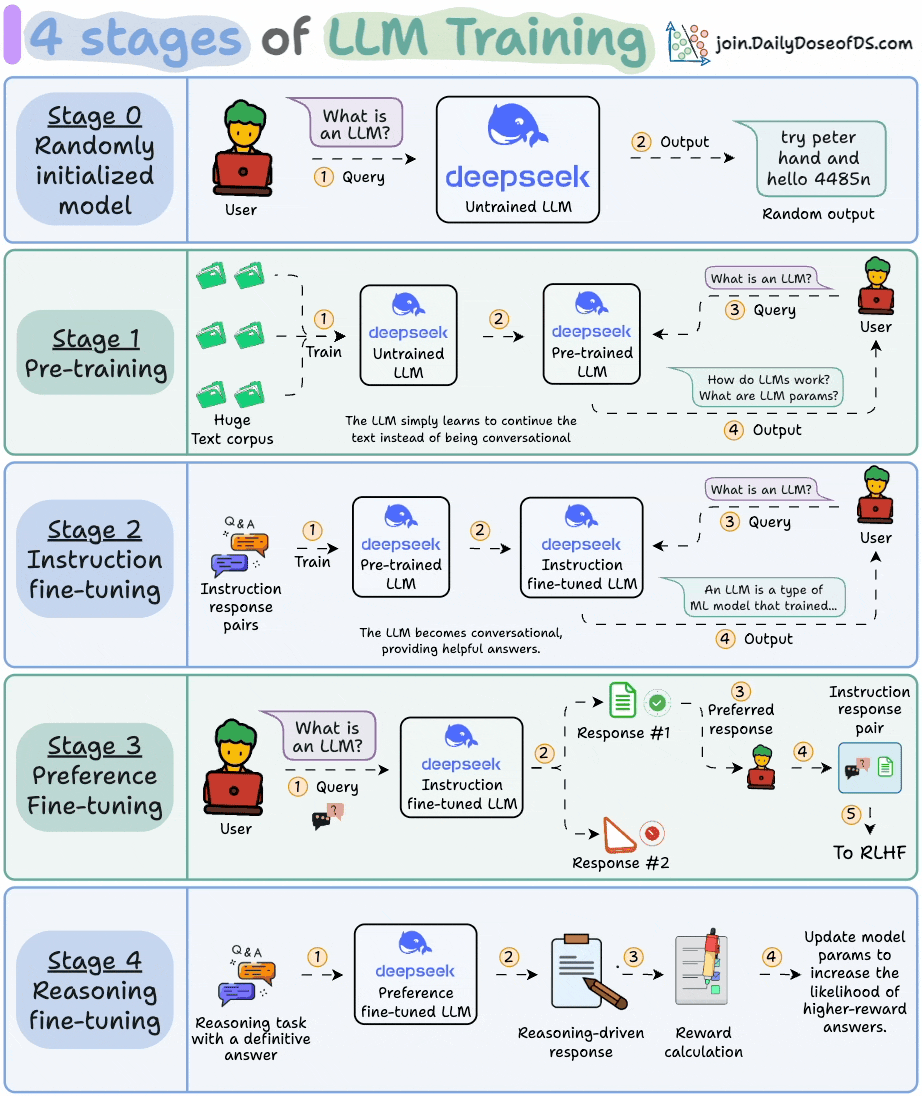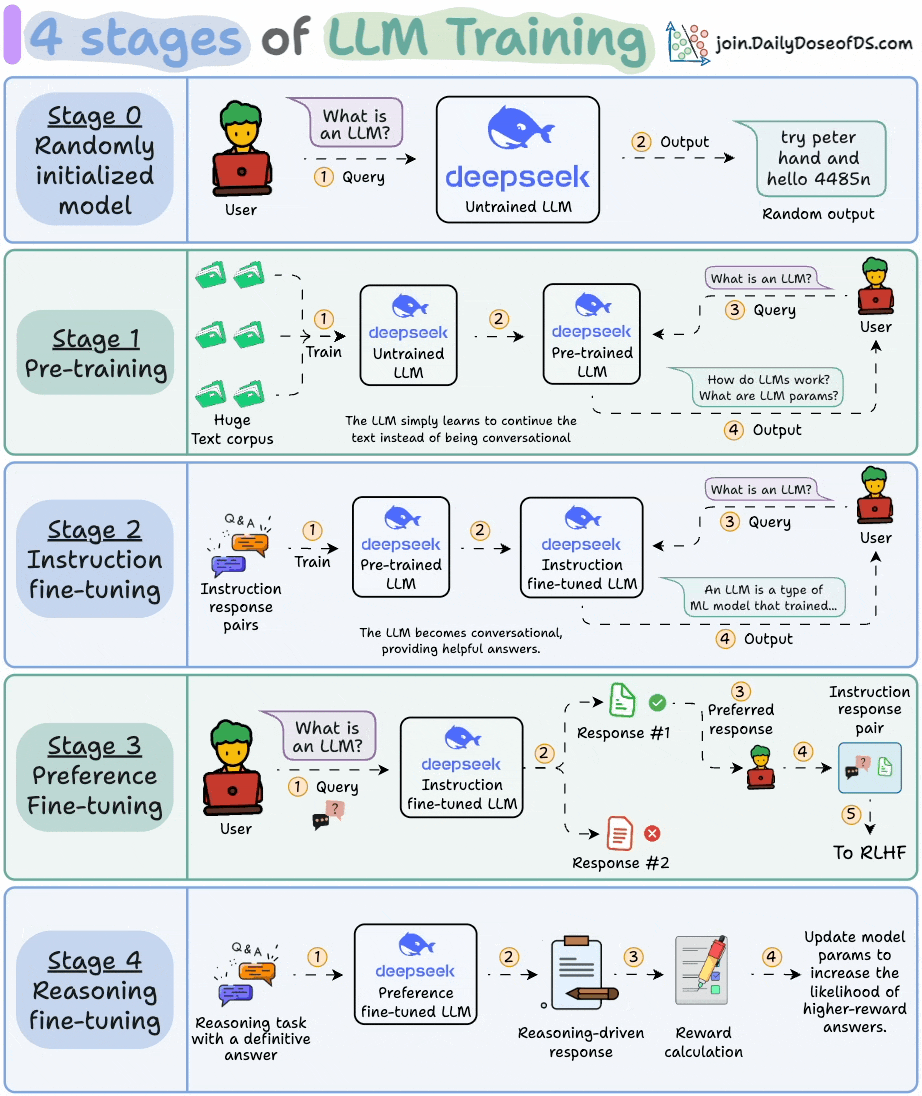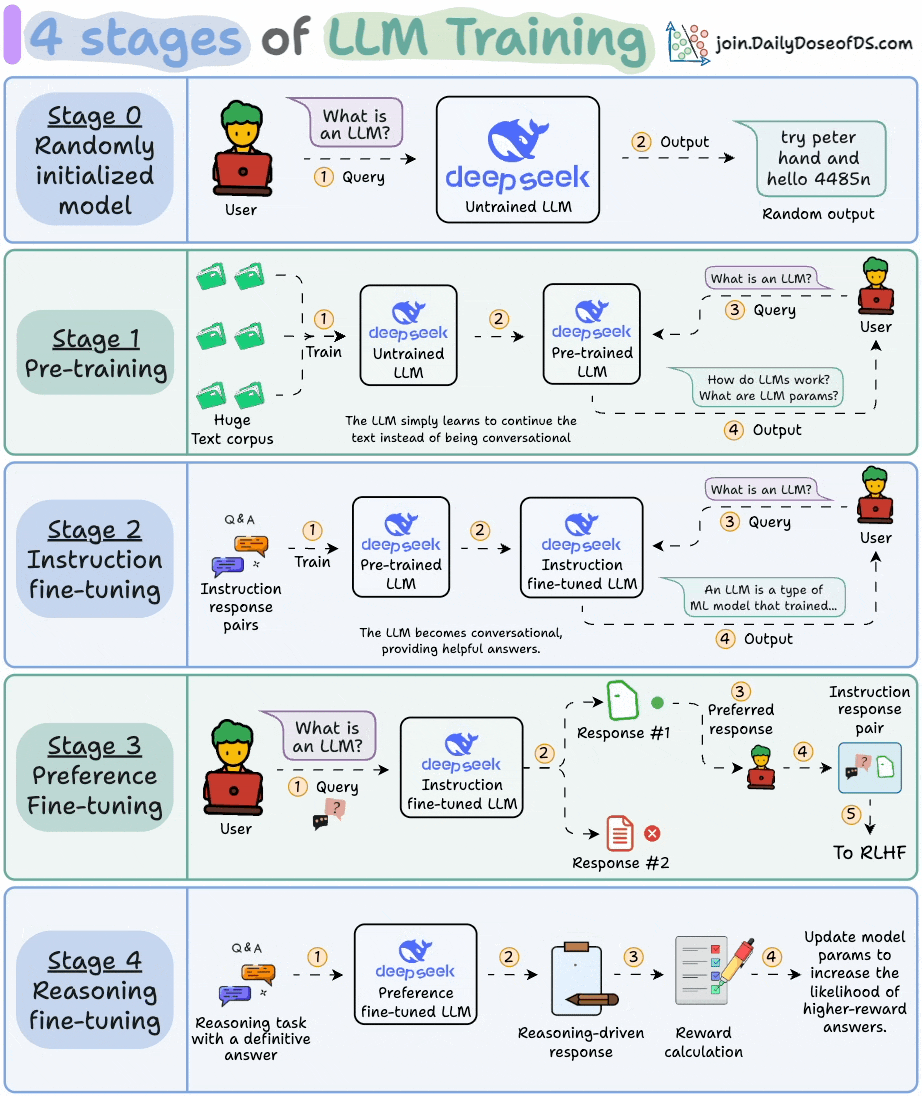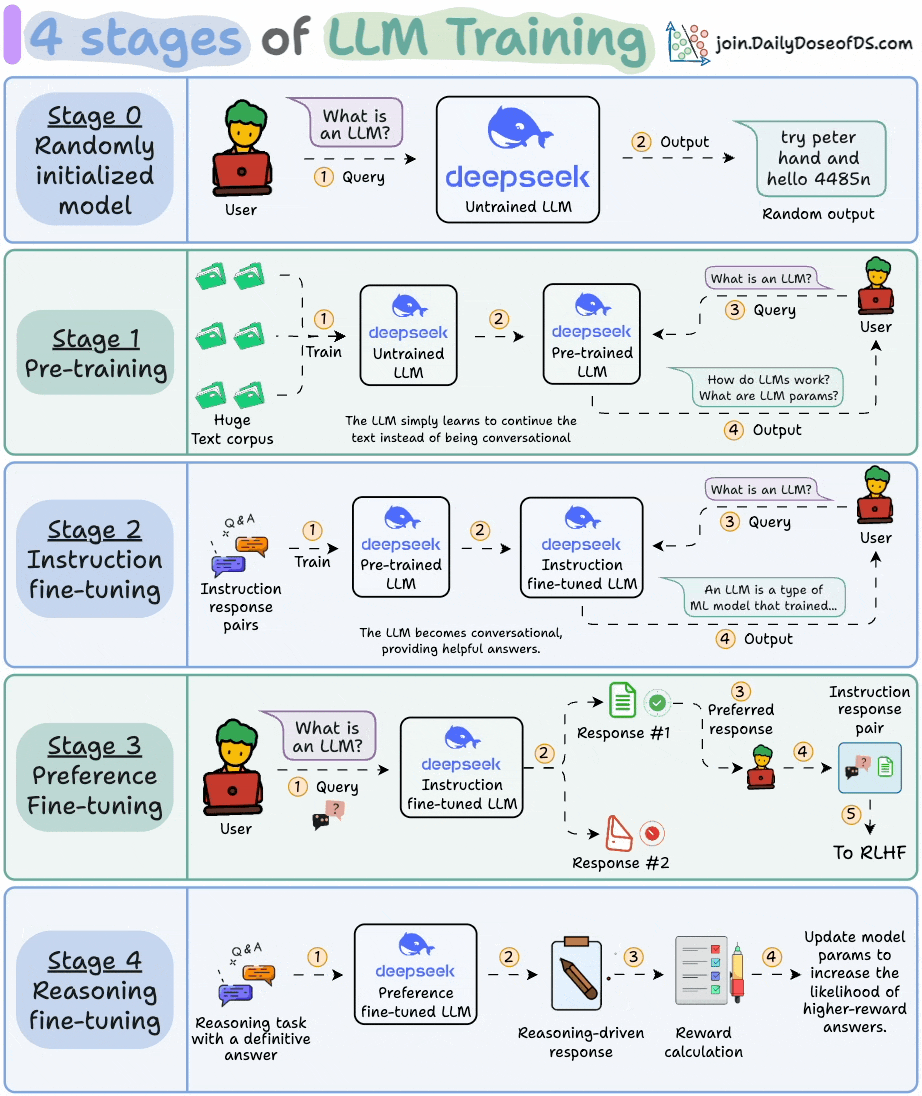
This visual covers the 4 stages of building LLMs from scratch that are used to make them applicable for real-world use cases.
These are:
Pre-training
Instruction fine-tuning
Preference fine-tuning
Reasoning fine-tuning
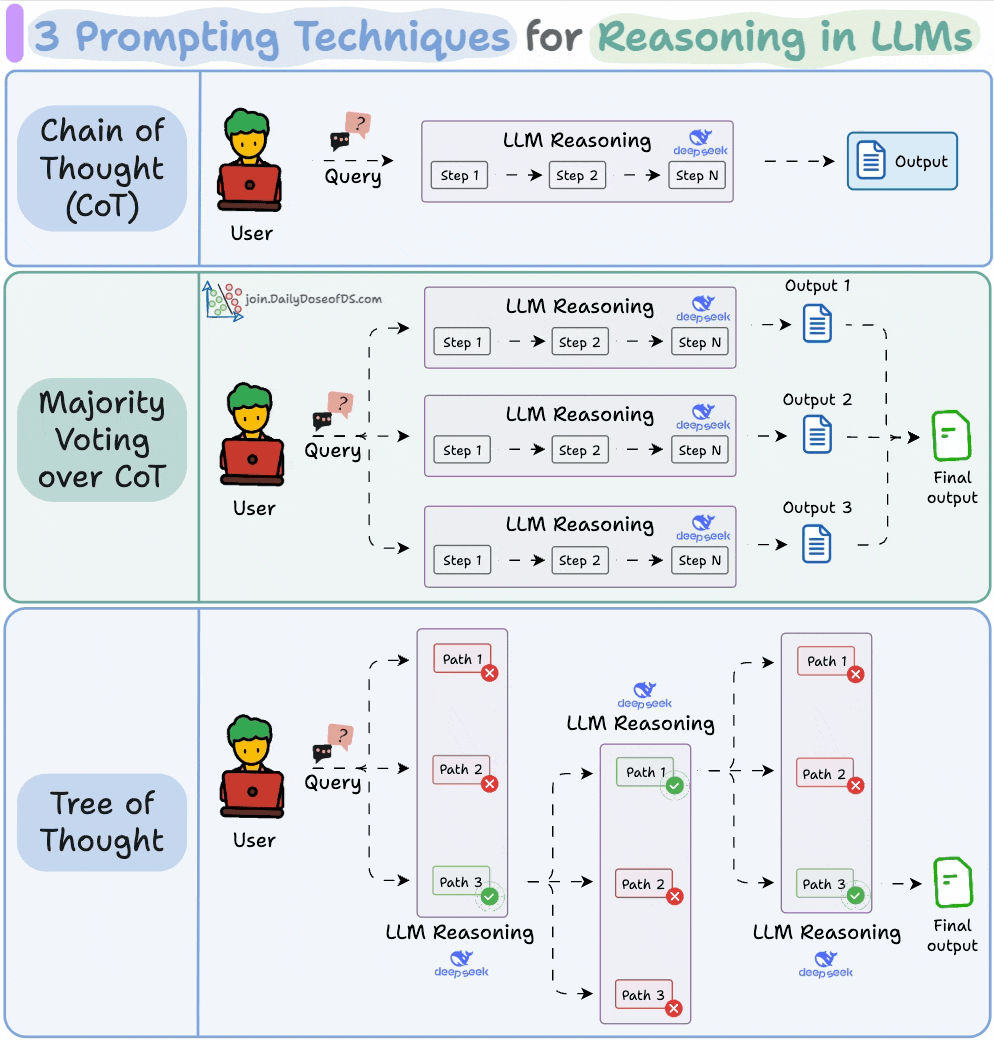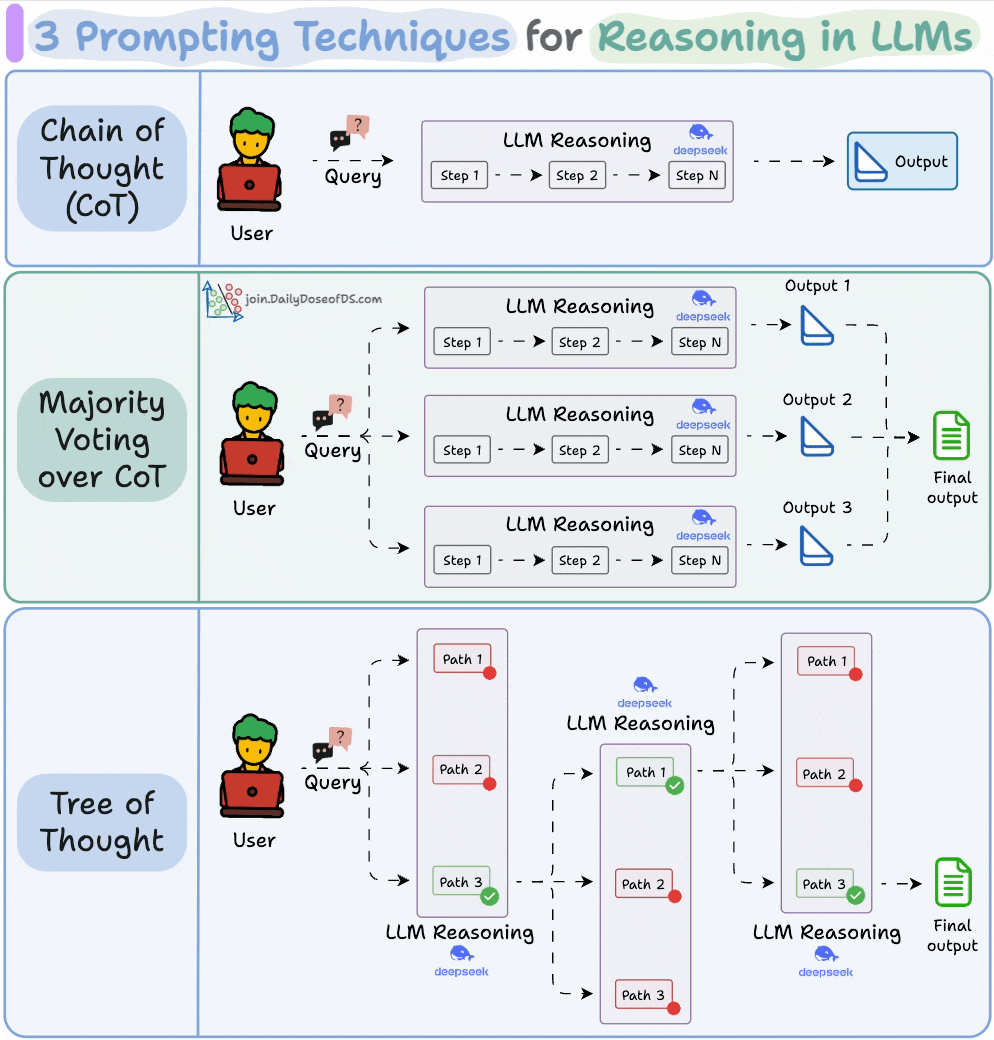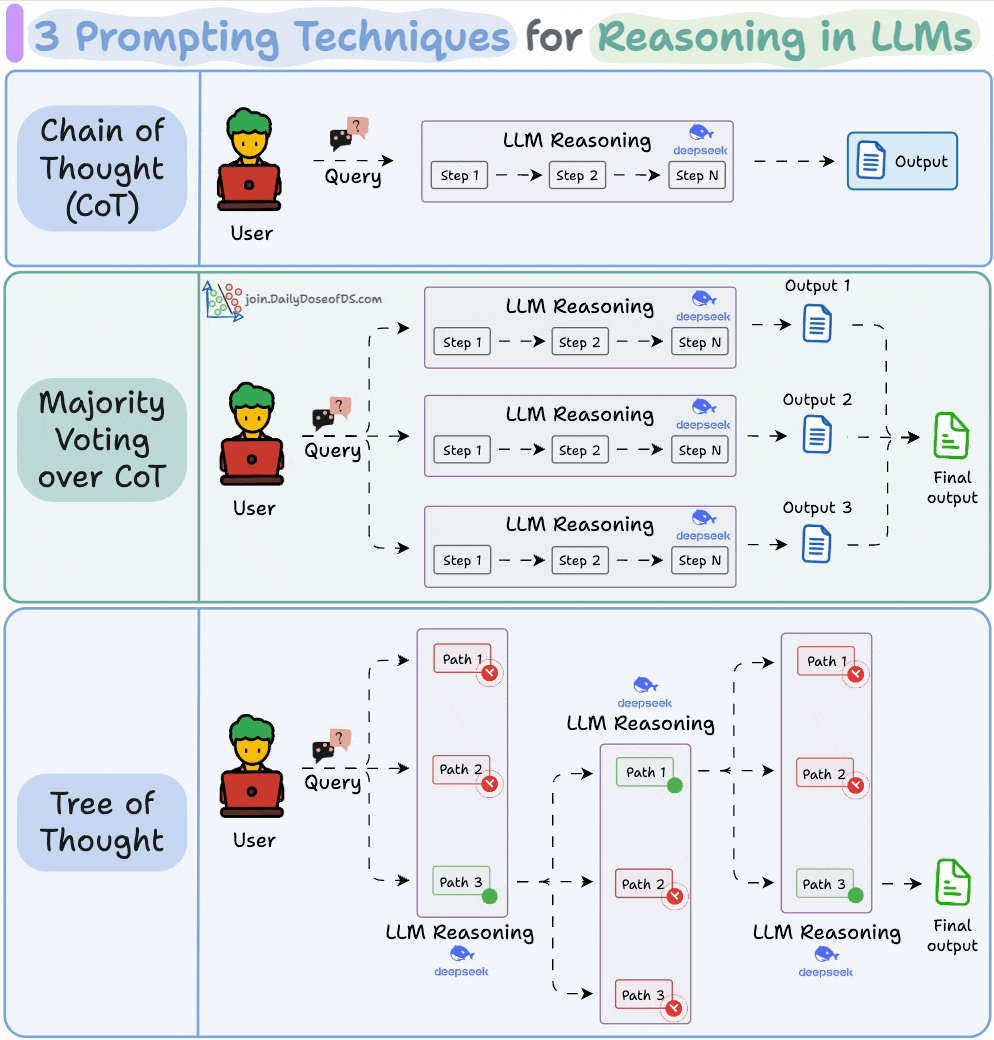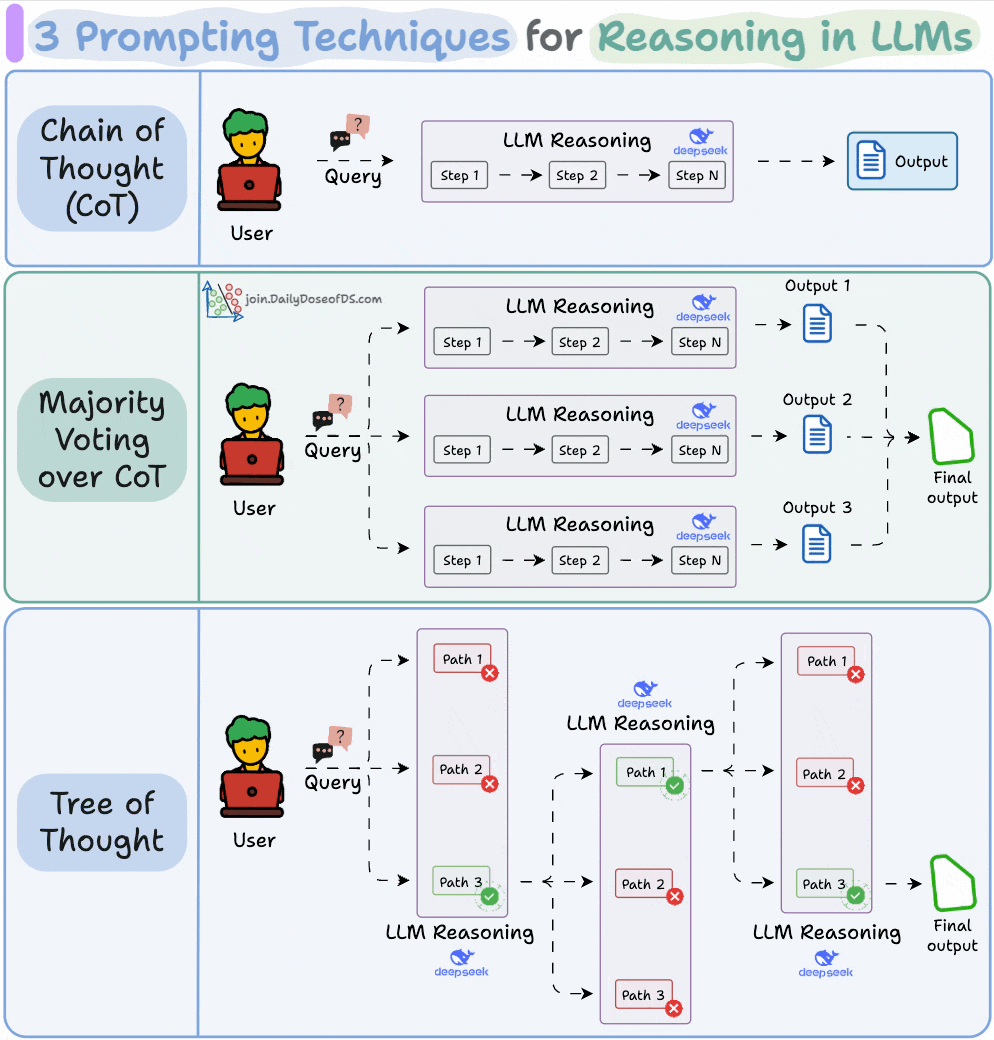
3) 3 prompting techniques for reasoning in LLMs
A large part of what makes LLM apps so powerful isn’t just their ability to predict the next token accurately, but their ability to reason through it.
This visual covers three popular prompting techniques that help LLMs think more clearly before they answer.
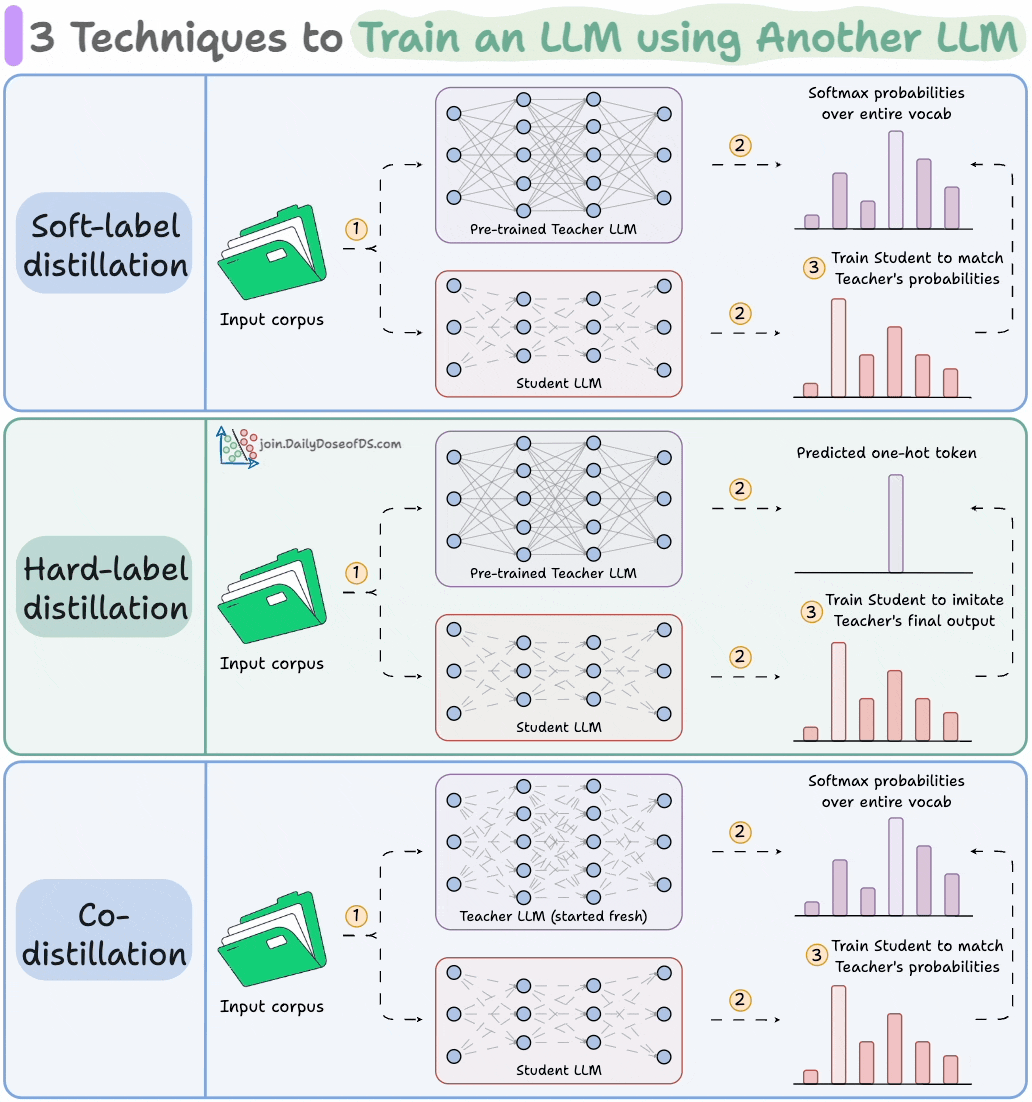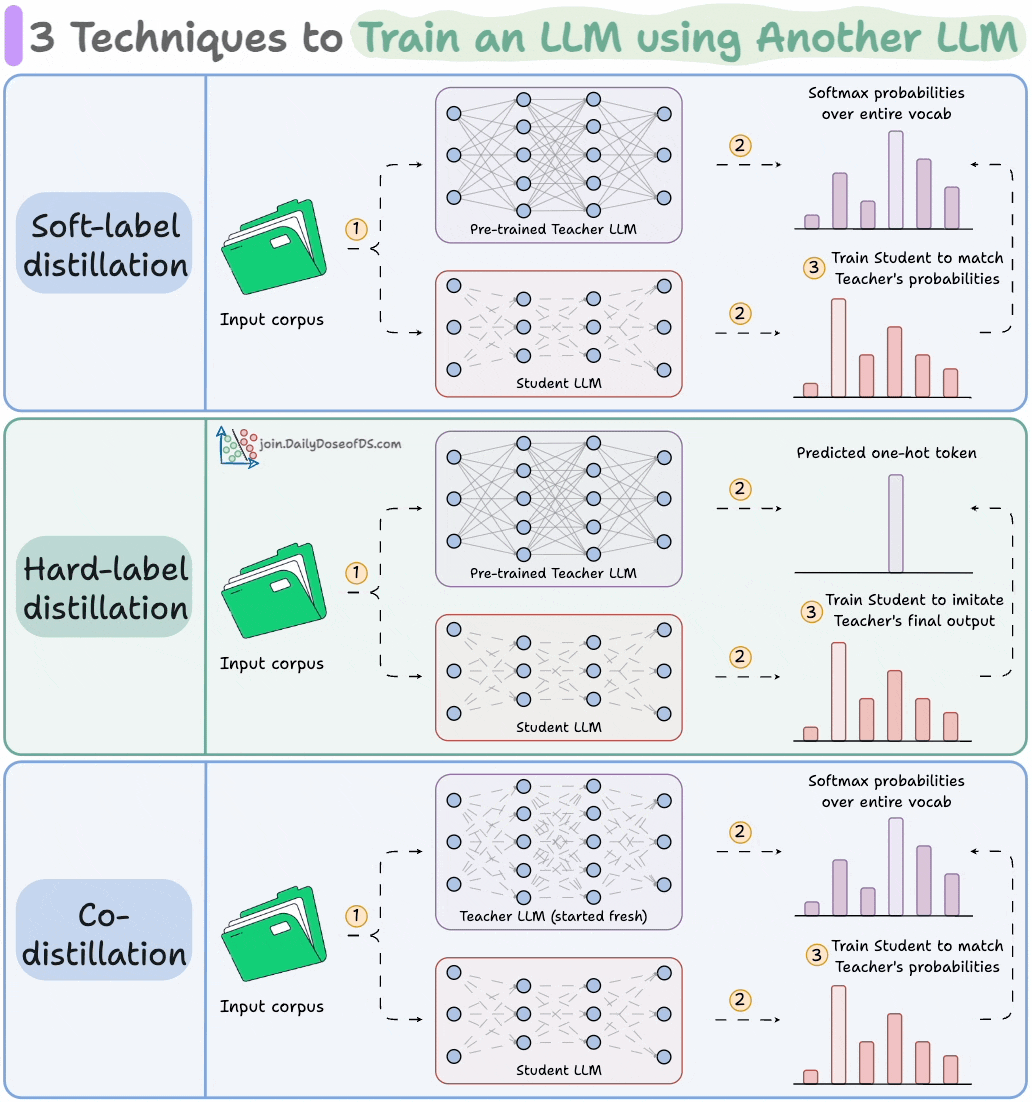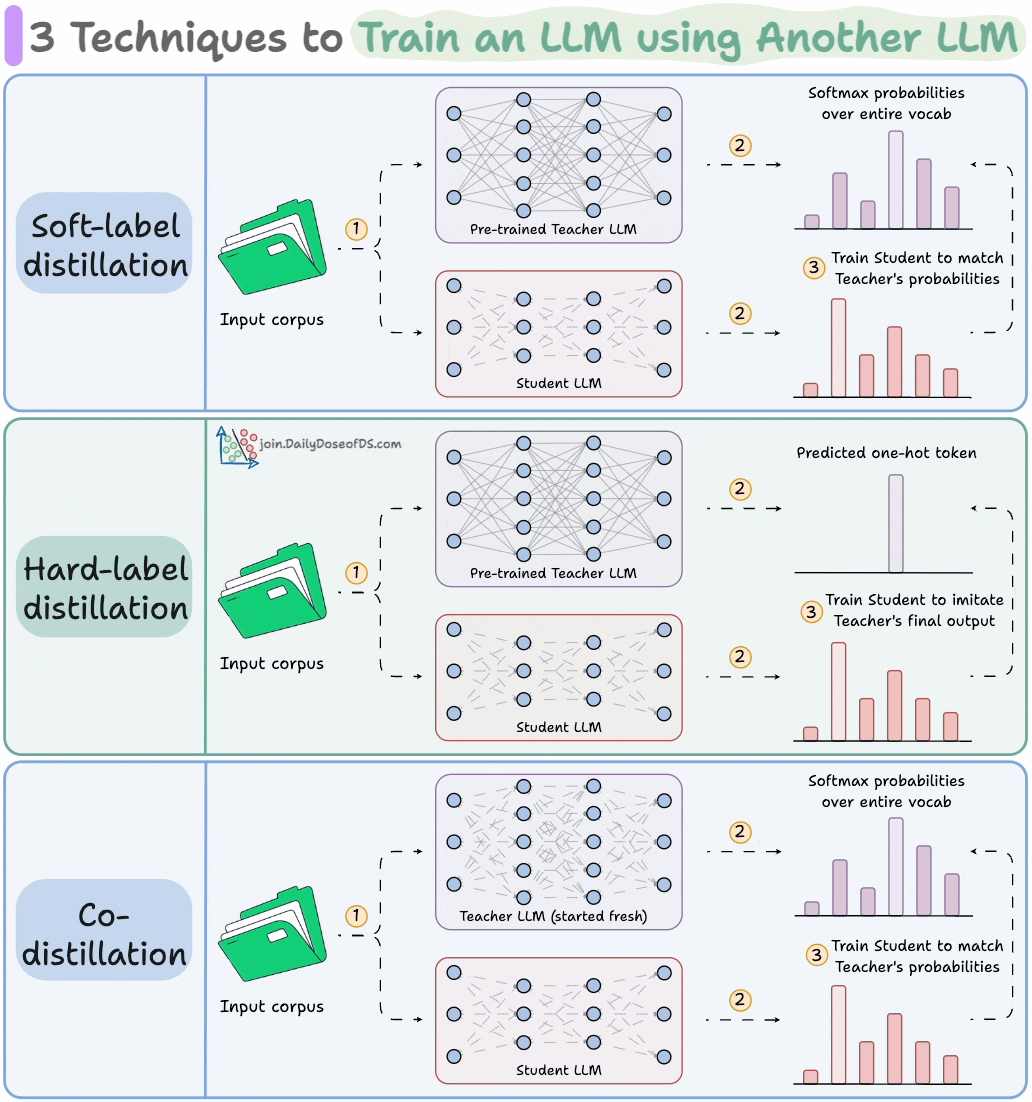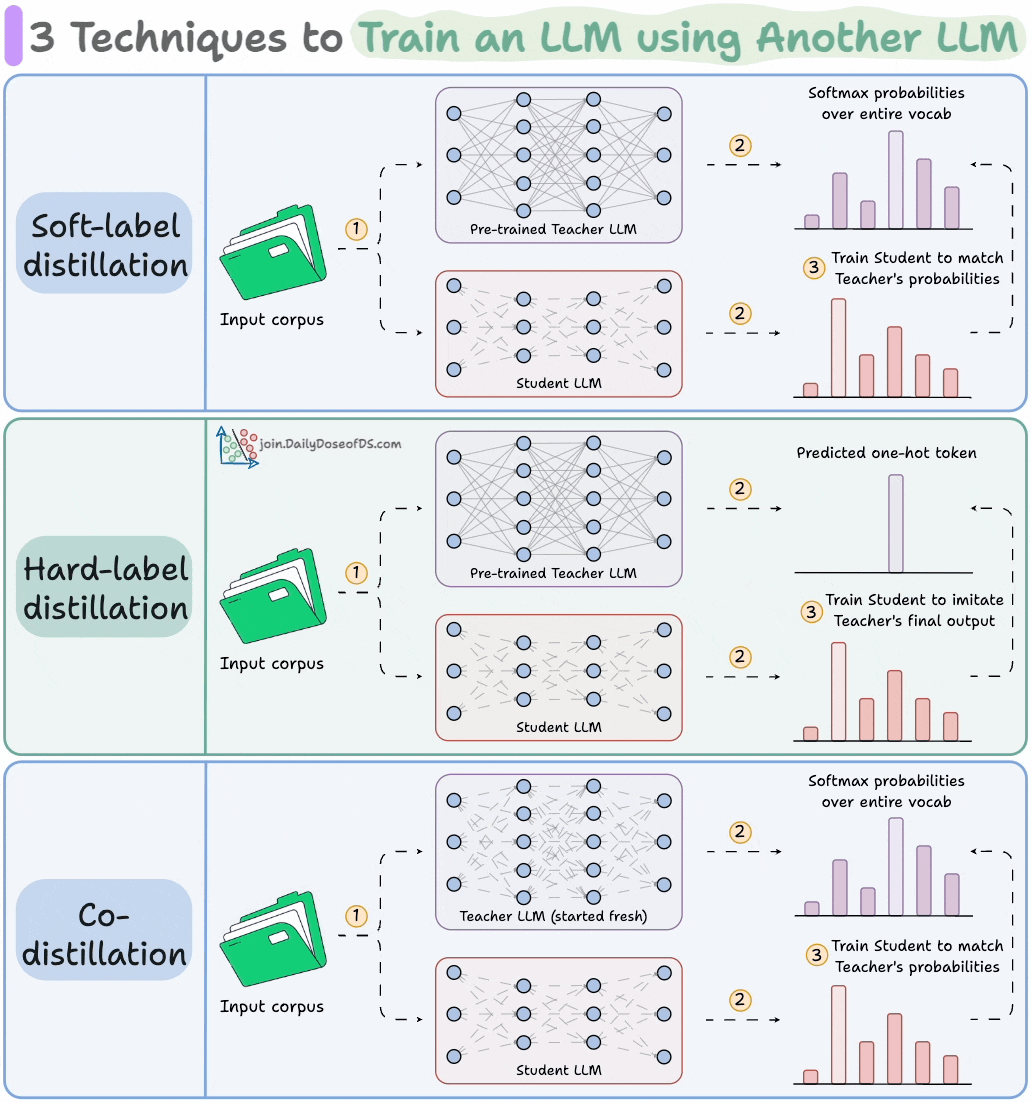
4) Train LLMs using other LLMs
LLMs don’t just learn from raw text; they also learn from each other:
Llama 4 Scout and Maverick were trained using Llama 4 Behemoth.
Gemma 2 and 3 were trained using Google’s proprietary Gemini.
Distillation helps us do so, and the visual below depicts three popular techniques.
5) Supervised & Reinforcement fine-tuning in LLMs
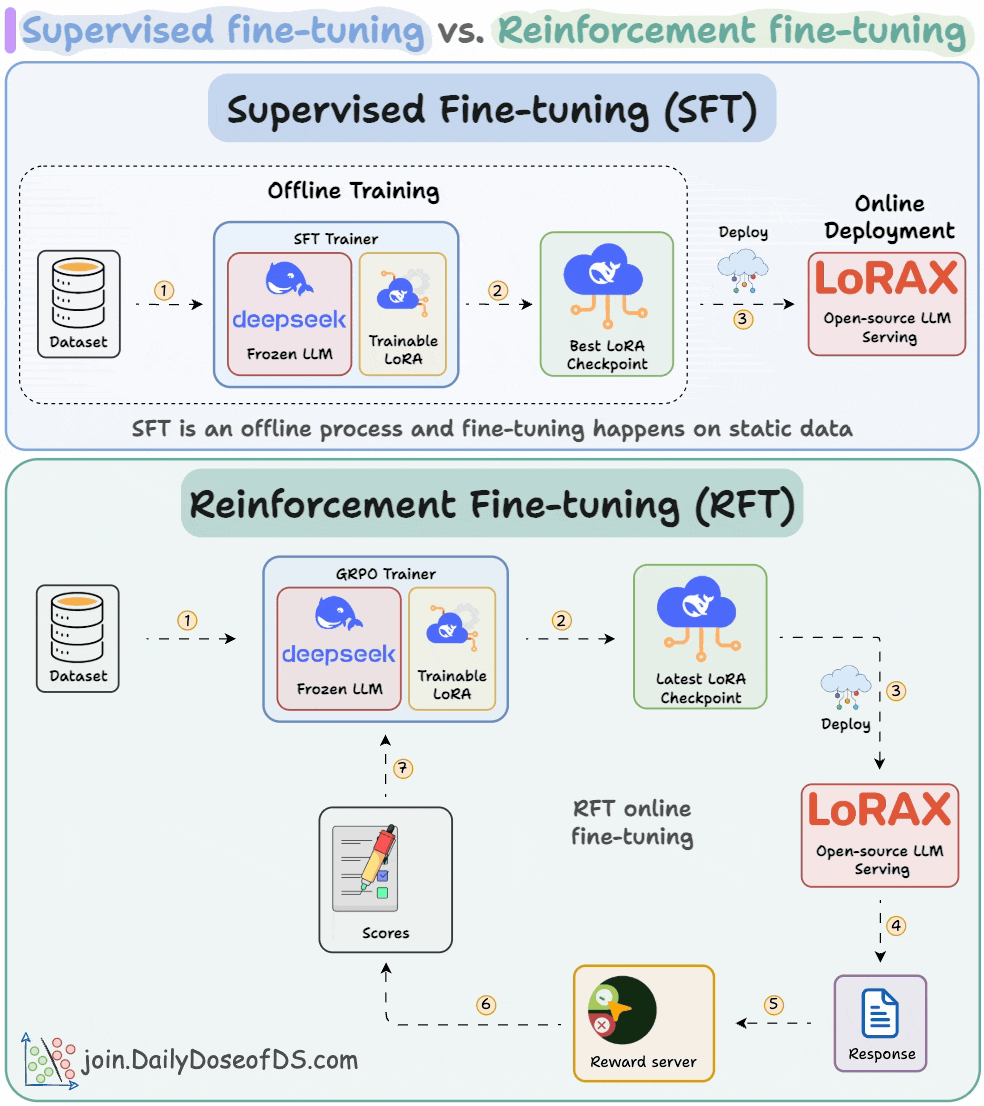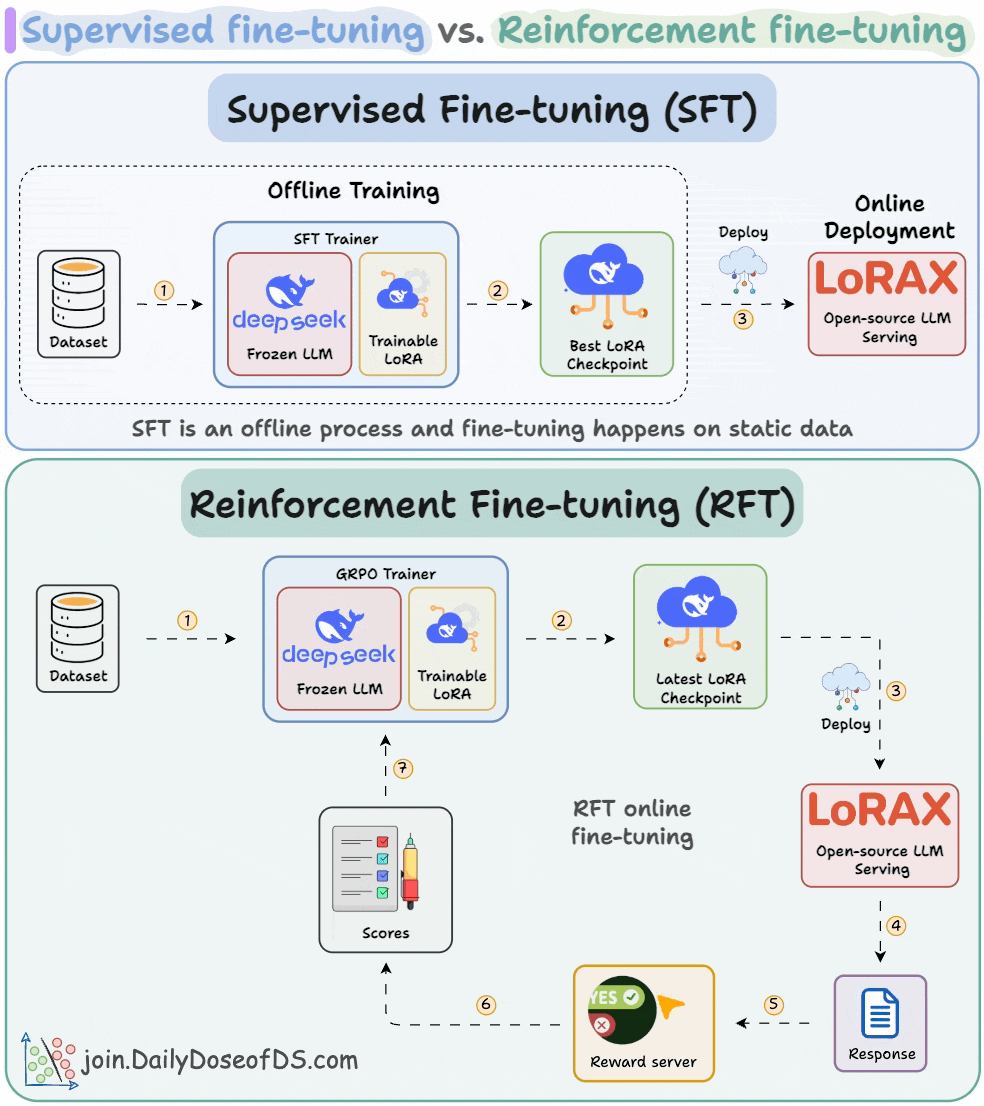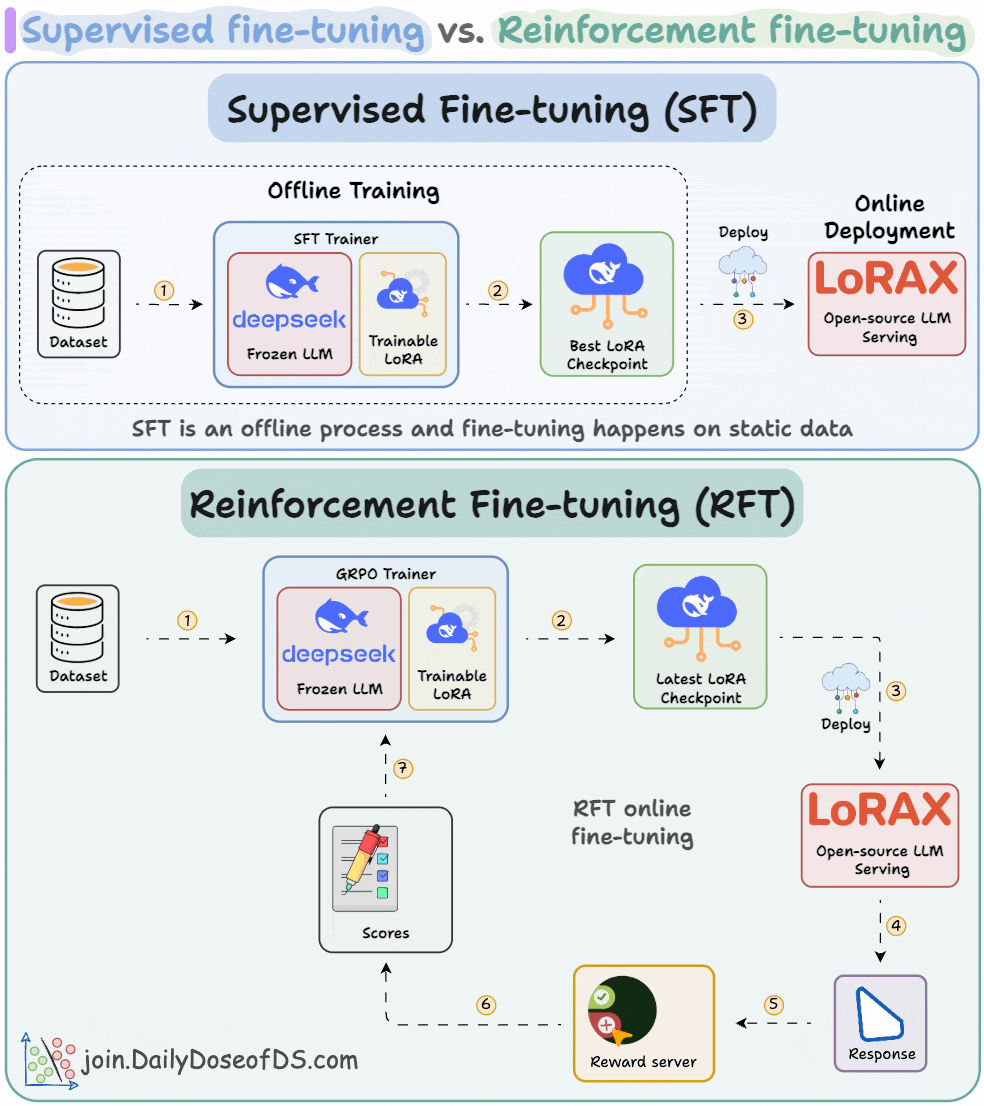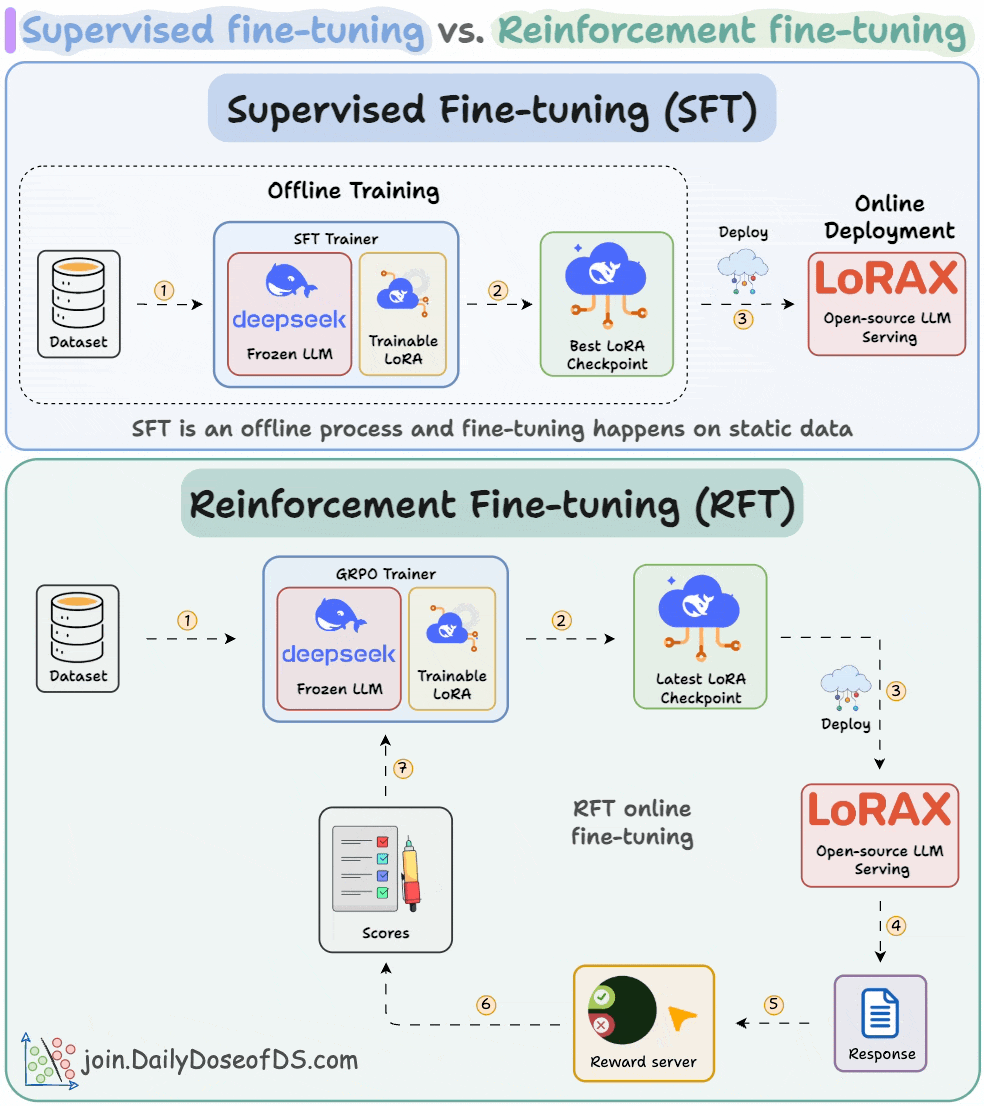
RFT lets us transform any open-source LLM into a reasoning powerhouse without any labeled data.
This visual covers the differences between supervised fine-tuning and reinforcement fine-tuning.
6) Transformer vs. Mixture of Experts
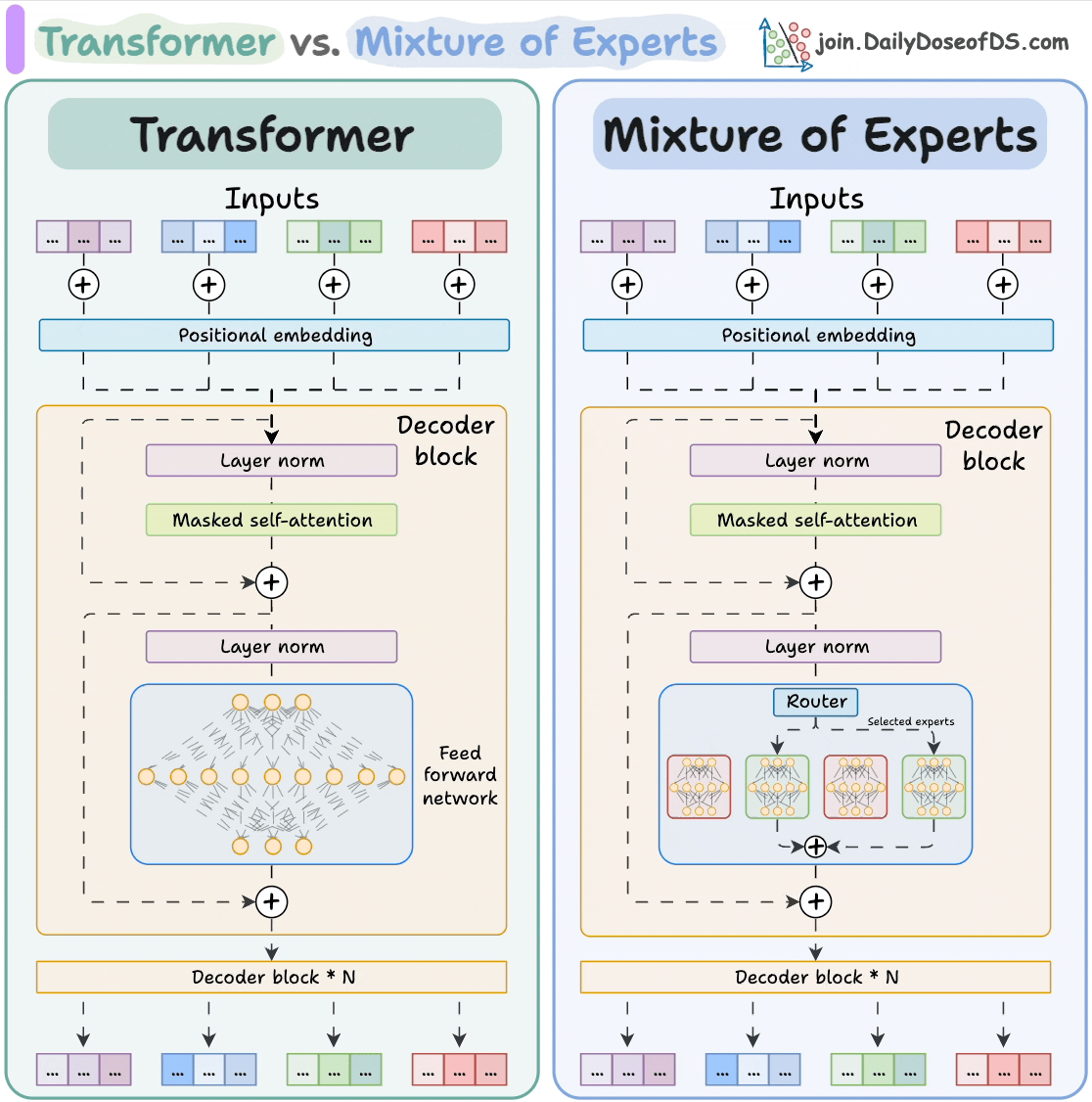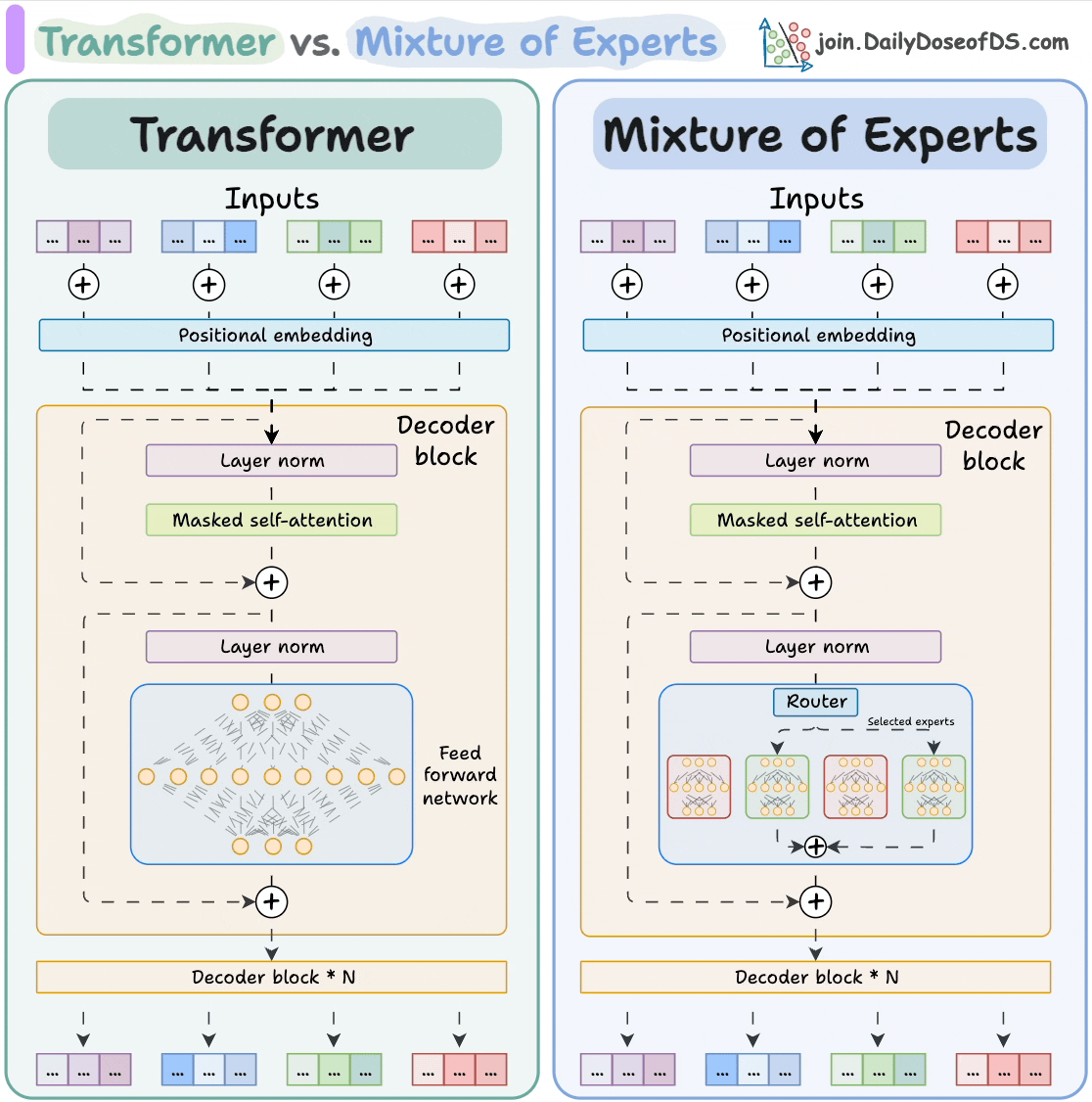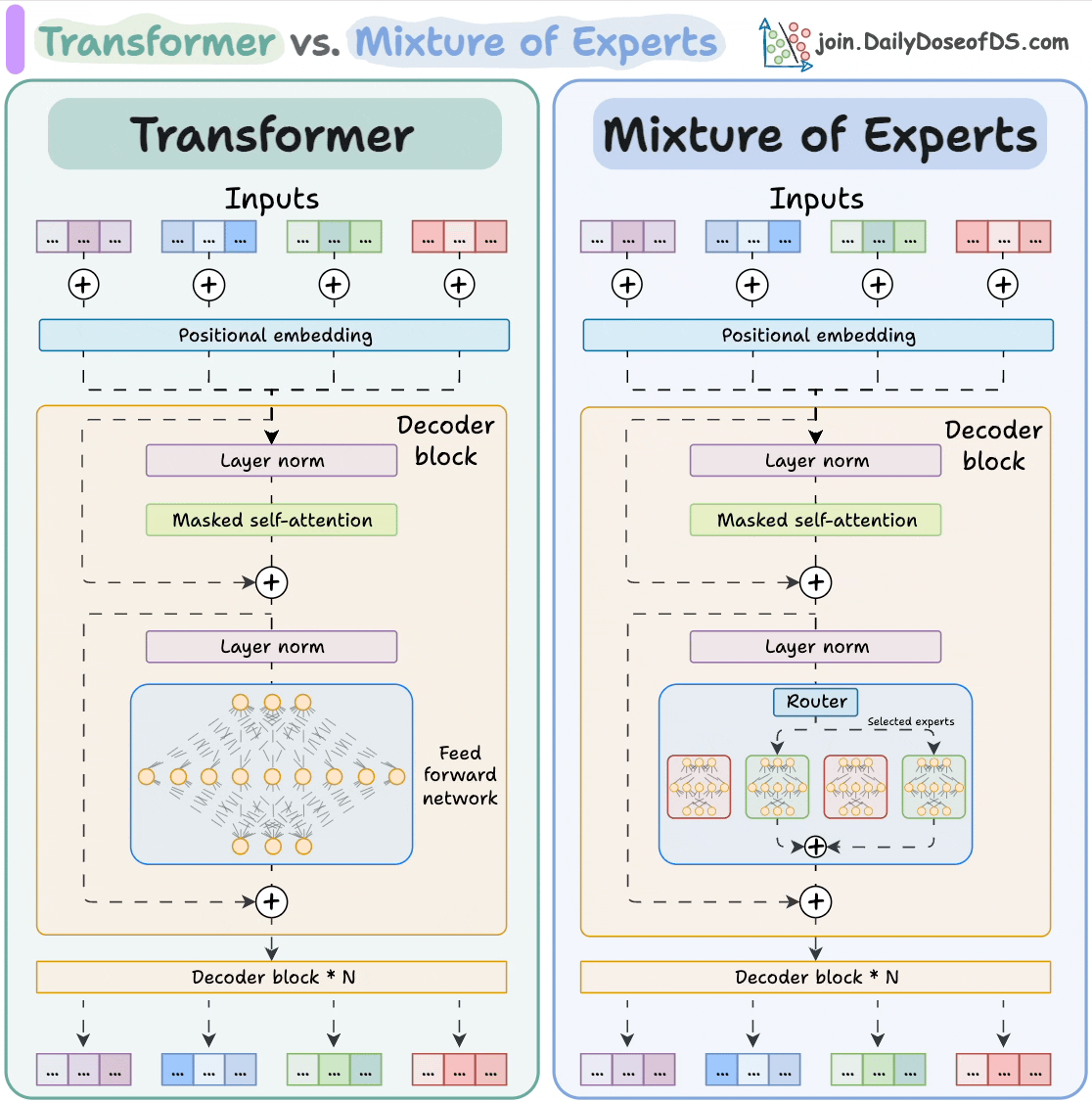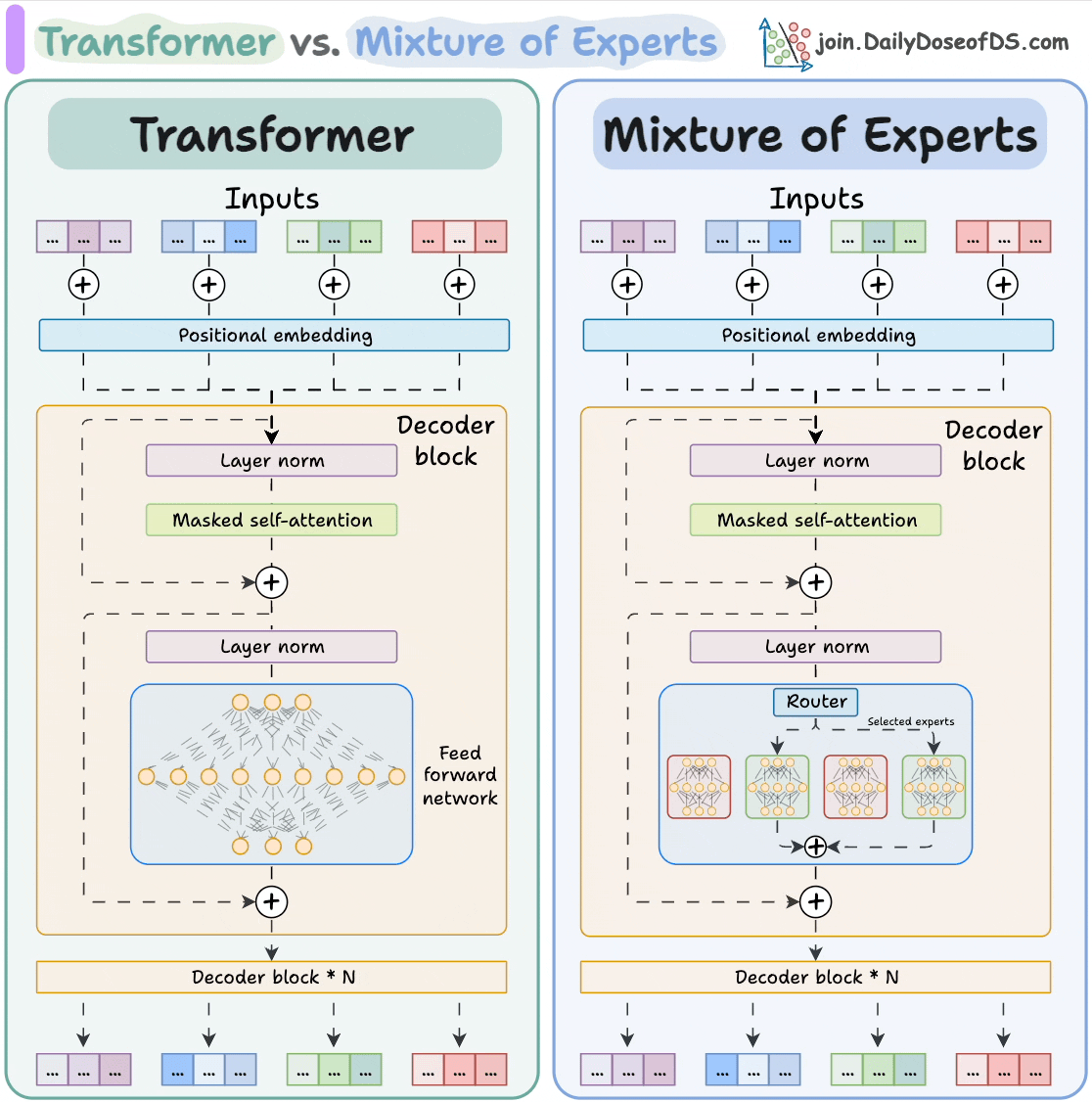
Mixture of Experts (MoE) is a popular architecture that uses different “experts” to improve Transformer models.
Experts are like which are feed-forward networks but smaller compared to those in traditional Transformer models.
7) RAG vs Agentic RAG
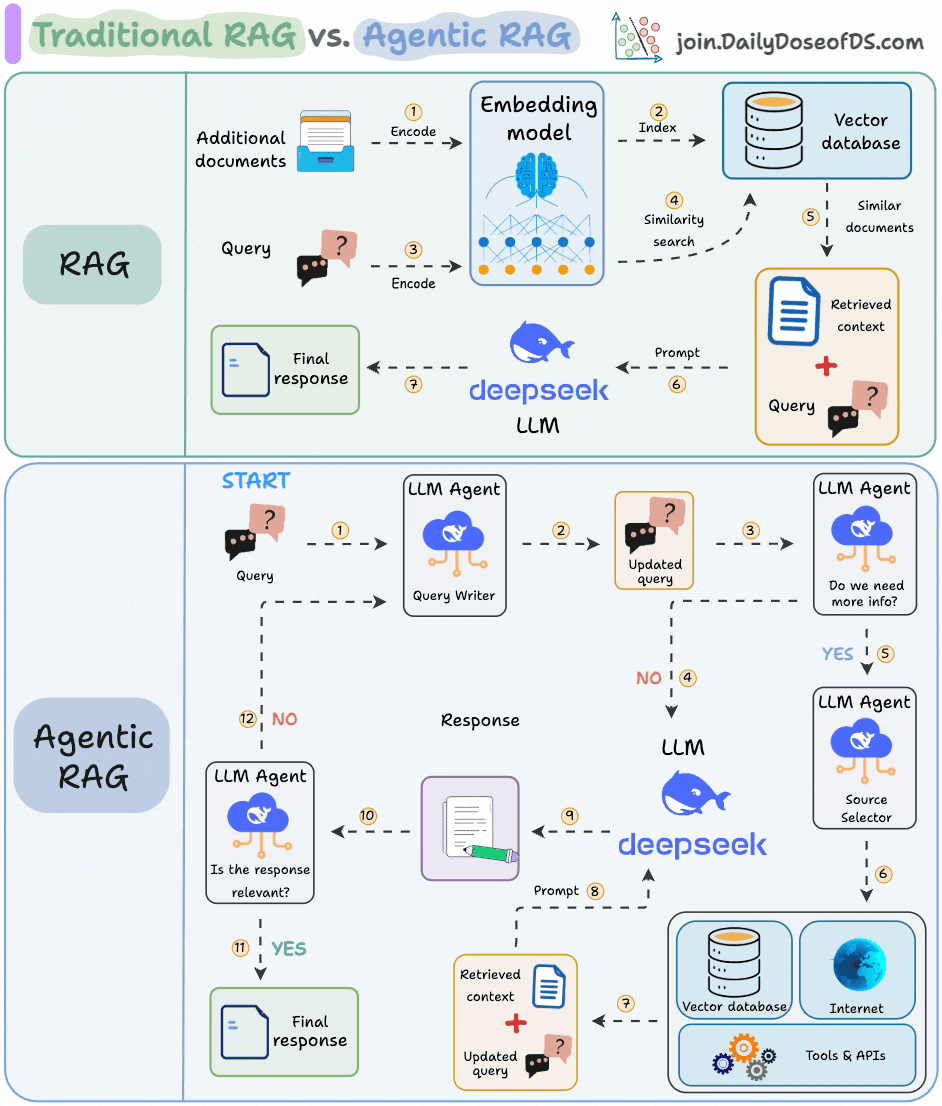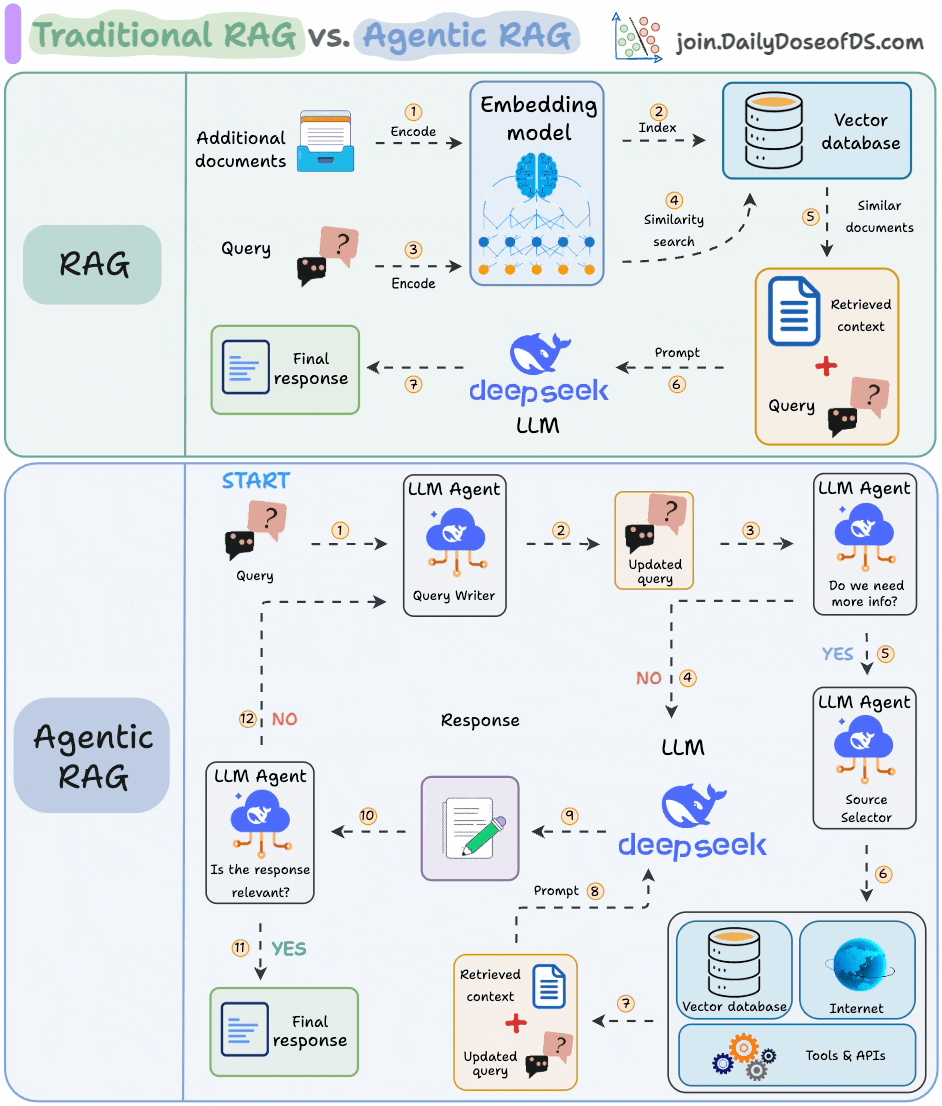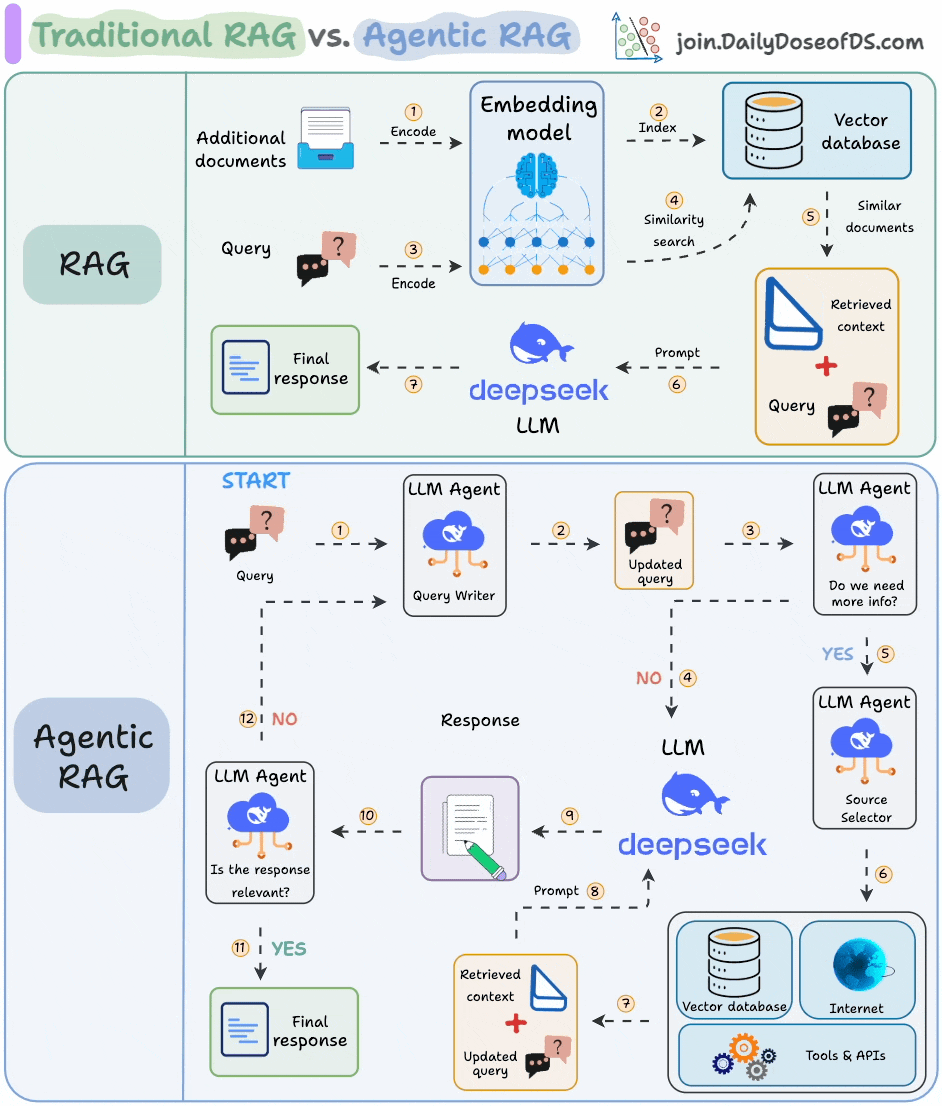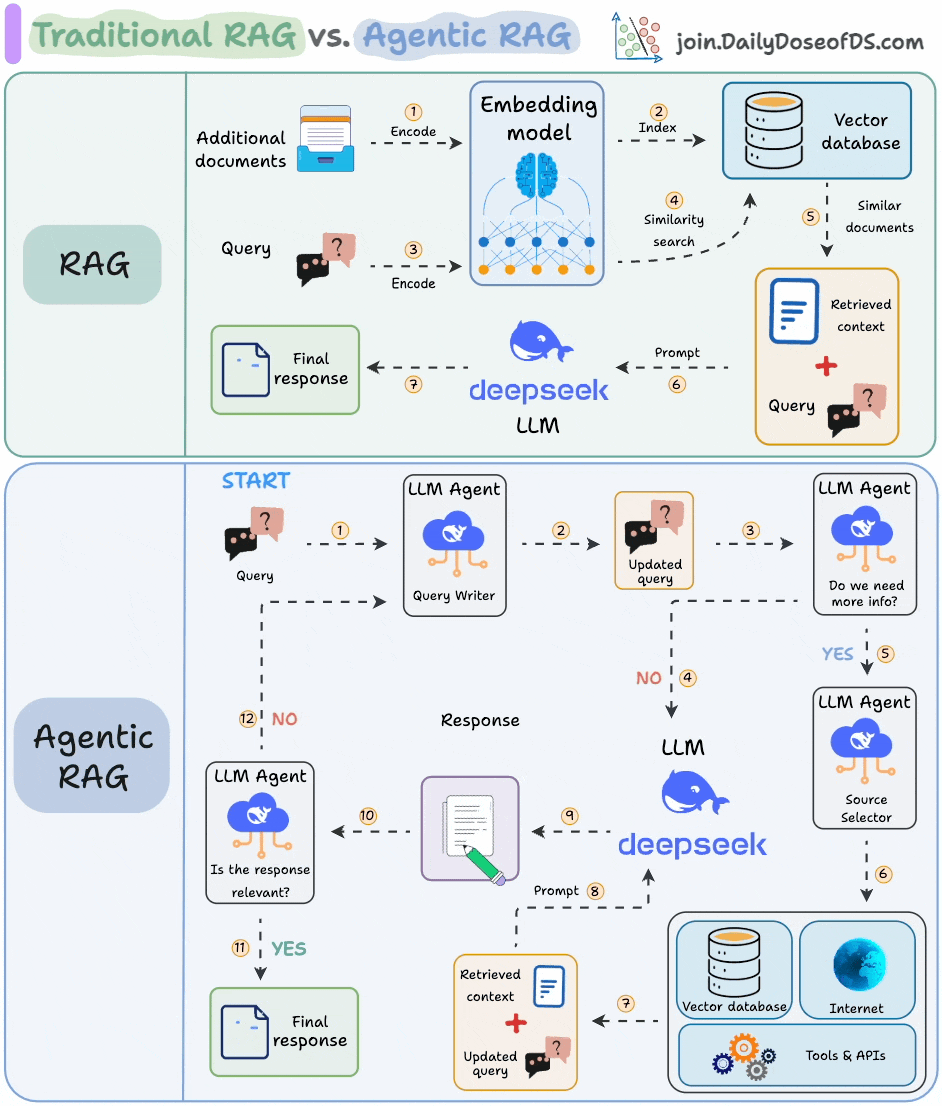
Naive RAG retrieves once and generates once, it cannot dynamically search for more info, and it cannot reason through complex queries.
Also, there’s little adaptability. The LLM can’t modify its strategy based on the problem at hand.
Agentic RAG solves this.
8) 5 Agentic AI design patterns
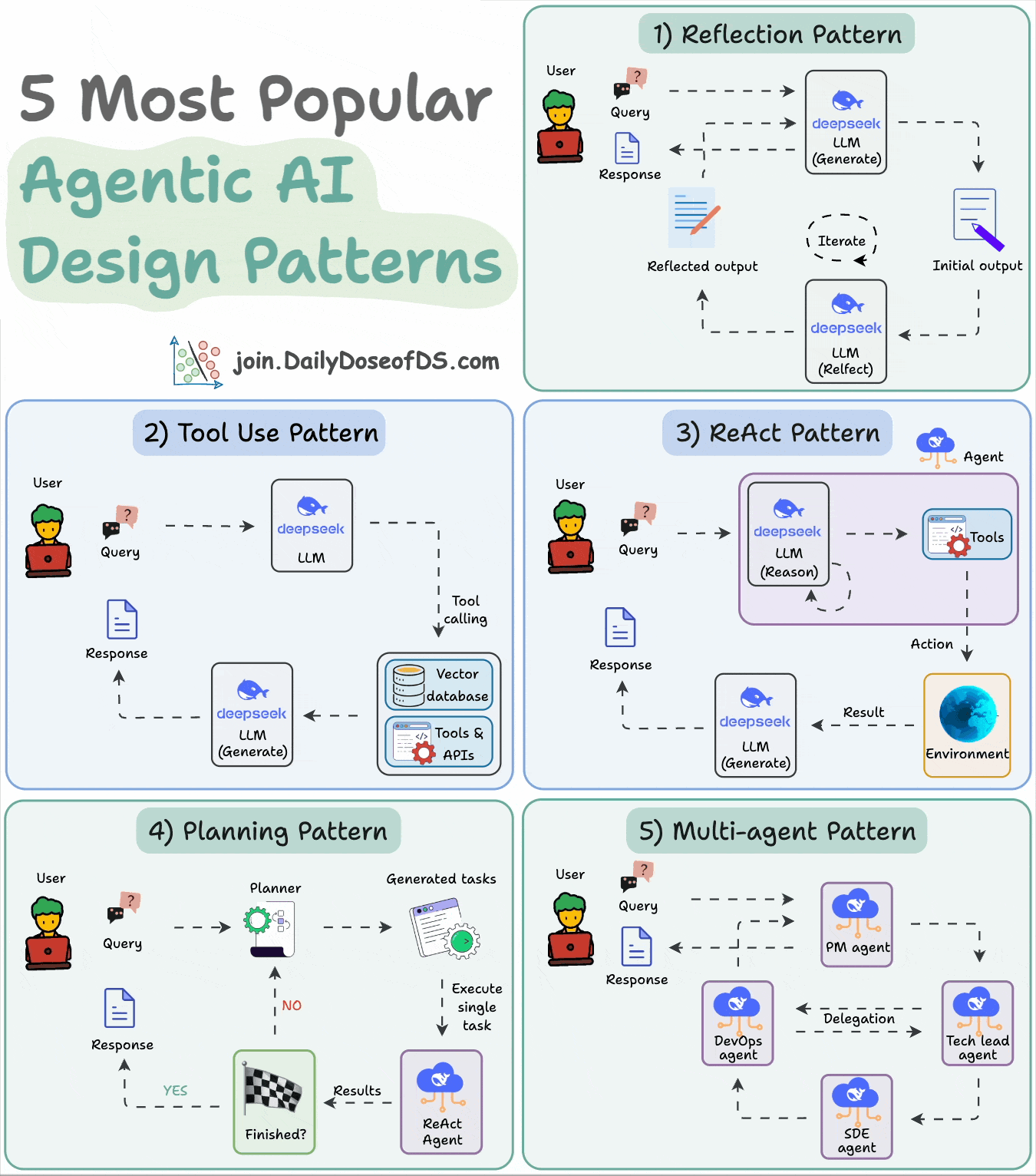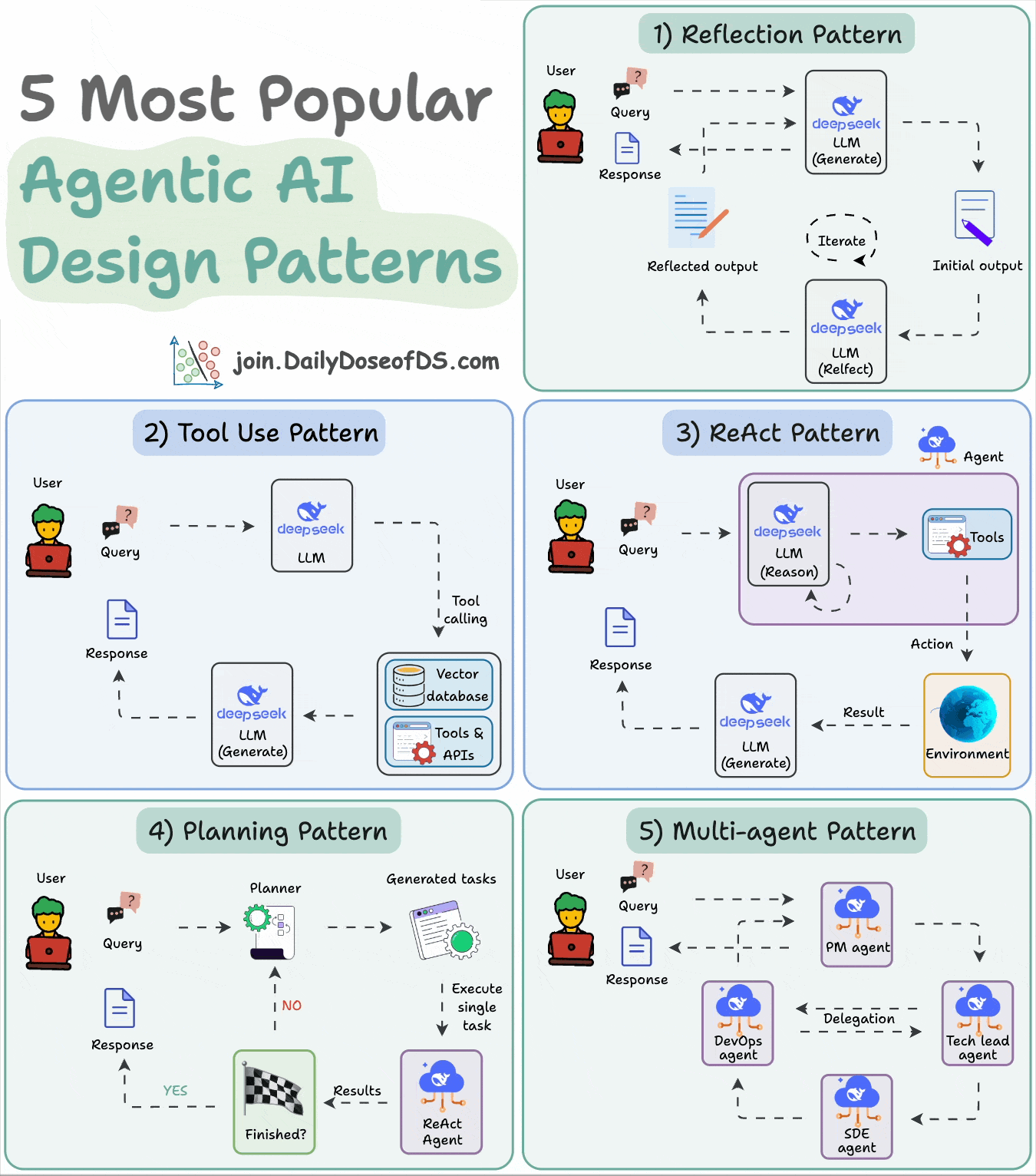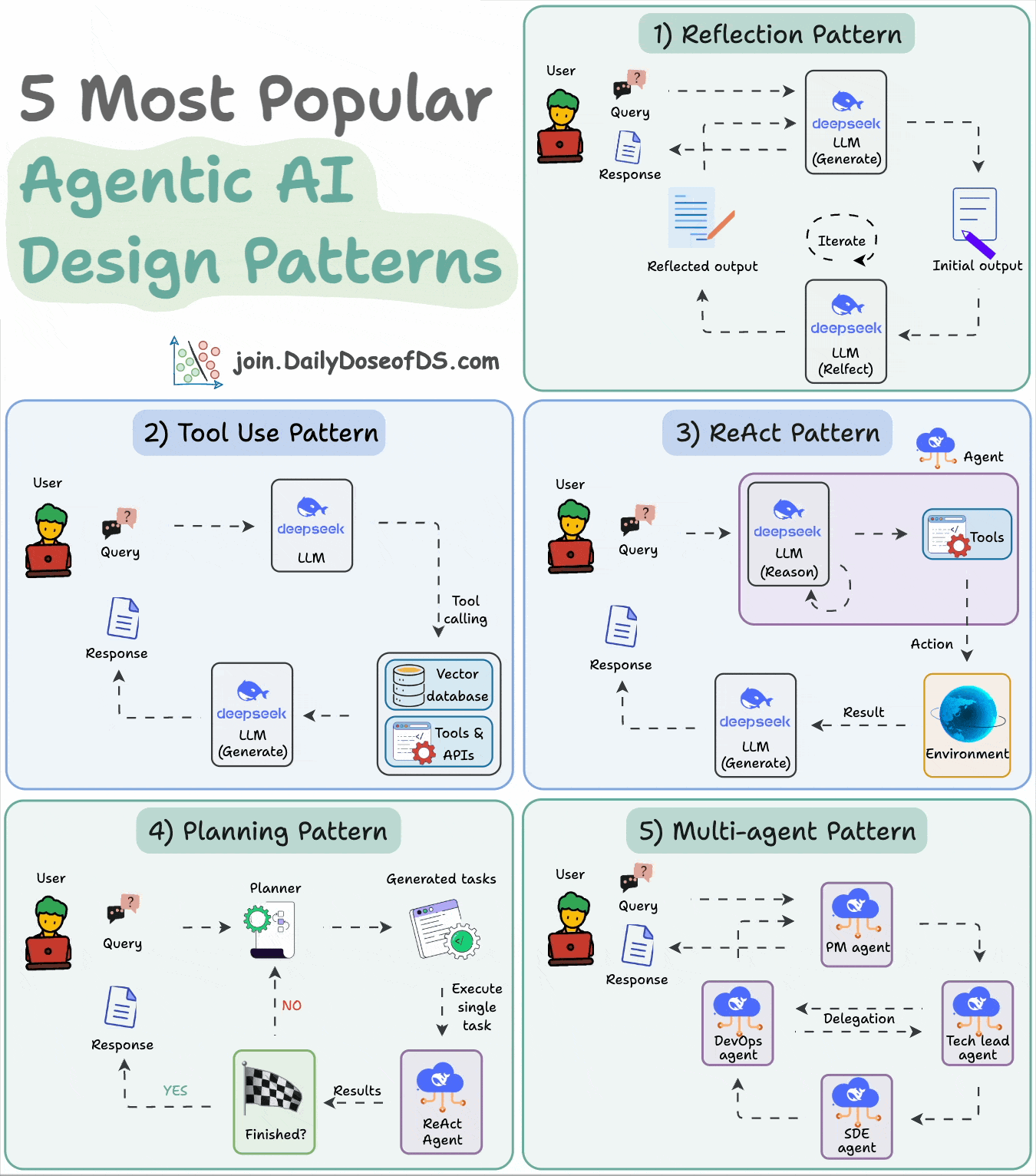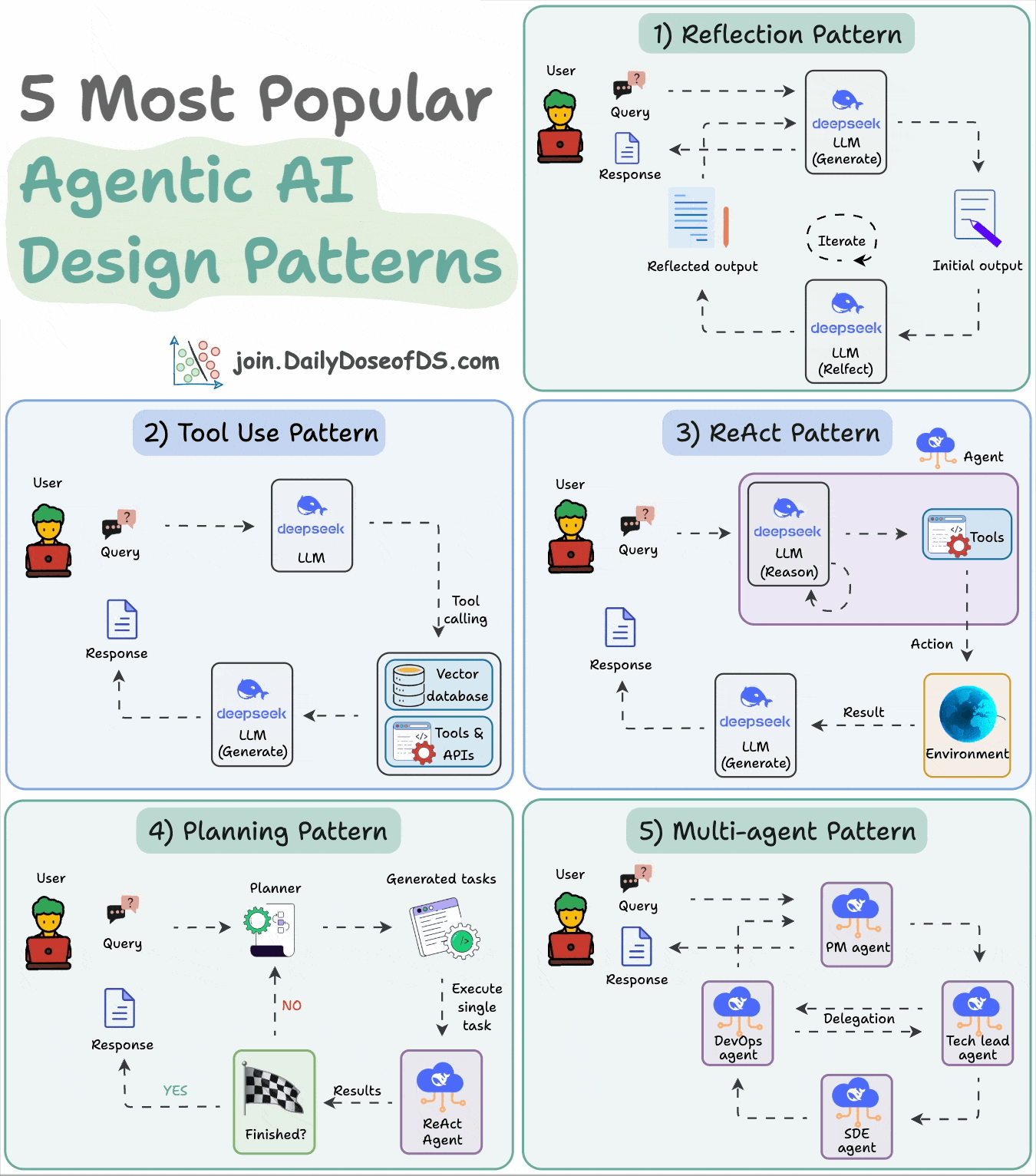
Agentic behaviors allow LLMs to refine their output by incorporating self-evaluation, planning, and collaboration!
This visual depicts the 5 most popular design patterns employed in building AI agents.
9) 5 levels of Agentic AI systems
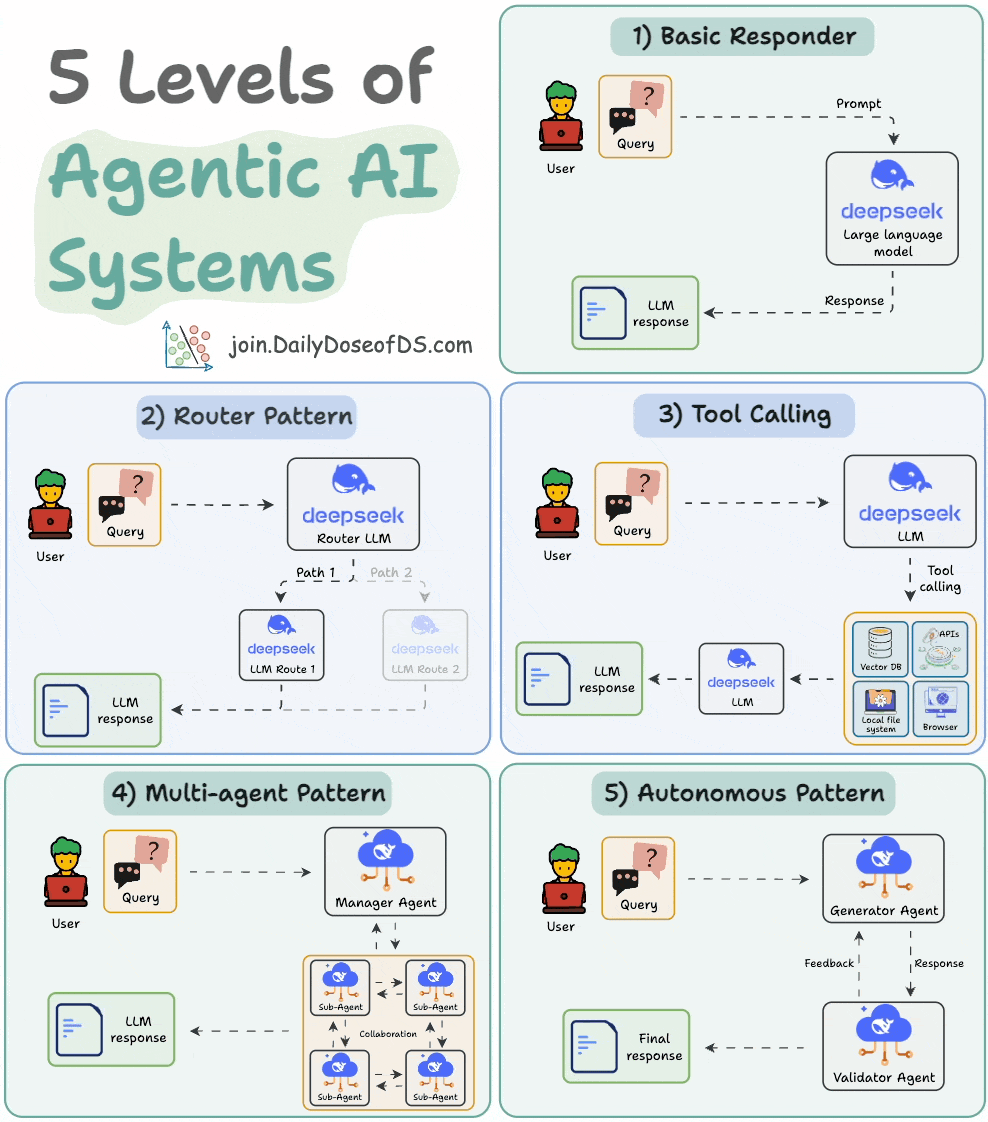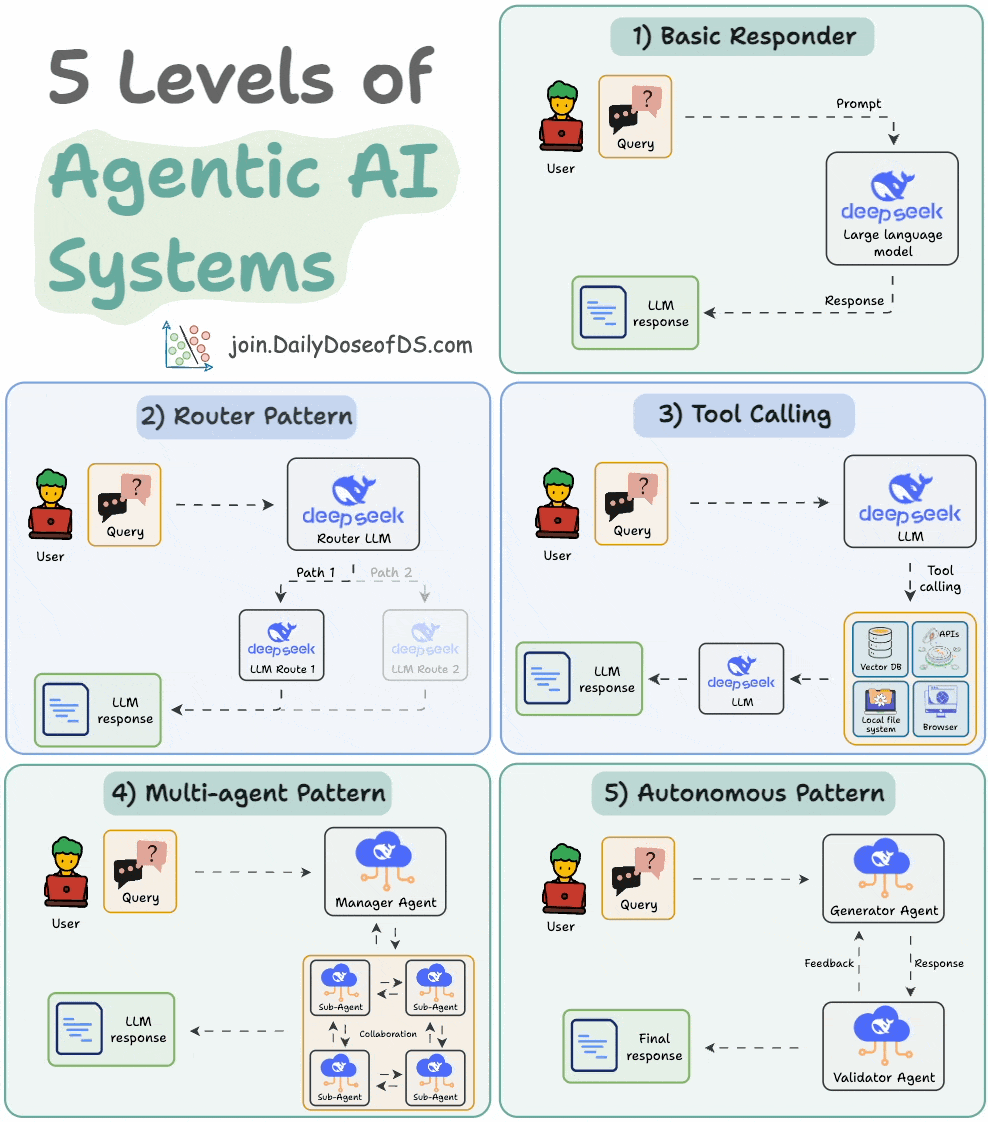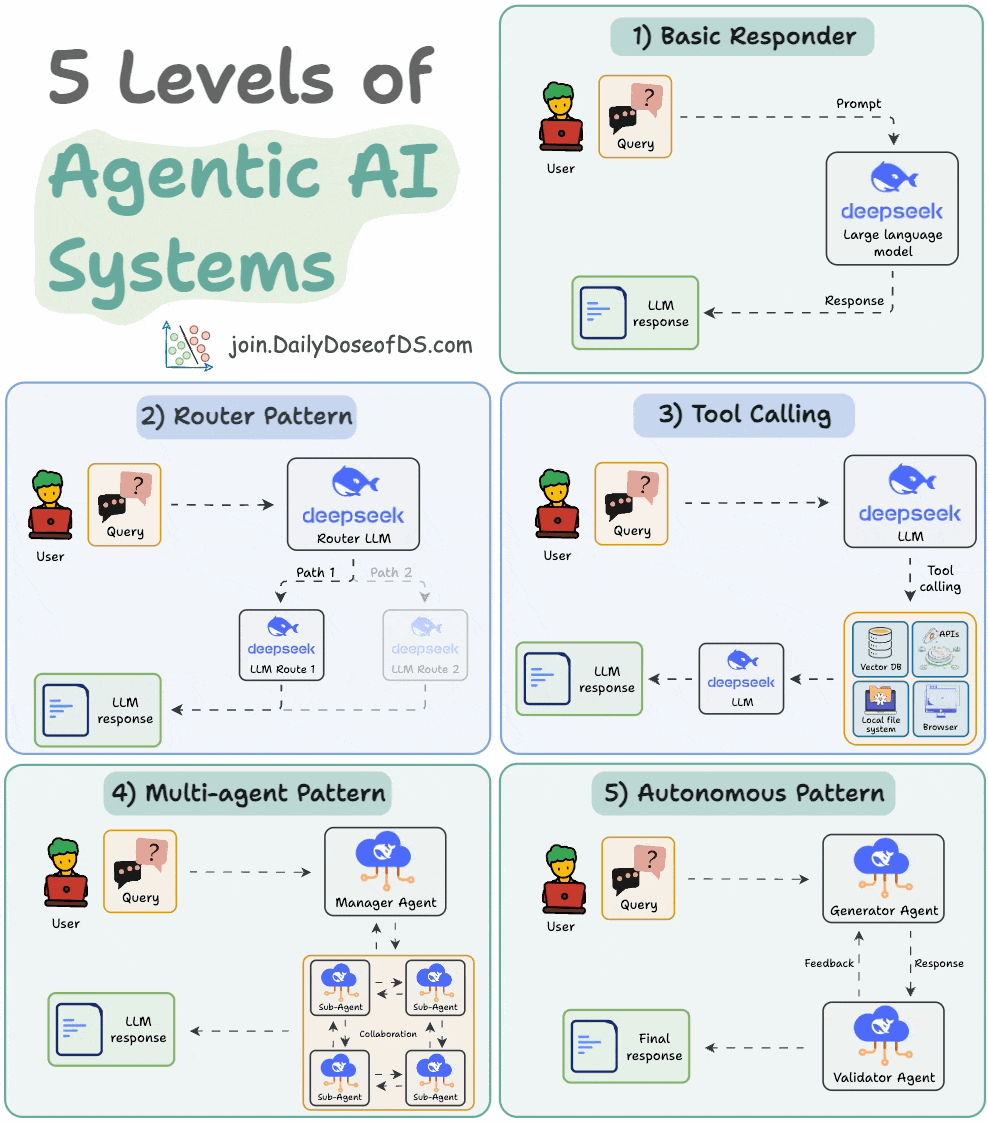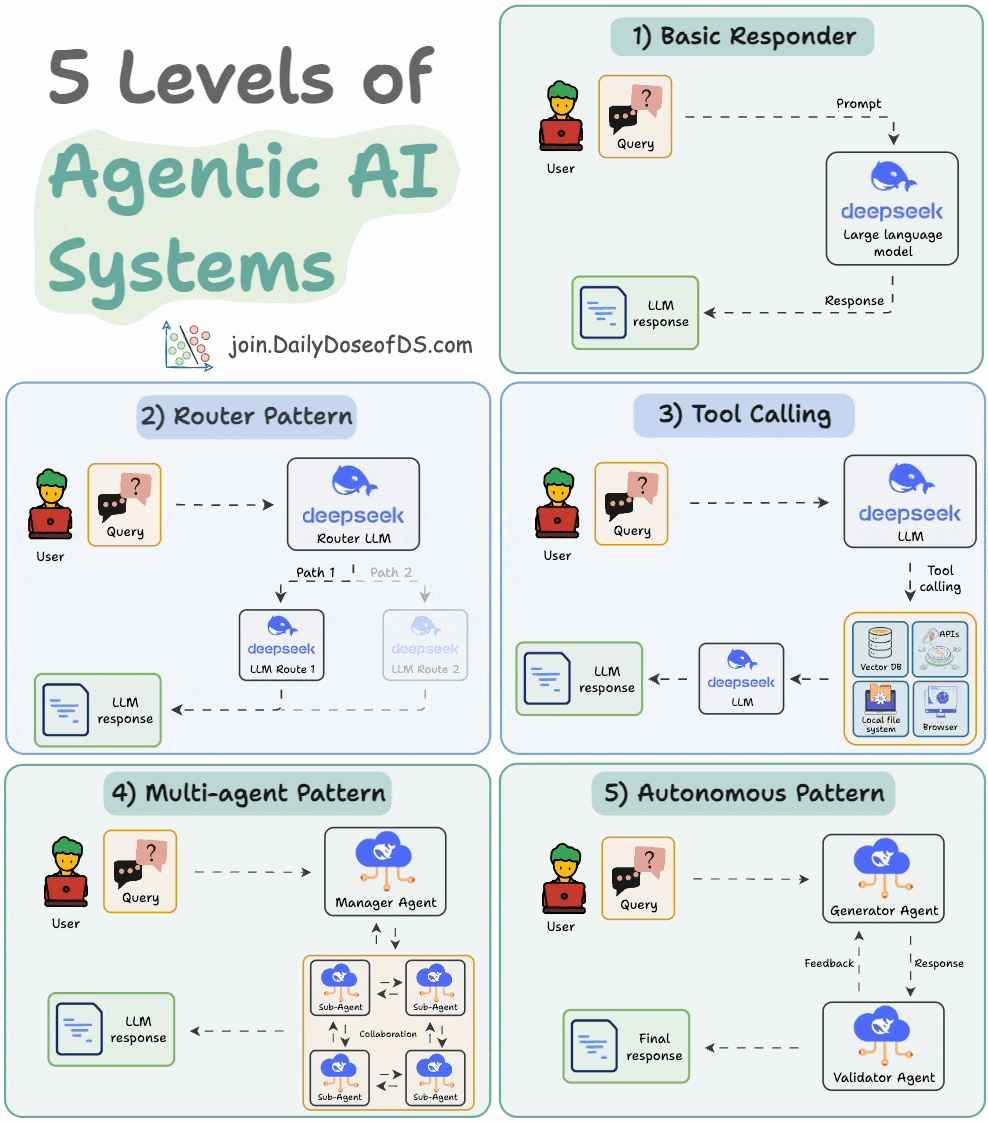
Agentic systems don’t just generate text; they make decisions, call functions, and even run autonomous workflows.
The visual explains 5 levels of AI agency—from simple responders to fully autonomous agents.
10) Traditional RAG vs HyDE
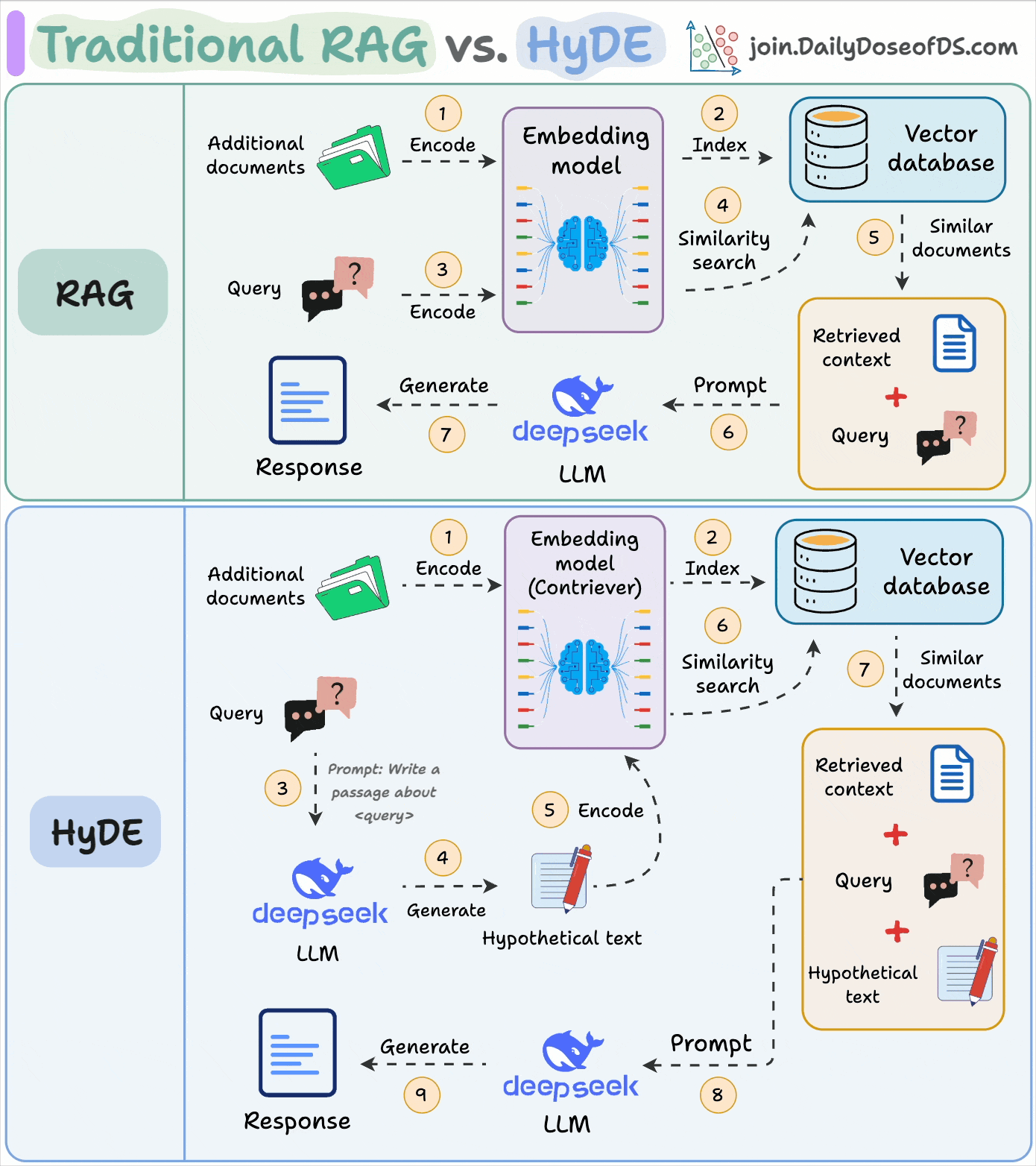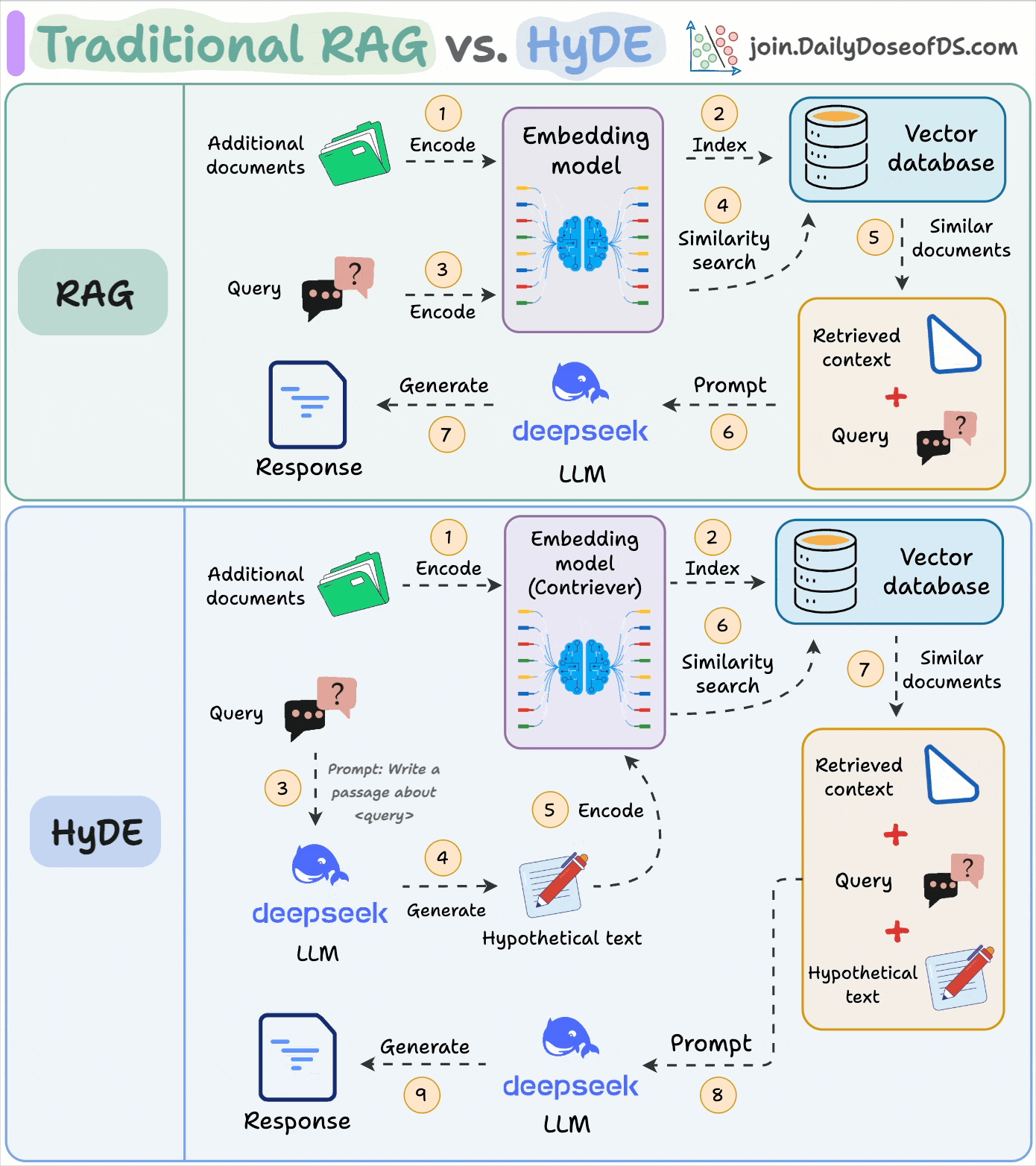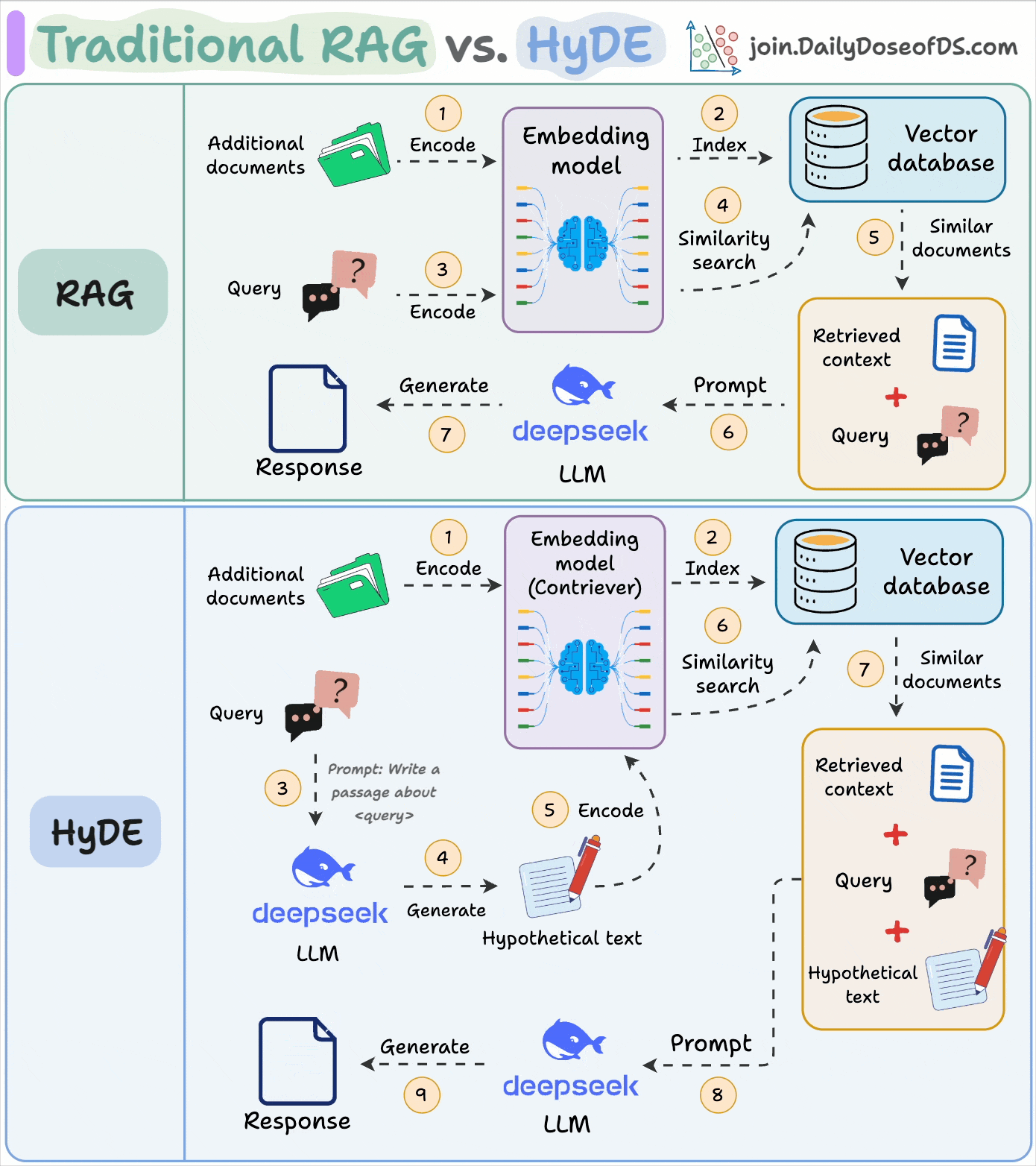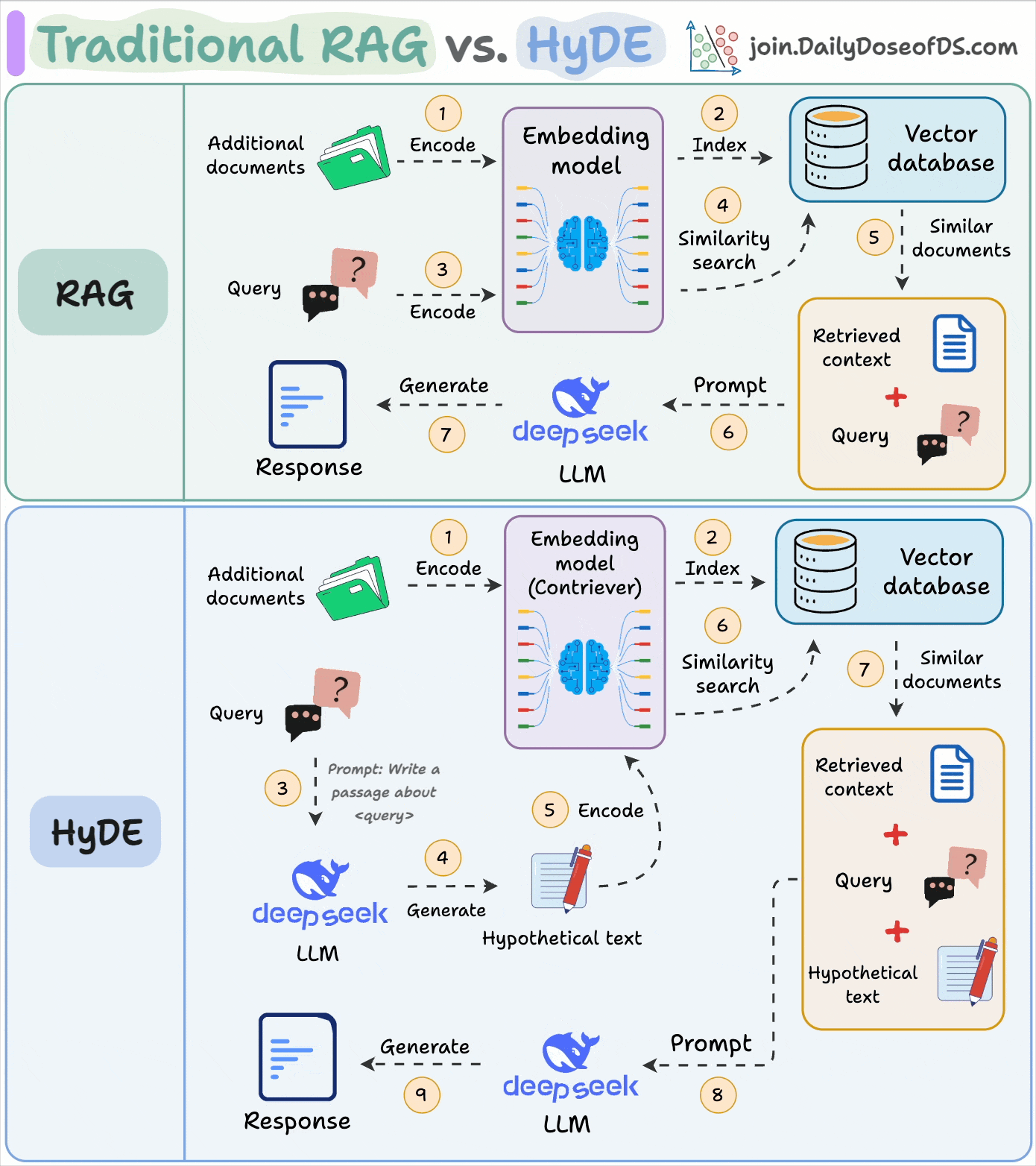
One critical problem with the traditional RAG system is that questions are not semantically similar to their answers. As a result, several irrelevant chunks get retrieved during the retrieval due to a higher cosine similarity than the documents actually containing the answer.
HyDE solves this by generating a hypothetical response first.
11) RAG vs Graph RAG
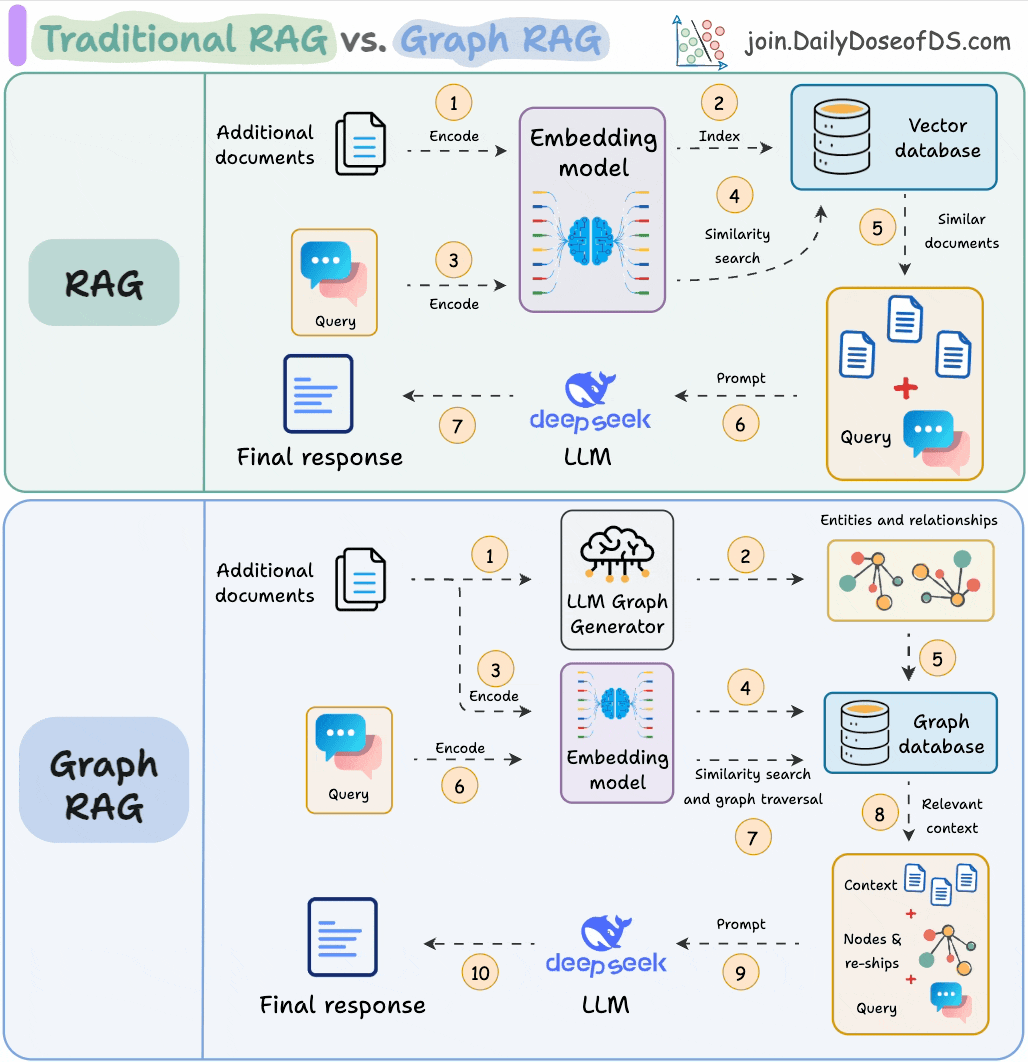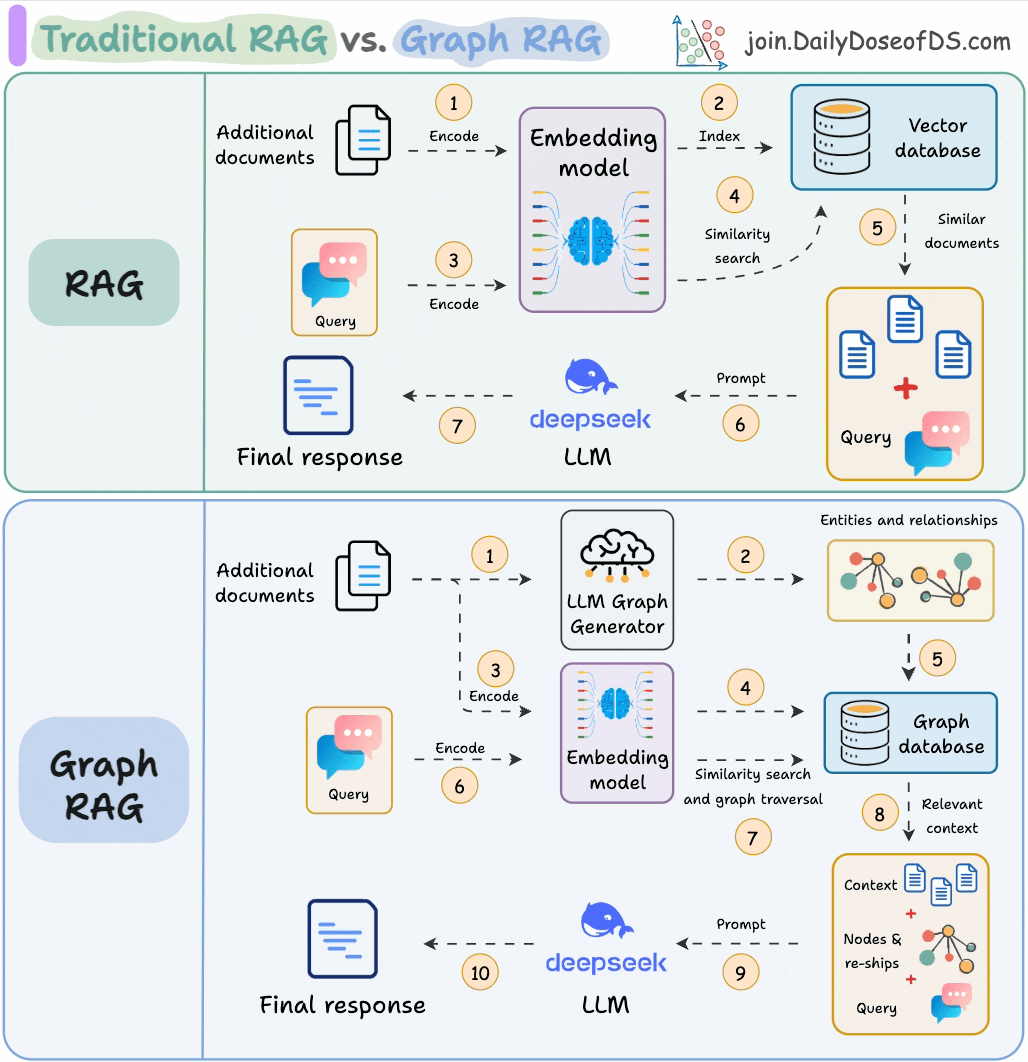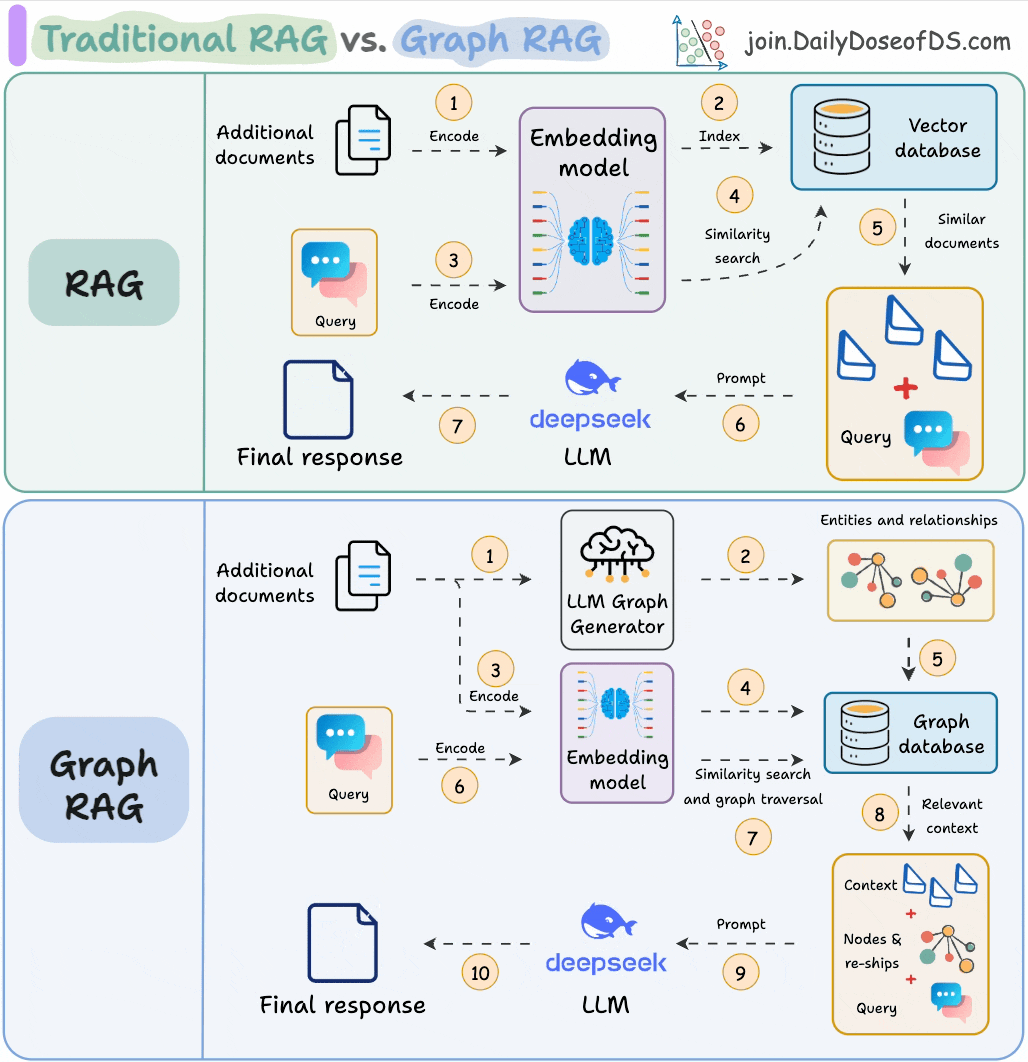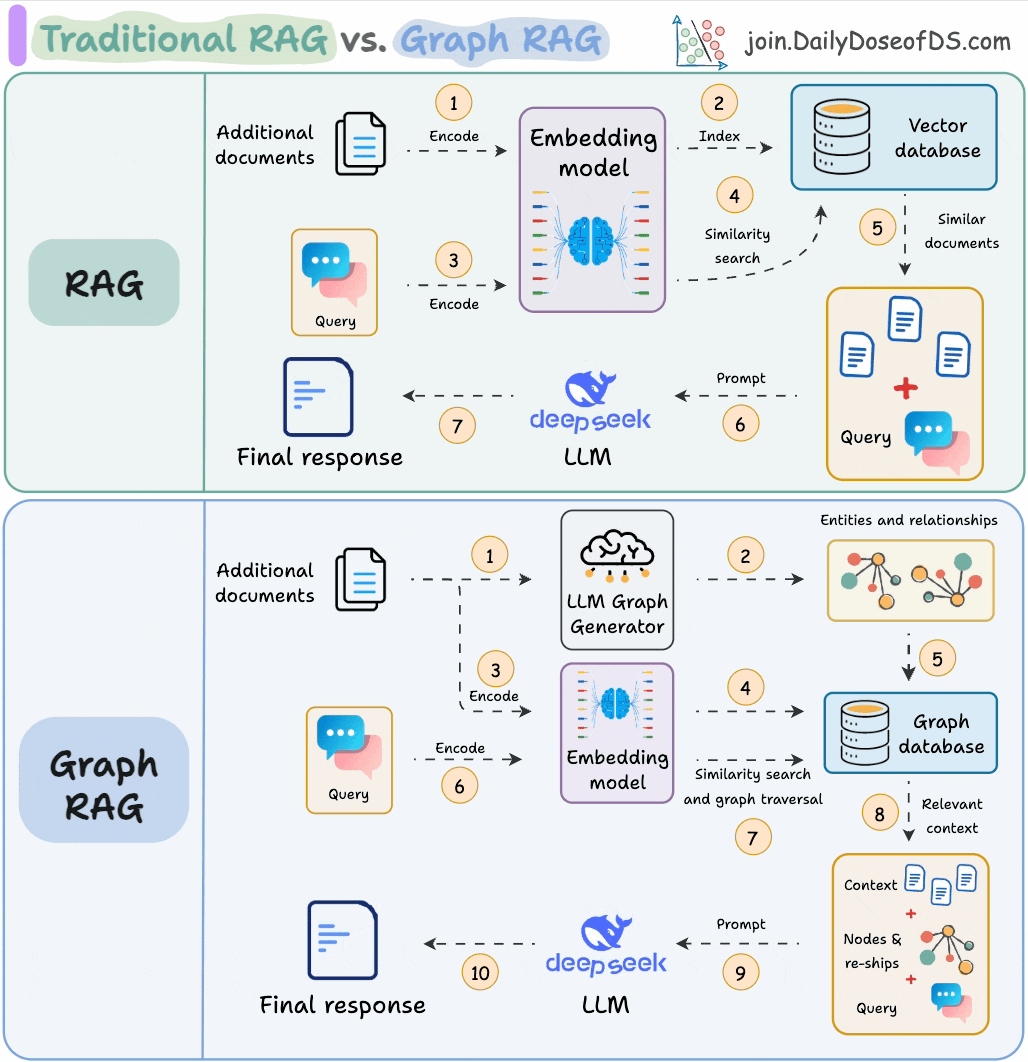
Answering questions that need global context is difficult with traditional RAG since it only retrieves the top-k relevant chunks.
Graph RAG makes it more robust with graph structures, which helps it build long-range dependencies instead of local text grouping that happens in RAG.
12) KV caching
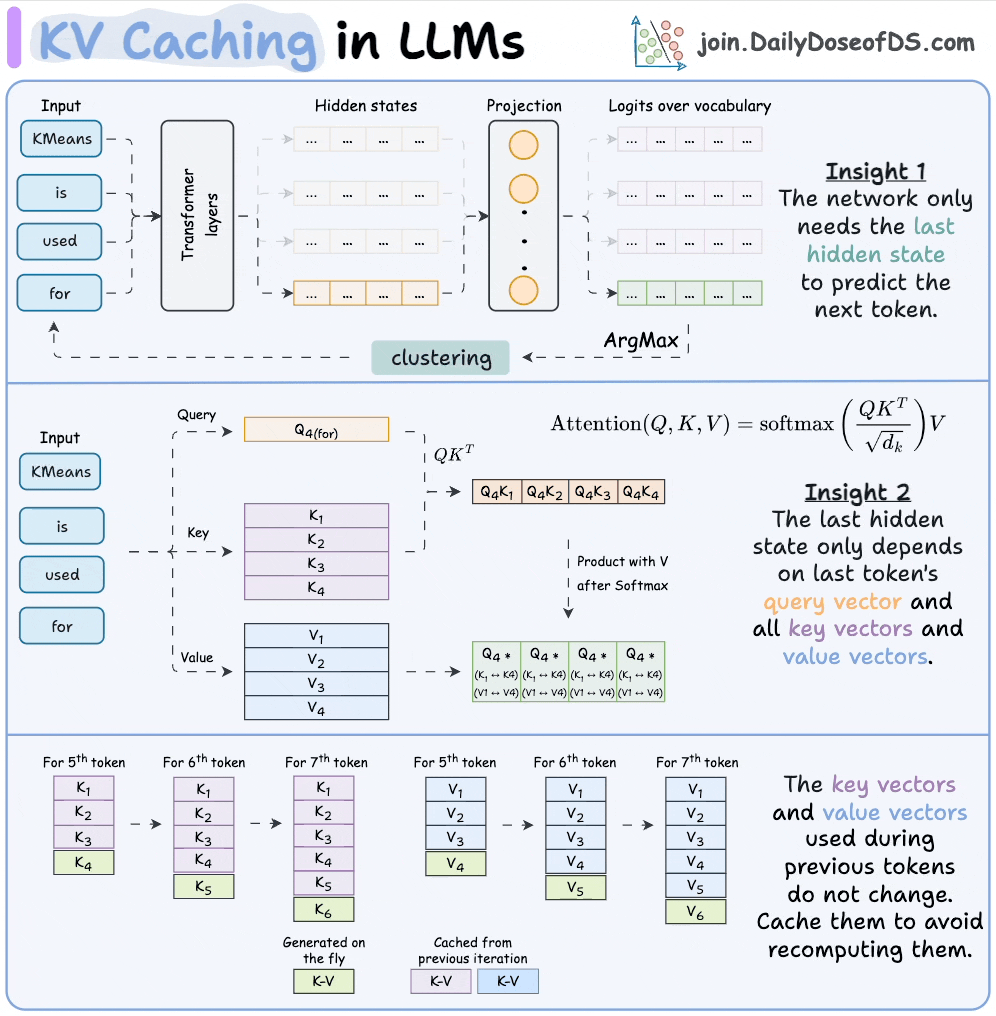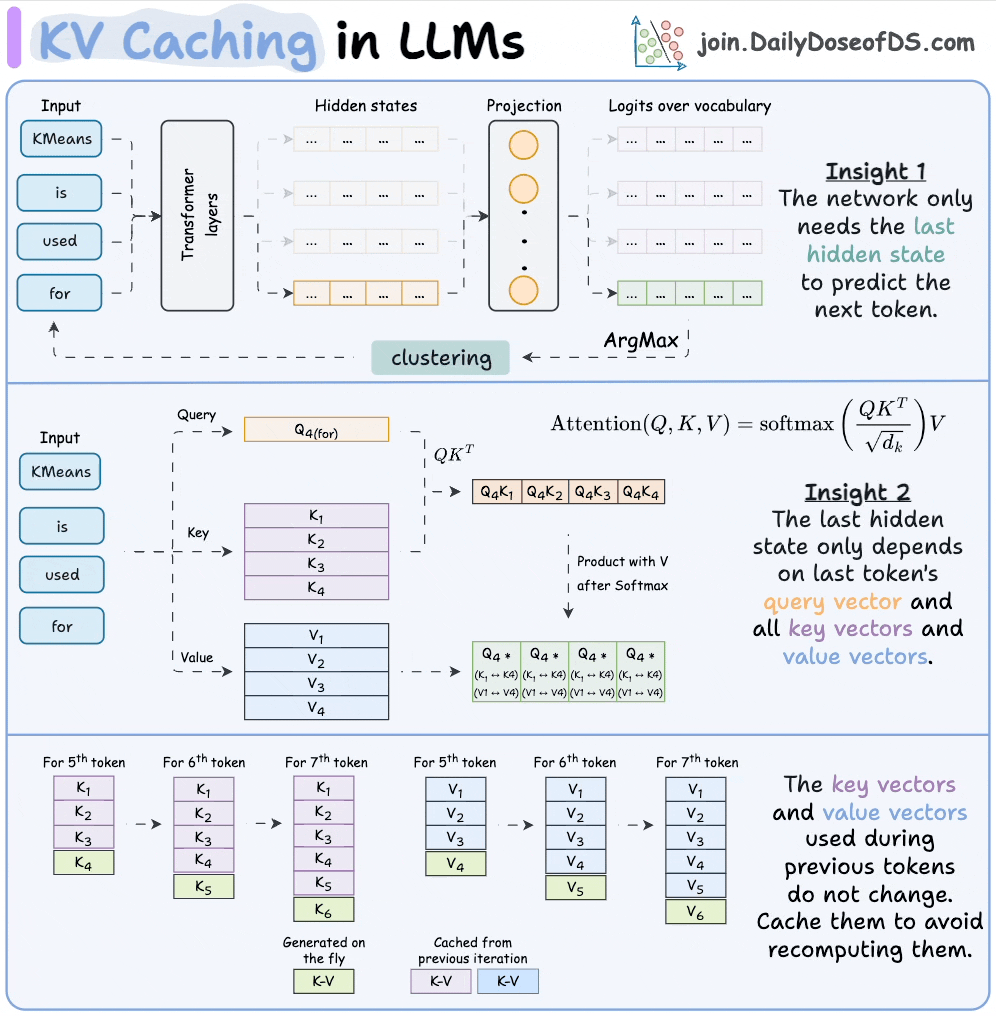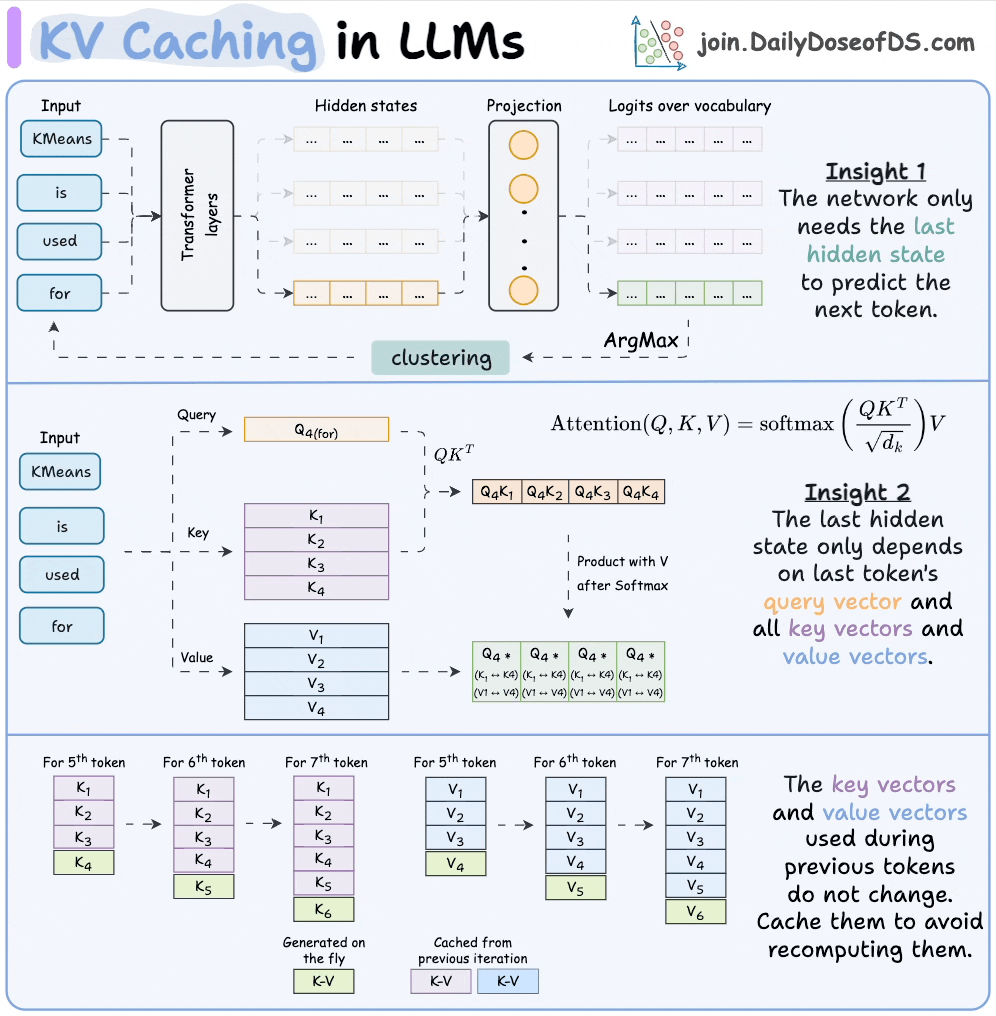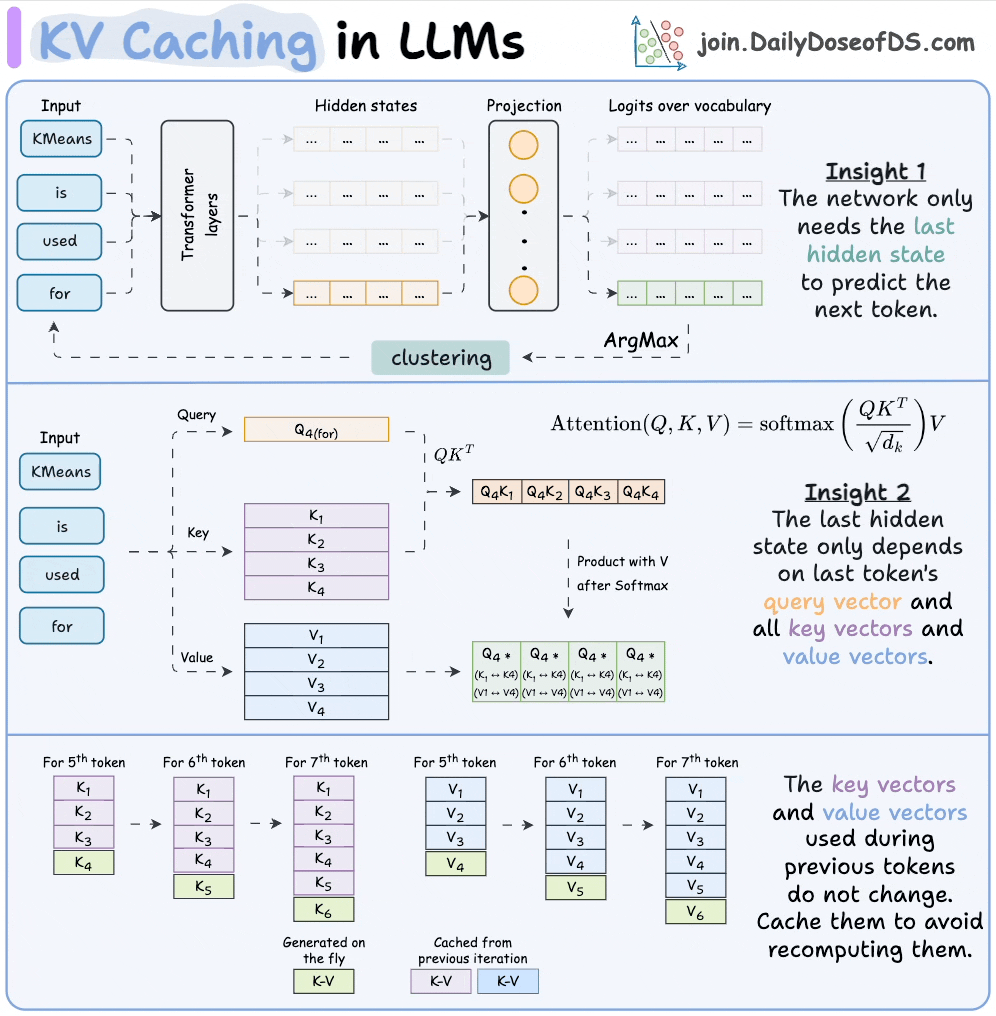
KV caching is a technique used to speed up LLM inference.
In a gist, instead of redundantly computing KV vectors of all context tokens, we cache them. This saves time during inference.
Thanks for reading!