
Full Global Attention vs. Alternating Attention
...explained visually

Year-end sale for lifetime accounts
Lifetime membership to Daily Dose of Data Science is now available at 30% off for the next 5 days. Join here: Lifetime membership.
It gives you lifetime access to the no-fluff, industry-relevant, and practical DS and ML resources that help you succeed and stay relevant in these roles:

Here’s what you'll get:
Our recent 7-part crash course on building RAG systems.
LLM fine-tuning techniques and implementations.
Our crash courses on graph neural networks, PySpark, model interpretability, model calibration, causal inference, and more.
Scaling ML models with implementations.
Building privacy-preserving ML systems.
Mathematical deep dives on core DS topics, clustering, etc.
From-scratch implementations of several core ML algorithms.
Building 100% reproducible ML projects.
50+ more existing industry-relevant topics.
Also, all weekly deep dives that we will publish in the future are included.
Join below at 30% off: Lifetime membership.
Our next sale will be after at least 8-9 months. If you find value in this work, it is a great time to upgrade to a lifetime experience.
P.S. If you are an existing monthly or yearly member and wish to upgrade to lifetime, please reply to this email.
Full global attention vs. alternating attention
Last week, ModernBERT was released, which is an upgraded version of BERT, with:
16x larger sequence length.
Much better downstream performance, both for classification tasks and retrieval (like used in RAG systems)
The most memory-efficient encoder.
I read the paper and found an interesting detail related to the attention network shared below:
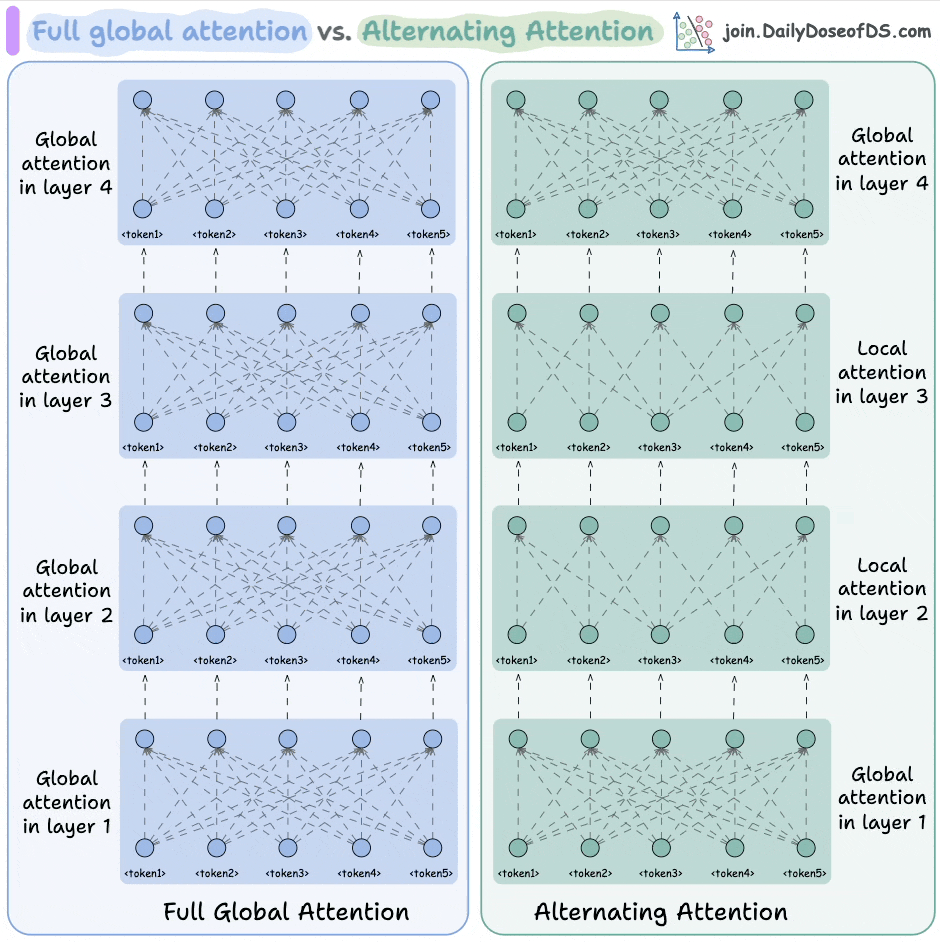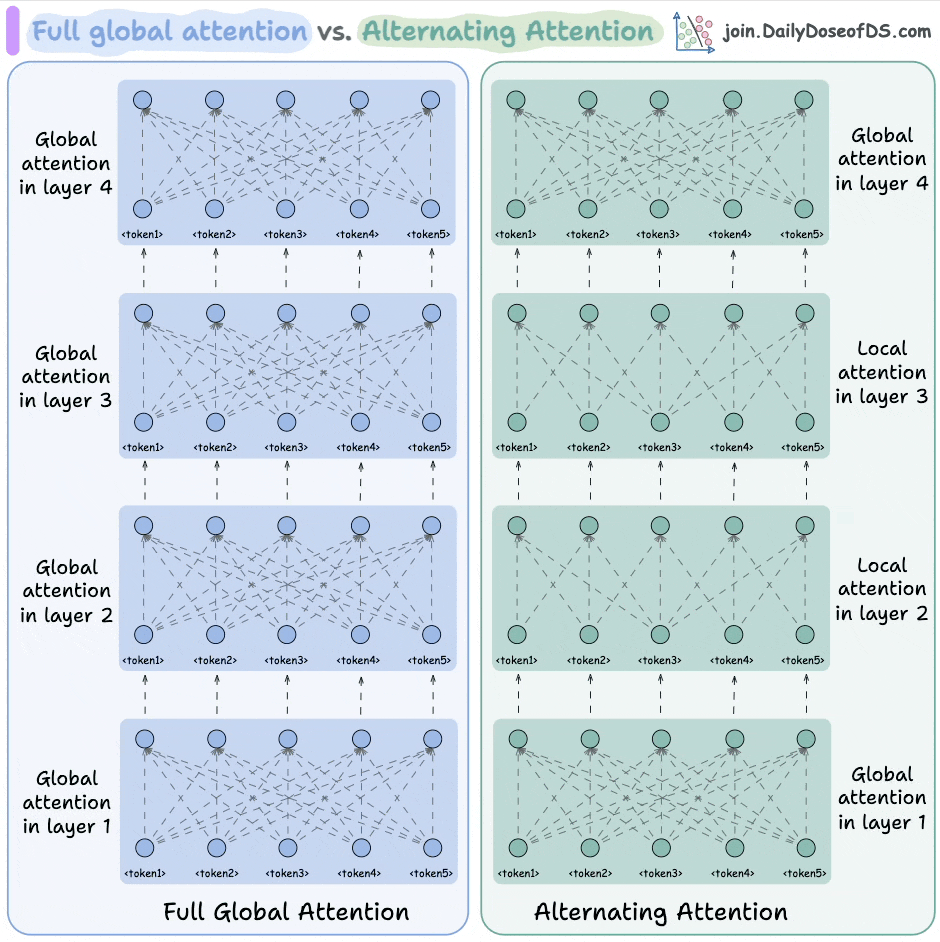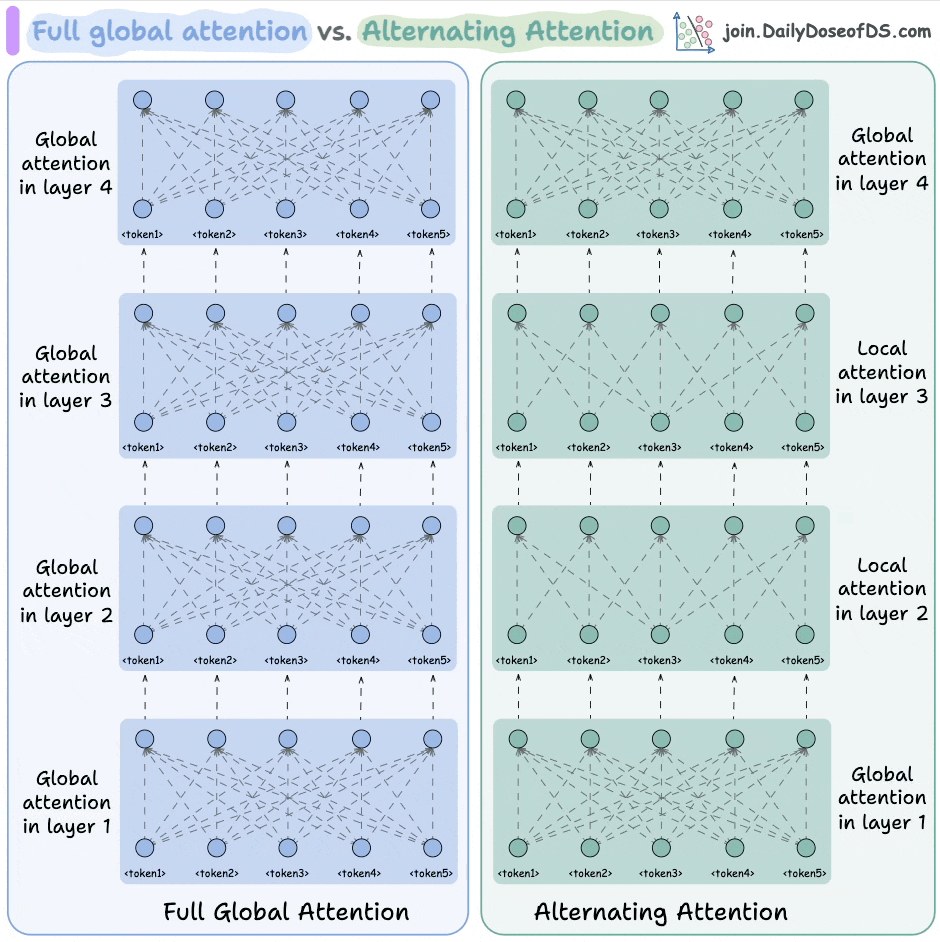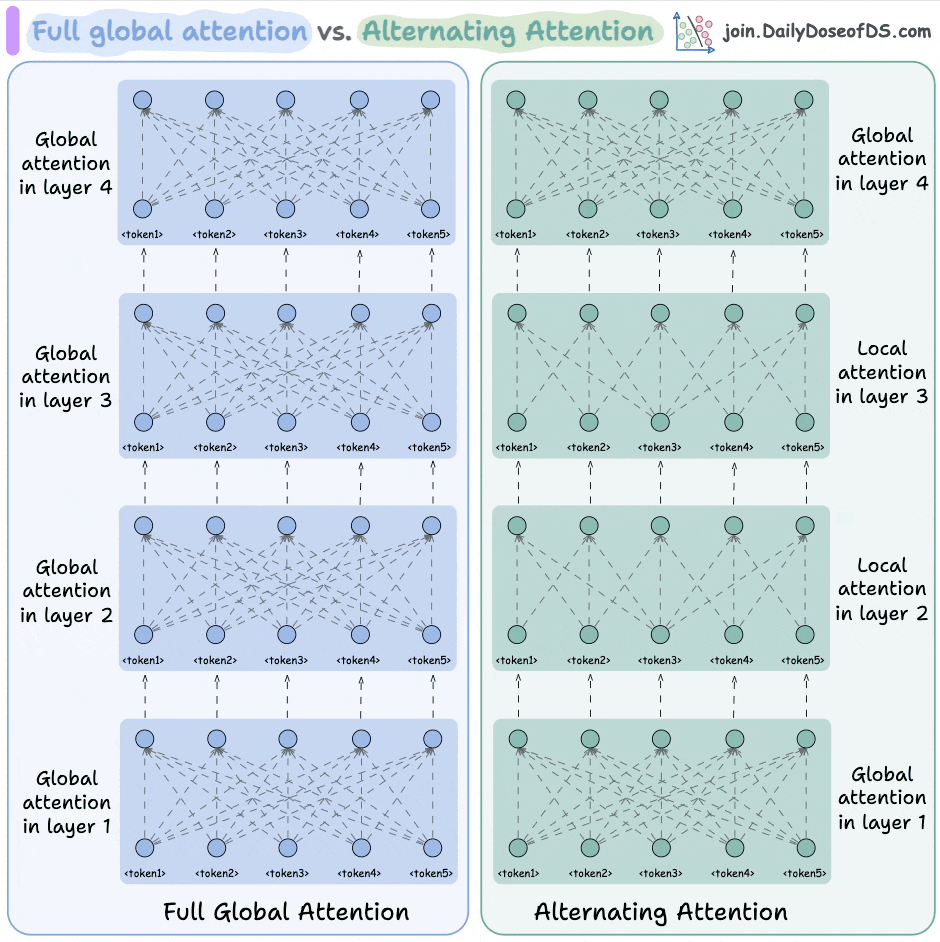
BERT used full global attention (shown on the left above), which has a quadratic complexity.
But ModernBERT made this efficient with alternating attention.
Here's the idea:
They used full global attention in every third layer.
All other layers used a sliding window attention, wherein, every token only attended to 128 nearest tokens (called local attention).
This allows ModernBERT to process much longer input sequences, while also being significantly faster than other encoder models.
Here's an intuitive explanation that explains the motivation behind alternating attention (taken directly from the announcement):
Conceptually, the reason this works is pretty simple: Picture yourself reading a book. For every sentence you read, do you need to be fully aware of the entire plot to understand most of it (full global attention)? Or is awareness of the current chapter enough (local attention), as long as you occasionally think back on its significance to the main plot (global attention)? In the vast majority of cases, it’s the latter.
Makes sense, doesn't it?
Here are some more details:
It is available in 2 sizes— Base (149M parameters) and Large (395M parameters).
It was trained on 2 trillion tokens (400x more than BERT)
Outperforms several encoder models like BERT, RoBERTa, etc.
Outperforms all other encoder base models in variable-length inference.
Uses RoPE for long-context support.
It is Apache 2.0 licensed.
and more.
Here's a quick demo:

It does not have any multilingual versions yet.
Since the model is new and we are still experimenting with it, we'll share our learnings soon.
Also, we won't release a new issue tomorrow (28th December 2024). You will hear next from us on Monday.
👉 Over to you: What are your initial thoughts on ModernBERT?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.