
Gaussian Mixture Models: The Flexible Twin of KMeans
Addressing the major limitation of KMeans.

KMeans is widely used for its simplicity and effectiveness as a clustering algorithm.
But it has many limitations.
To begin:
It does not account for cluster variance
It can only produce spherical clusters. As shown below, even if the data has non-circular clusters, it still produces round clusters.
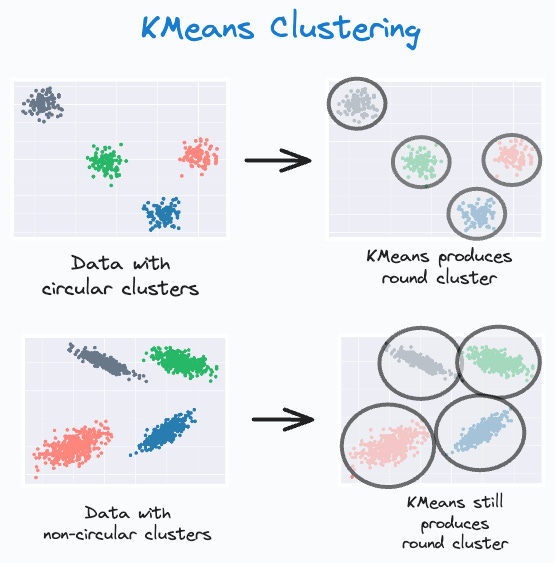
It performs a hard assignment. There are no probabilistic estimates of each data point belonging to each cluster.

These limitations often make KMeans a non-ideal choice for clustering.
Gaussian Mixture Models are often a superior algorithm in this respect.
As the name suggests, they can cluster a dataset that has a mixture of many Gaussian distributions.
They can be thought of as a more flexible twin of KMeans.
The primary difference is that:
KMeans learns centroids.
Gaussian mixture models learn a distribution.
For instance, in 2 dimensions:

KMeans can only create circular clusters
GMM can create oval-shaped clusters.
The effectiveness of GMMs over KMeans is evident from the image below.
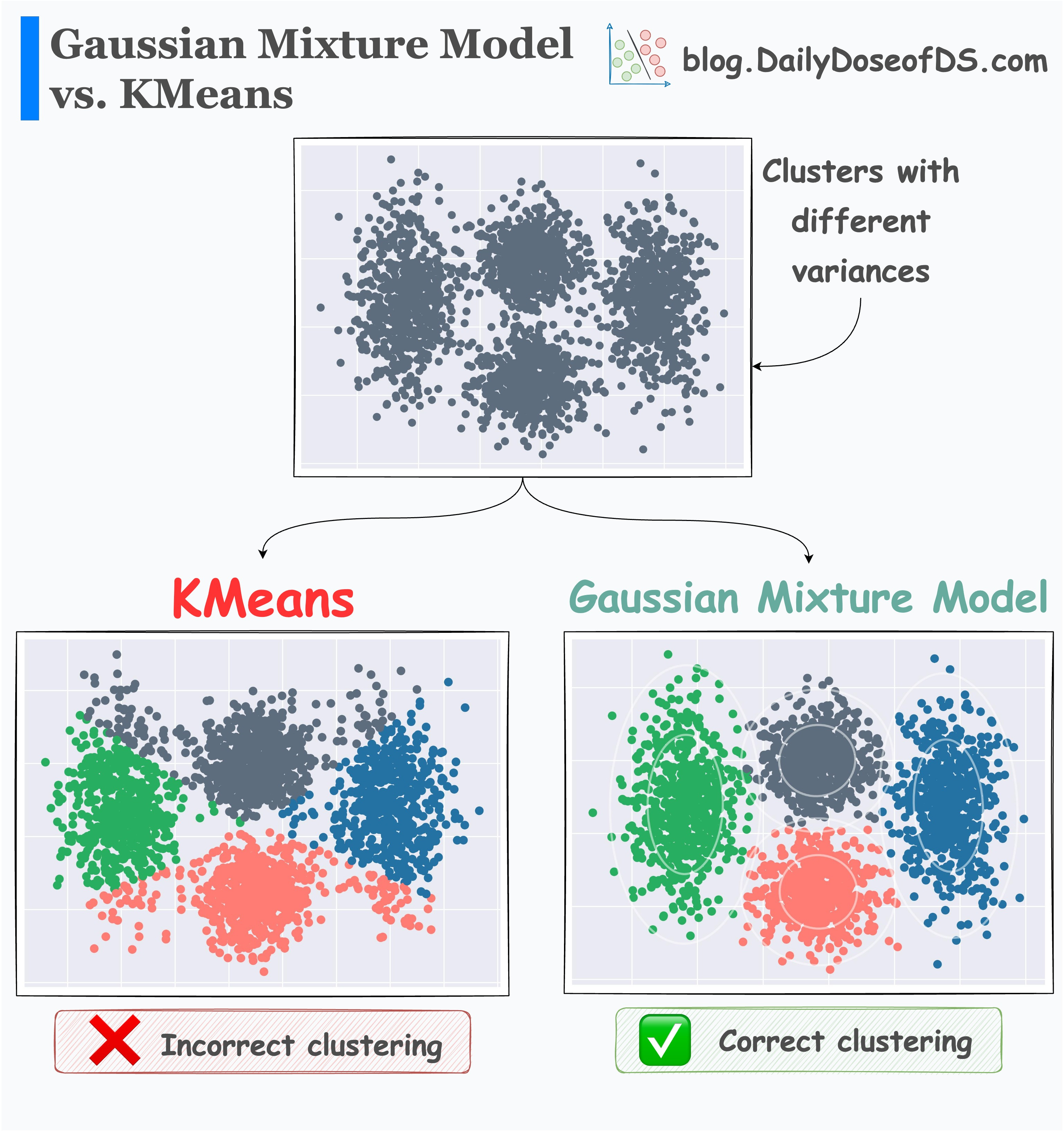
KMeans just relies on distance and ignores the distribution of each cluster
GMM learns the distribution and produces better clustering.
But how does it exactly work, and why is it so effective?
What is the core intuition behind GMMs?
How do they model the data distribution so precisely?
If you are curious, then this is precisely what we are learning in today’s extensive machine learning deep dive.

The entire idea and formulation of Gaussian mixture models appeared extremely compelling and intriguing to me when I first learned about them.
The notion that a single model can learn diverse data distributions is truly captivating.
Learning about them has been extremely helpful to me in building more flexible and reliable clustering algorithms.
Thus, understanding how they work end-to-end will be immensely valuable if you are looking to expand your expertise beyond traditional algorithms like KMeans, DBSCAN, etc.
Thus, today’s article covers:
The shortcomings of KMeans.
What is the motivation behind GMMs?
How do GMMs work?
The intuition behind GMMs.
Plotting dummy multivariate Gaussian distributions to better understand GMMs.
The end-to-end mathematical formulation of GMMs.
How to use Expectation-Maximization to model data using GMMs?
Coding a GMM from scratch (without sklearn).
Comparing results of GMMs with KMeans.
How to determine the optimal number of clusters for GMMs?
Some practical use cases of GMMs.
Takeaways.
👉 Interested folks can read it here: Gaussian Mixture Models (GMM).
Hope you will learn something new today :)
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!
How do you know which clustering is correct unless you are clustering on a data set where you already have a "correct" somehow verifiable clustering solution? k-means is definitely not an optimization technique and the n clustering solutions you get have to be evaluated for something like "viability" or some kind of at least face validity. At least this was my experience in using clustering for market segmentation. Are you suggesting that the Gaussian approach provides some type of optimized solution?