
Generalized Linear Models (GLMs)
The limitations of linear regression and how GLMs solve them.

A linear regression model is undeniably an extremely powerful model, in my opinion.
However, it does make some strict assumptions about the type of data it can model, as depicted below.

These conditions often restrict its applicability to data situations that do not obey the above assumptions.
That is why being aware of its extensions is immensely important.
Generalized linear models (GLMs) precisely do that.
They relax the assumptions of linear regression to make linear models more adaptable to real-world datasets.
If you are interested in learning more about this, I once wrote a detailed guide on this topic here: Generalized Linear Models (GLMs): The Supercharged Linear Regression.
Why GLMs?
Linear regression is pretty restricted in terms of the kind of data it can model.
For instance, its assumed data generation process looks like this:
Firstly, it assumes that the conditional distribution of Y given X is a Gaussian.
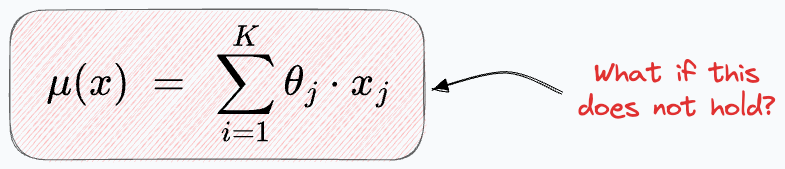
Next, it assumes a very specific form for the mean of the above Gaussian. It says that the mean should always be a linear combination of the features (or predictors).

Lastly, it assumes a constant variance for the conditional distribution P(Y|X) across all levels of X. A graphical way of illustrating this is as follows:
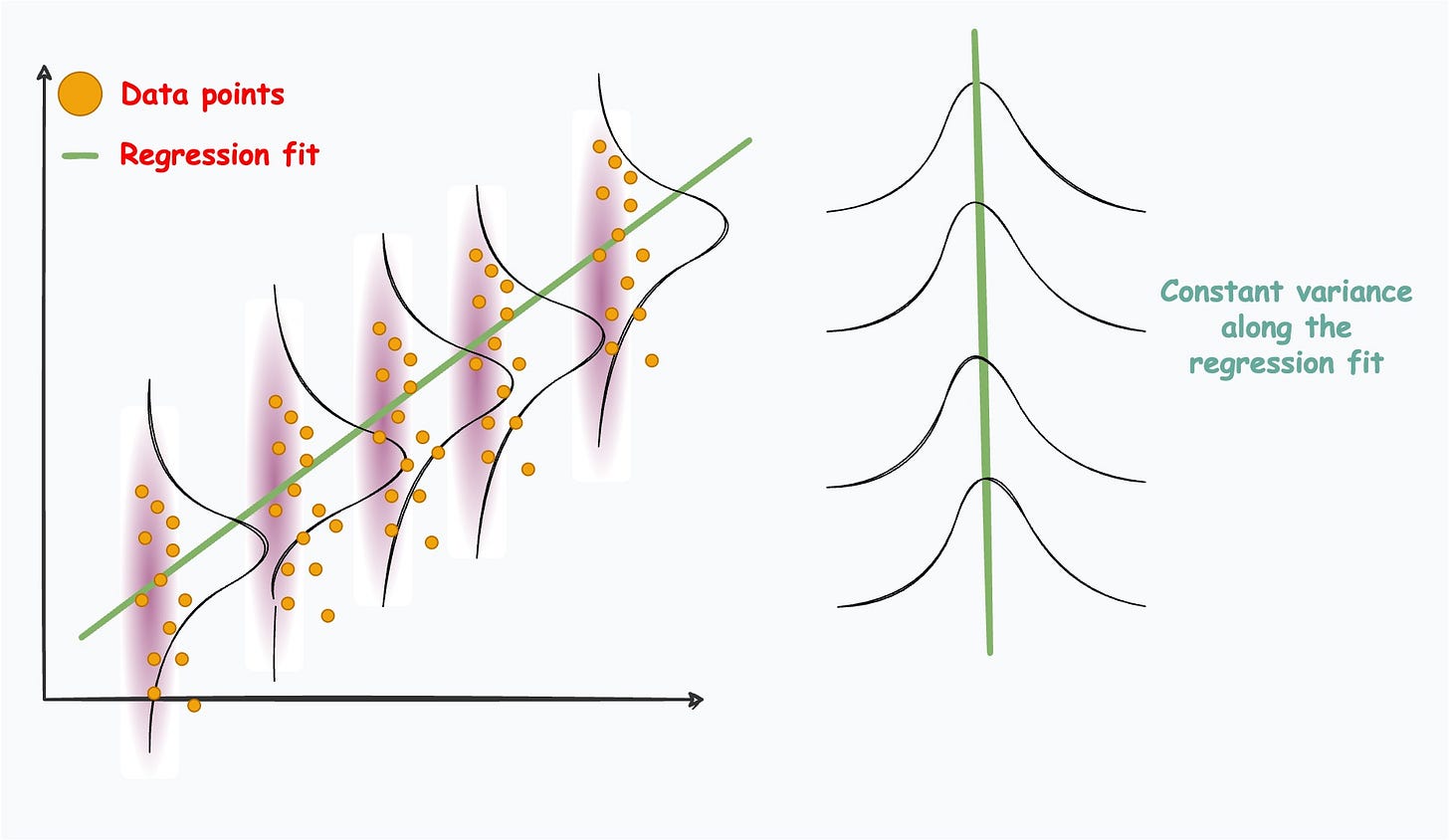
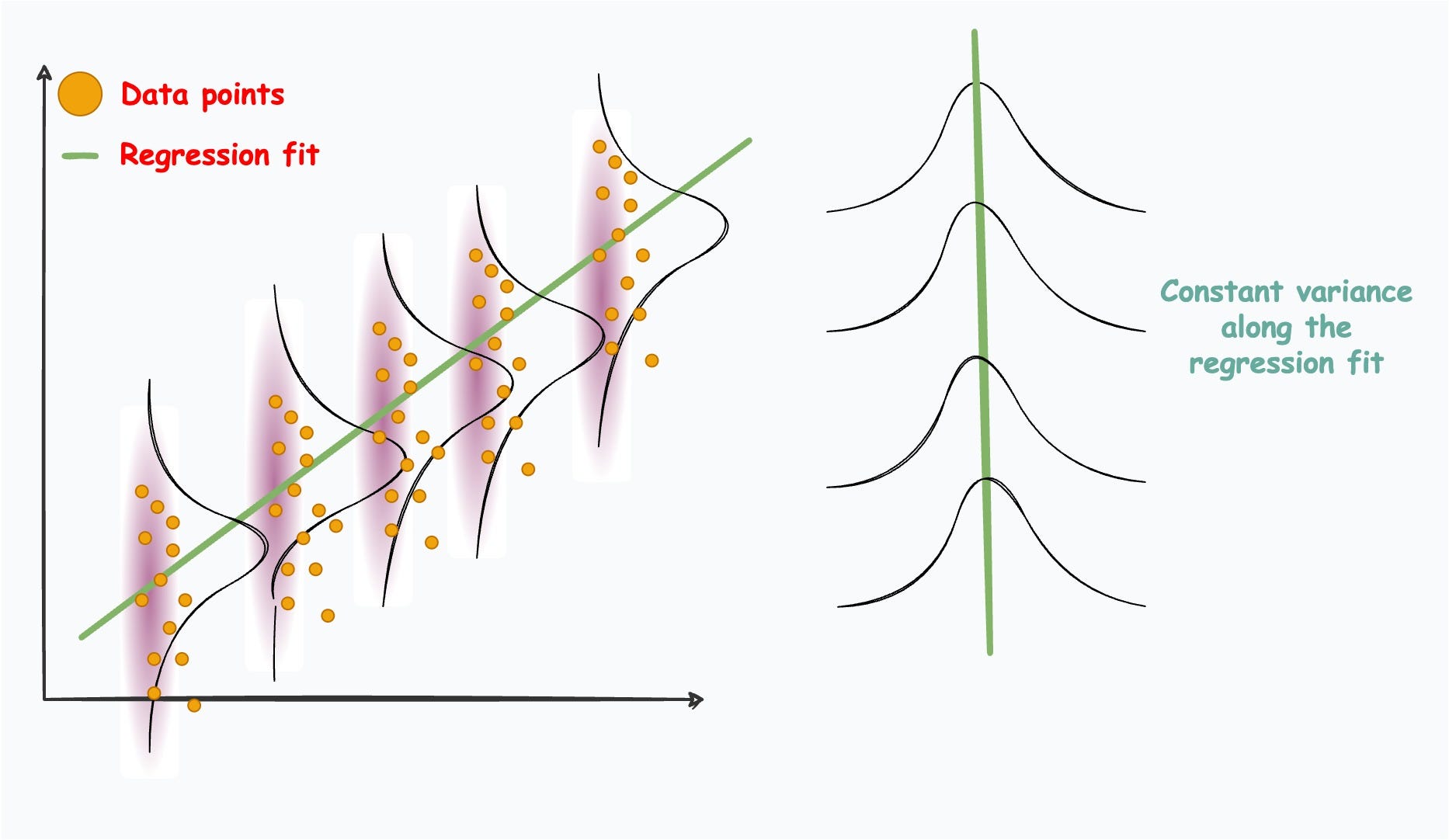
These conditions often restrict its applicability to data situations that do not obey the above assumptions.
In other words, nothing stops real-world datasets from violating these assumptions.
In fact, in many scenarios, the data might exhibit complex relationships, heteroscedasticity (varying variance), or even follow entirely different distributions altogether.
Yet, if we intend to build linear models, we should formulate better algorithms that can handle these peculiarities.
Generalized linear models (GLMs) precisely do that.
They relax the assumptions of linear regression to make linear models more adaptable to real-world datasets.
More specifically, they consider the following:
What if the distribution isn’t normal but some other distribution?


What if X has a more sophisticated relationship with the mean?
What if the variance varies with X?

The effectiveness of a specific GLM — Poisson regression over linear regression is evident from the image below:

Linear regression assumes the data is drawn from a Gaussian, when in reality, it isn’t. Hence, it underperforms.
Poisson regression adapts its regression fit to a non-Gaussian distribution. Hence, it performs significantly better.
If you are interested in learning more about this, I once wrote a detailed guide on this topic here: Generalized Linear Models (GLMs): The Supercharged Linear Regression.
It covers:
How does linear regression model data?
The limitations of linear regression.
What are GLMs?
What are the core components of GLMs?
How do they relax the assumptions of linear regression?
What are the common types of GLMs?
What are the assumptions of these GLMs?
How do we use maximum likelihood estimates with these GLMs?
How to build a custom GLM for your own data?
Best practices and takeaways.
👉 Interested folks can read it here: Generalized Linear Models (GLMs): The Supercharged Linear Regression.
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.

Thanks for reading :)
Whenever you are ready, here’s one more way I can help you:
Every week, I publish 1-2 in-depth deep dives (typically 20+ mins long). Here are some of the latest ones that you will surely like:
[FREE] A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 If you love reading this newsletter, feel free to share it with friends!
Finance and Marketing are expansive sectors where Generalized Linear Models (GLMs) find extensive application. And right, when it comes to handling count data, such as in Traffic Analysis, Poisson regression proves to be particularly beneficial.