
Generate Synthetic Datasets with Llama3
...for fine-tuning other LLMs.

The LLM that emerges from the pre-training phase isn’t entirely useful to engage with.
For instance, here’s how a pre-trained (not fine-tuned yet) model typically behaves when prompted:

It’s clear that the model simply continues the sentence as if it is one long text in a book or an article.
Generating synthetic data through existing LLMs and utilizing that for fine-tuning can improve this.
In this case, the synthetic data will have fabricated examples of human-AI interactions—an instruction or query paired with an appropriate AI response:

Lately, we’ve been playing around with Distilabel, an open-source framework that facilitates generating domain-specific synthetic text data using Llama-3.
This is great for anyone working on fine-tuning LLMs or building small language models (SLMs).
The underlying process is simple:
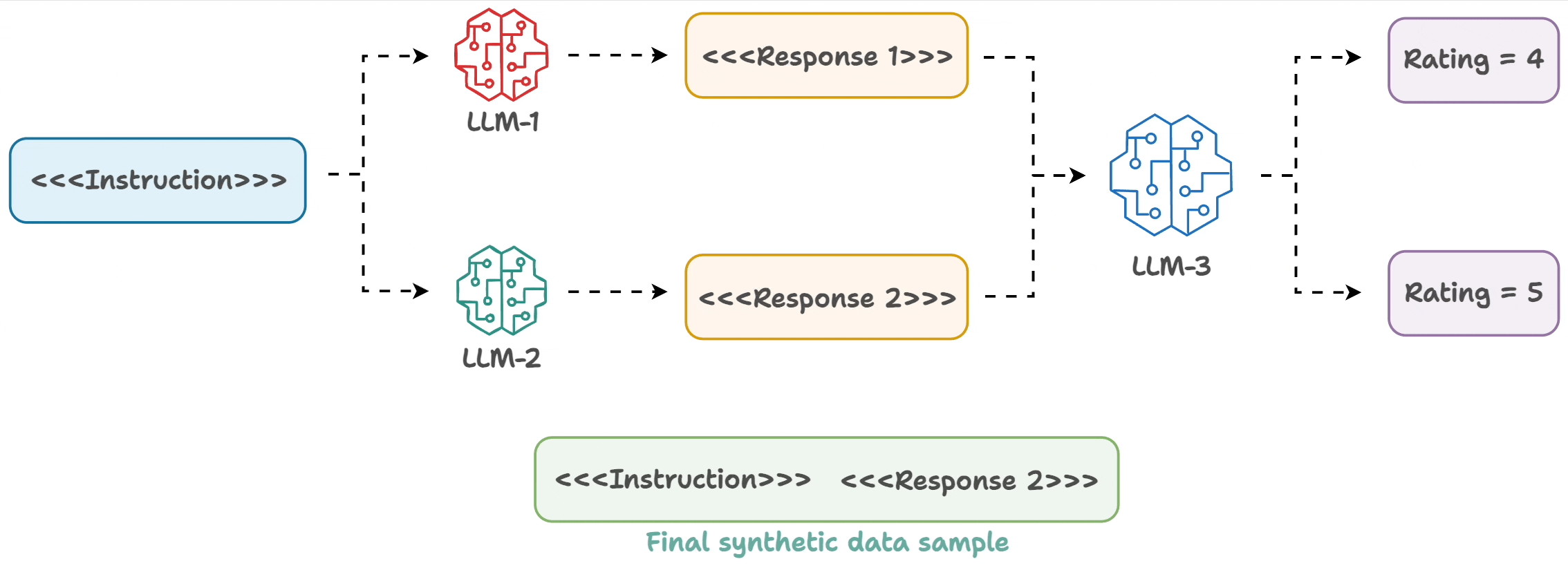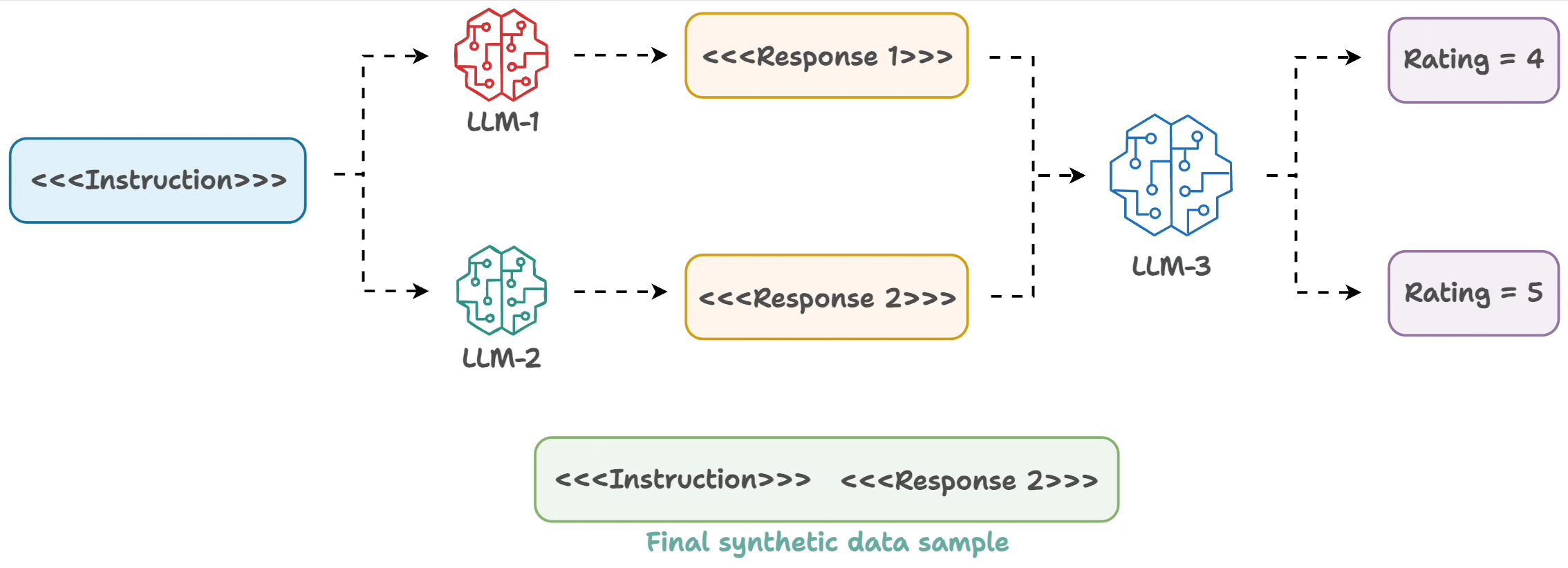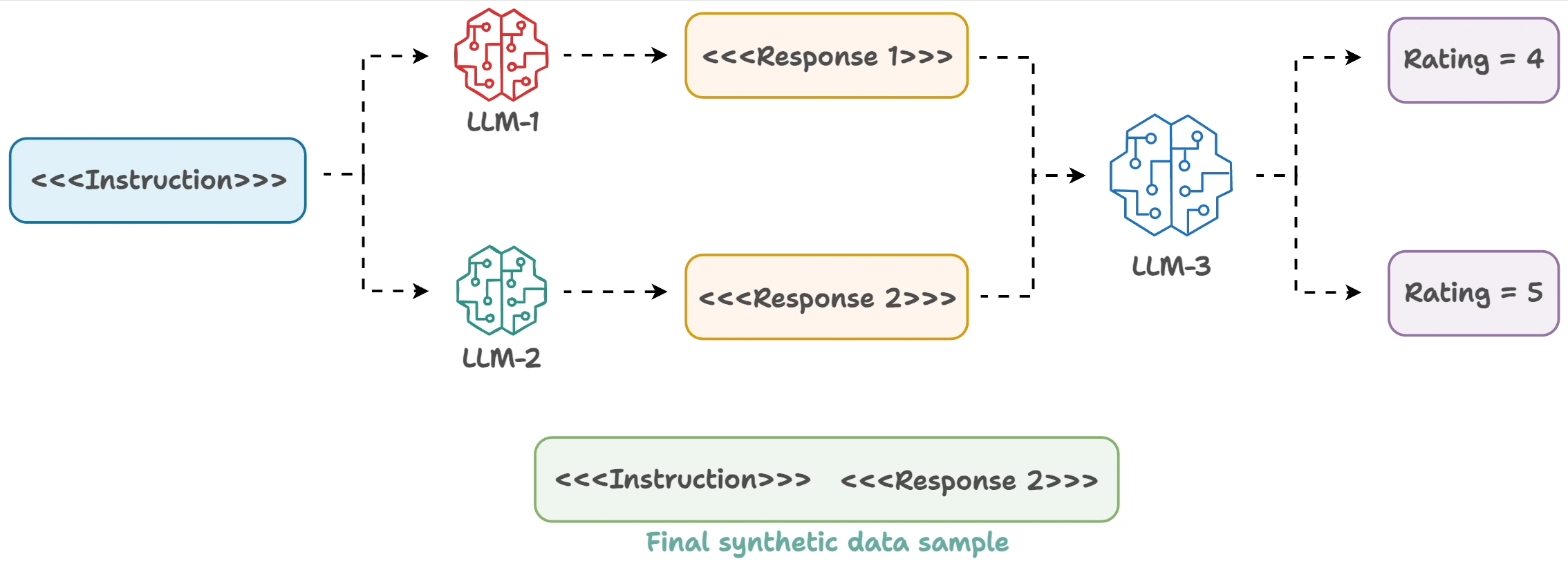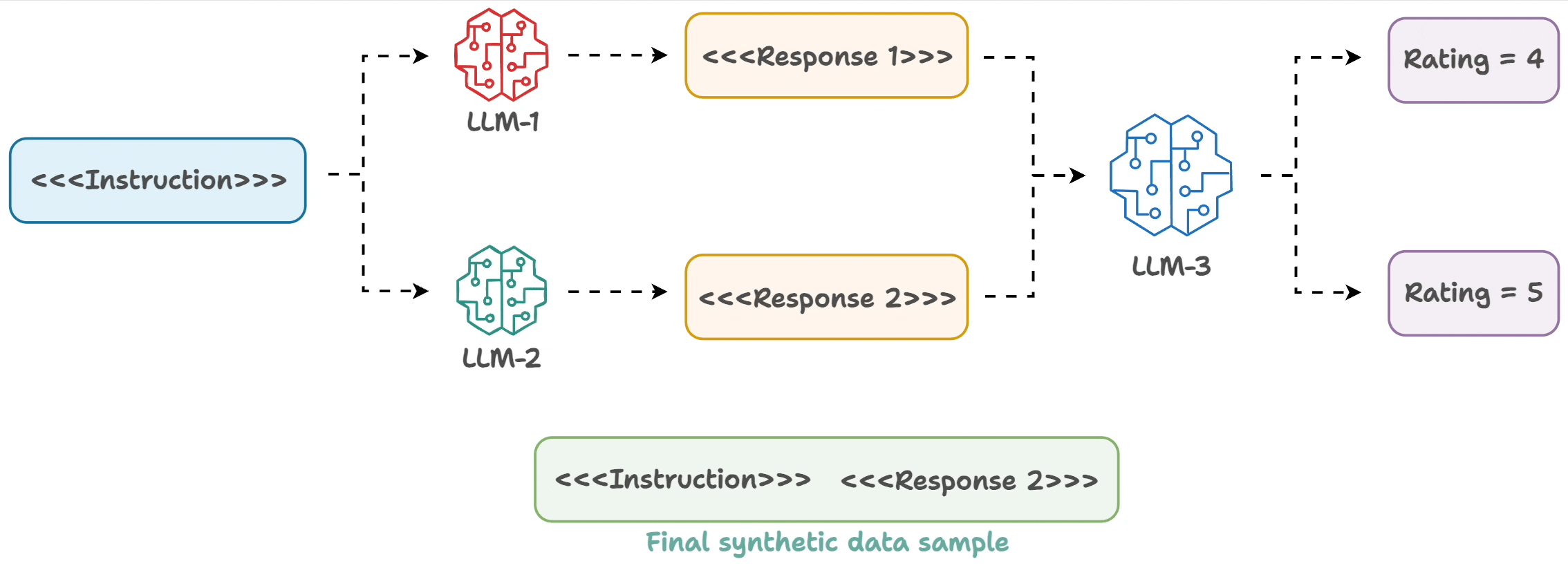
- Input an instruction.
- Two LLMs generate responses.
- A judge LLM rates the responses.
- The best response is paired with the instruction.
And you get the synthetic dataset!
A sample is shown below:

On a side note, this is quite similar to how we learned to evaluate our RAG pipelines in Part 2 of our RAG crash course.
Let’s look at the implementation below with the Distilabel library.
First, we start with some standard imports:

Next, we load the Lllama-3 models locally with Ollama (we covered the procedure to setup Ollama here):

Moving on, we define our pipeline:
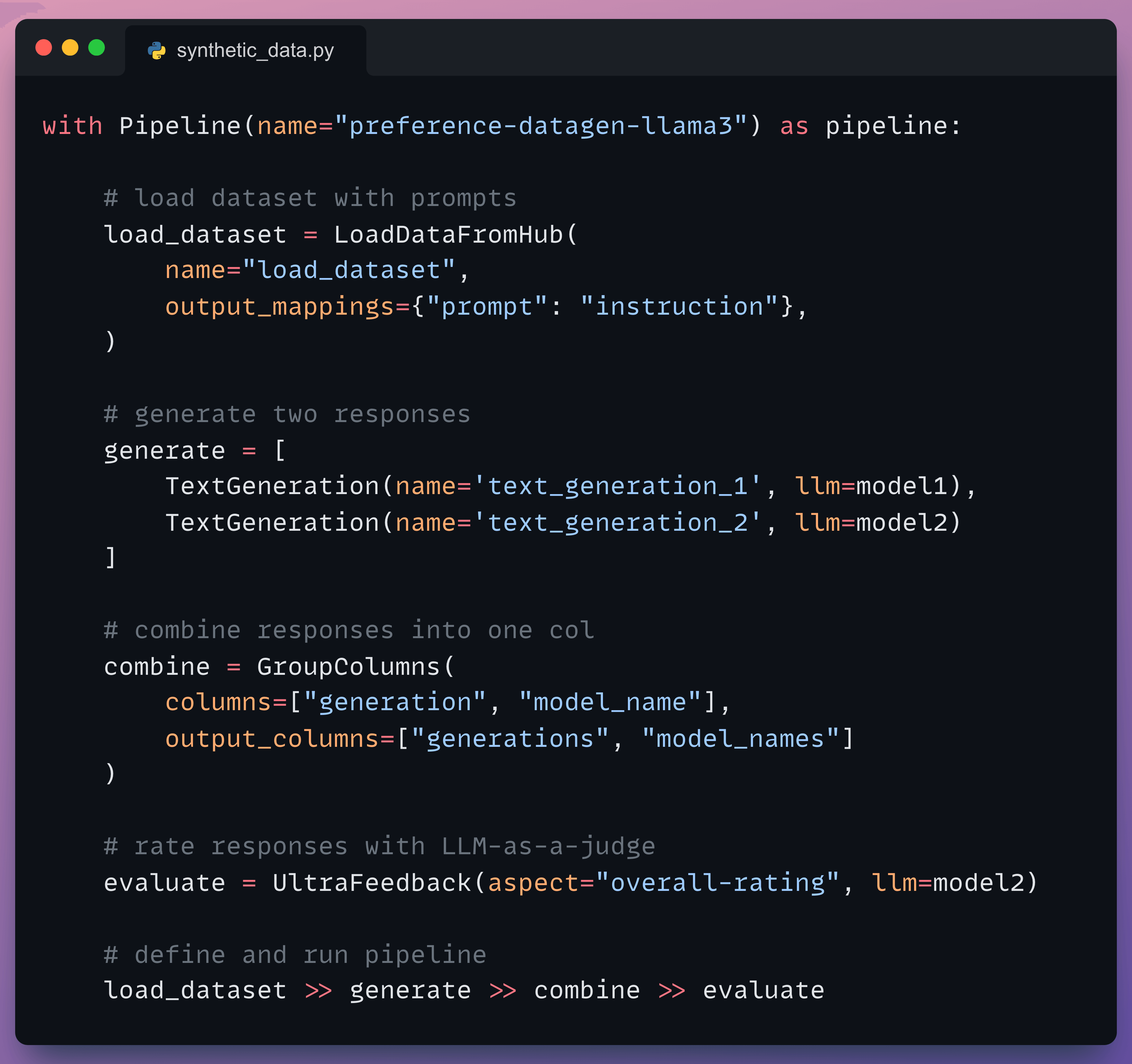
First, we load the dataset (we’ll pass it shortly).
Next, we generate two responses.
Once done, we combine the responses into one column (under the hood, a prompt template is also created for the third LLM).
Moving on, we evaluate the responses with an LLM.
Finally, we define and run the pipeline.
We execute this as follows:

Done!
This produces the instruction and response synthetic dataset as desired.
That was simple, wasn’t it?
This produces a dataset on which the LLM can be easily fine-tuned.
We’ll cover more about our learnings from synthetic data generation in future issues.
That said, if you know how to build a reliable RAG system, you can bypass the challenge and cost of fine-tuning LLMs.
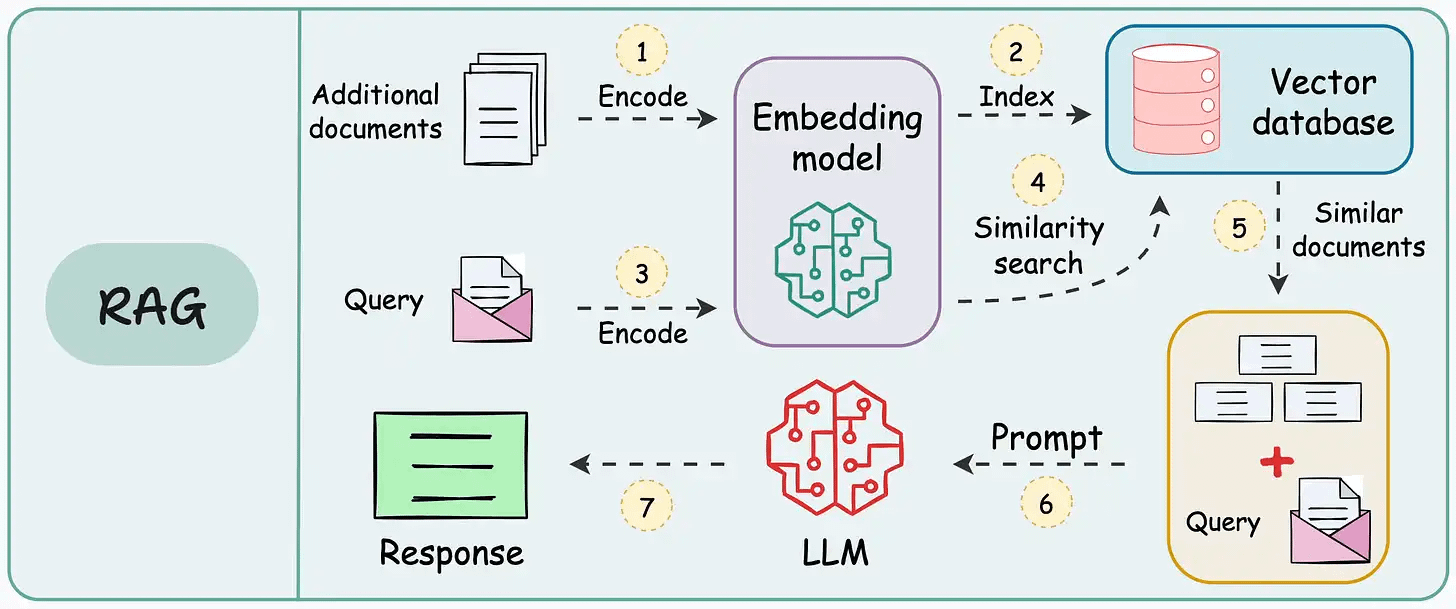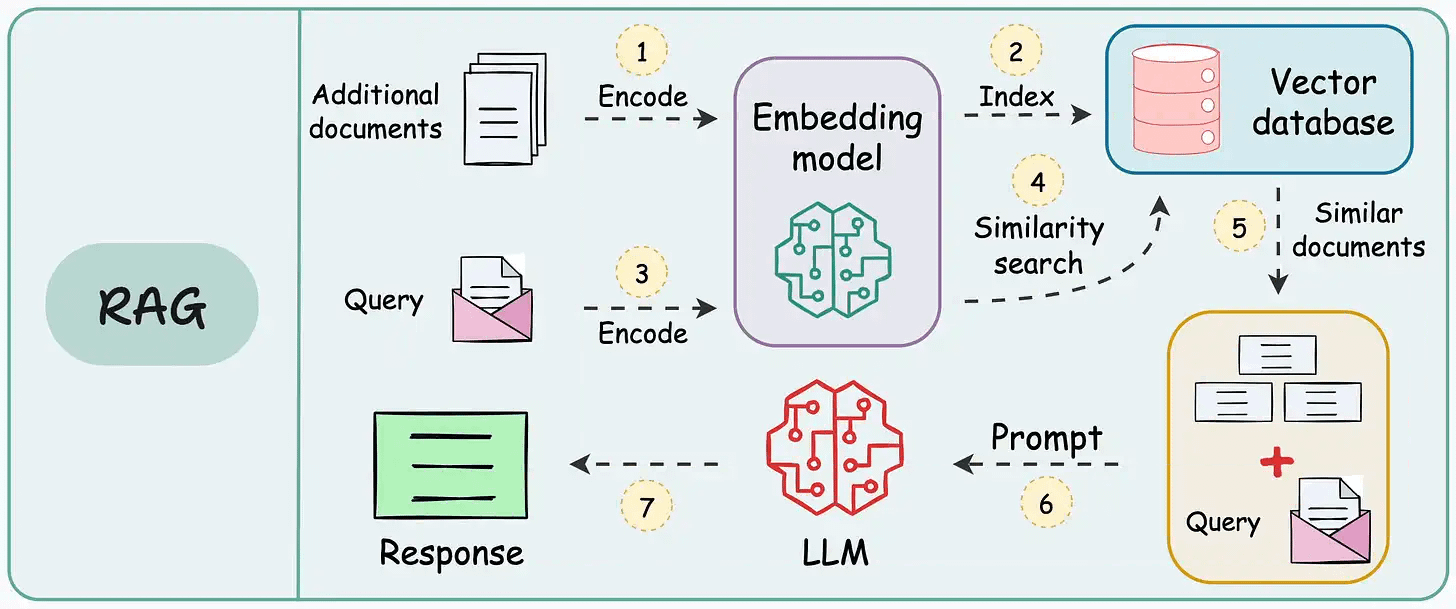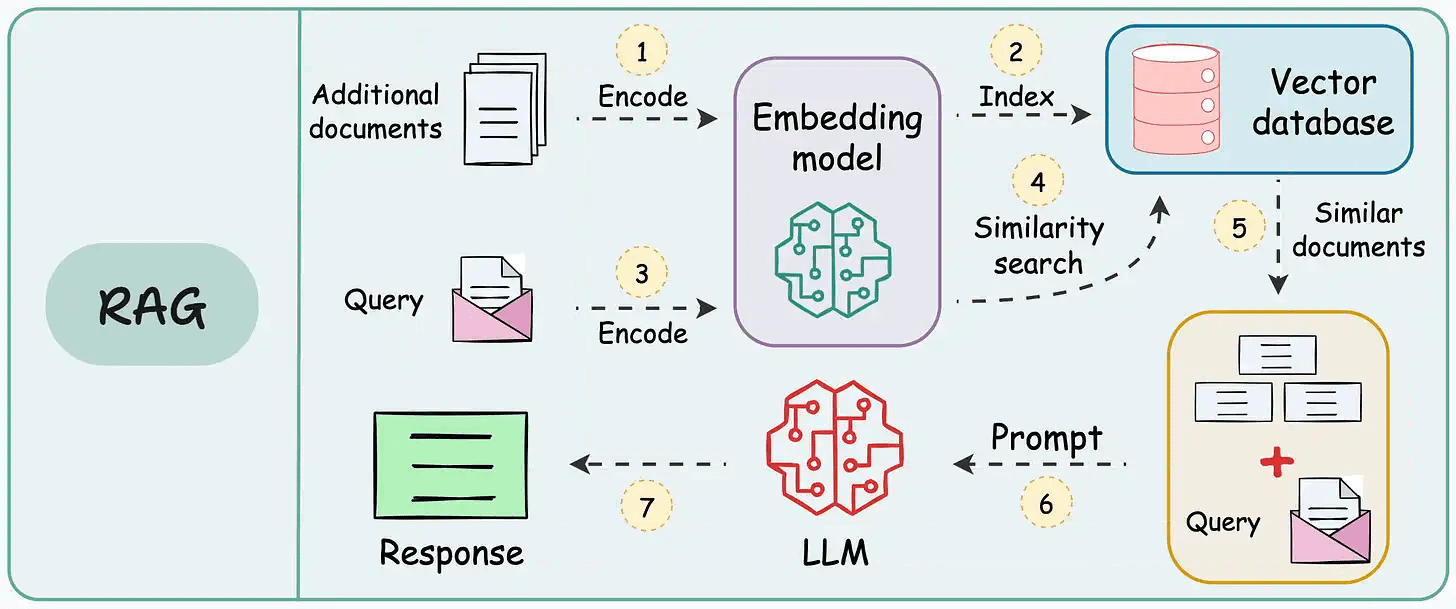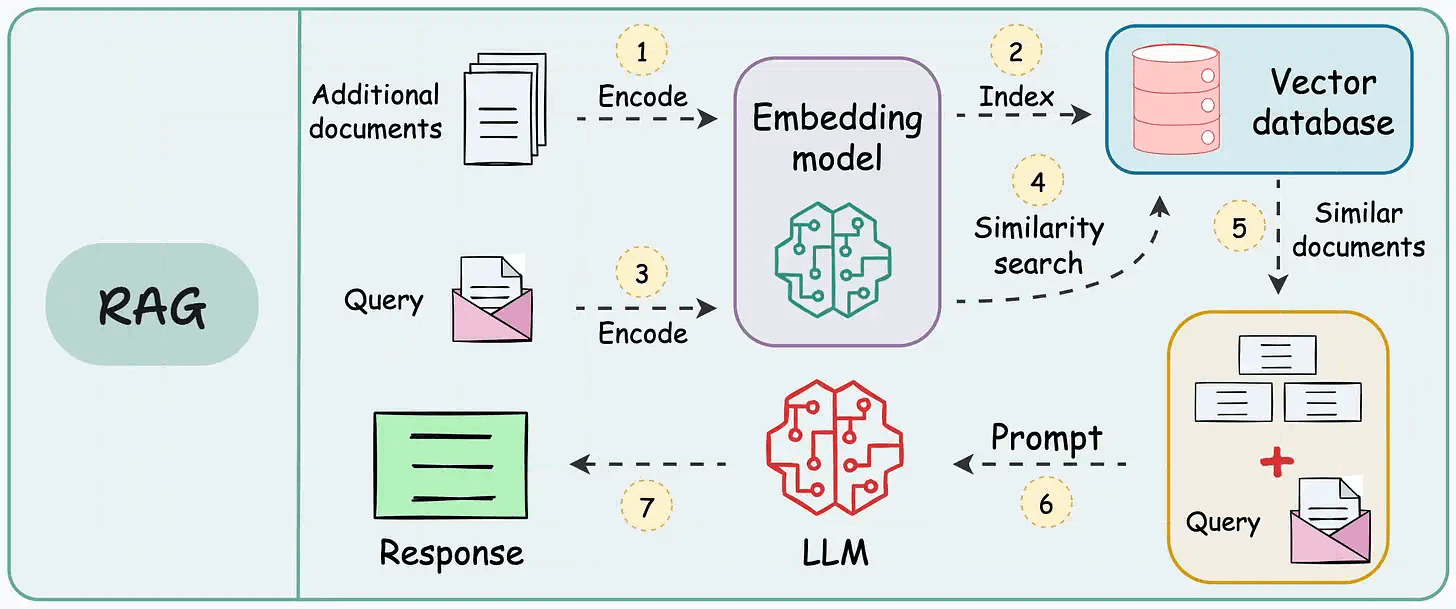
That’s a considerable cost saving for enterprises.
We started a crash course to help you implement reliable RAG systems, understand the underlying challenges, and develop expertise in building RAG apps on LLMs, which every industry cares about now.
Read the first part here →
Read the second part here →
Read the third part here →
Read the fourth part here →
Read the fifth part here [OPEN ACCESS] →
Of course, if you have never worked with LLMs, that’s okay. We cover everything in a practical and beginner-friendly way.
👉 Over to you: What are some other ways to generate synthetic data for fine-tuning?
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
Hi, Avi
May I ask how long it takes you to run a pipeline with the same configuration?