
Generate Your Own LLM Fine-tuning Dataset
100% locally.

GenAI Engineering Convergence Conference by CometML [FREE and VIRTUAL EVENT]

Comet is organizing Convergence 2025, a two-day virtual event focused on GenAI engineering.
Dates: May 13th-14th, 2025.
You’ll hear from industry experts on how to build, evaluate, and deploy LLM-based systems responsibly and effectively.
Here’s what you’ll learn:
How to build safer, faster, and more sustainable GenAI systems.
How to ship reliable LLM apps using evaluation-driven development.
Strategies for scaling LLM performance and optimizing deployments.
Best practices for designing, building, and observing autonomous agents.
Engineering insights from scaling vector databases for intelligent systems.
Real-world insights from Uber, Apple, Meta, and other leaders on RAG eval.
And much more.
Thanks to CometML for partnering today!
Generate Your Own LLM Fine-tuning Dataset
Once an LLM has been pre-trained, it simply continues the sentence as if it is one long text in a book or an article.
For instance, check this to understand how a pre-trained LLM behaves when prompted:

Generating a synthetic dataset using existing LLMs and utilizing it for fine-tuning can improve this.
The synthetic data will have fabricated examples of human-AI interactions.
Check this sample:

This process is called instruction fine-tuning and it is described in the animation below:
Distilabel is an open-source framework that facilitates generating domain-specific synthetic text data using LLMs.
Check this to understand the underlying process👇
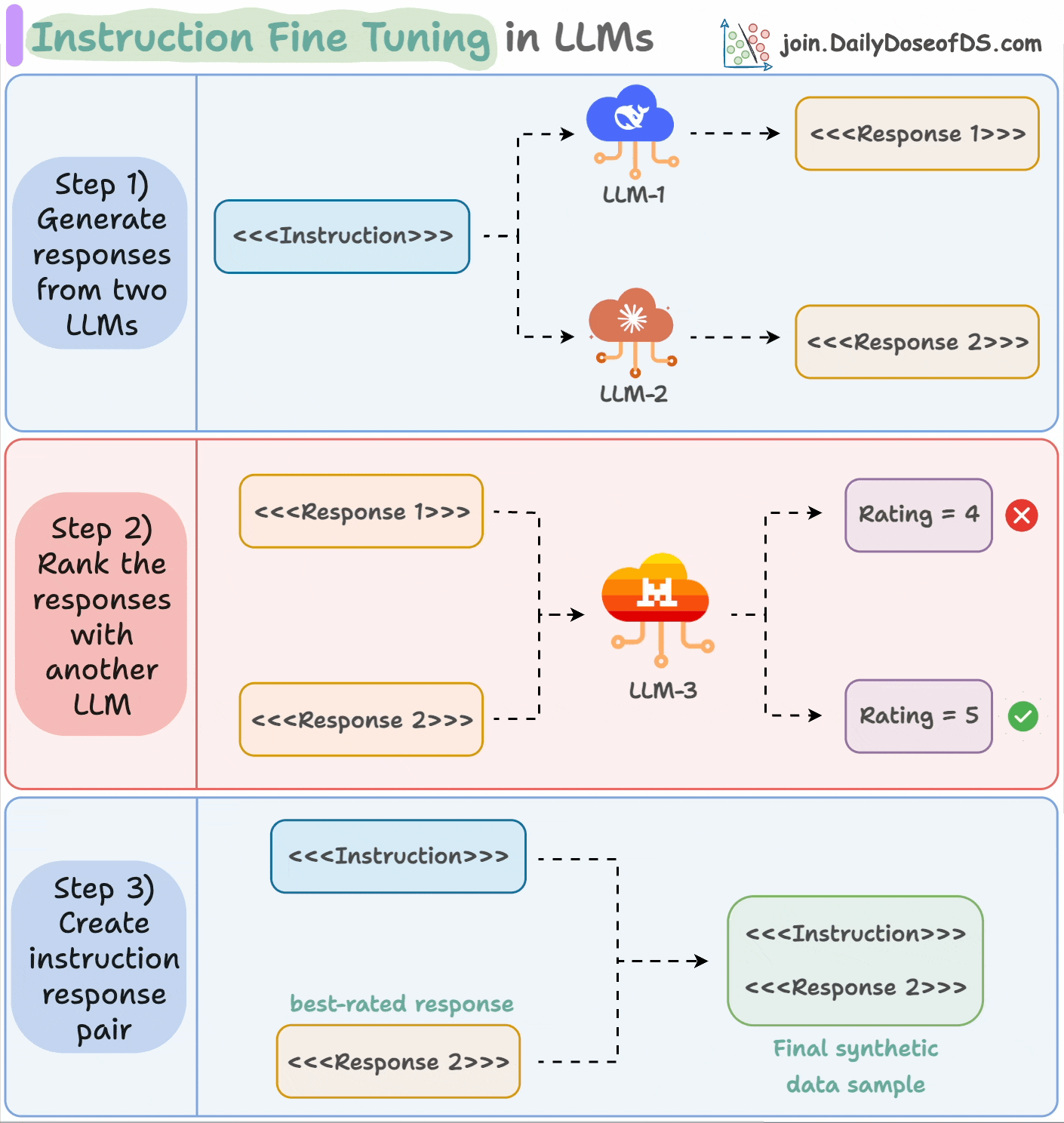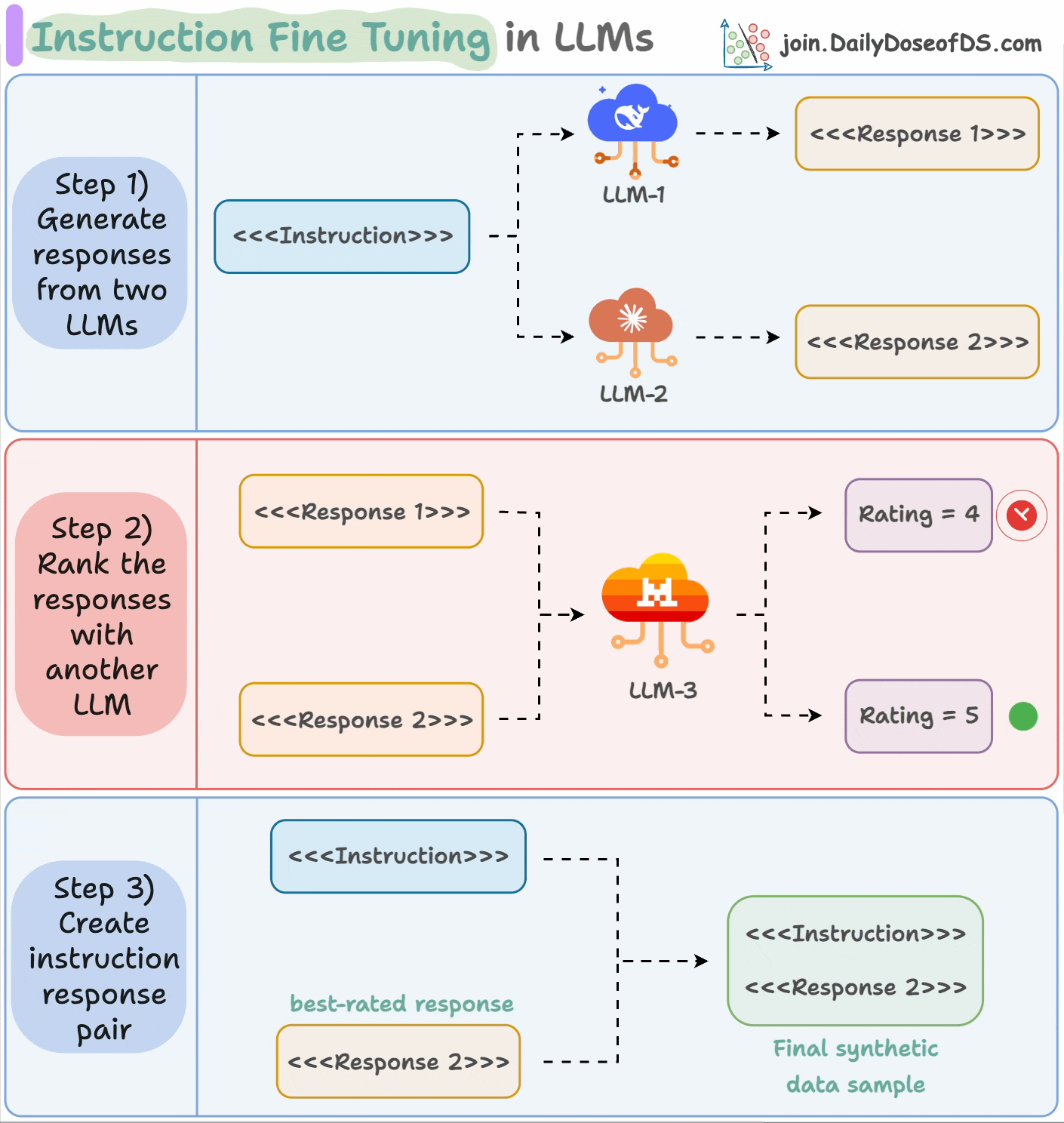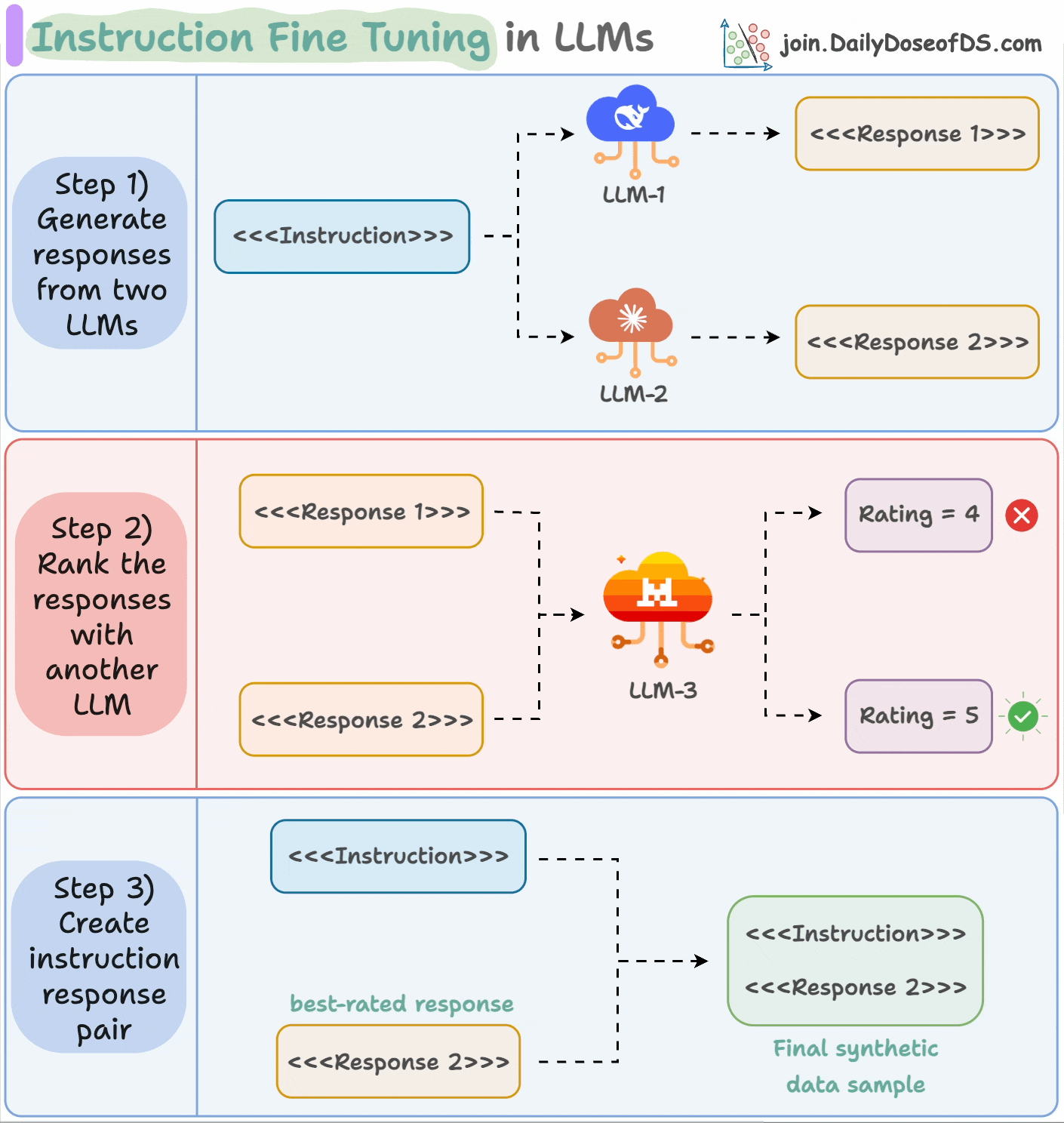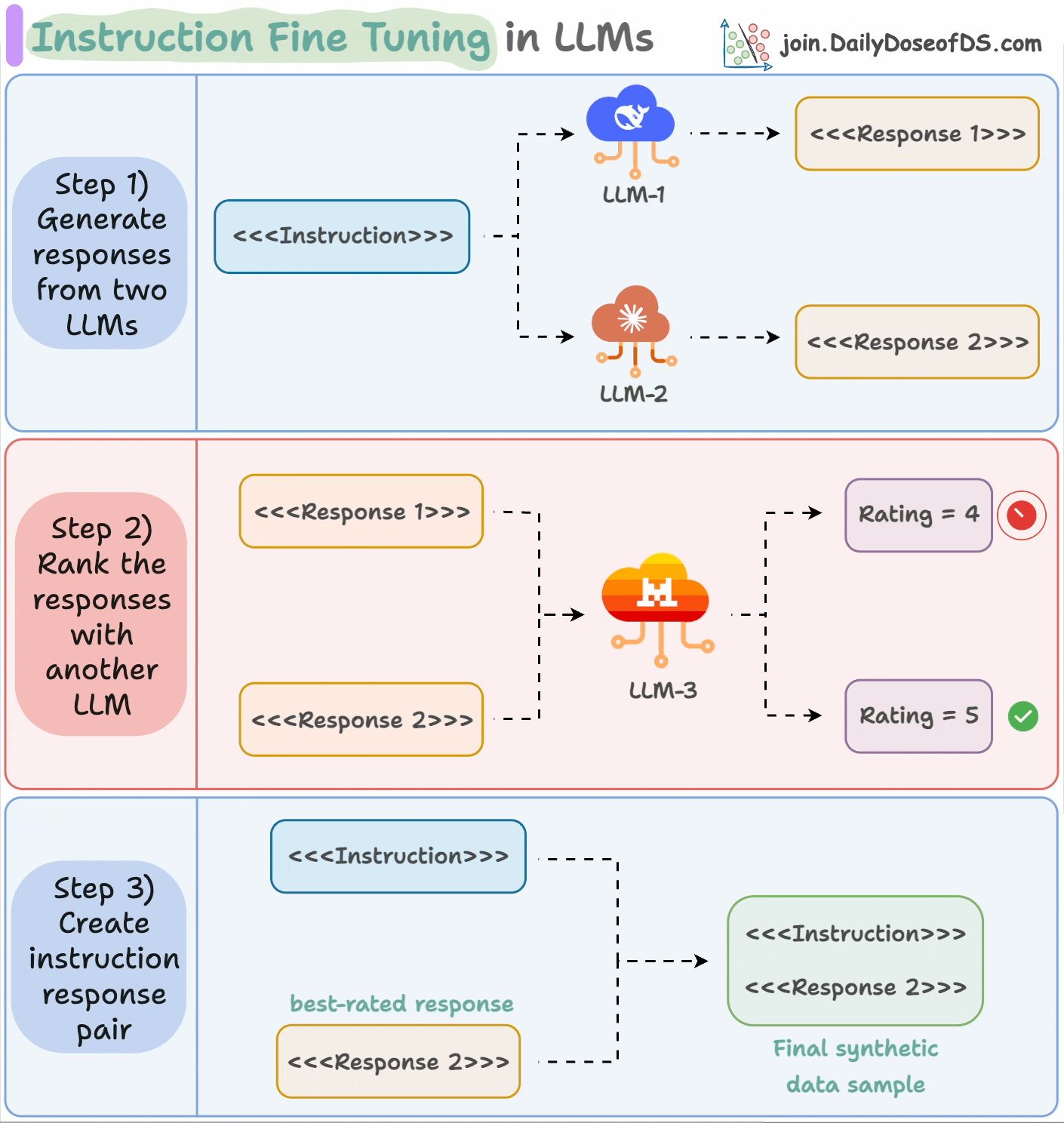
Input an instruction.
Two LLMs generate responses.
A judge LLM rates the responses.
The best response is paired with the instruction.
And you get the synthetic dataset!
Next, let's look at the code.
First, we start with some standard imports:

Next, we load the Llama-3 models locally with Ollama:

Moving on, we define our pipeline:
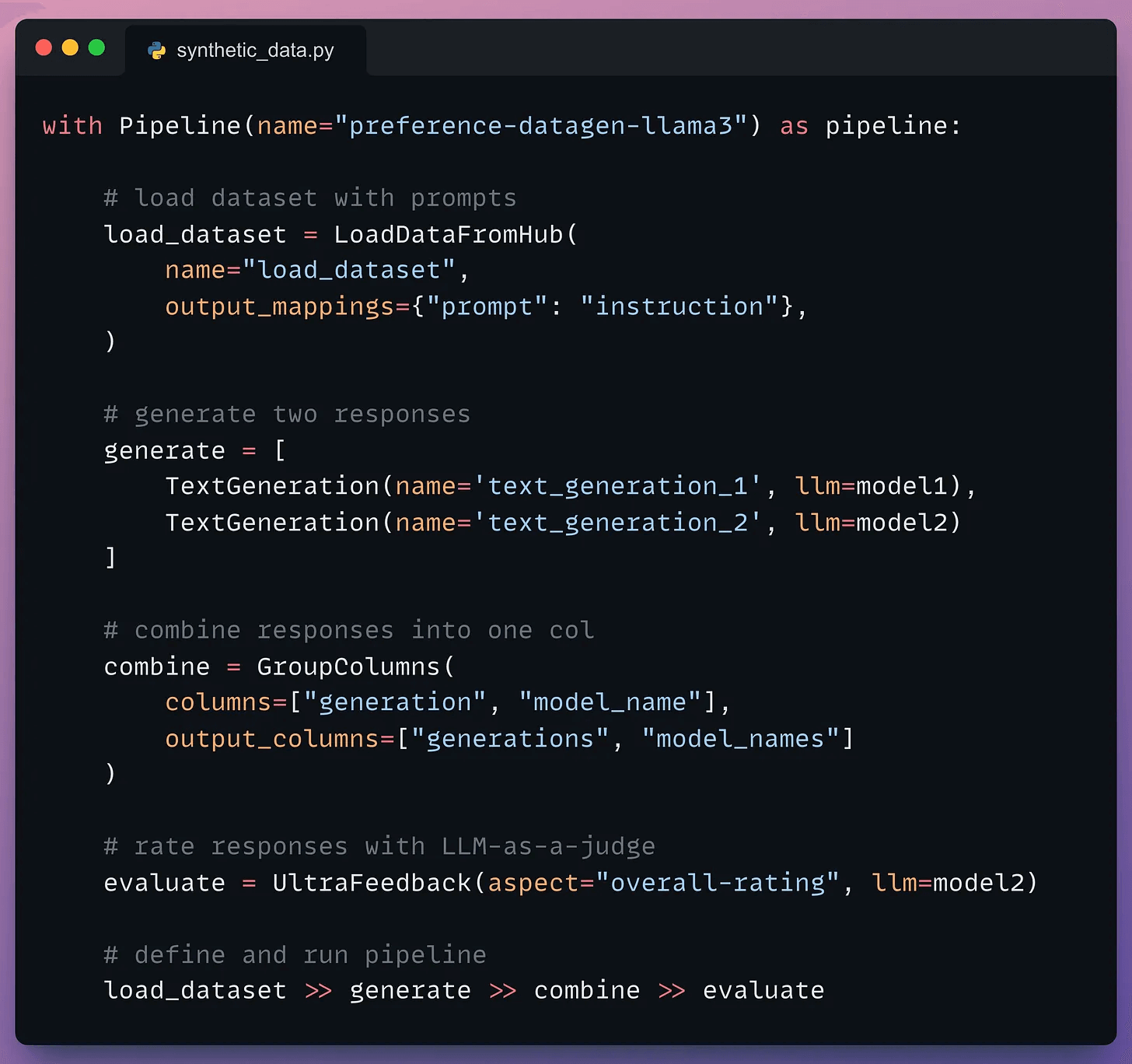
First, we load the dataset (we’ll pass it shortly).
Next, we generate two responses.
Once done, we combine the responses into one column (under the hood, a prompt template is also created for the third LLM).
Moving on, we evaluate the responses with an LLM.
Finally, we define and run the pipeline.
Once the pipeline has been defined, we need to execute it by giving it a seed dataset.
The seed dataset helps it generate new but similar samples. So we execute the pipeline with our seed dataset as follows:

Done!
This produces the instruction and response synthetic dataset as desired.
Check the sample below:

That was simple, wasn’t it?
This produces a dataset on which the LLM can be easily fine-tuned.
We’ll cover more about our learnings from synthetic data generation in future issues.
That said, if you know how to build a reliable RAG system, you can bypass the challenge and cost of fine-tuning LLMs.
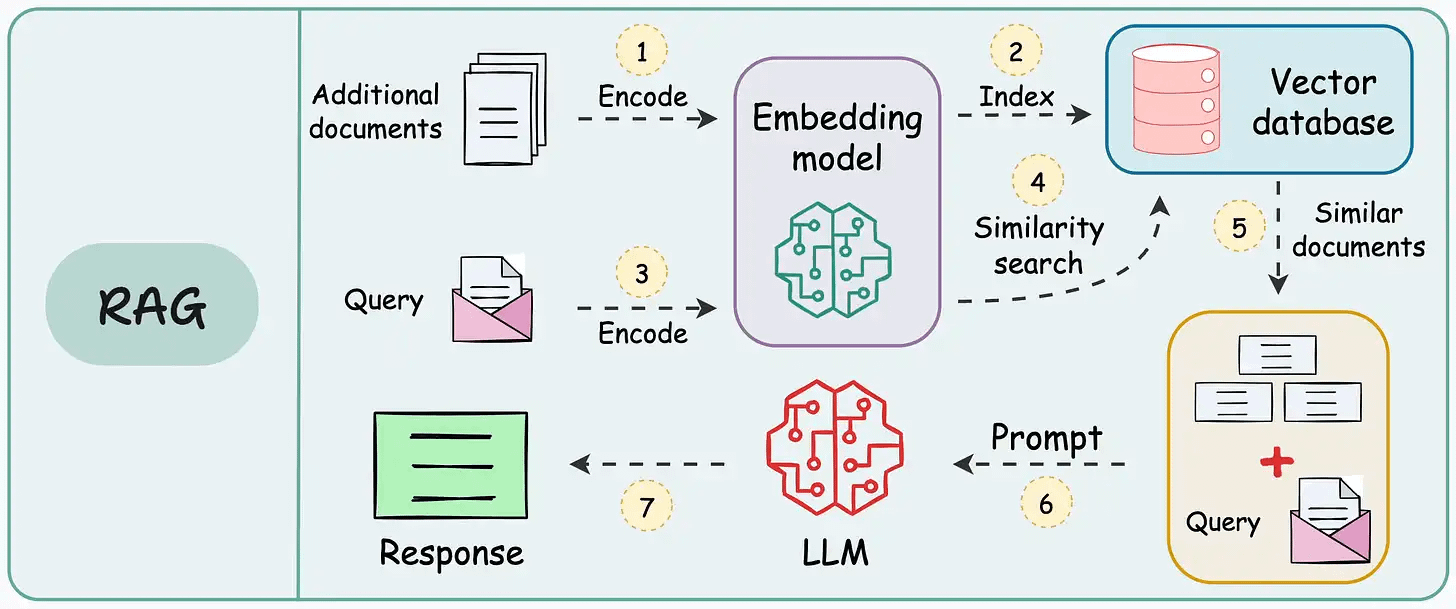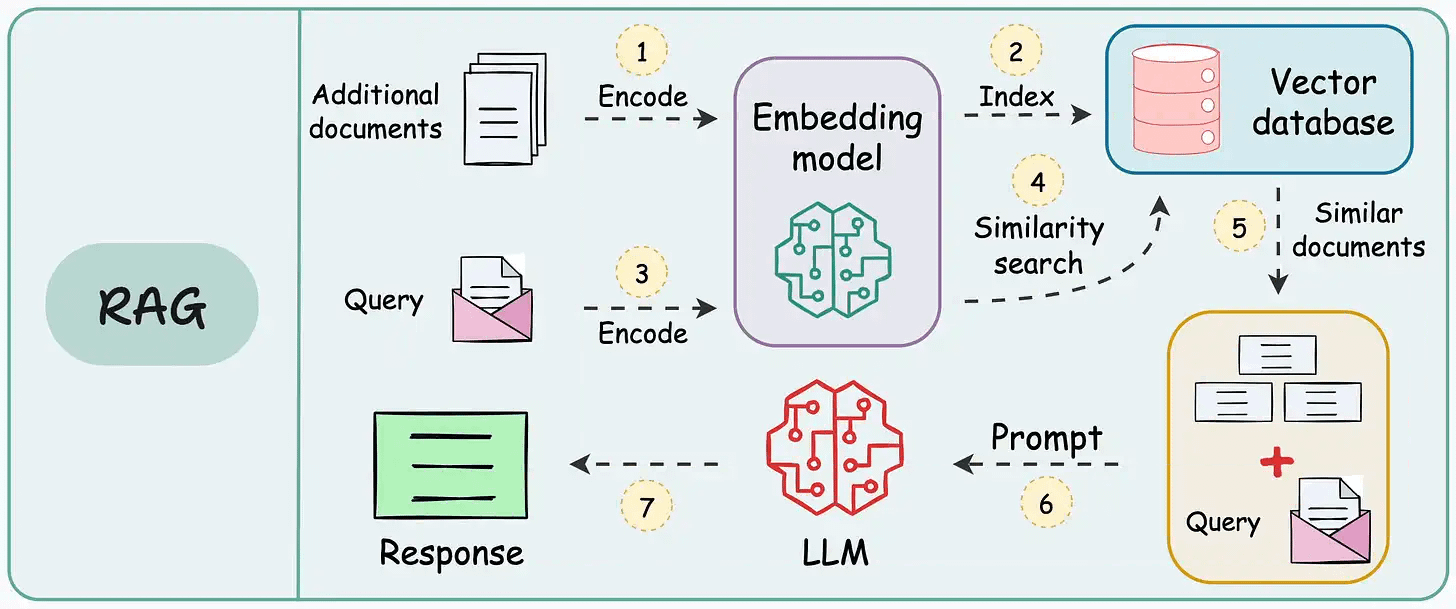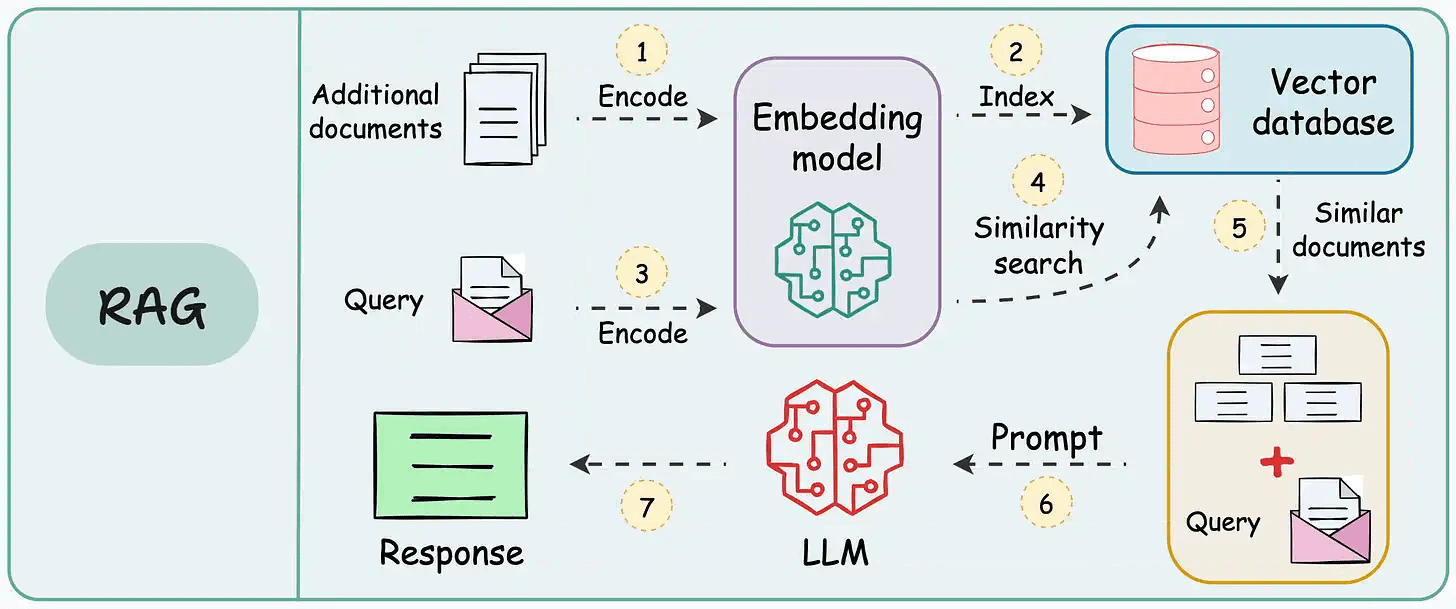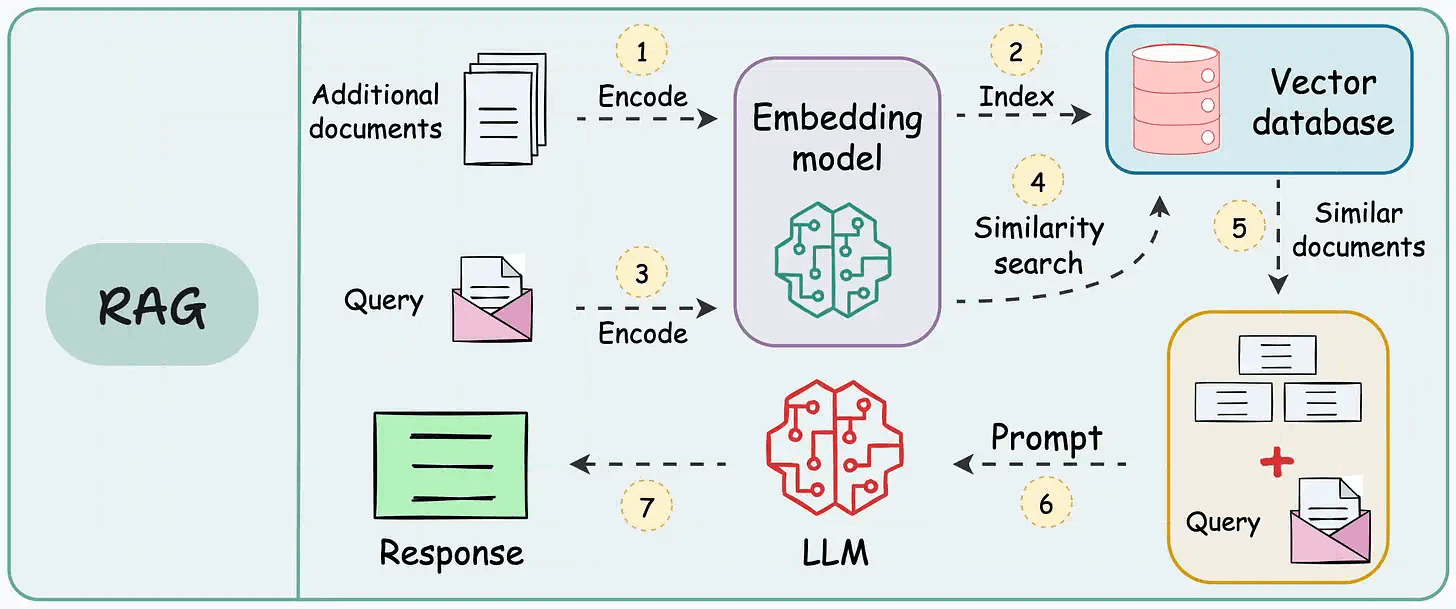
That’s a considerable cost saving for enterprises.
We started a crash course to help you implement reliable RAG systems, understand the underlying challenges, and develop expertise in building RAG apps on LLMs, which every industry cares about now.
In Part 1, we explored the foundational components of RAG systems, the typical RAG workflow, and the tool stack, and also learned the implementation.
In Part 2, we understood how to evaluate RAG systems (with implementation).
In Part 3, we learned techniques to optimize RAG systems and handle millions/billions of vectors (with implementation).
In Part 4, we understood multimodality and covered techniques to build RAG systems on complex docs—ones that have images, tables, and texts (with implementation)
In Part 5, we understood the fundamental building blocks of multimodal RAG systems that will help us improve what we built in Part 4.
In Part 6, we utilized the learnings from Part 5 to build a much more extensive multimodal RAG system.
In Part 7, we learned how to build graph RAG systems. Here, we utilized a graph database to store information in the form of entities and relations, and build RAG apps over.
In Part 8, we learned how to improve retrieval and rerankers with ColBERT, to produce much more coherent responses at scale.
In Part 9, we built vision-driven RAG systems and learned about advanced multimodal RAG systems.
Of course, if you have never worked with LLMs, that’s okay. We cover everything in a practical and beginner-friendly way.
👉 Over to you: What are some other ways to generate synthetic data for fine-tuning?
Thanks for reading!