
Google solved an Old RNN Problem
A better middle ground between RNNs and Transformers.

Devs shipped a new class of AI Agents
To understand why it matters, you need to see where it sits.
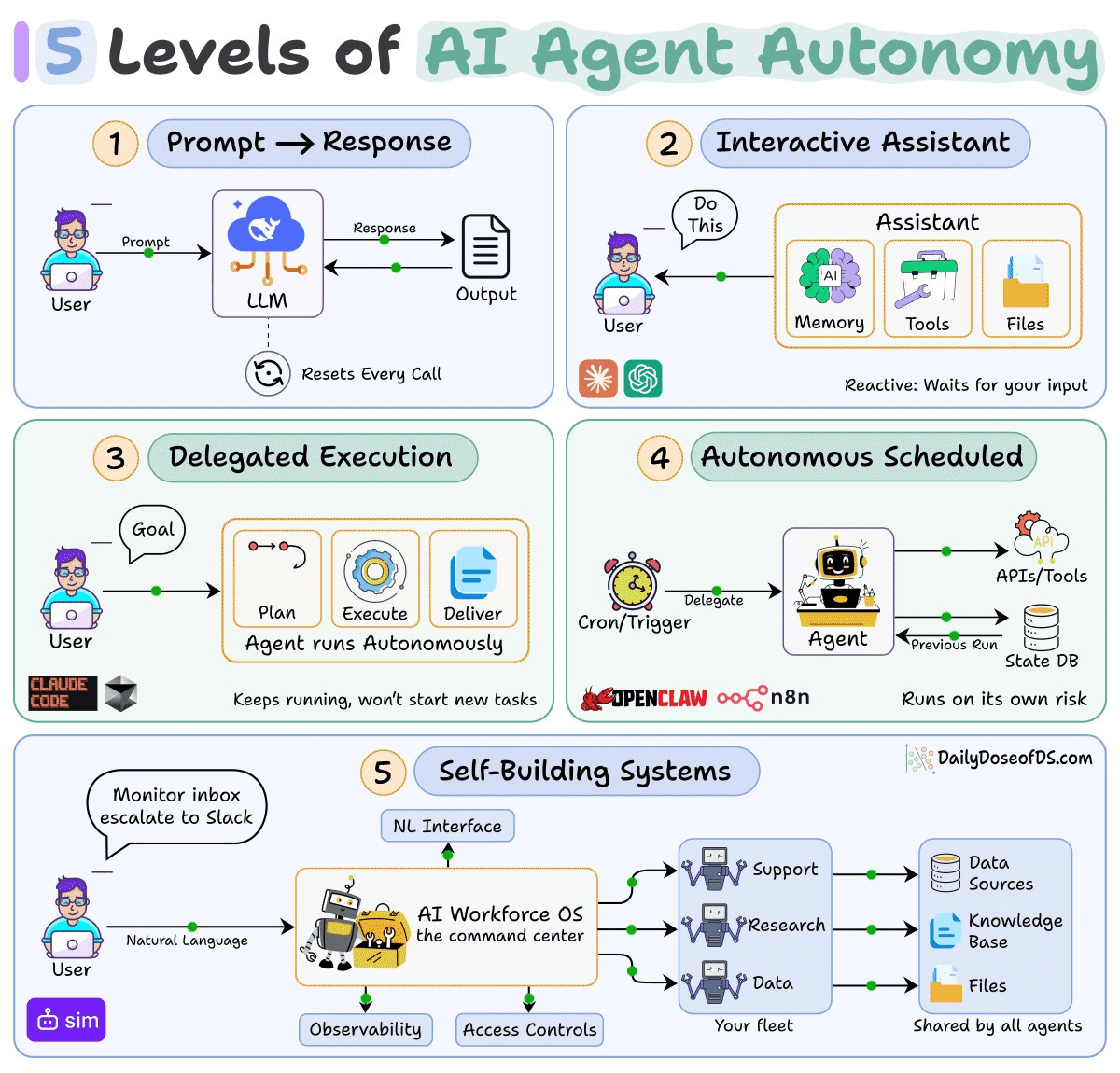
Level 1: Prompt → Response
Each call is stateless. The model can use tools/APIs within a single request but nothing persists. Most production LLM apps are sophisticated Level 1 wrappers.
Level 2: Interactive assistant
The platform handles persistence for you with memory, tools, files, connectors. ChatGPT and Claude live here. These are capable, but entirely reactive.
Level 3: Delegated execution
You define the goal and the agent owns the execution. Claude Code, Codex, and deep research operate here. Your task keeps running when you walk away, but the agent won’t start new work on its own.
Level 4: Autonomous scheduled operation
The agent runs on its own clock using cron, webhooks, or event triggers with persistent state across runs. OpenClaw with heartbeat, n8n with AI nodes, or the custom stacks devs stitch together.
Level 5: Self-building systems
Tools like Lovable and Bolt already go from prompt to deployed app. But the output is a web app that sits there until someone interacts with it.
Level 5 is different.
You can say “monitor my competitors’ blogs, store new posts in a table, and Slack me when they launch a product” and then the agent creates the database schema, connects the integrations, sets the schedule, and deploys a workflow that runs every morning on its own. No one needs to be present.
The workflow it just created runs on a schedule, maintains persistent state, and acts without human initiation.
Those are the exact characteristics of Level 4. So the output of a Level 5 agent is itself a Level 4 agent.
If you want to see this in practice, Sim (GitHub repo) shipped Mothership as an early implementation of this.
You can describe what you need, and it creates tables, wires workflow blocks, configures integrations, and sets the schedule.
It’s fully open-source (27k+ GitHub stars) so you can easily self-host it and see the full implementation on GitHub.
Google solved an old RNN problem
A new paper from Google Research introduces “Memory Caching,” and the idea is quite simple.

Here’s the problem it solves:
Modern RNNs compress the entire input into a single fixed-size memory state. As sequences get longer, old information gets overwritten. That’s why they still struggle with recall-heavy tasks compared to Transformers.
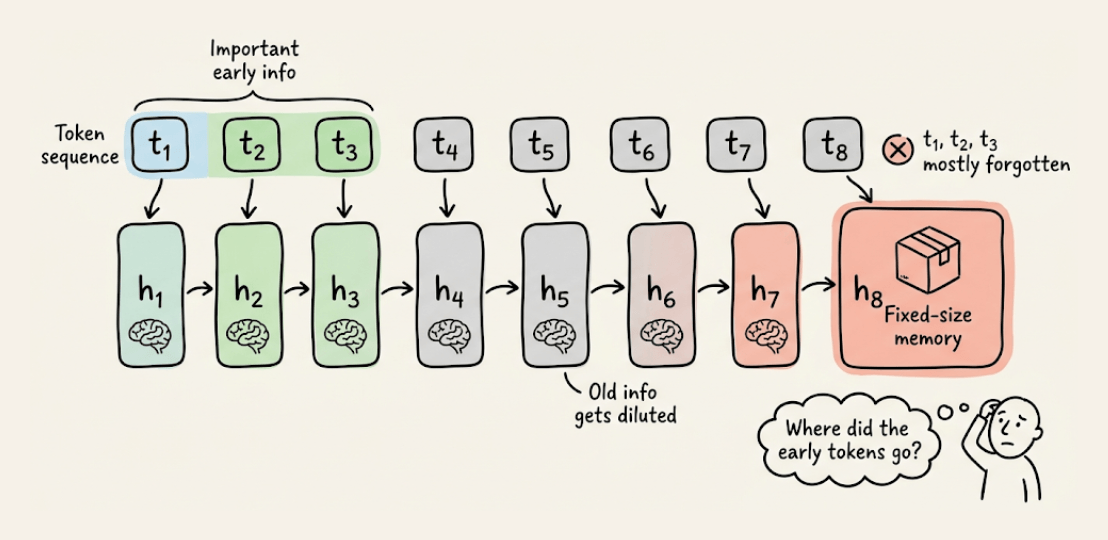
Memory Caching addresses this by splitting the sequence into segments and saving the RNN’s memory state at the end of each segment.
When generating output, each token looks back at all these saved checkpoints, not just the current memory.
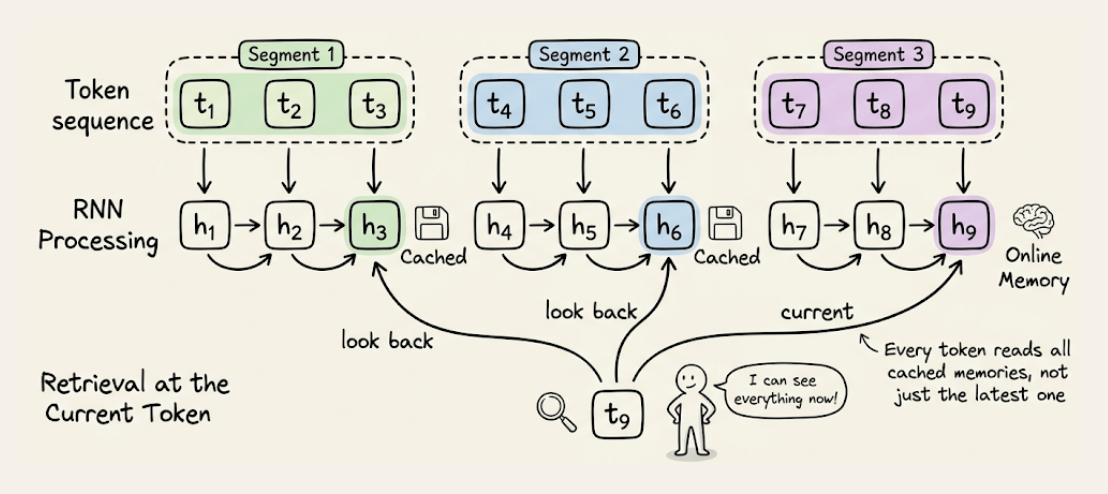
The complexity trade-off is elegant:
Standard RNNs: O(L)
Transformers: O(L²)
Memory Caching: O(NL), where N = number of segments
You control the trade-off by choosing how many segments to cache. The model smoothly interpolates between RNN-like efficiency and Transformer-like recall.
The paper proposes four ways to use these cached memories:
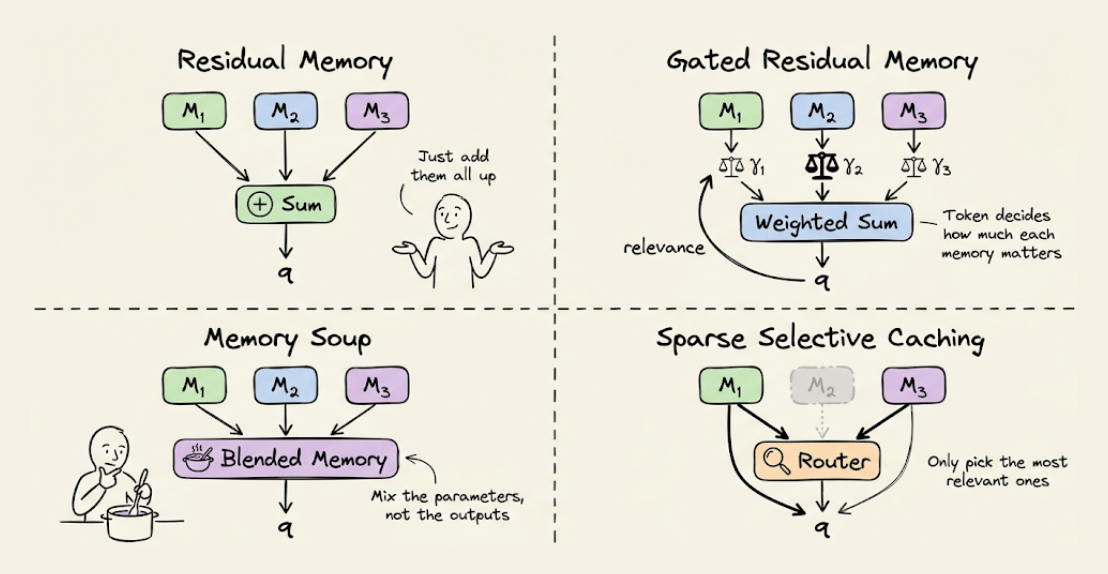
Residual Memory: just sum all cached states (simplest)
Gated Residual Memory (GRM): input-dependent gates that weigh each segment’s relevance to the current token
Memory Soup: interpolates the actual parameters of cached memories into a custom per-token network
Sparse Selective Caching (SSC): MoE-style routing that picks only the most relevant segments
Gated Residual Memory (GRM) consistently performs best across tasks.
Under simplifying assumptions, hybrid architectures that interleave RNN and attention layers can be viewed as a special case of Memory Caching. This gives clean intuition for why hybrid models work. They’re implicitly caching memory states.
On recall-heavy tasks, Memory Caching significantly closes the gap between RNNs and Transformers. When applied to already strong models like Titans, it pushes them even further ahead on language understanding benchmarks.
Transformers still lead on the hardest retrieval tasks like UUID lookup at long contexts. But the direction is clear that you don’t need to choose between fixed memory and quadratic attention. There’s a useful middle ground now.
All experiments are at an academic scale (up to 1.3B params). Whether these gains hold at the frontier scale remains open.
This comes from the same team behind Titans and MIRAS, so it’s part of a larger research program on memory-augmented sequence models.
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.