
GROUPING SETS — A HIGHLY Underrated Technique to Run Multiple Aggregations While Scanning the Table Only Once
A lesser-known and much efficient way to run multiple aggregations.

Whenever running multiple aggregations on some table, most people write multiple SQL queries — one query per aggregation.
Finally, if the results are to be gathered in a single table, they aggregate all the above tables using UNION or UNION ALL (as needed).
But this is among the most inefficient ways to approach this.
Let me explain with an example.
Consider an organization that has the following Employees table in their database:

The task is to get the following information in the same table:
The total employees in each
City→ This will involve an aggregation on theCitycolumn.The total full-time employees and interns in each
City→ This will involve an aggregation on theCityandStatuscolumn.
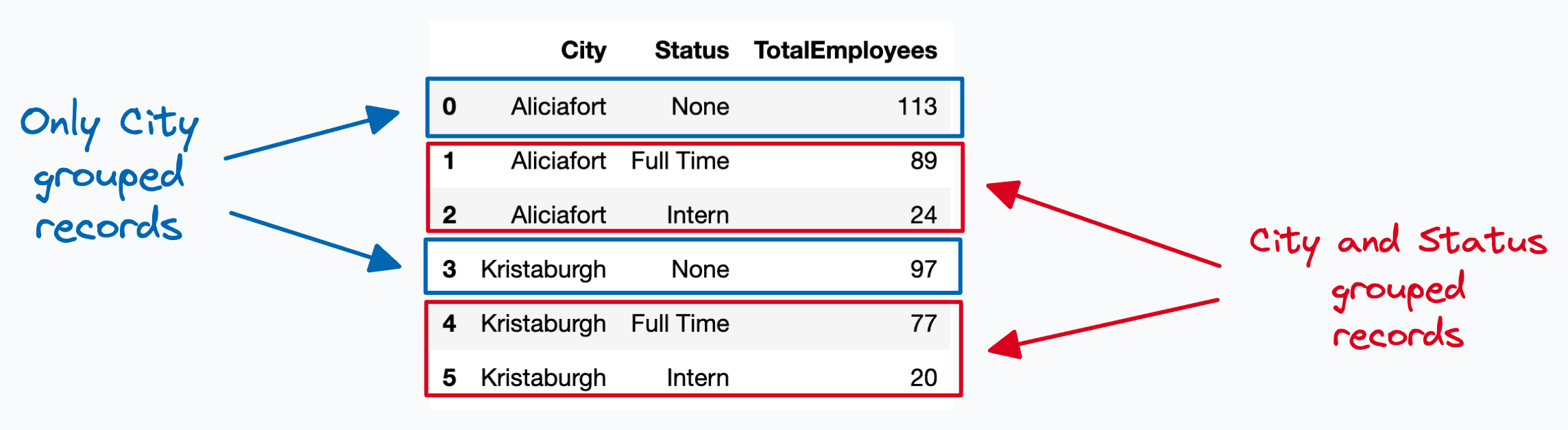
So the final output must look like this:

Every city has three records:
One for total employees.
One for total full-time employees.
One for total interns.
The standard approach
The most common approach of doing this involves the following SQL query:

ORDER BY and alias for the Count column is not shown here intentionally.We have one query for finding the total employees in each
City.We have another query for finding the total full-time employees and interns in each city by aggregating on both
CityandStatuscolumns.
Finally, we take a UNION of both results to get the desired results:
Cool! This works as expected.
But the biggest bottleneck in this approach is that it involves scanning the same table twice.
Can we do better?
Of course we can!
The smart approach — Grouping Sets
Grouping sets is a great way to run multiple aggregations on the same table by scanning the table just once instead of multiple times.
Quite clearly, this makes our query much more efficient.
This is demonstrated below:

In this query:
We specify all aggregation columns we want to group on using the
GROUPING SETSkeyword.
From the above query, it is pretty clear that we are only scanning the whole table once.
Also, just like the UNION approach, it produces the desired results:

The SQL query with GROUPING SETS is much more efficient, elegant, and shorter.
Isn’t that cool?
Try it out by downloading this Jupyter Notebook: Grouping Sets Notebook.
👉 Over to you: What are some other cool ways of using GROUPING SETS?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed:
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Wow... I never knew about this and didn't expect to get this valuable information from here! Always surprising us with great content Avi! I for sure will use this sometime in the near future in my SQL queries; bookmarked!
Nice trick