
GROUPING SETS in SQL
A lesser-known way to run multiple aggregations.

A few weeks back, we discussed GROUPING SETS, ROLLUP, and CUBE in SQL. Here’s the visual for a quick recap:

Among these three, the one I have seen people using most often is GROUPING SETS.
So today, let’s do a more comprehensive demo of this and understand how it works.
Background
Whenever running multiple aggregations on some table, most people write multiple SQL queries — one query per aggregation.
Finally, if the results are to be gathered in a single table, they aggregate all the above tables using UNION or UNION ALL (as needed).
But this is among the most inefficient ways to approach this.
Let me explain with an example.
Consider an organization that has the following Employees table in their database:

The task is to get the following information in the same table:
The total employees in each
City→ This will involve an aggregation on theCitycolumn.The total full-time employees and interns in each
City→ This will involve an aggregation on theCityandStatuscolumn.
So the final output must look like this:

Every city has three records:
One for total employees.
One for total full-time employees.
One for total interns.
The standard approach
The most common approach of doing this involves the following SQL query:

ORDER BY and alias for the Count column is not shown here intentionally.We have one query for finding the total employees in each
City.We have another query for finding the total full-time employees and interns in each city by aggregating on both
CityandStatuscolumns.
Finally, we take a UNION of both results to get the desired results:
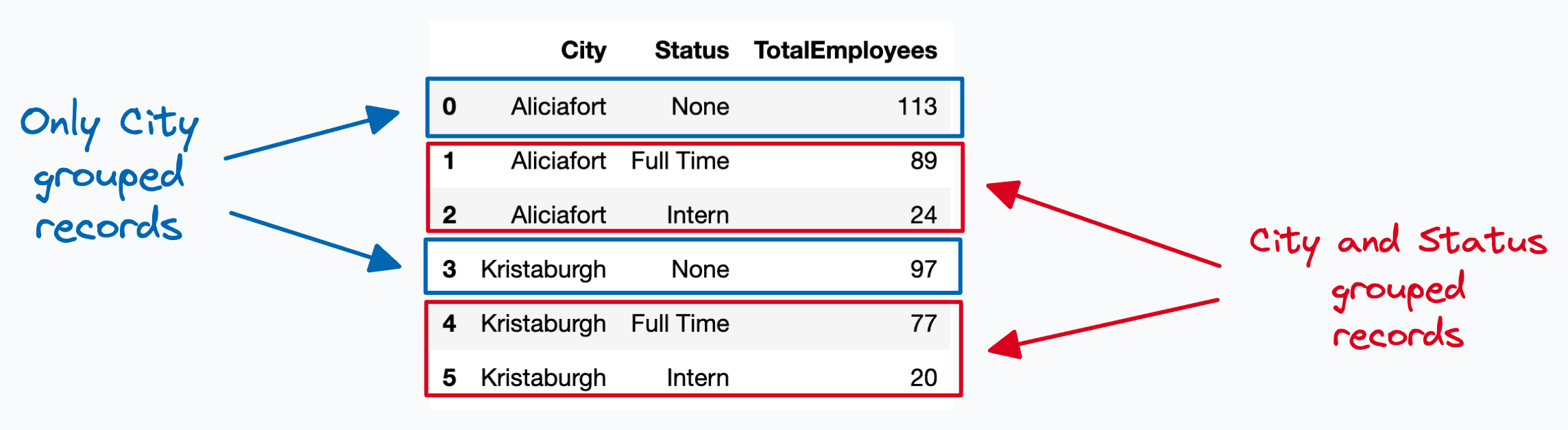
Cool! This works as expected.
But the biggest bottleneck in this approach is that it involves scanning the same table twice.
Can we do better?
Of course we can!
The smart approach — Grouping Sets
Grouping sets is a great way to run multiple aggregations on the same table by scanning the table just once instead of multiple times.
Quite clearly, this makes our query much more efficient.
This is demonstrated below:

In this query:
We specify all aggregation columns we want to group on using the
GROUPING SETSkeyword.
From the above query, it is pretty clear that we are only scanning the whole table once.
Also, just like the UNION approach, it produces the desired results:

The SQL query with GROUPING SETS is much more efficient, elegant, and shorter.
Isn’t that cool?
Try it out by downloading this Jupyter Notebook: Grouping Sets Notebook.
👉 Over to you: What are some other cool ways of using GROUPING SETS?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs)
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 84,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.