
Guardrails for AI Agents
...explained visually and with code.

Reinforcement Fine-tuning Free Guidebook

Reinforcement Fine-Tuning (RFT) is redefining what’s possible with open-source LLMs—and this free guide shows you how to harness it.
Here’s what you’ll learn:
Why RFT beats traditional fine-tuning (with 20%+ accuracy gains)
How top teams fine-tune with just a few examples
Real-world benchmarks vs. GPT-4 and DeepSeek
How to turbo your reasoning models to increase throughput 2-4x
Example tutorial: Creating rewards for code gen
Essentially, it has everything you need to know about RFT and training custom reasoning models—no labeled data required.
Thanks to Predibase for partnering with us today!
Guardrails for AI Agents
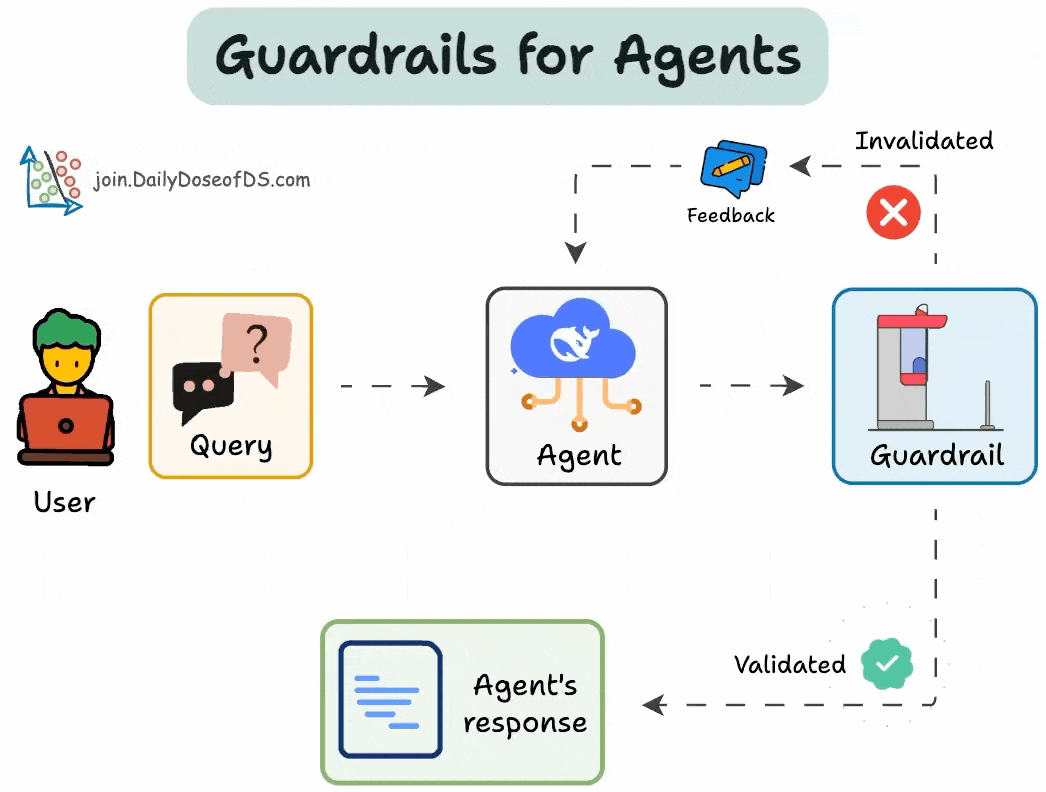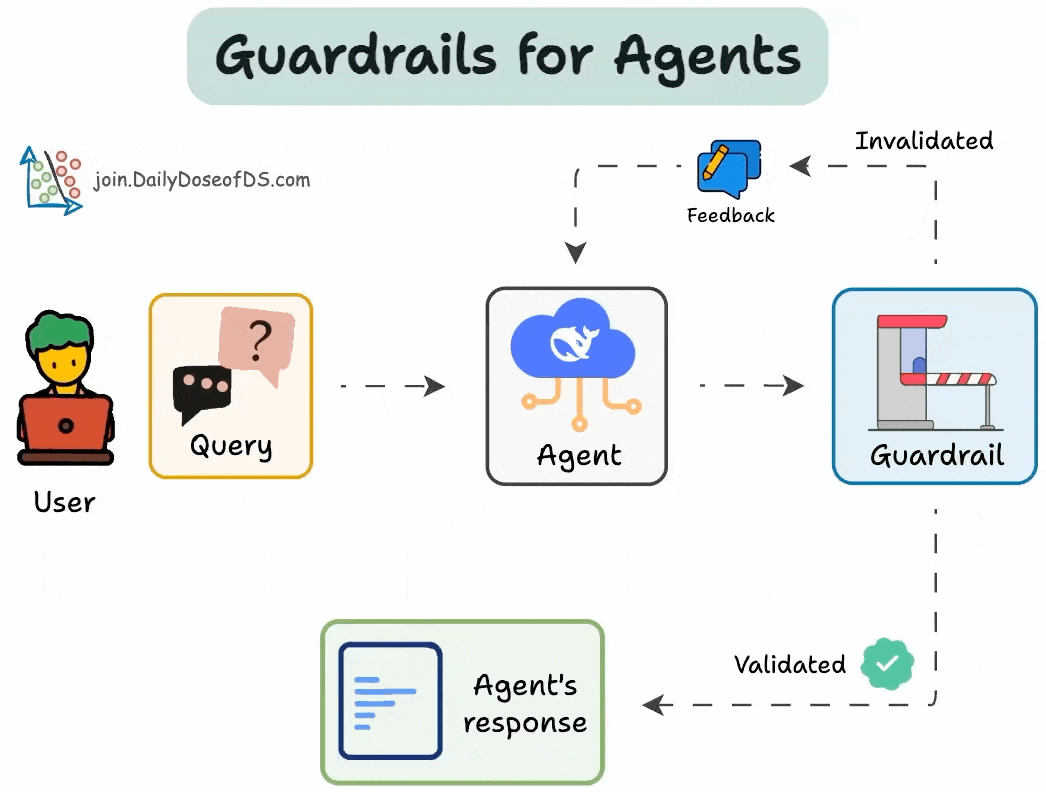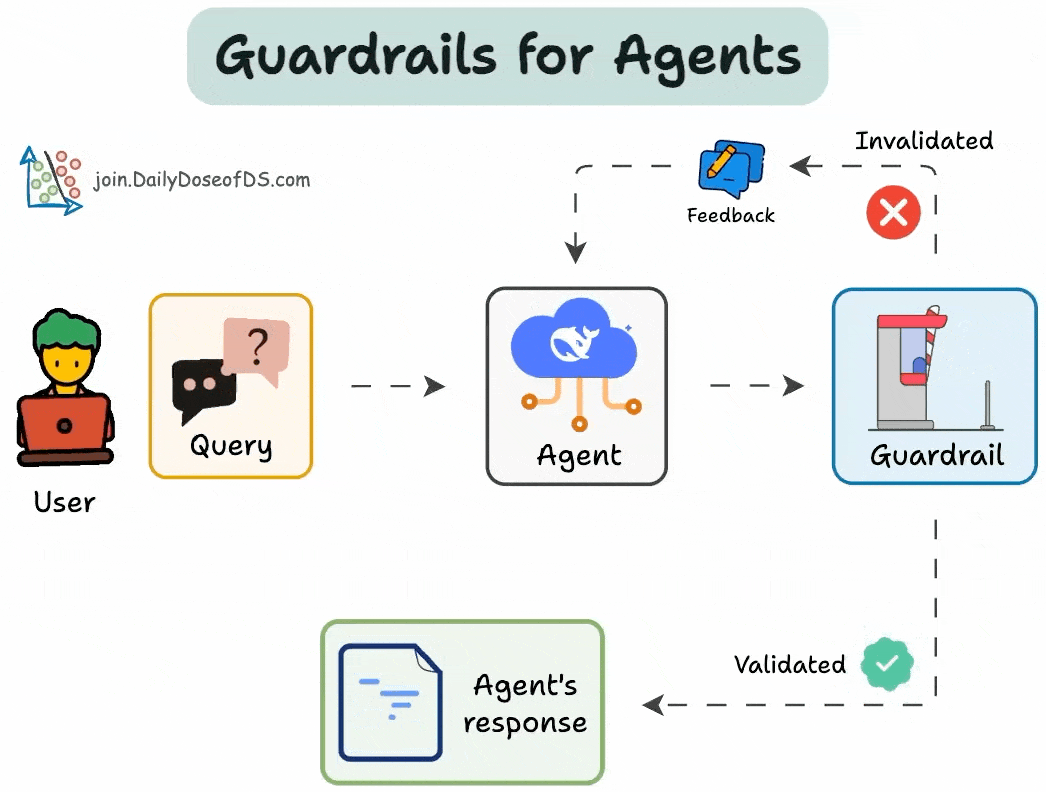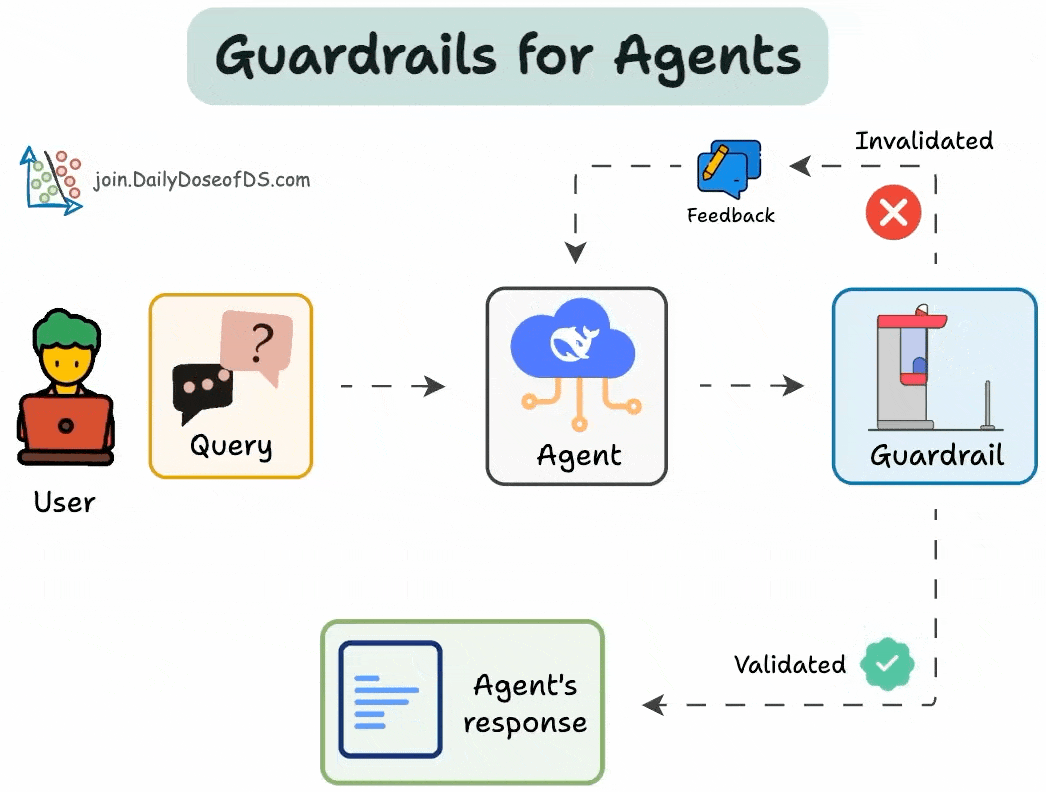
AI agents are powerful, but without safeguards, they can hallucinate, enter infinite loops, or give unreliable outputs.
Guardrails solve this.
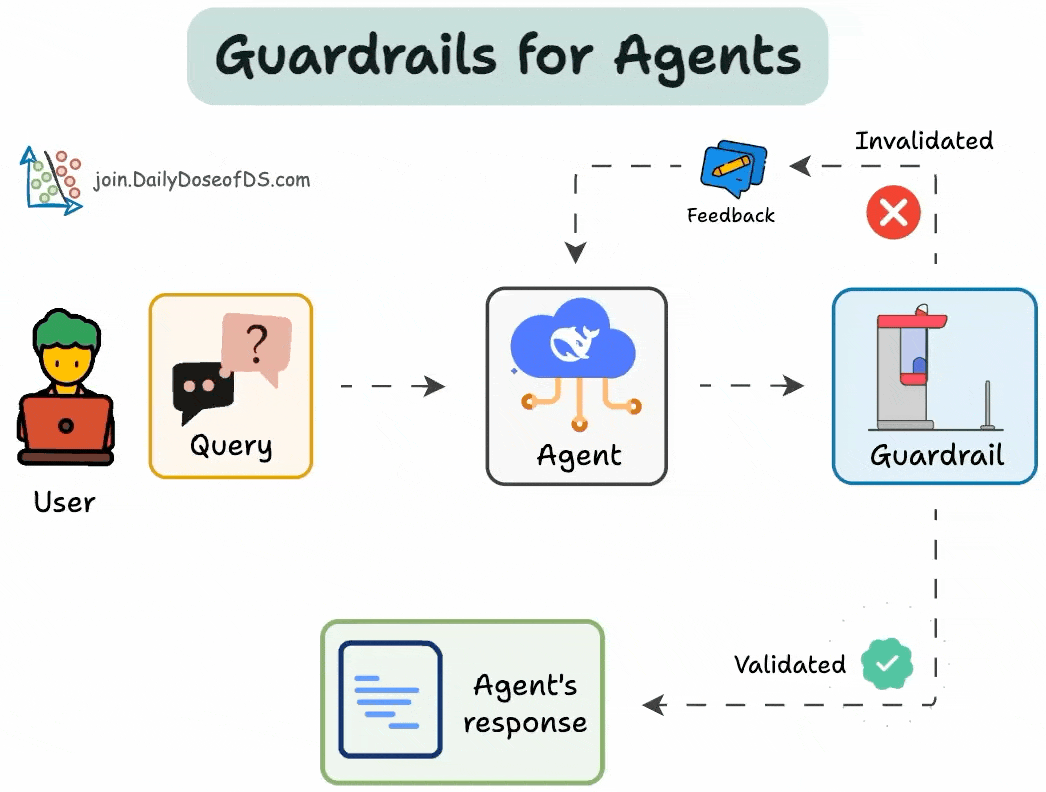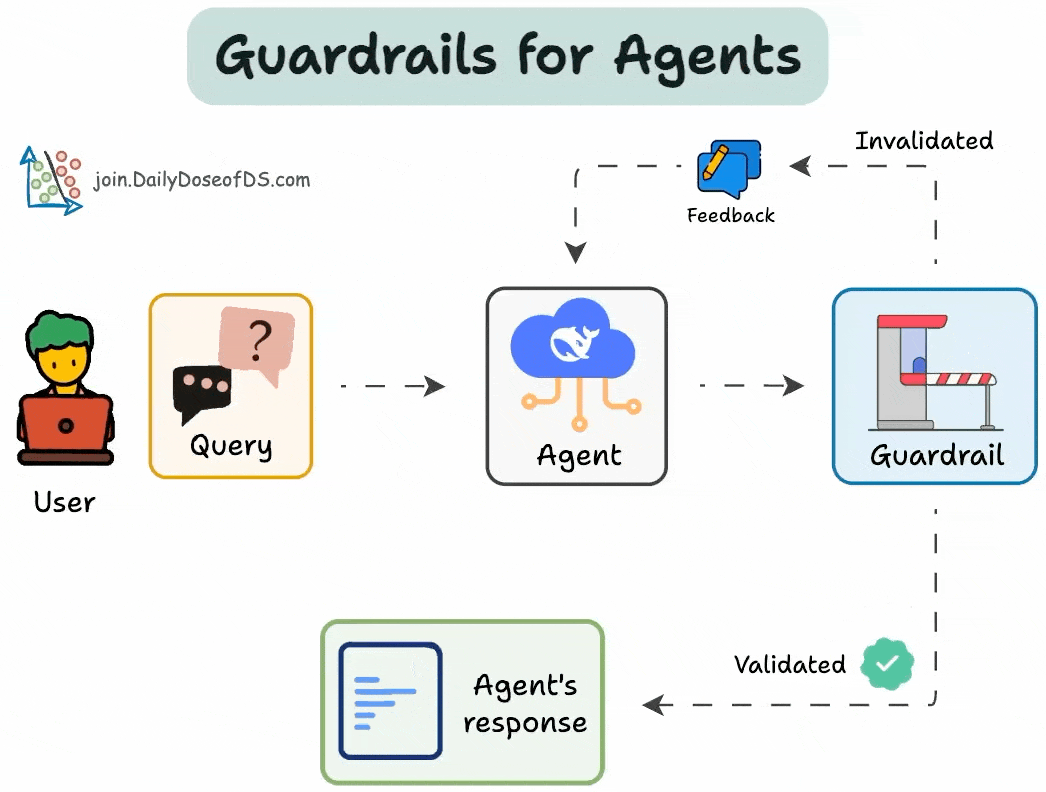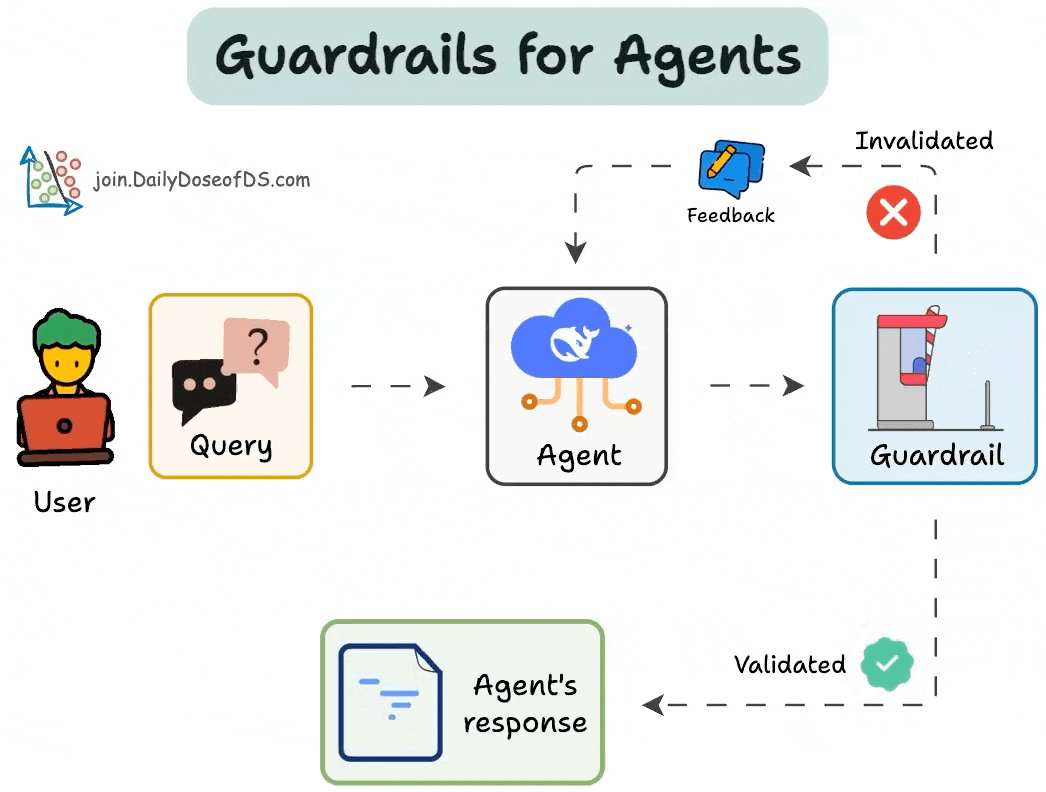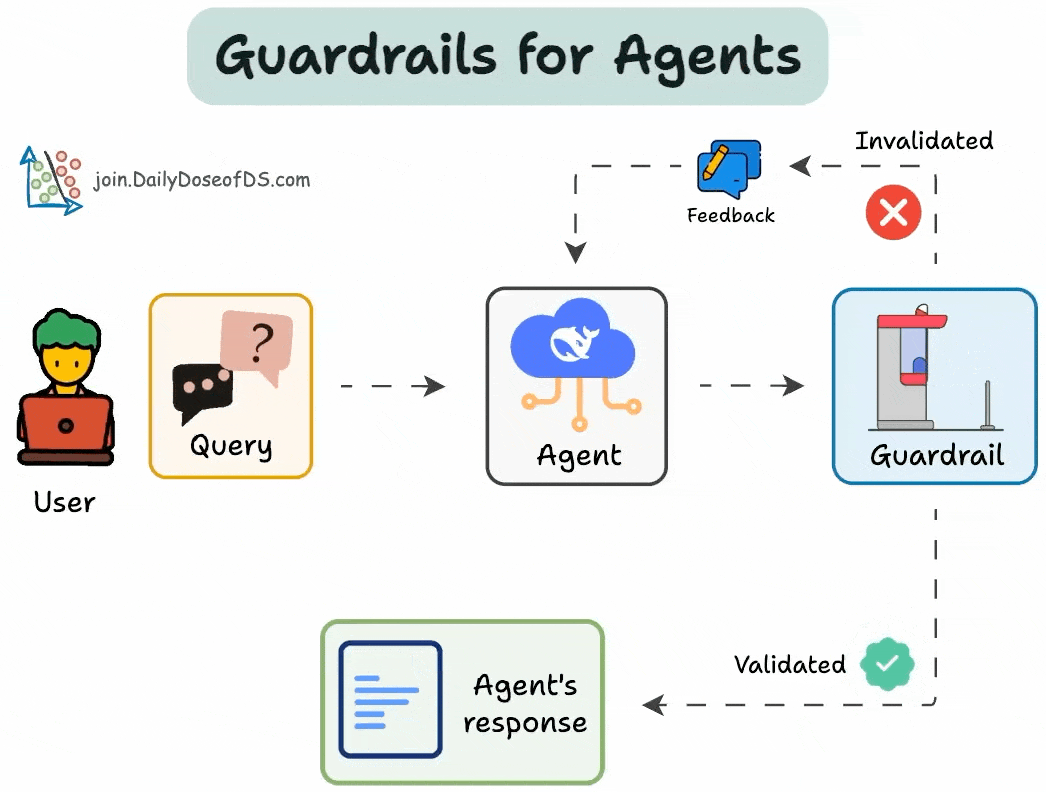
We can use them to:
Limit tool usage
Set validation checkpoints
Specify fallback mechanisms
Below, let's implement them!
A quick note…
If you want to dive into building Agentic systems, we have published nine parts so far in our AI Agents crash course.
It covers—fundamentals, custom tooling, structured outputs, modular Agents, Flows, state management, Flow control, building projects with Flows, advanced techniques like Async execution, Callbacks, Human-in-the-loop, Multimodal Agents, Knowledge, and Memory.
Consider an Agent to summarize research topics. The summary must be under 150 words—a Guardrail.
A Guardrail is a function that accepts the task's output and returns two values:

Success (True) or Failure (False).
The validated output (success) or an error message (failure).
Next, we define a summarizer Agent and its Task—asking it to summarize an ML topic.

We pass the Guardrail method defined above (validate_summary_length) as a parameter to the Task and kick off the Crew.
This produces the output shown in the image.

It has a few print statements from the Guardrail method, which raised no failure.
But now let's understand what happens upon failure.
Let's intentionally ask it to generate a 200-word summary instead, keep the guardrail method the same, and kick off the Crew.

This time, we get the output shown in the image below.

The lines in yellow indicate the error message received from the guardrail method.
The Agent retries a few times to fix it before it exits the program.
And that is how we specify Guardrails in AI Agents!
Guardrails are powerful, which is why they are considered among the 6 things that make Agents great:
Role
Tools
Focus
Memory
Guardrails
Cooperation
We have covered everything in detail (and with implementation) in the AI Agents crash course with 9 parts:
In Part 1, we covered the fundamentals of Agentic systems, understanding how AI agents act autonomously to perform tasks.
In Part 2, we extended Agent capabilities by integrating custom tools, using structured outputs, and built modular Crews.
In Part 3, we focused on Flows, learning about state management, flow control, and integrating a Crew into a Flow.
In Part 4, we extended these concepts into real-world multi-agent, multi-crew Flow projects.
In Part 5 and Part 6, we moved into advanced techniques that make AI agents more robust, dynamic, and adaptable, like Guardrails, Async execution, Callbacks, Human-in-the-loop, Multimodal Agents, and more.
In Part 7, we covered Knowledge of agentic Systems.
In Part 8 and Part 9, we covered everything related to memory for Agentic systems:
5 types of Memory from a theoretical, practical, and intuitive perspective.
How each type of Memory helps an Agent.
How an Agent retrieves relevant details from the Memory.
The underlying mechanics of Memory and how it is stored.
How to utilize each type of Memory for Agents (implementations).
How to customize Memory settings.
How to reset Memory if needed.
And more.
Of course, if you have never worked with LLMs, that’s okay.
We cover everything in a practical and beginner-friendly way.
Thanks for reading!