
[Hands-on] Build a Real-Time Satellite Tracker with Claude Code
Backed by a production-grade time-series database.

Mythos taught everyone a lesson this week.
Mythos got shut down this week.
A company built on top of intelligence it didn’t control suddenly found itself exposed to decisions it couldn’t influence.
That’s what the cost debate kept missing. For two years, the only question about open models was whether they were cheaper, but cheaper tokens don’t help you the day the platform changes the rules underneath you.
And to be fair, nobody fully owns an open model either. The base weights still come from labs you don’t control.
The difference is that once those weights are on your hardware, they can’t be taken back. A frontier API can drop you tomorrow, but the weights you already have stay yours.
The base model was never really the point anyway. The real value is in the post-training, your data, your evals, the behavior shaped around the work only your company does.
[Hands-on] Build a real-time satellite tracker with Claude Code
We gave Claude Code one prompt, and it built a real-time satellite tracker that shows every active satellite orbiting Earth on an interactive 3D globe:
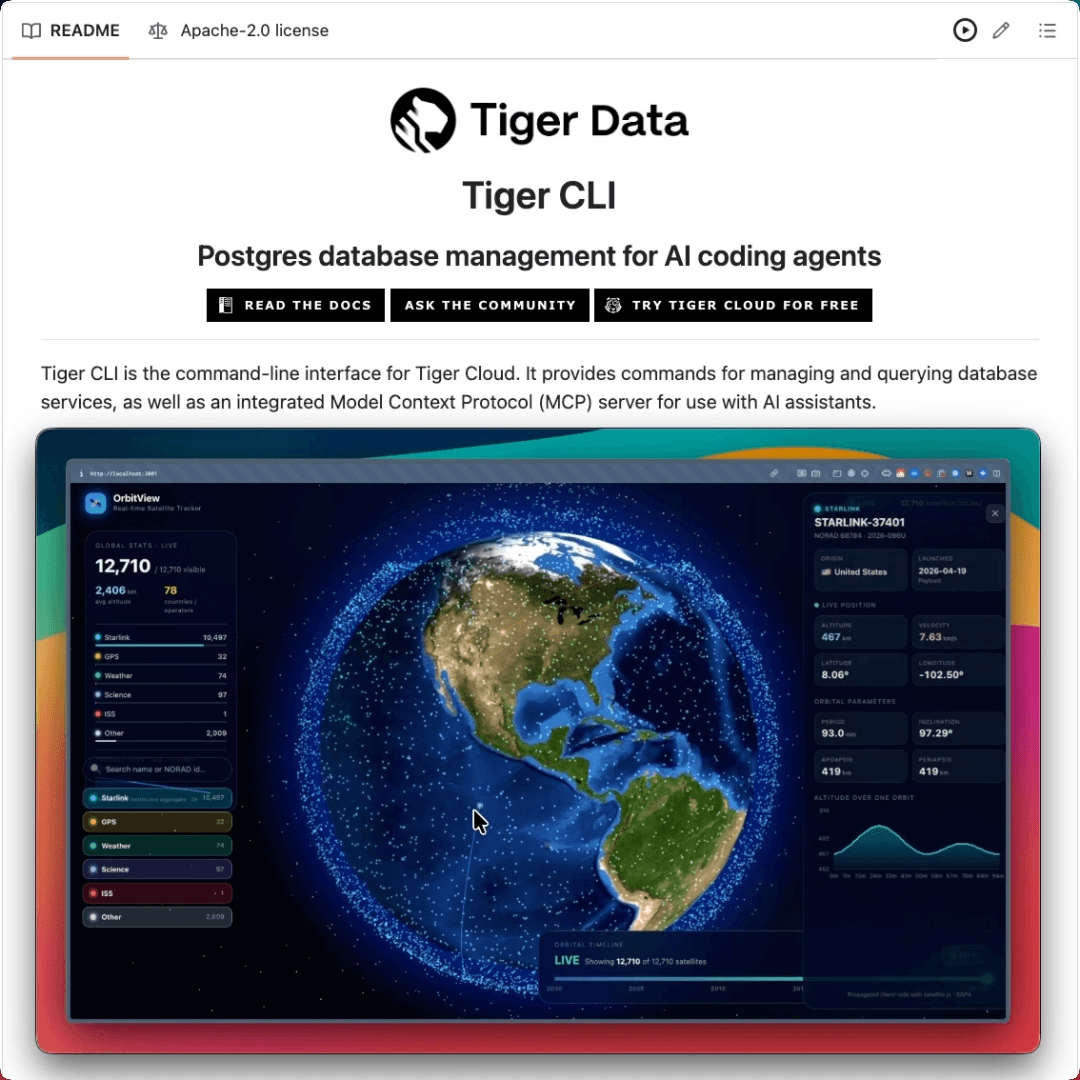
There are over 10,000 active satellites up there right now, including 6,000+ Starlink satellites.
The tracker visualizes all of them moving along their real orbital paths, with a timeline slider that lets you drag from 2000 to 2026 and watch space gradually fill up as satellites launched over the years.
The backend runs on Tiger Cloud by Tiger Data, which gives you managed TimescaleDB on Postgres.
Claude Code provisioned the database, created the schema, seeded the data, and built the frontend in a single session. Let’s walk through the setup, the prompt, and what we built.
Setting up the backend
The entire database infrastructure was provisioned from inside Claude Code using the Tiger CLI MCP server. These are three commands to get started:
# Install Tiger CLI
curl -fsSL https://cli.tigerdata.com | sh
# Authenticate with Tiger Cloud
tiger auth login
# Connect Claude Code to Tiger Cloud via MCP
tiger mcp install claude-codeAfter restarting Claude Code, it has full access to Tiger Cloud through the MCP server: creating services, running SQL, and querying documentation.
The prompt
The prompt we gave Claude Code covered the full stack in one shot:
Build a real-time satellite tracker with an interactive 3D globe
showing satellites orbiting Earth.
Backend: Use our Tiger Cloud account (via Tiger MCP) to create a
TimescaleDB service. Create a hypertable for satellite position
snapshots (norad_id, object_name, country, launch_date, latitude,
longitude, altitude_km, velocity, timestamp). Store snapshots for
thousands of satellites every 5 minutes. Set up continuous aggregates
for orbital statistics per constellation per hour.
Data: Pull satellite data from CelesTrak public orbital database.
Compute real-time positions using satellite.js from TLE data.
Frontend: Next.js + Three.js. Dark theme. The globe should have a
day/night cycle with NASA satellite imagery, city lights on the dark
side. Each satellite rendered as a glowing dot colored by constellation
(Starlink: cyan, GPS: gold, Weather: green, ISS: red). Add a timeline
slider from 2000 to 2026 that filters satellites by launch date.
Clicking any satellite shows its name, launch date, country, altitude,
velocity, and orbital parameters.After this, Claude Code provisioned the TimescaleDB service, created the hypertable, set up continuous aggregates, pulled orbital data for 10,000+ satellites, computed their positions, and built the complete Next.js frontend with the Three.js globe.
Tracking thousands of satellites every 5 minutes generates a lot of time-series data fast, and that’s what TimescaleDB handles best.
Speedcast already does this at production scale, monitoring 12,000+ Starlink terminals and ingesting 20GB/hour of satellite telemetry through Tiger Cloud. Learn more here →
Its hypertables partition the data by timestamp automatically, so each query only hits the relevant time chunk.
Continuous aggregates serve queries like “average Starlink altitude over 24 hours” from pre-computed summaries instead of recalculating from scratch every time.
On a regular Postgres table, this would require manual partitioning and index tuning to stay fast as the position snapshots accumulate. TimescaleDB handles this out of the box.
To get started:
# 1. Sign up for Tiger Cloud (link below)
# 2. Install Tiger CLI
curl -fsSL https://cli.tigerdata.com | sh
# 3. Authenticate
tiger auth login
# 4. Connect Claude Code
tiger mcp install claude-code
# 5. Give Claude Code a prompt and let it buildTiger Cloud gives new users $1,000 in free 30-day credit, no credit card required. That’s enough to run a production TimescaleDB instance for a full month and build whatever you want on top of it.
You can sign up for Tiger Cloud here →
Tiger CLI is open-source (Apache 2.0) and works with Claude Code, Cursor, Codex, Gemini CLI, and VS Code.
👉 Over to you: what would you build if Claude Code could provision your database infrastructure?
Thanks to Tiger Data for working with us on today’s issue!
From AGI → ASI
There’s a brilliant new paper from Google DeepMind called “From AGI to ASI,” and it skips the fight everyone else is having.

Almost every AI debate today is about reaching human-level intelligence. This one asks the harder question instead.
Once we have an AI as capable as a person, where does it go next?
Their reasoning is uncomfortable because it’s so simple.
Essentially, the moment you have one human-level AI, you can copy it exactly, down to its memory and everything it has ever learned.
So you don’t end up with one digital worker but rather a million of them, running faster than any human and sharing every lesson instantly.
A group like that could outthink any company or research lab long before any single AI becomes a lone genius.
That’s the heart of it. Scale alone might carry us from “as smart as a person” to “smarter than entire teams of the best experts.”
The paper maps four ways this could play out, and they can all happen at once.
Keep scaling what already works, i.e., invent a new approach when the current one runs dry, let AI improve AI in a loop that feeds itself. or let armies of AIs organize into something smarter than any one of them, the way a company outperforms any single employee.
They also list everything that could slow it all down, like running out of good training data, maybe costs and energy becoming impossible to sustain, or research simply getting harder as the easy wins disappear.
But the most interesting roadblock isn’t a wall but rather a question.
Today’s AI learns from everything humans have already figured out, and it’s brilliant at remixing our ideas. What it has never done is invent a genuinely new idea from scratch.
A test by Demis Hassabis is a good criterion, which drops an AI into the year 1900 with everything Einstein knew, and asks it to discover relativity. Right now, it can’t, and something is clearly still missing.
The popular picture is one big moment where everything changes overnight. This paper argues that there will be a series of waves instead, each one reshaping a field of science or the economy, arriving faster than the last.
And the most useful work right now involves building better ways to measure progress, so we actually notice which wave we’re already in.
Good day!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.