
[Hands-on] CI/CD in MLOps Workflows
The full MLOps blueprint.

Part 18 of the MLOps and LLMOps crash course is now available, where we understand and learn the entirety of CI/CD workflows in ML systems with all necessary theoretical details and hands-on examples.
MLOps and LLMOps crash course Part 18 →
Traditional CI/CD focuses on delivering code changes quickly and safely. With ML, we need to extend this idea to data and models too.
This means our pipelines must not only run code tests, but also validate input data, retrain models, track model metrics, and then deploy or push those models.
To explain, we cover the entire end-to-end details, covering:
CI for ML
Data CI: validating data
Code CI: testing code
Model CI: testing models and quality
CD for ML
Model packaging and serving
Automated deployments
Hands-on: CI/CD pipeline with AWS
Just like all our past series on MCP, RAG, and AI Agents, this series is both foundational and implementation-heavy, walking you through everything that a real-world ML system entails:
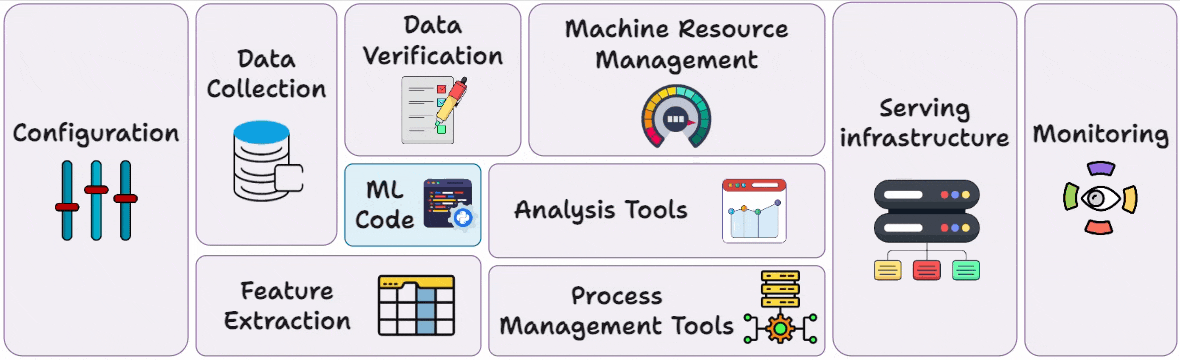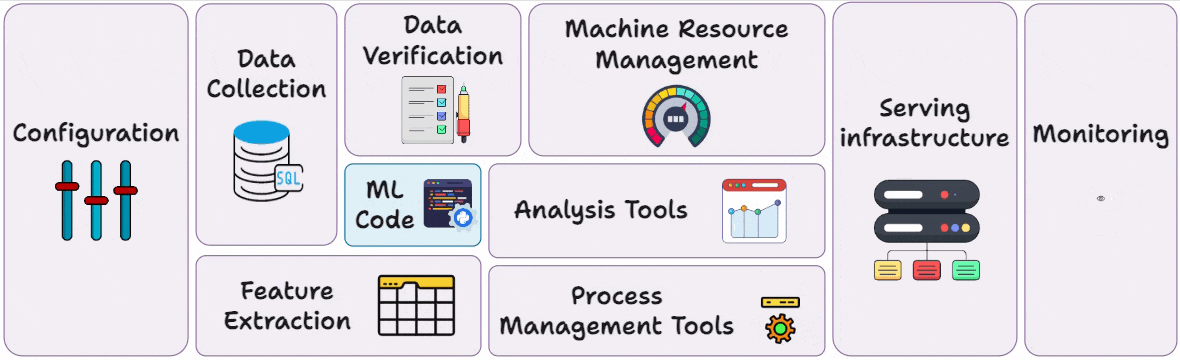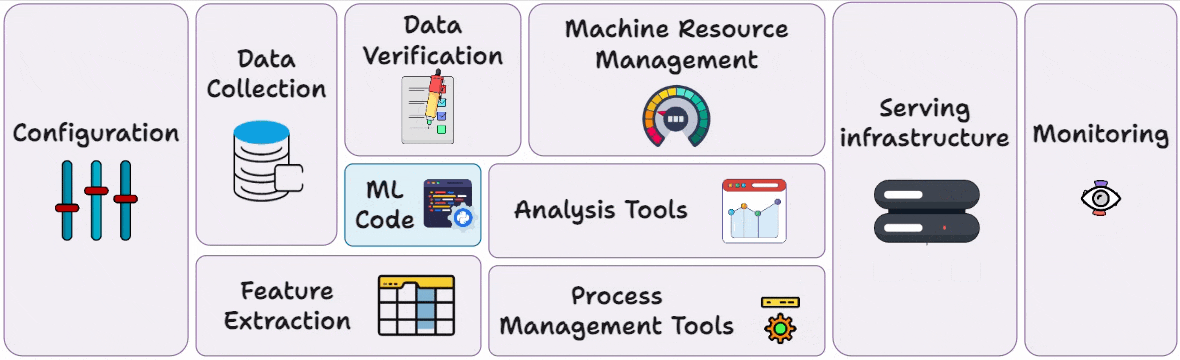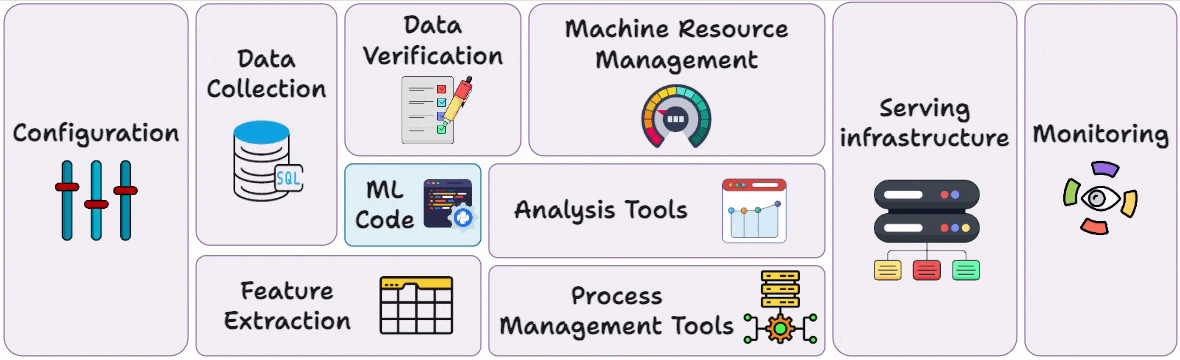
Part 3 covered reproducibility and versioning for ML systems →
Part 4 also covered reproducibility and versioning for ML systems →
Part 7 covered Spark, and orchestration + workflow management →
Part 8 covered the modeling phase of the MLOps lifecycle from a system perspective →
Part 9 covered fine-tuning and model compression/optimization →
Part 10 expanded on the model compression discussed in Part 9 →
Part 11 covered the deployment phase of the MLOps lifecycle →
This MLOps and LLMOps crash course provides a thorough explanation and systems-level thinking to build AI models for production settings.
Just like the MCP crash course, each chapter will clearly explain necessary concepts, provide examples, diagrams, and implementations.
Thanks for reading!
Hi Avi..where do you make these diagrams? Thank you