
How Decision Tree Computes Feature Importance?
The underlying mathematical details.


💼 Want to become an AI Consultant?
The AI consulting market is about to grow by 8X – from $6.9 billion today to $54.7 billion in 2032.
But how does an AI enthusiast become an AI consultant?
How well you answer that question makes the difference between just “having AI ideas” and being handsomely compensated for contributing to an organization’s AI transformation.
Thankfully, you don’t have to go it alone—our friends at Innovating with AI just welcomed 200 new students into The AI Consultancy Project, their new program that trains you to build a business as an AI consultant.
Some of the highlights current students are excited about:
The tools and frameworks to find clients and deliver top-notch services.
A 6-month plan to build a 6-figure AI consulting business.
Students getting their first AI client in as little as 3 days.
And as a Daily Dose of Data Science reader, you have a chance to get early access to the next enrollment cycle.
Click here to request early access to The AI Consultancy Project.
Thanks to Innovating with AI for sponsoring today’s issue.
Feature importance in decision tree
A decision tree has a native method to compute feature importance:

Today, let me show you how it is calculated.
Intuition
Consider this is our decision tree, and it shows which specific feature was used for data splitting at nodes:

If you were formulating feature importance from scratch, let’s think about everything you would prefer:
If a feature is never used in tree building, its importance must be zero (quite obvious).
If a feature generates pure splits, it should significantly contribute to its feature importance. For instance, since X1 generates a pure split in the image below, this “purity” factor should be considered in the feature selection.

Lastly, feature importance should also be dependent on the number of samples handled by a particular feature at a specific node. Let me explain this below.
As we traverse the decision tree, the number of samples that a child node has to handle is always less than its parent node:

Thus, if a feature at the top of the tree (with several samples) can generate perfect splits, it should be given more weight than a feature that creates perfect splits at the bottom (with few samples).
I hope that makes intuitive sense.
That said, we have to keep in mind that in a decision tree, the same feature can be used in multiple nodes (shown below):
Thus, we can first measure the importance of every node, which can be added to the overall importance value of the feature used in that node:

Node Importance
Here’s a way to compute the node importance based on what we have discussed above:

A node will split the samples into the left and right nodes. Thus, we determine the weighted difference in the Gini index before and after the split to calculate the node’s importance.
For instance, consider this as our decision tree on a binary classification dataset:
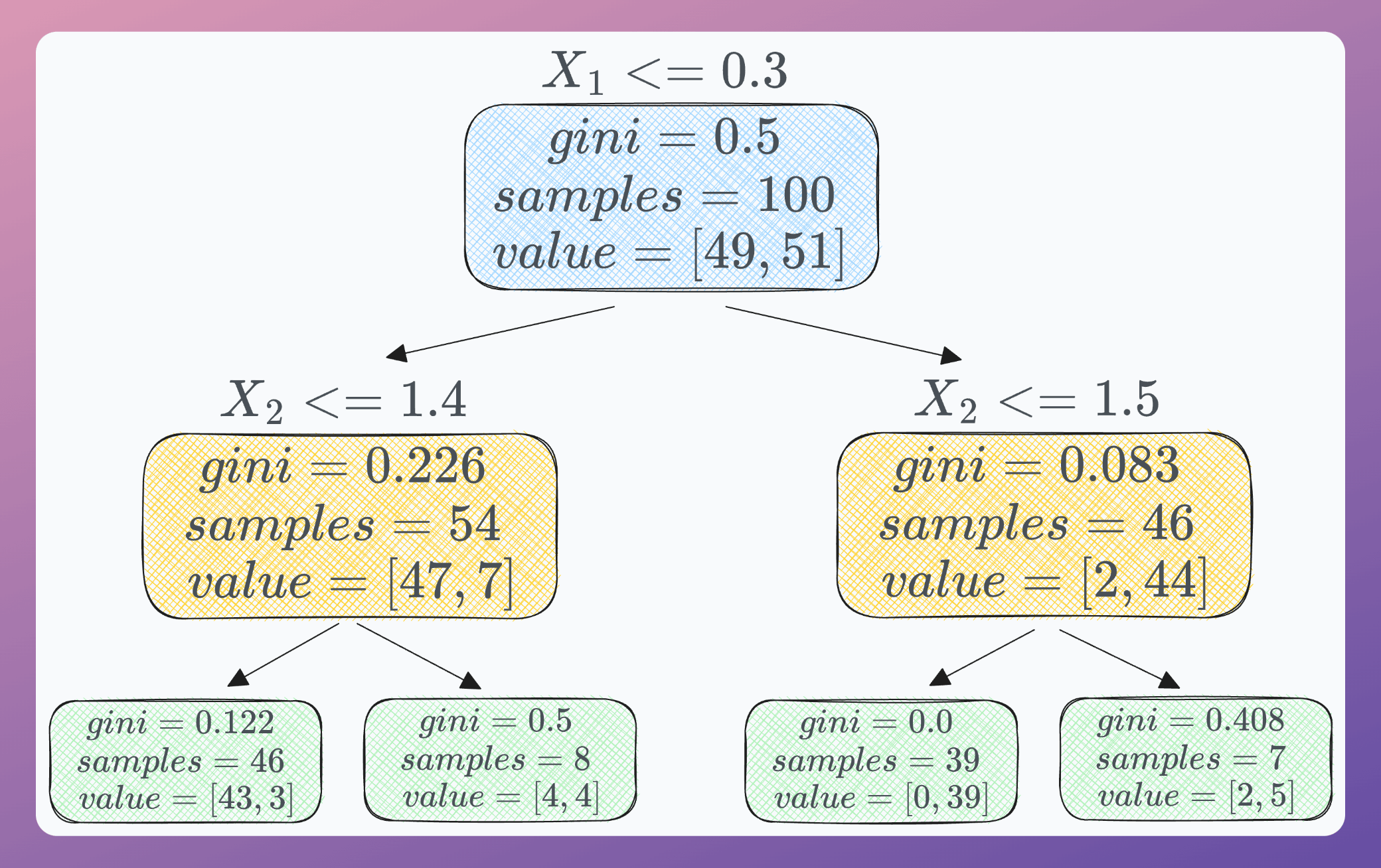
Let’s compute the root node’s importance.
Here are the parent node, the left child node, and the right child node in this case:

For root node (blue):
fraction of samples = 1.00 (complete dataset)
gini = 0.5
For the left node:
Fraction of samples = 54/100.
gini = 0.226
For the right node:
Fraction of samples = 46/100.
gini = 0.083
Thus, we get the root’s node importance as:

Similarly, we can compute the importance of other nodes:

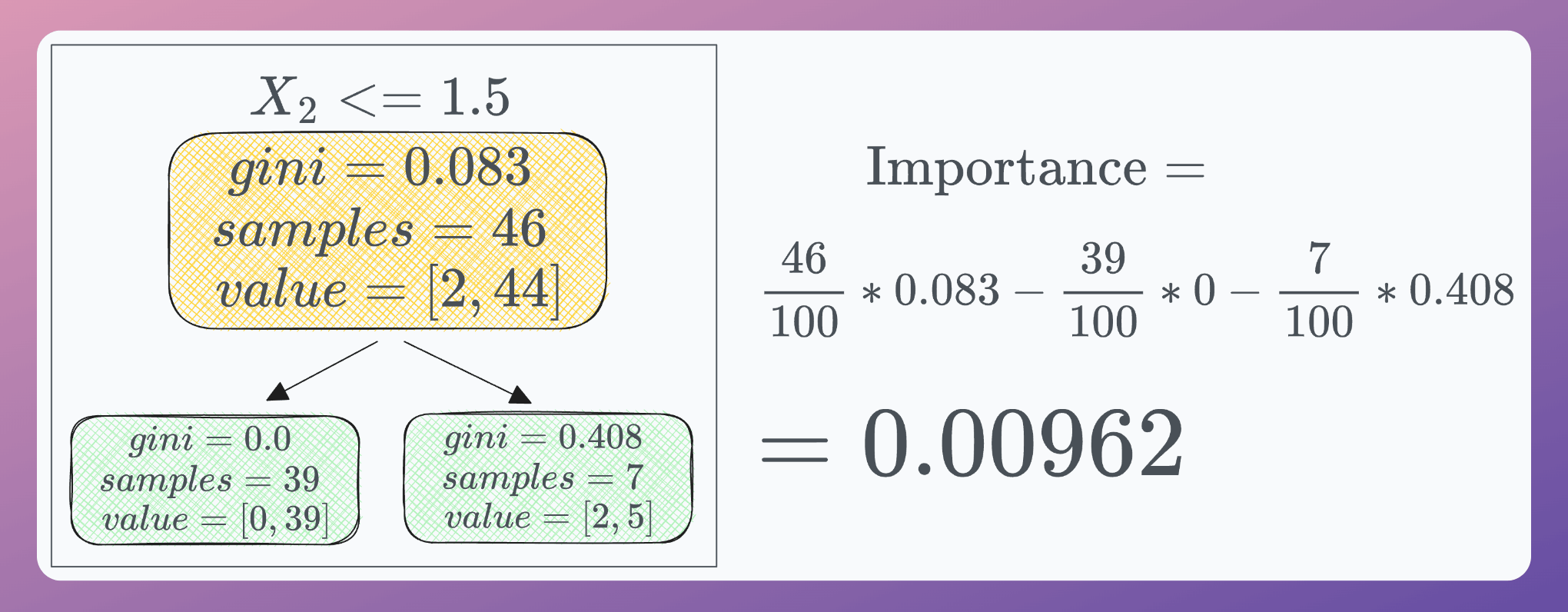
With that, we have calculated the importance of all nodes. We use them to obtain the feature importance:

Almost done!
One final step is to normalize these values so that they add to 1.

Done!
This gives us:
X1 feature importance = 0.905
X2 feature importance = 0.095
We can also verify it with the values we get from the sklearn decision tree object:
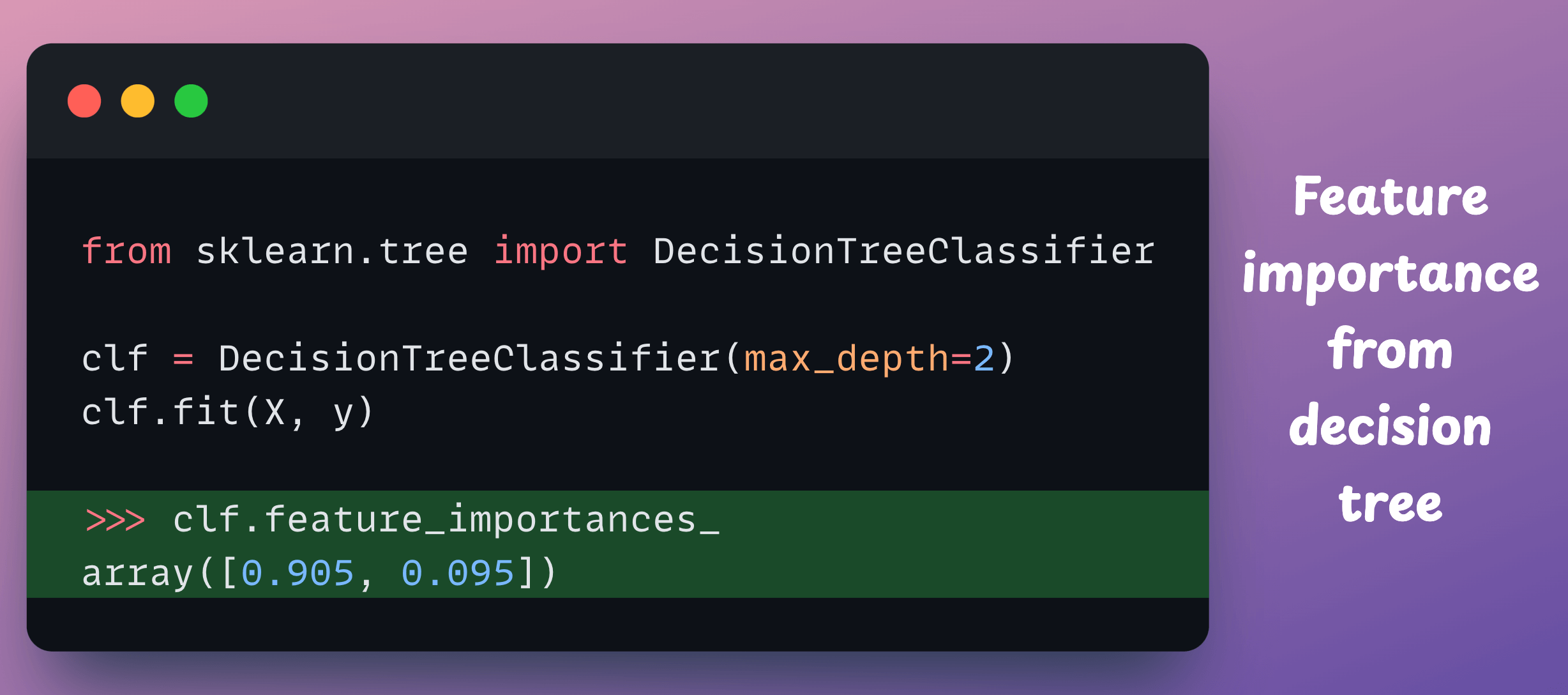
It matches!
You can actually see that there is a proper intuition that goes into the above feature importance method.
The core idea is to quantify how well a feature separates different classes and measure the impurity difference before and after the split.
The higher the impurity reduction, the higher the importance.
In fact, in the above walkthrough, had the first node created a perfect split (shown below), we can verify that it leads to feature importance of 1:

A similar idea for feature importance can also be extended to a random forest model.
That was simple and intuitive, wasn’t it?
That said, if you like intuitive guides, have you ever wondered why we must sample rows from the training dataset with replacement in a random forest?

Also, how to mathematically formulate the idea of Bagging and prove variance reduction.
Learn here: Why Bagging is So Ridiculously Effective At Variance Reduction?
Also, we formulated and implemented the entire XGBoost algorithm from scratch here: Formulating and Implementing XGBoost From Scratch.
Lastly, do you know that decision tree models can be supercharged with tensor computations for up to 40x faster inference?

Check out this article to learn more: Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 100,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
A detailed explanation here - https://scikit-learn.org/dev/modules/ensemble.html#feature-importance-evaluation
For readers interested in the cons and an alternative - https://scikit-learn.org/dev/modules/generated/sklearn.tree.DecisionTreeRegressor.html#sklearn.tree.DecisionTreeRegressor.feature_importances_