
How Do LLMs Work?
...explained with visuals and maths.

Make Claude Code 10x more powerful!
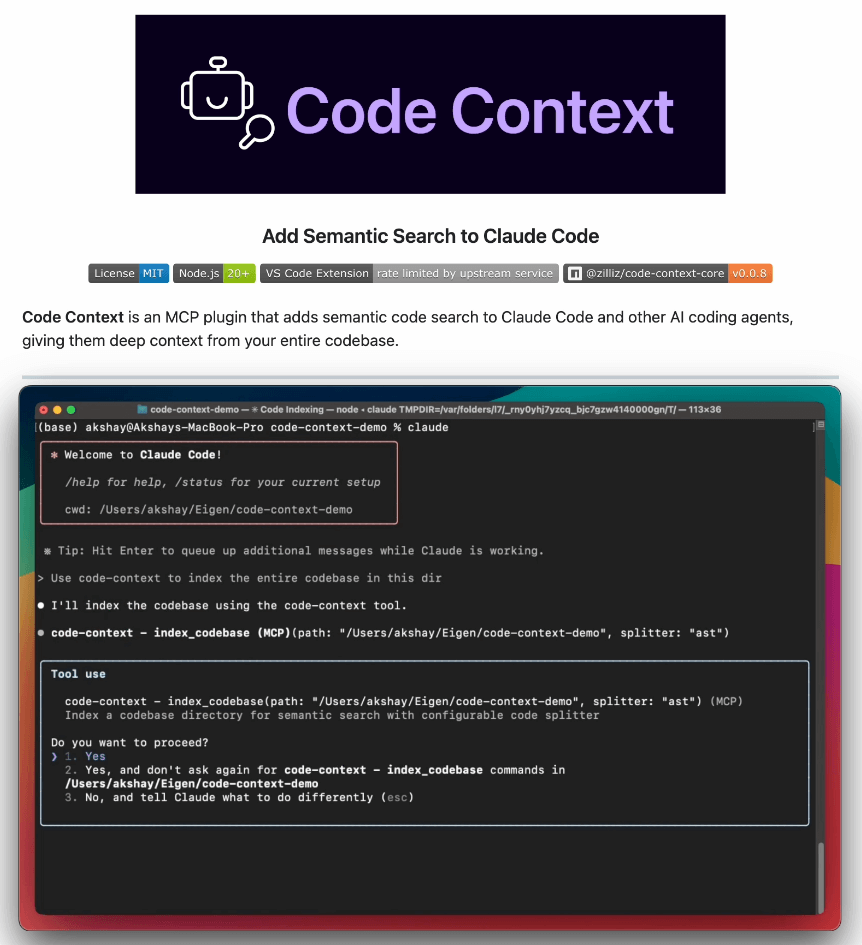
We just discovered this MCP plugin that brings semantic code search to Claude Code, Gemini CLI, or any AI coding agent.
Full codebase indexing provides richer context and better code generation.
Semantic search across millions of lines of code
Context-aware discovery of code relationships
Incremental indexing with Merkle trees
Intelligent AST-based code chunking
Fully customizable configurations
Scalable vector search
100% open-source.
How do LLMs work?
A few days back, we covered the 4 stages of training LLMs from scratch:
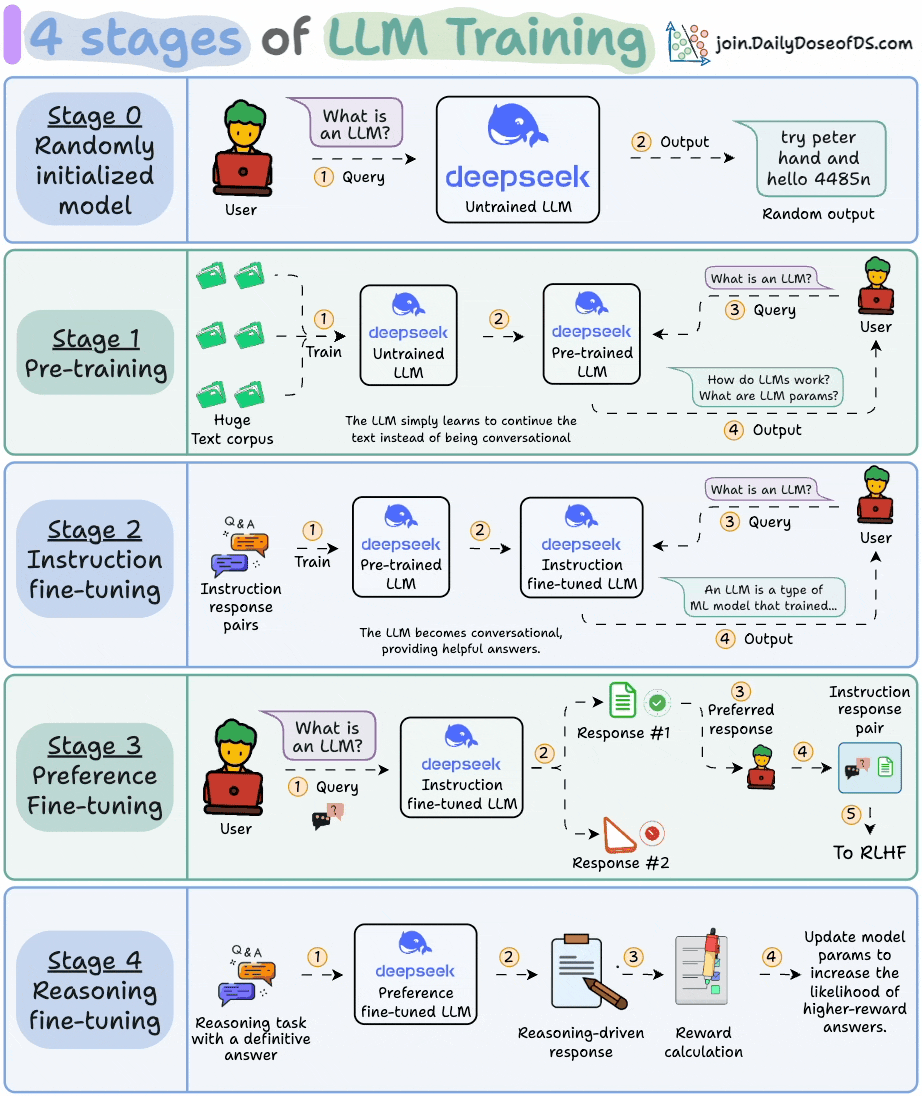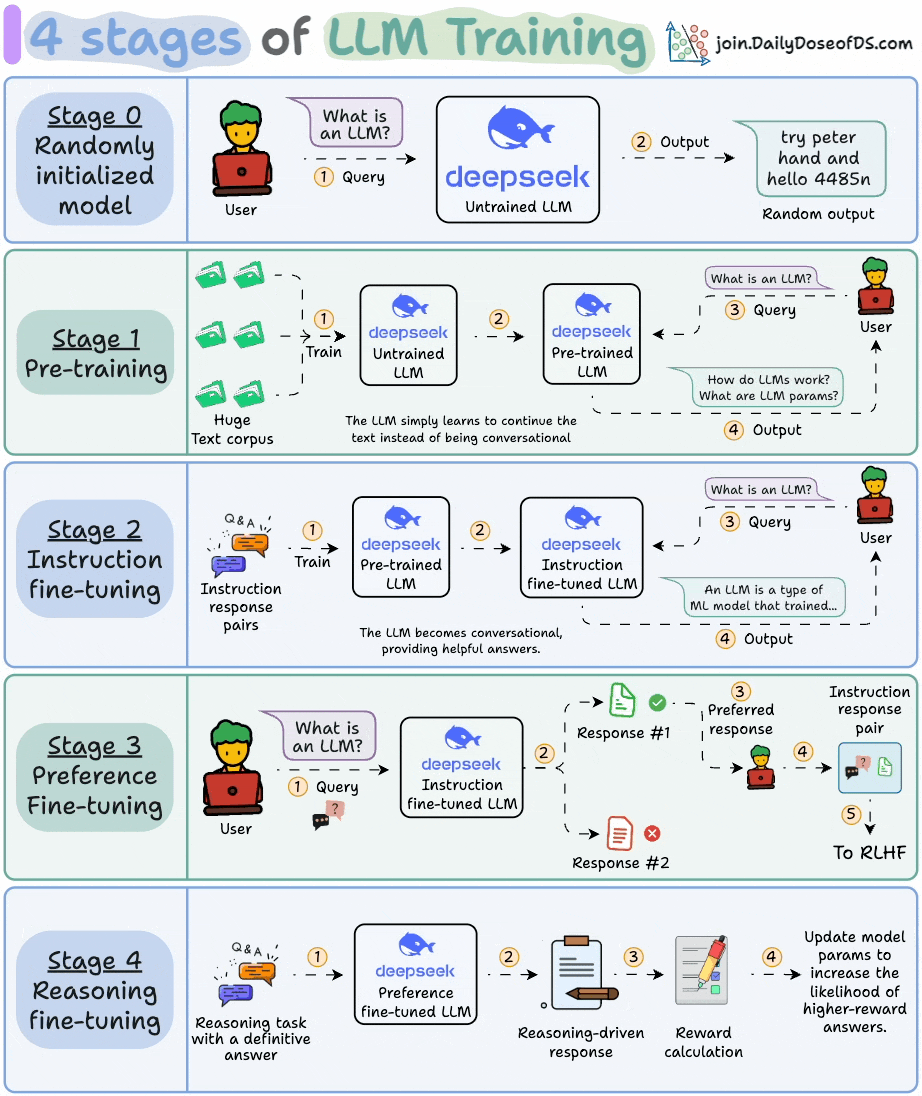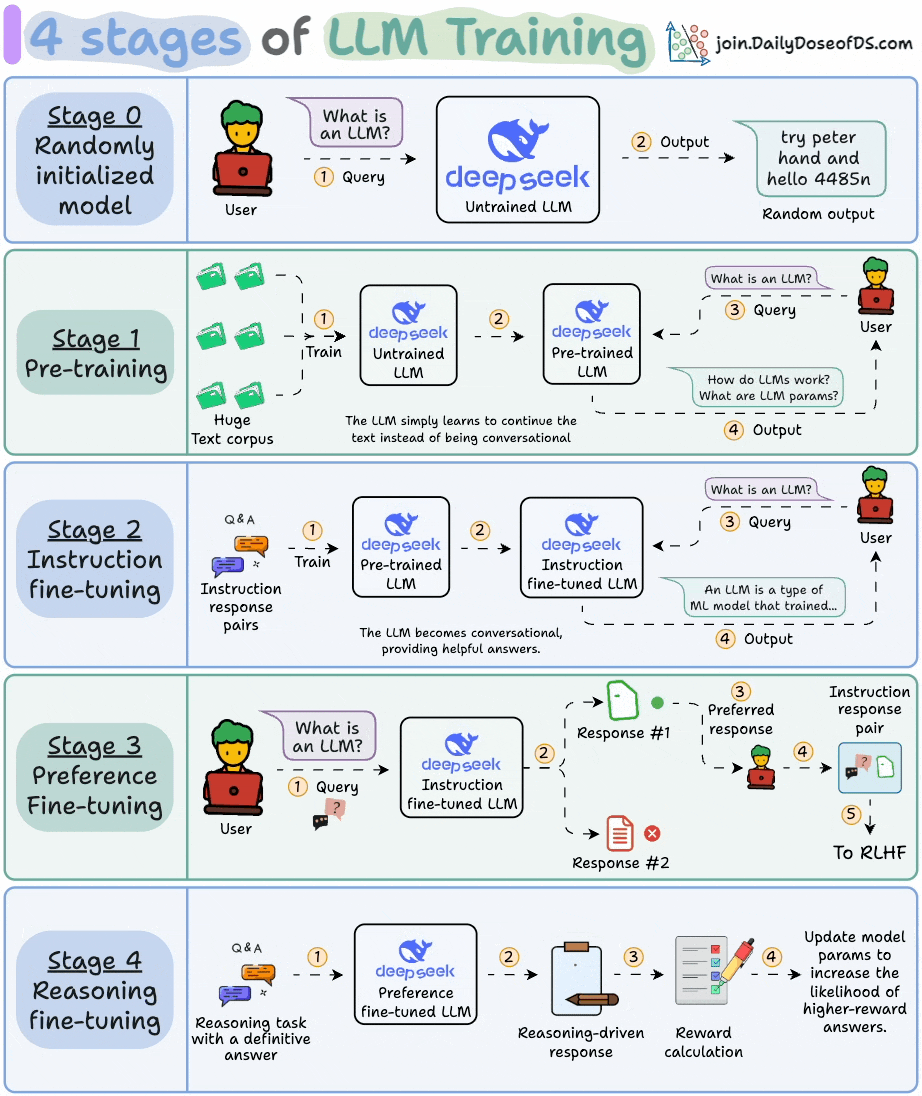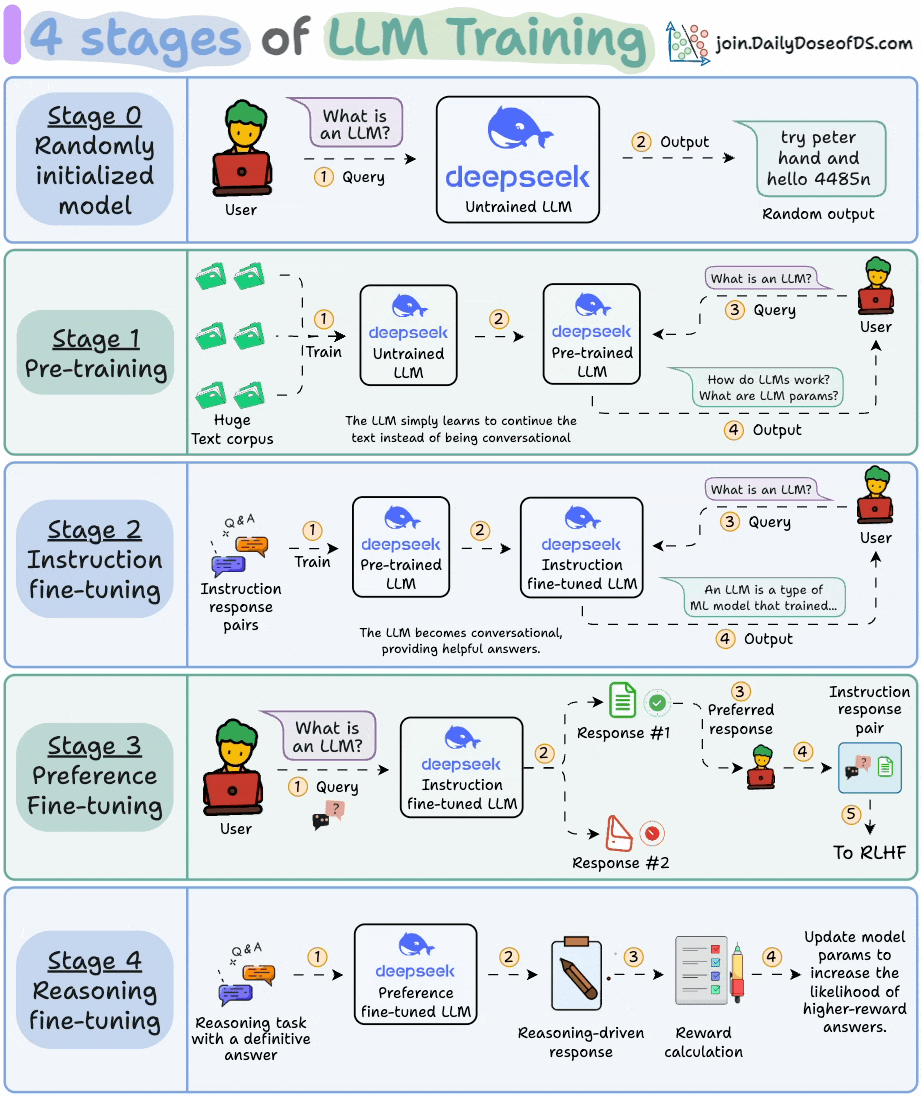
Today, let’s dive into the next stage and understand how exactly do LLMs work and generate text.
Before diving into LLMs, we must understand conditional probability.
Let's consider a population of 14 individuals:
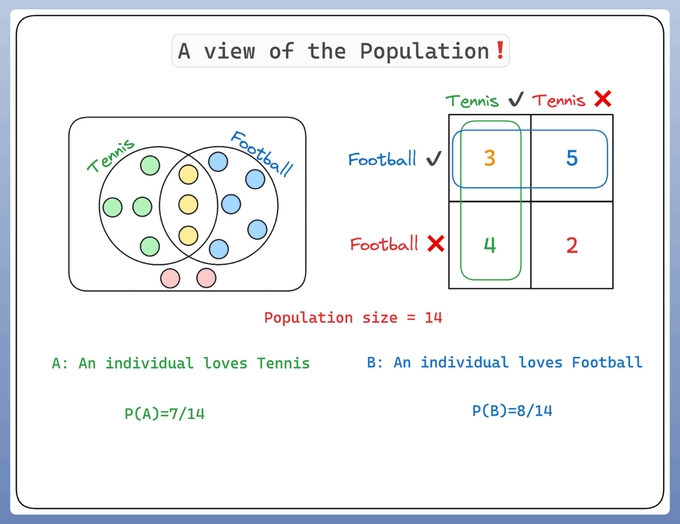
Some of them like Tennis 🎾
Some like Football ⚽️
A few like both 🎾 ⚽️
And few like none
Conditional probability is a measure of the probability of an event given that another event has occurred.
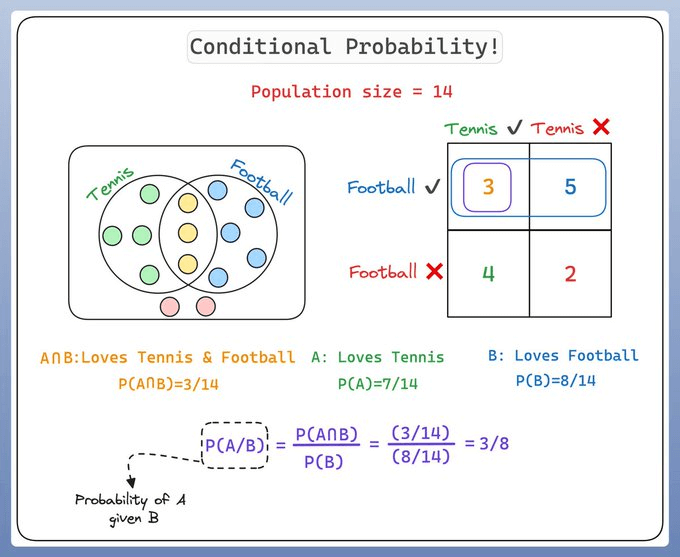
If the events are A and B, we denote this as P(A|B).
This reads as "probability of A given B"
For instance, if we're predicting whether it will rain today (event A), knowing that it's cloudy (event B) might impact our prediction.
As it's more likely to rain when it's cloudy, we'd say the conditional probability P(A|B) is high.
That's conditional probability!
Now, how does this apply to LLMs like GPT-4?
These models are tasked with predicting/guessing the next word in a sequence.

This is a question of conditional probability: given the words that have come before, what is the most likely next word?
To predict the next word, the model calculates the conditional probability for each possible next word, given the previous words (context).
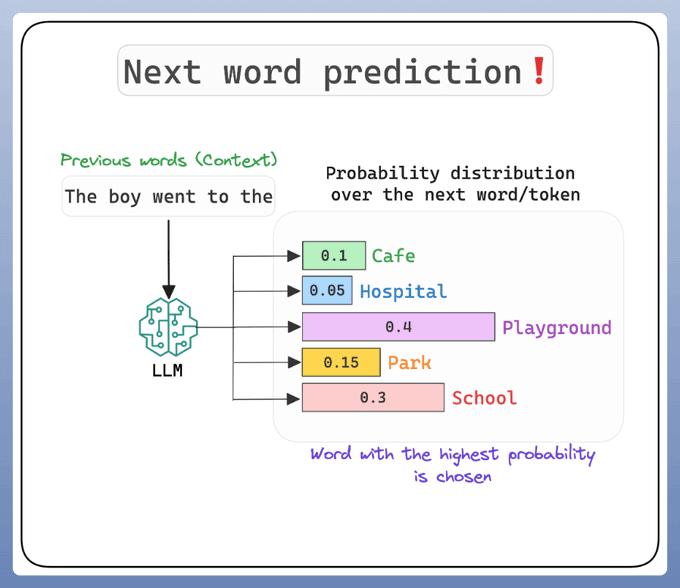
The word with the highest conditional probability is chosen as the prediction.
The LLM learns a high-dimensional probability distribution over sequences of words.

And the parameters of this distribution are the trained weights!
The training (or rather pre-training) is supervised.
But there is a problem!
If we always pick the word with the highest probability, we end up with repetitive outputs, making LLMs almost useless and stifling their creativity.

This is where temperature comes into the picture.
Let's understand what's going on..
To make LLMs more creative, instead of selecting the best token (for simplicity let's think of tokens as words), they "sample" the prediction.
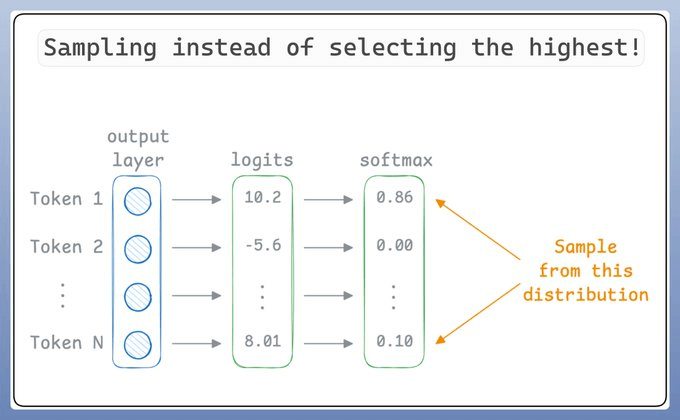
So even if “Token 1” has the highest score, it may not be chosen since we are sampling.
Now, temperature introduces the following tweak in the softmax function, which, in turn, influences the sampling process:
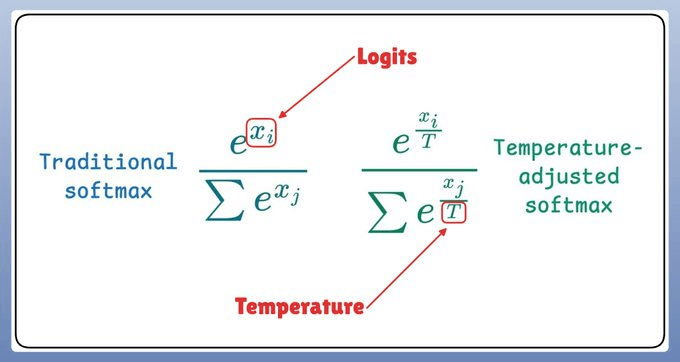
Let's take a code example!
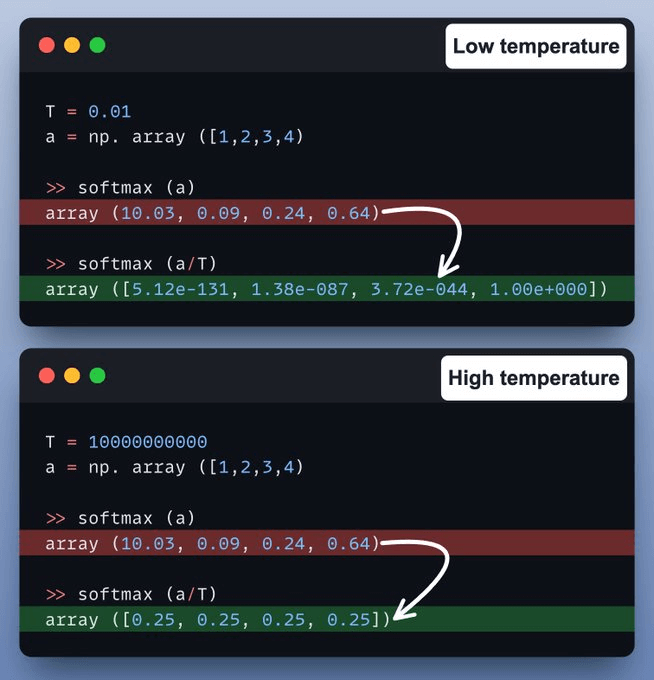
At low temperature, probabilities concentrate around the most likely token, resulting in nearly greedy generation.
At high temperature, probabilities become more uniform, producing highly random and stochastic outputs.
And that is how LLMs work and generate text!
Read this where we implemented pre-training of Llama 4 from scratch here →
It covers:
Character-level tokenization
Multi-head self-attention with rotary positional embeddings (RoPE)
Sparse routing with multiple expert MLPs
RMSNorm, residuals, and causal masking
And finally, training and generation.
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.