
How Do LLMs Work?
...explained with visuals and maths.

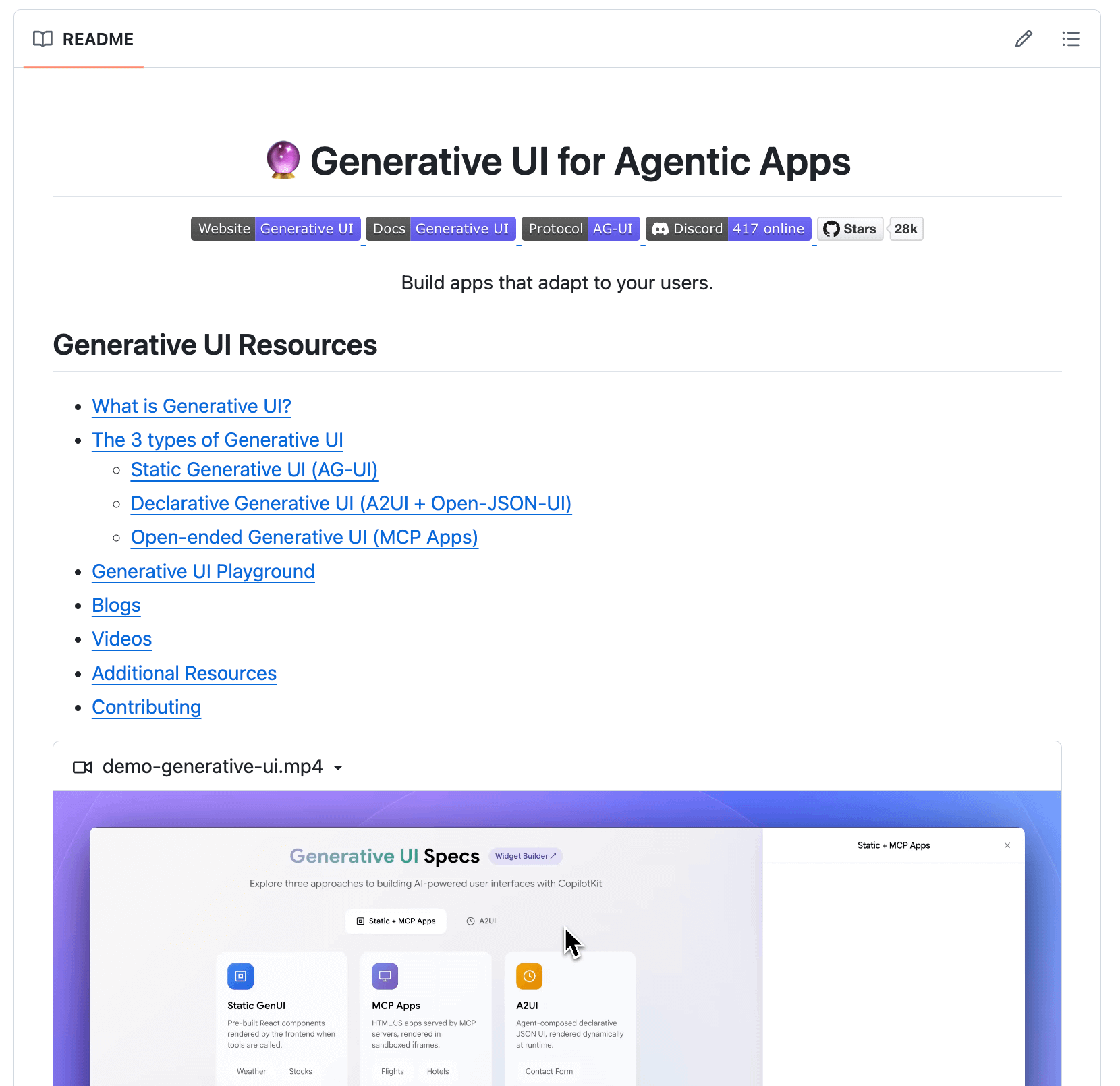
Resources to get started with Generative UI
Google. OpenAI. Anthropic.
They’re all working on the same problem for agents.
How to let agents control the UI layer at runtime, rather than just output text.
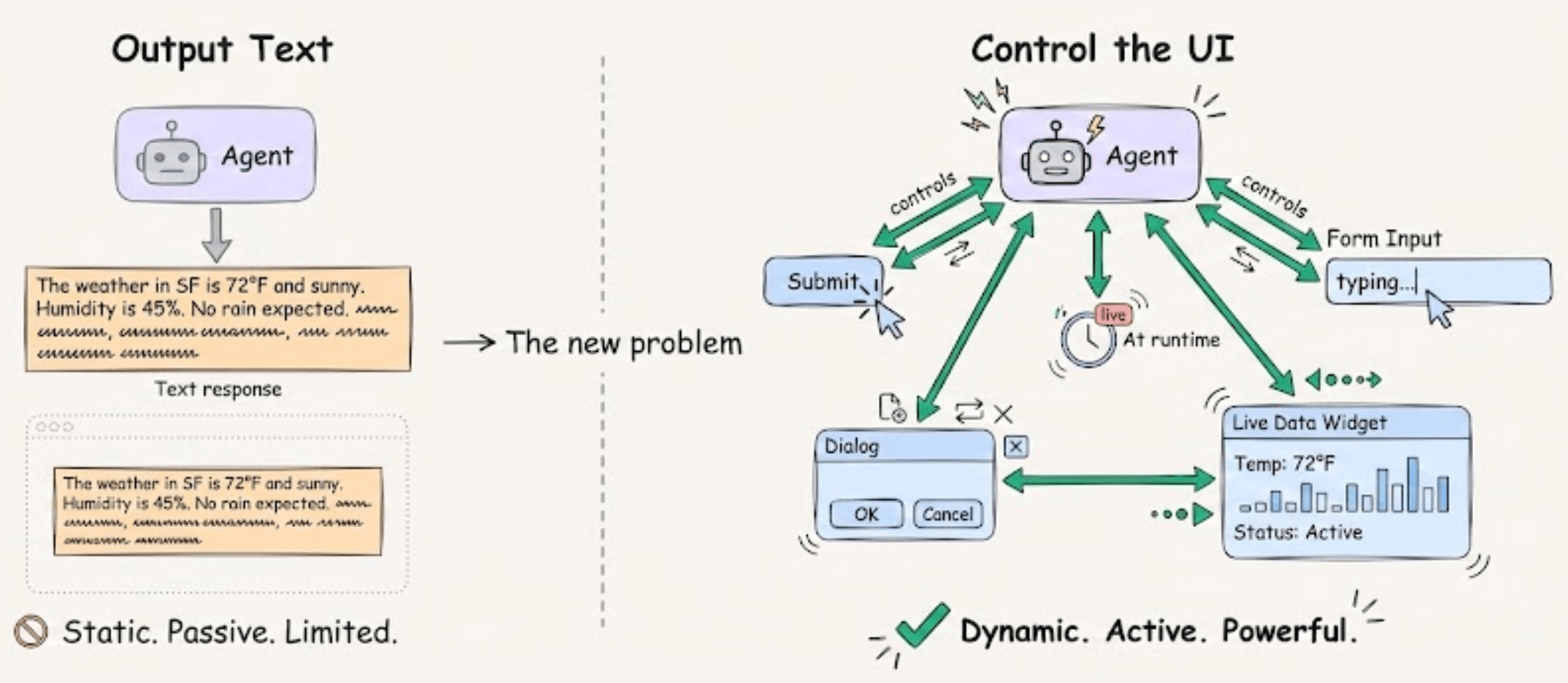
That’s Generative UI, and it’s built on three parts:
Anthropic’s MCP Apps + Google’s A2UI + CopilotKit’s AG-UI
These are the building blocks that power Generative UI behind agentic apps like Claude.
Until now, bringing them into your app has been complex, with no clear resources to follow.
But we found 2 resources that cover everything you need to get started.
Here’s what they cover:
What GenUI actually means (beyond buzzwords)
how it works via agentic UI specs (A2UI, MCP Apps...)
the three practical patterns
complete integration flow (with code)
how agent state, tools, and UI stay in sync (AG-UI protocol)
One is a detailed blog that goes deep into the concepts and the “why” behind the code. The other is a GitHub repo (400+ stars) that maps the patterns with examples you can run right away.
These are the best starter guides for building Generative UI into your full-stack apps.
You can find them here:
We’ll cover this in a hands-on demo soon!
How do LLMs work?
This visual explains the 4 stages of training LLMs from scratch:
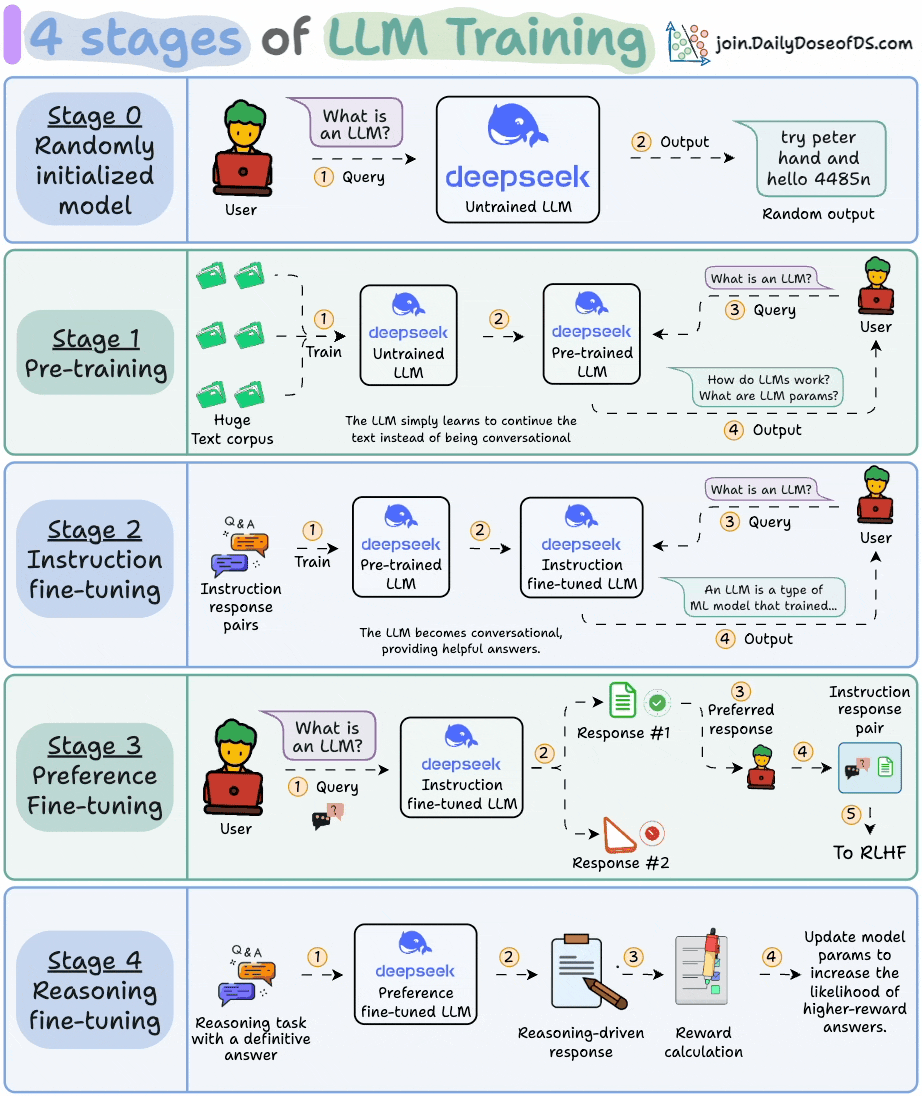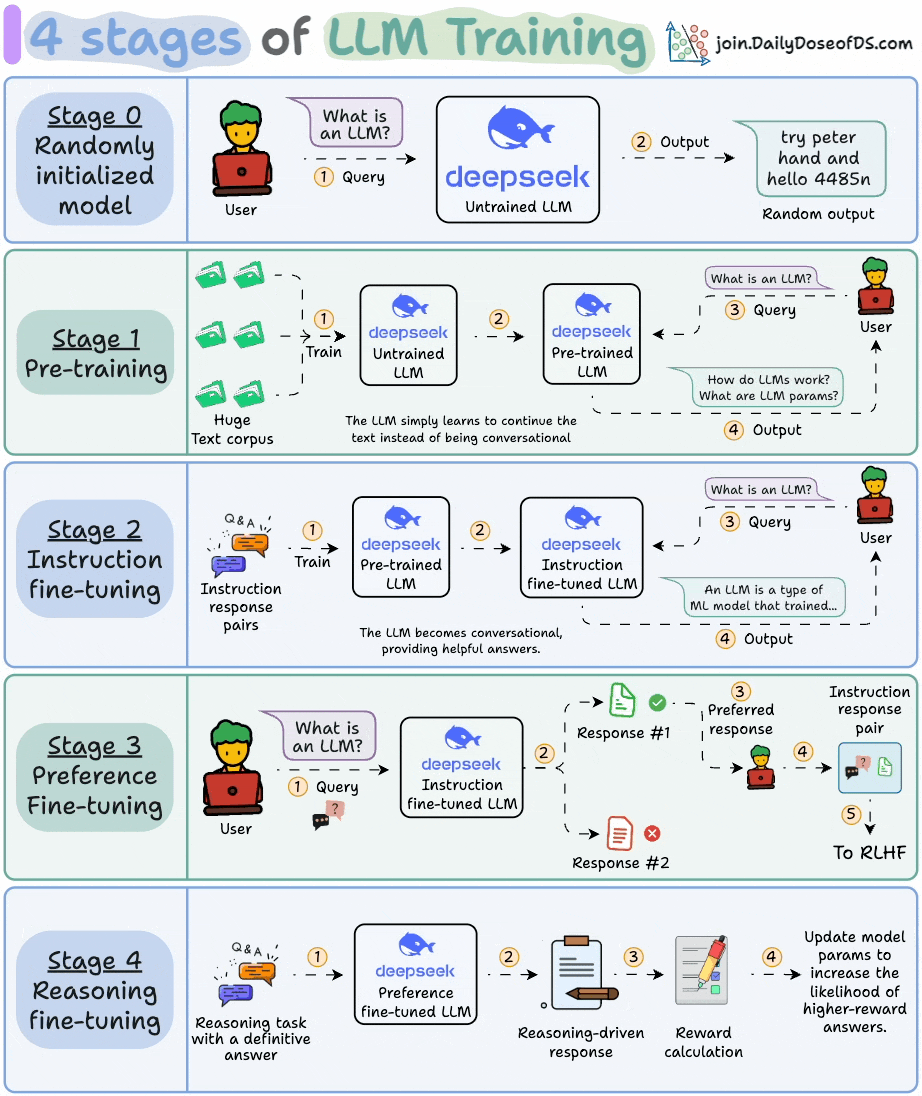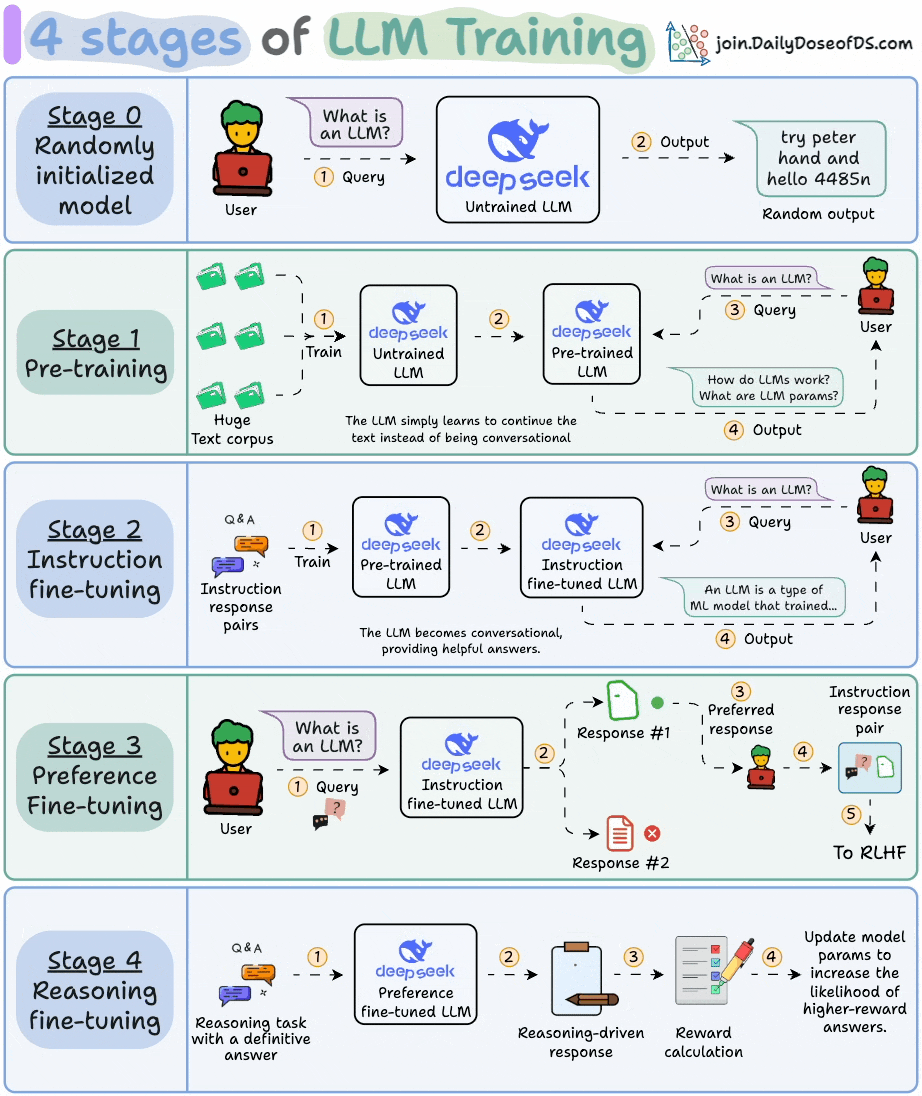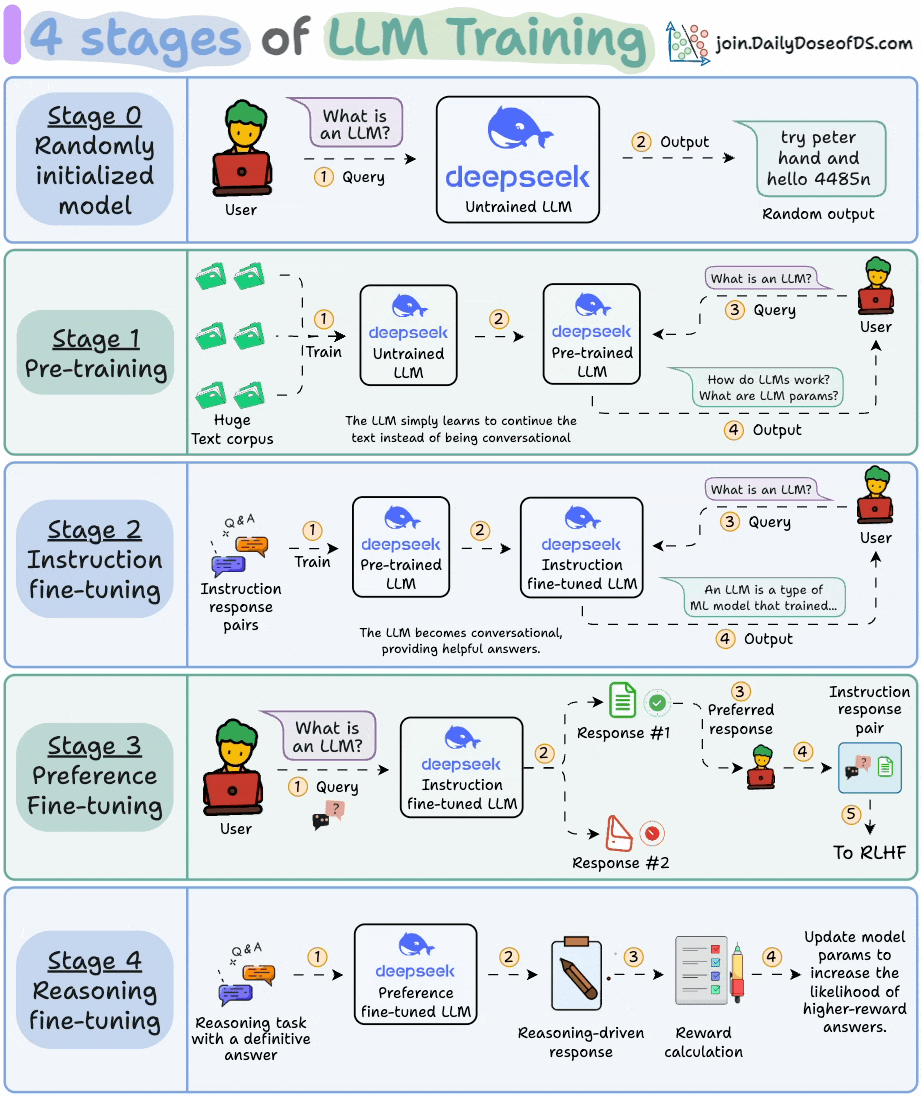
Today, let’s dive into the next stage and understand how exactly do LLMs work and generate text.
Before diving into LLMs, we must understand conditional probability.
Let’s consider a population of 14 individuals:
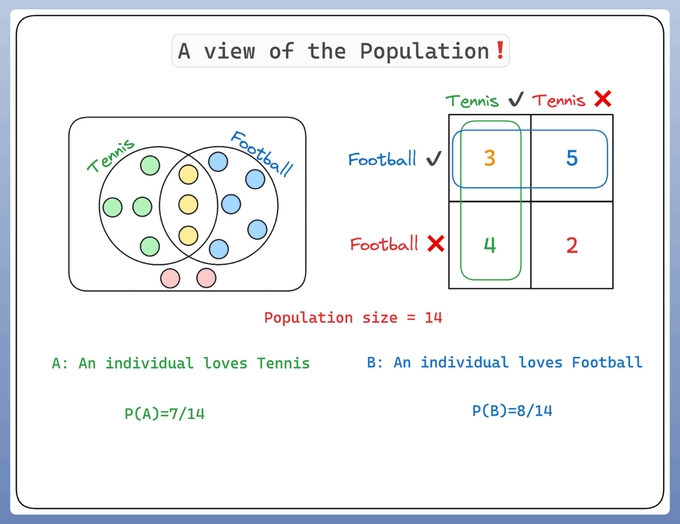
Some of them like Tennis 🎾
Some like Football ⚽️
A few like both 🎾 ⚽️
And few like none
Conditional probability is a measure of the probability of an event given that another event has occurred.
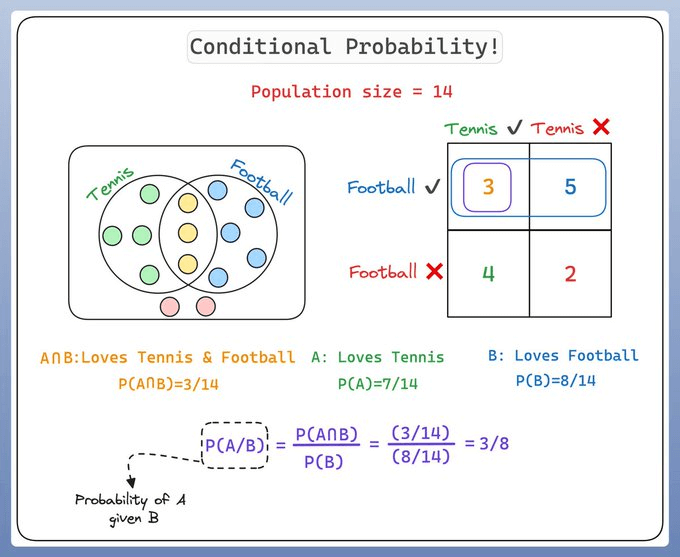
If the events are A and B, we denote this as P(A|B).
This reads as “probability of A given B”
For instance, if we’re predicting whether it will rain today (event A), knowing that it’s cloudy (event B) might impact our prediction.
As it’s more likely to rain when it’s cloudy, we’d say the conditional probability P(A|B) is high.
That’s conditional probability!
Now, how does this apply to LLMs like GPT-4?
These models are tasked with predicting/guessing the next word in a sequence.

This is a question of conditional probability: given the words that have come before, what is the most likely next word?
To predict the next word, the model calculates the conditional probability for each possible next word, given the previous words (context).
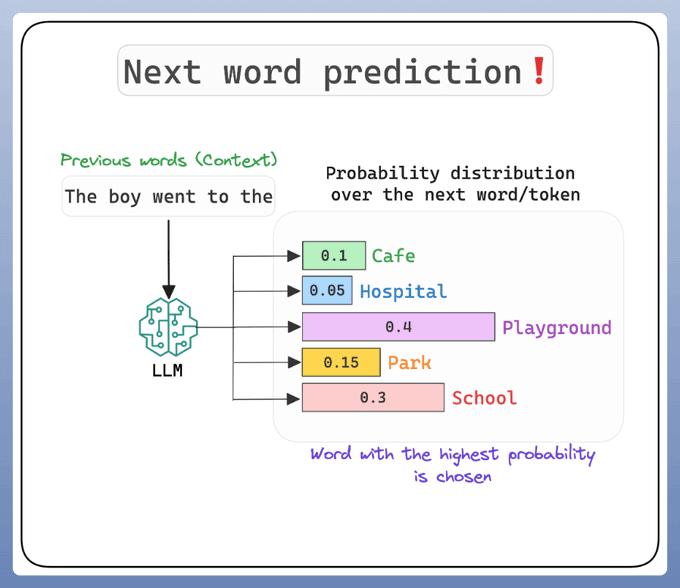
The word with the highest conditional probability is chosen as the prediction.
The LLM learns a high-dimensional probability distribution over sequences of words.

And the parameters of this distribution are the trained weights!
The training (or rather pre-training) is supervised.
But there is a problem!
If we always pick the word with the highest probability, we end up with repetitive outputs, making LLMs almost useless and stifling their creativity.

This is where temperature comes into the picture.
Let’s understand what’s going on..
To make LLMs more creative, instead of selecting the best token (for simplicity let’s think of tokens as words), they “sample” the prediction.
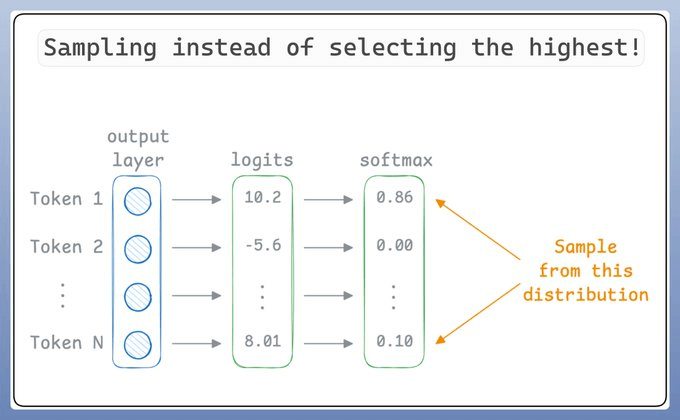
So even if “Token 1” has the highest score, it may not be chosen since we are sampling.
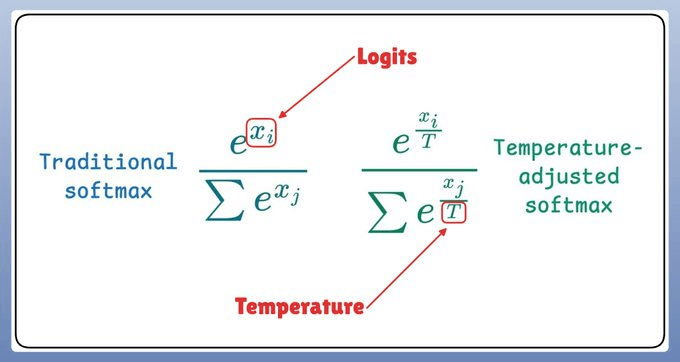
Now, temperature introduces the following tweak in the softmax function, which, in turn, influences the sampling process:
Let’s take a code example!
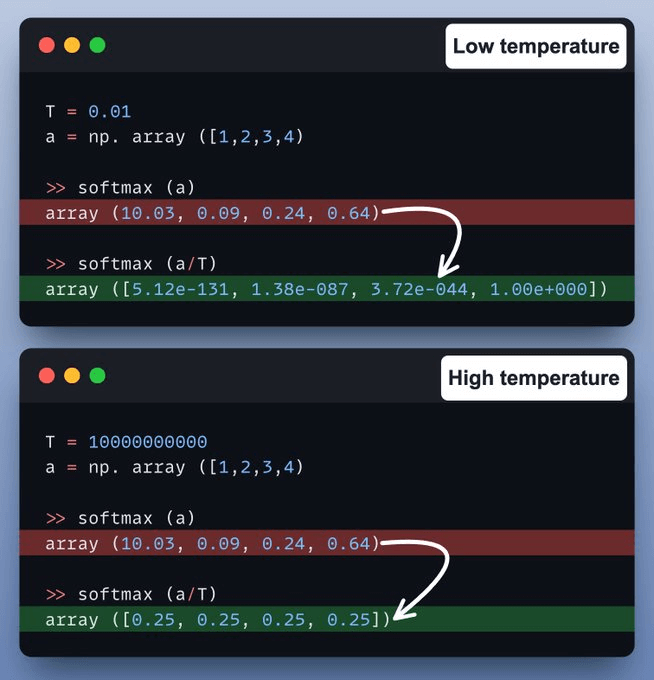
At low temperature, probabilities concentrate around the most likely token, resulting in nearly greedy generation.
At high temperature, probabilities become more uniform, producing highly random and stochastic outputs.
And that is how LLMs work and generate text!
Read this where we implemented pre-training of Llama 4 from scratch here →
It covers:
Character-level tokenization
Multi-head self-attention with rotary positional embeddings (RoPE)
Sparse routing with multiple expert MLPs
RMSNorm, residuals, and causal masking
And finally, training and generation.
Thanks for reading!
Hi @Avi Chawla , just curious, what tools do you use to make these animations.