
How Does BM25 Ranking Algorithm Work?
...explained with mathematical details.

A production-grade browser automation framework for Agents (open-source)!
Typical browser automation tools like Selenium, Playwright, or Puppeteer require you to hard-code your automations.
This makes them brittle since one change in the website can disrupt the entire automation.
On the other hand, high-level Agents like OpenAI Operator can be unpredictable in production.
Stagehand is an open-source framework that bridges the gap between:

brittle traditional automation like Playwright, Selenium, etc., and
unpredictable full-agent solutions like OpenAI Operator.
Key features:
Use AI when you want to navigate unfamiliar pages, and use code (Playwright) when you know exactly what you want to do.
Preview AI actions before running them, and cache repeatable actions to save tokens.
Compatible with SOTA computer use models with just one line of code.
Available in both Python and Typescript SDK.
Stagehand also has an open-source MCP server.
You can find the GitHub repo here →
How Does BM25 Ranking Algorithm Work?
A 30-year-old algorithm with zero training, zero embeddings, and zero fine-tuning still powers Elasticsearch, OpenSearch, and most production search systems today.
It’s called BM25.
Let’s understand what makes it so powerful:
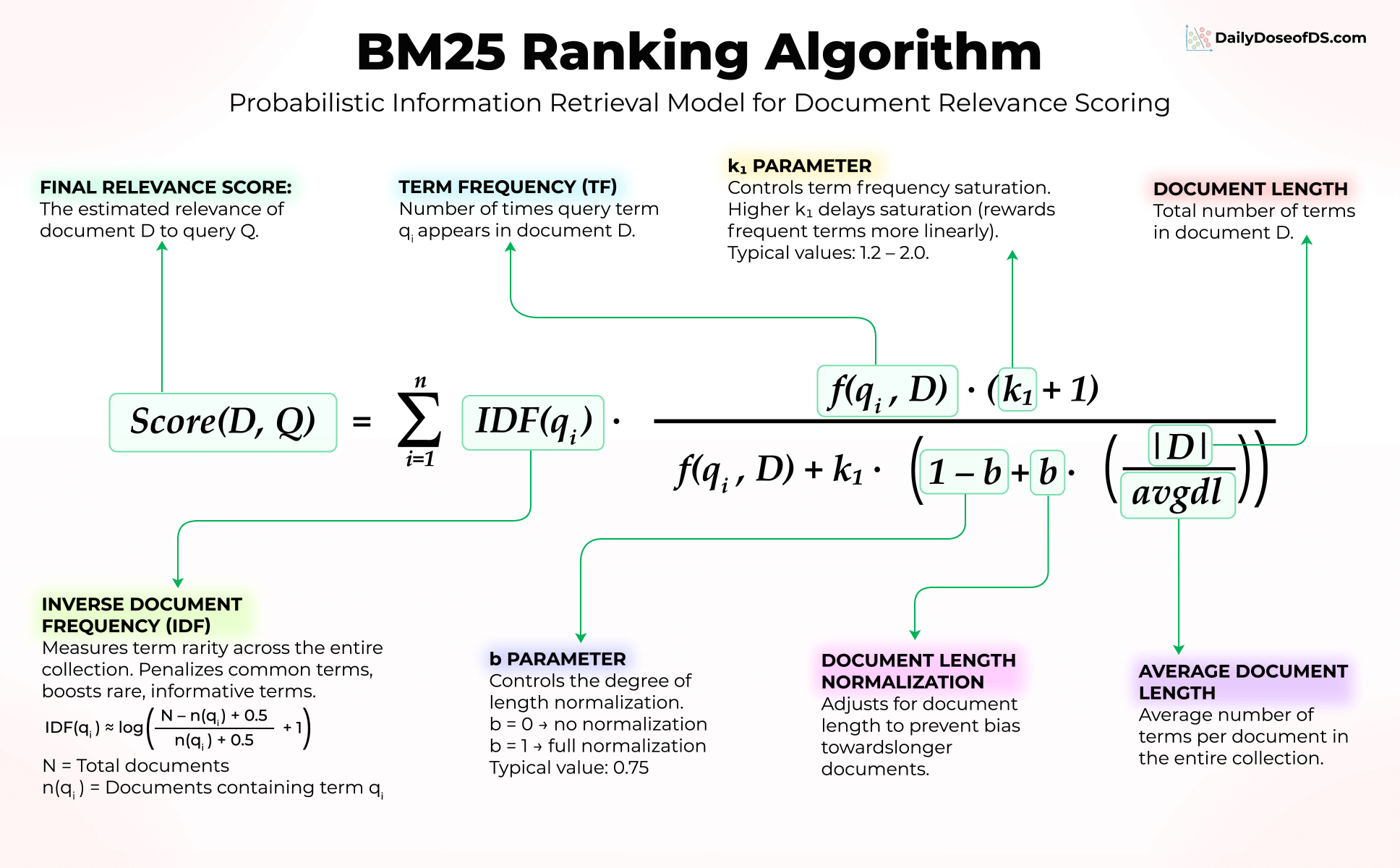
Imagine you’re searching for “transformer attention mechanism” in a library of ML papers.
BM25 asks three simple questions:
“How rare is this word?”
Every paper contains “the” and “is”, which makes it useless. But “transformer” is specific and informative. BM25 boosts rare words and ignores the noise.
→ This is IDF(qᵢ) in the formula
“How many times does it appear?”
If “attention” appears 10 times in a paper, that’s a good sign. But 10 vs 100 occurrences won’t make much difference. BM25 applies diminishing returns.
→ This is f(qᵢ, D) combined with k₁ that controls saturation
“Is this document unusually long?”
A 50-page paper will naturally contain more keywords than a 5-page paper. BM25 levels the playing field so longer documents don’t cheat their way to the top.
→ This is |D|/avgdl controlled by parameter b
Overall, BM25 is based around three questions, with no requirement for neural networks (refer to the image below again):
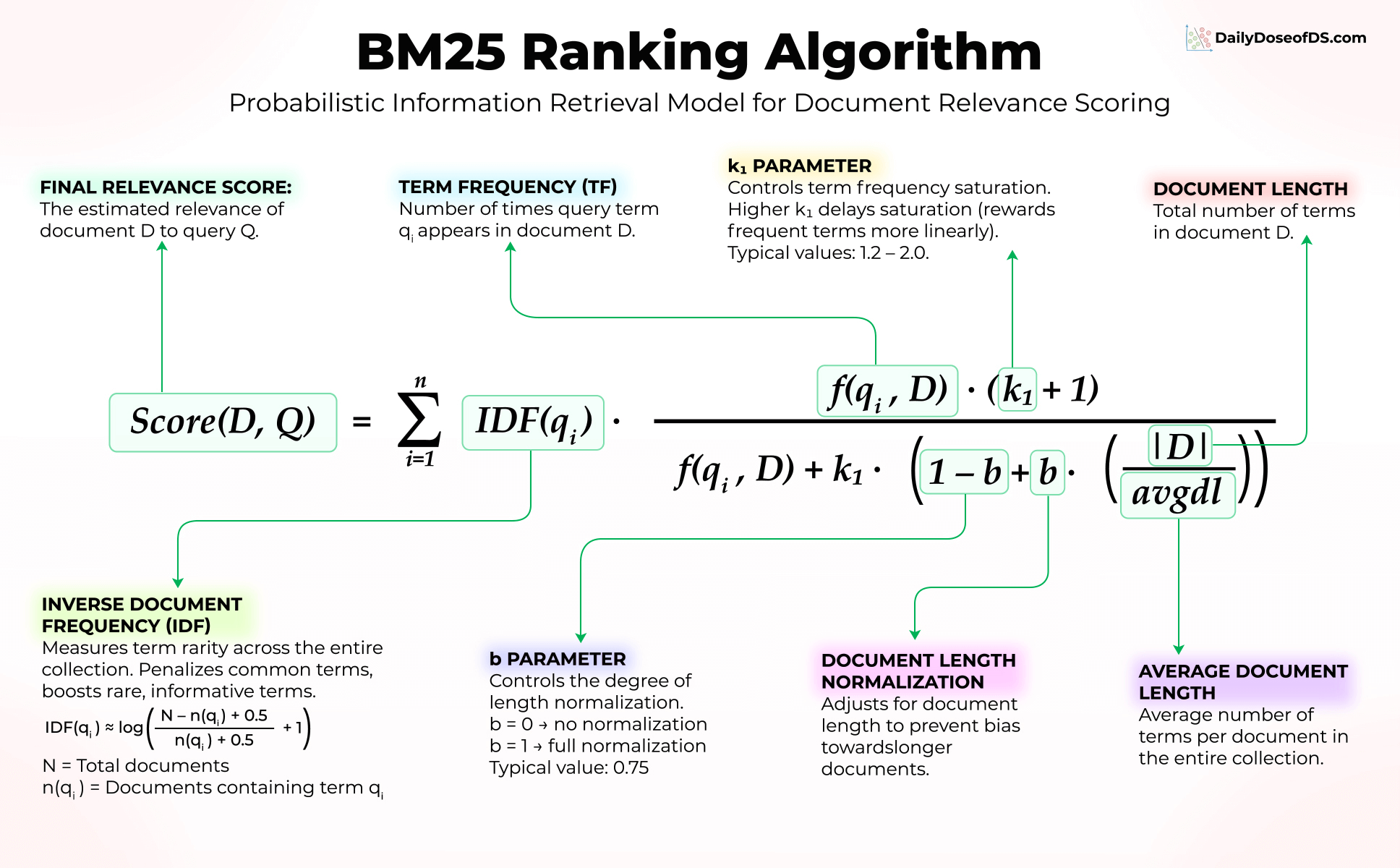
BM25 excels at exact keyword matching, which is something embeddings often struggle with. It also shines when your corpus has domain-specific terminology that embedding models probably weren’t trained on.
If your user searches for “error code 5012,” embeddings might return semantically similar results. BM25 will find the exact match.
This is why hybrid search exists.
Top RAG systems today combine BM25 with vector search. You get the best of both worlds: semantic understanding AND precise keyword matching.
Also, the entire hybrid search stack you mentioned is actually implemented in Airweave that we use as a context layer for Agents:

So before you throw GPUs at every search problem, consider BM25. It might already solve your problem, or make your semantic search even better when combined.
👉 Over to you: What topics would you like to learn next?
Thanks for reading!