
How Dropout Actually Works
A lesser-known detail of Dropout.

Run Python workloads on cloud with just a decorator!
Using the cloud is often harder than programming itself. Running any simple Python workflow on the cloud requires:
navigating consoles
setting IAM policies
writing YAML configs
monitoring billing spikes
Coiled lets you run any Python workload on the cloud in just two lines of code.
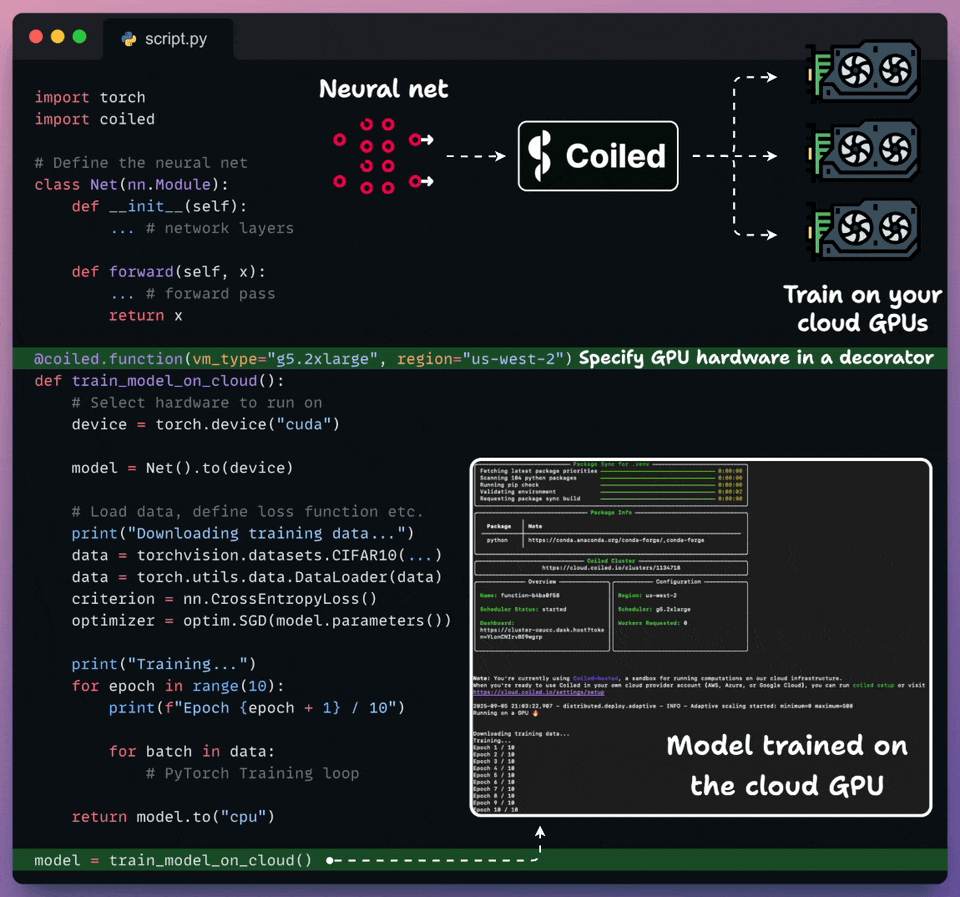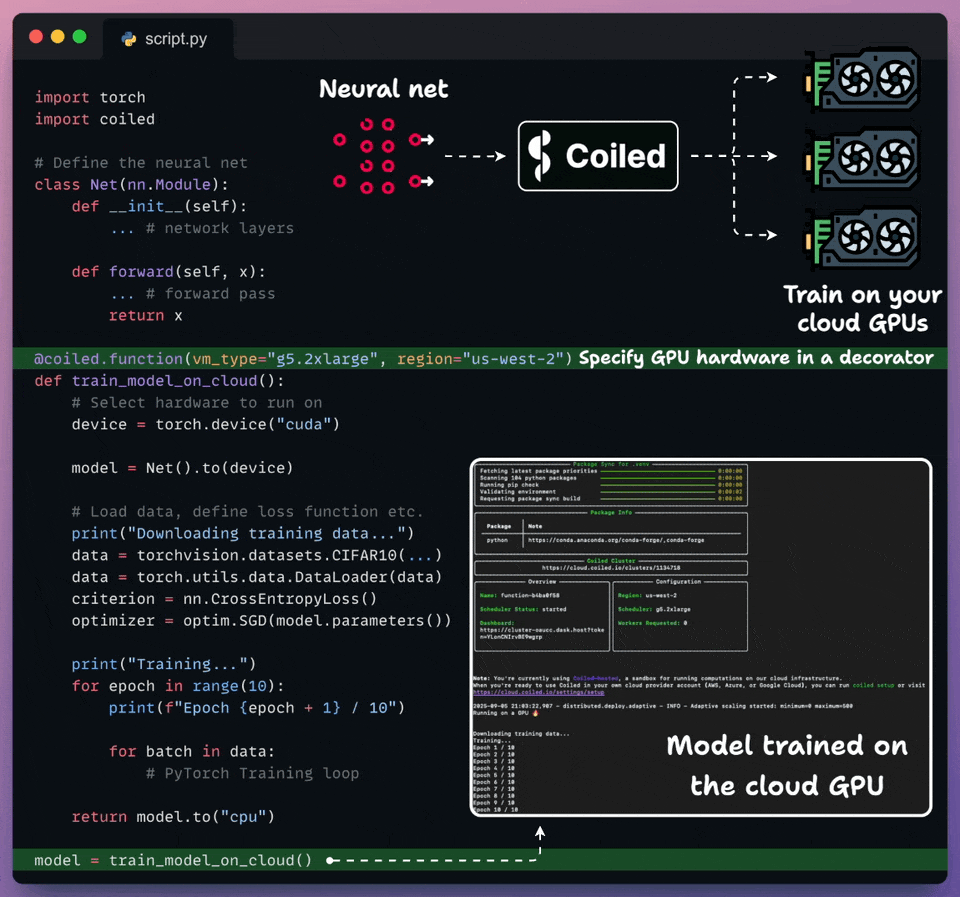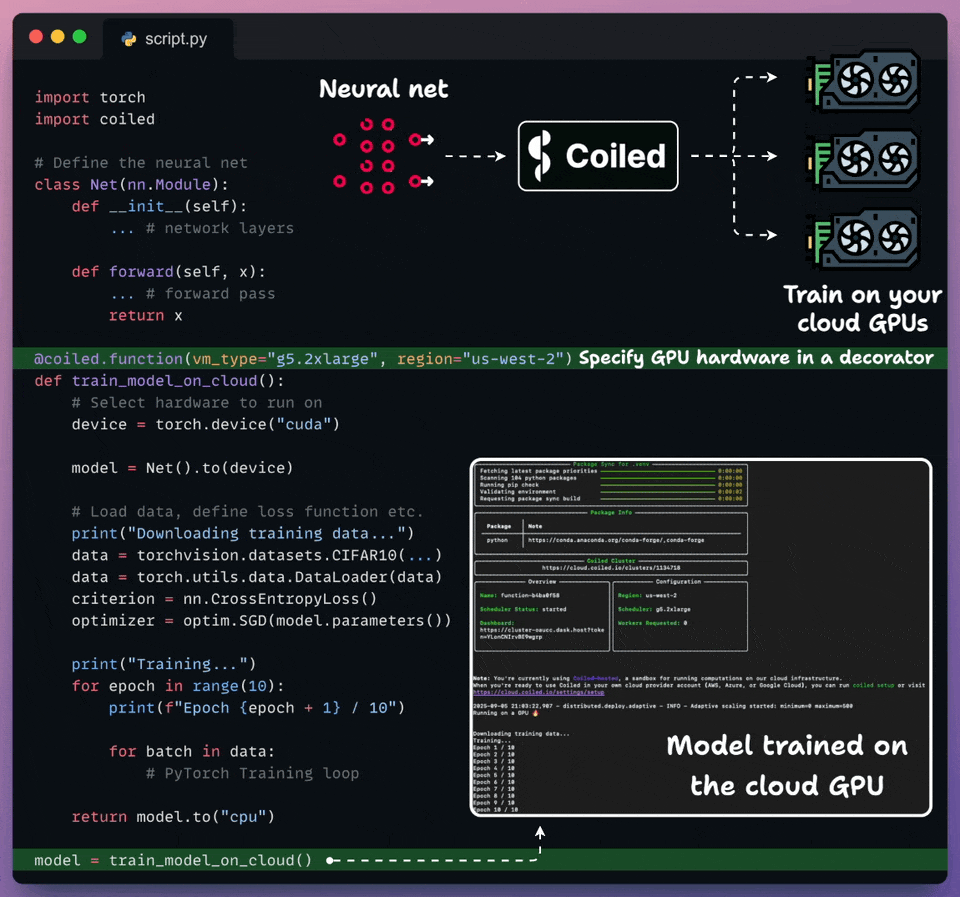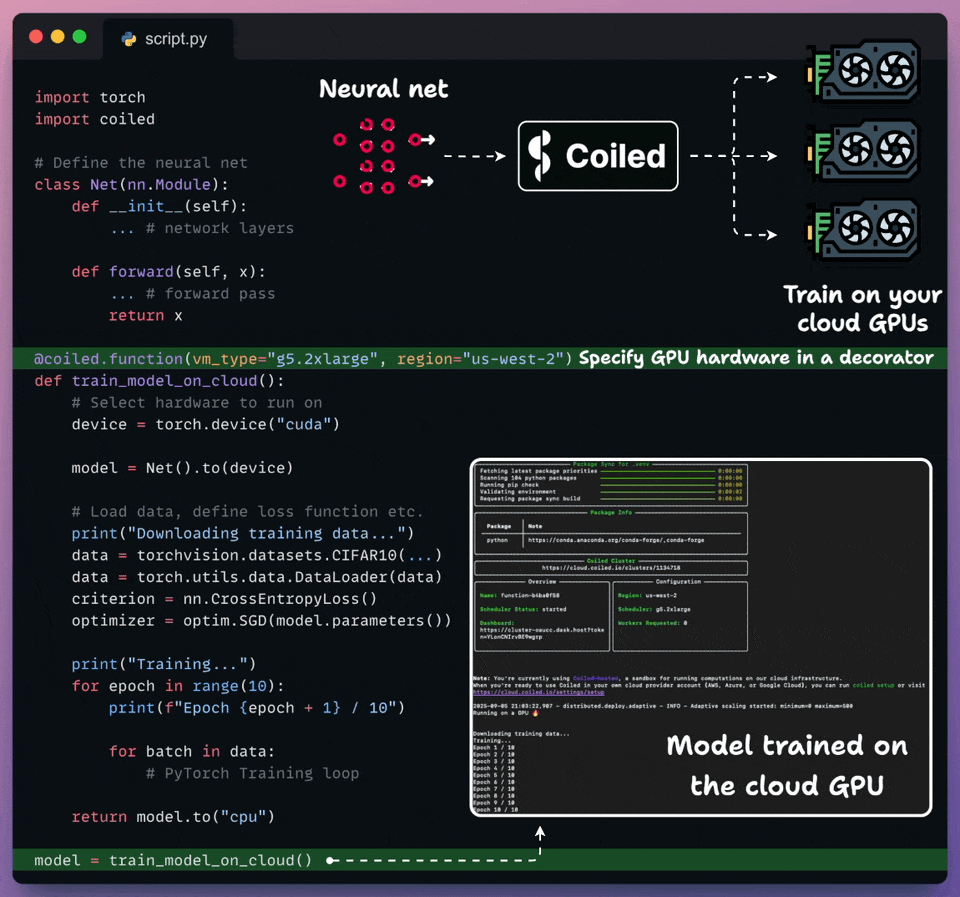
Import coiled.
Decorate the Python function and specify the hardware, region, etc.
Done!
It automatically syncs your local environment, runs the code on the specified hardware in your own cloud account, and shuts it down when you’re done.
Coiled is free for most users with 500 free CPU hours per month.
Thanks to Coiled for partnering today!
How Dropout Actually Works
Here’s what people typically know about Dropout:
It zeros out neurons randomly in a neural network.
It is only applied during training randomly.
But there’s one more missing detail here.
Let’s dive in!
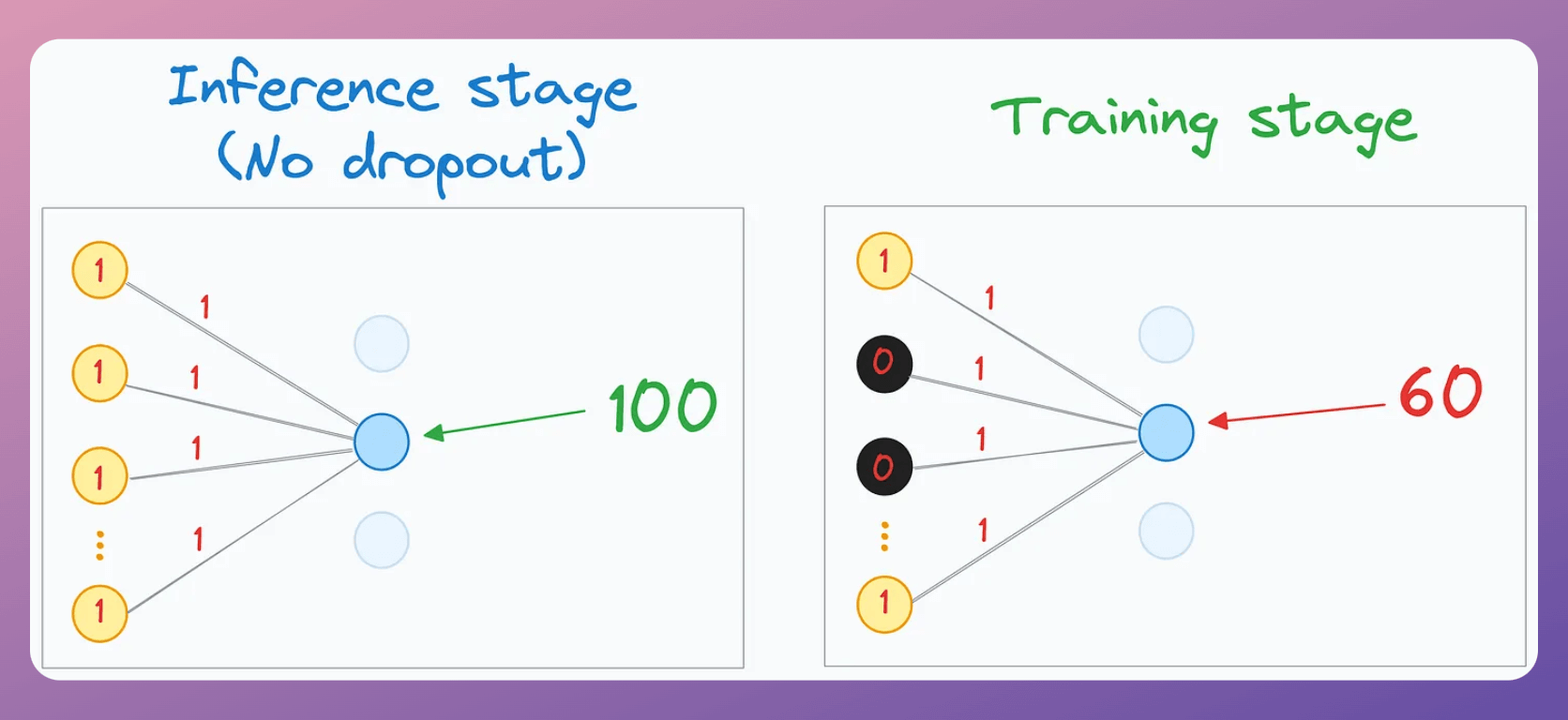
Consider a neuron whose input is computed using 100 neurons in the previous hidden layer (during training):
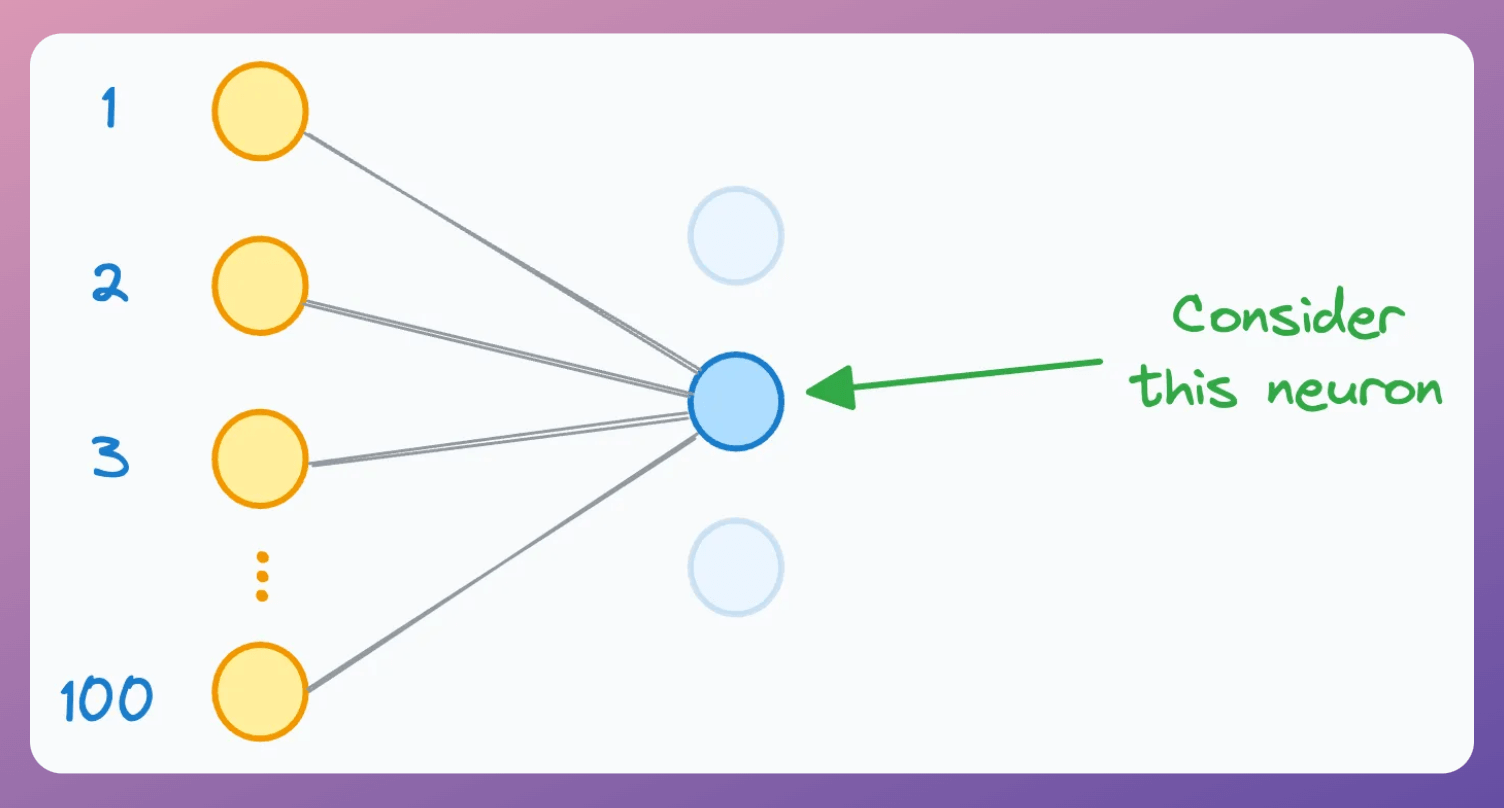
For simplicity, let’s assume:
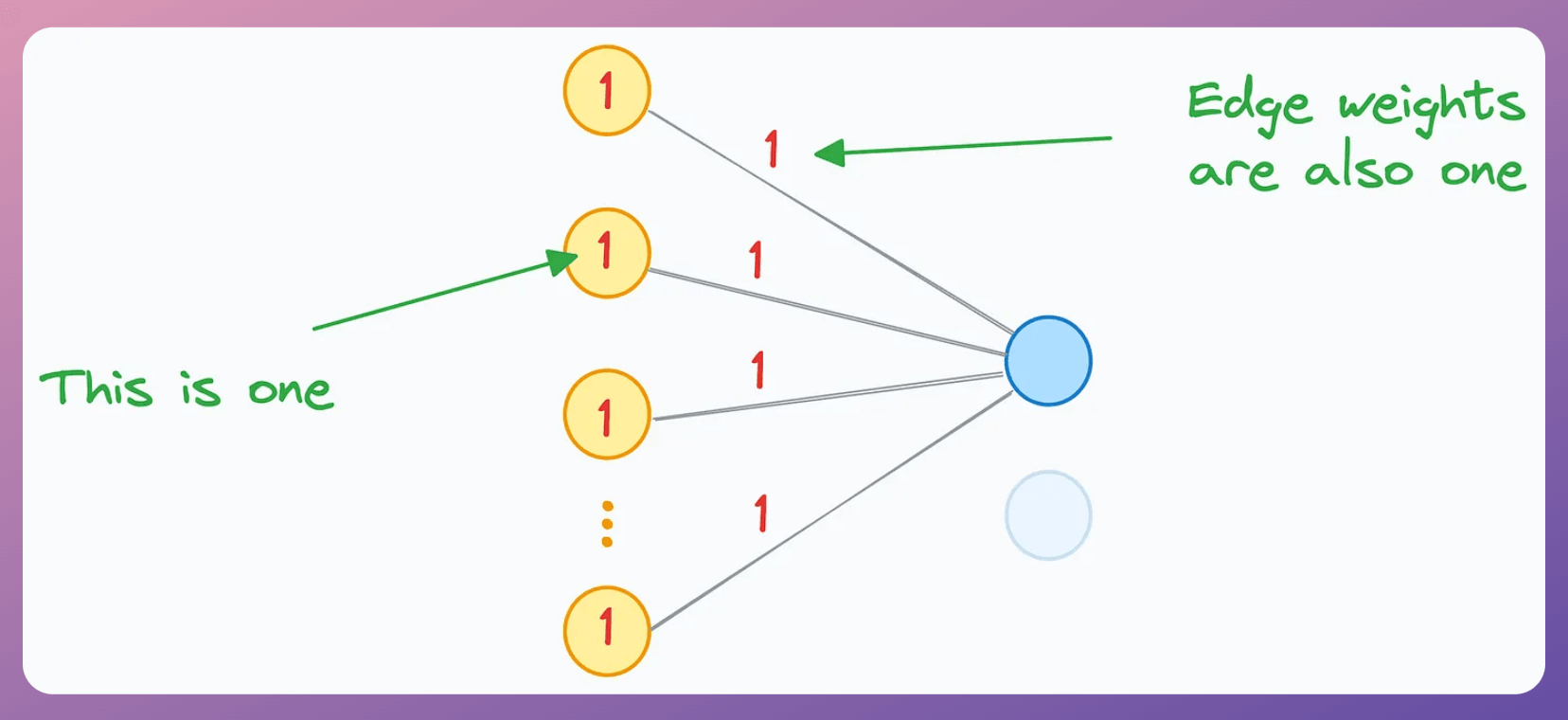
The activation of every yellow neuron is 1.
The edge weight from the yellow neurons to the blue neuron is also 1.
As a result, the input received by the blue neuron will be 100:
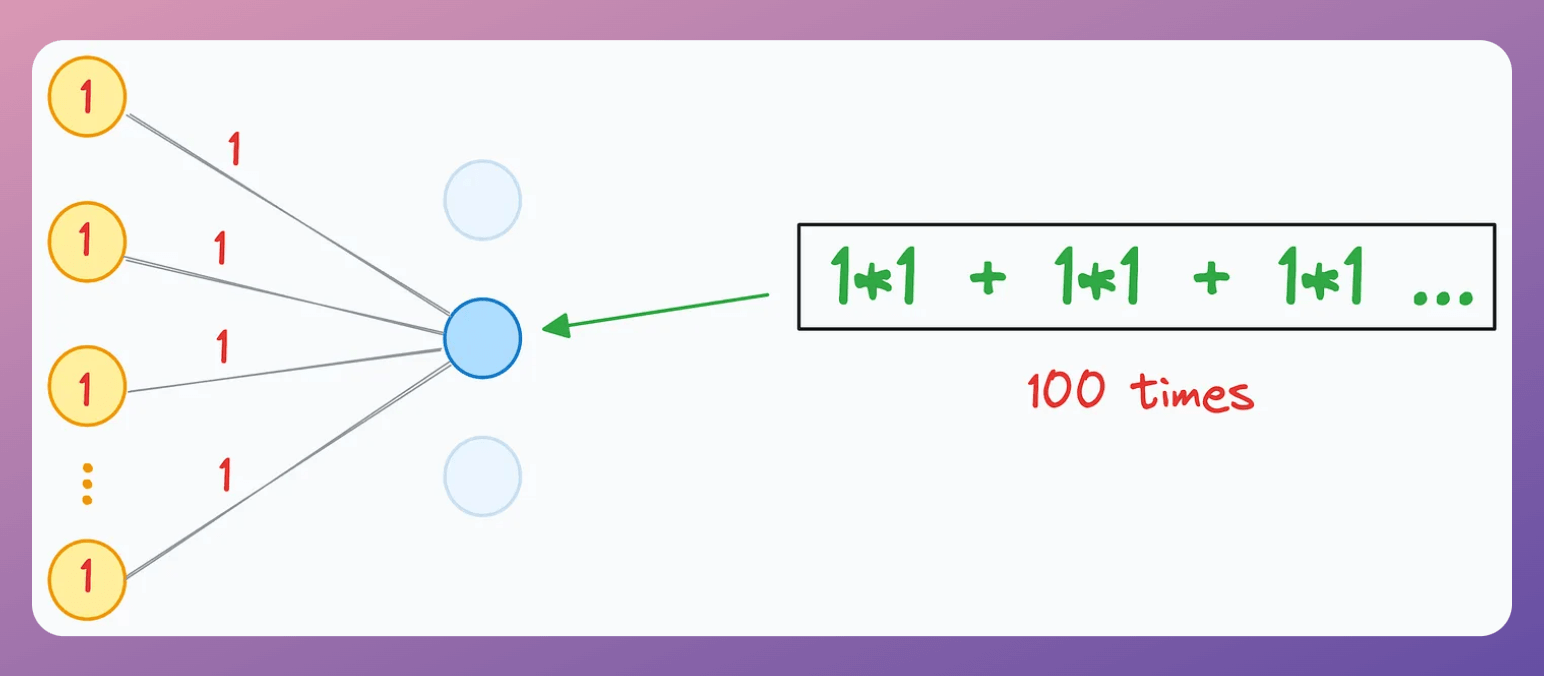
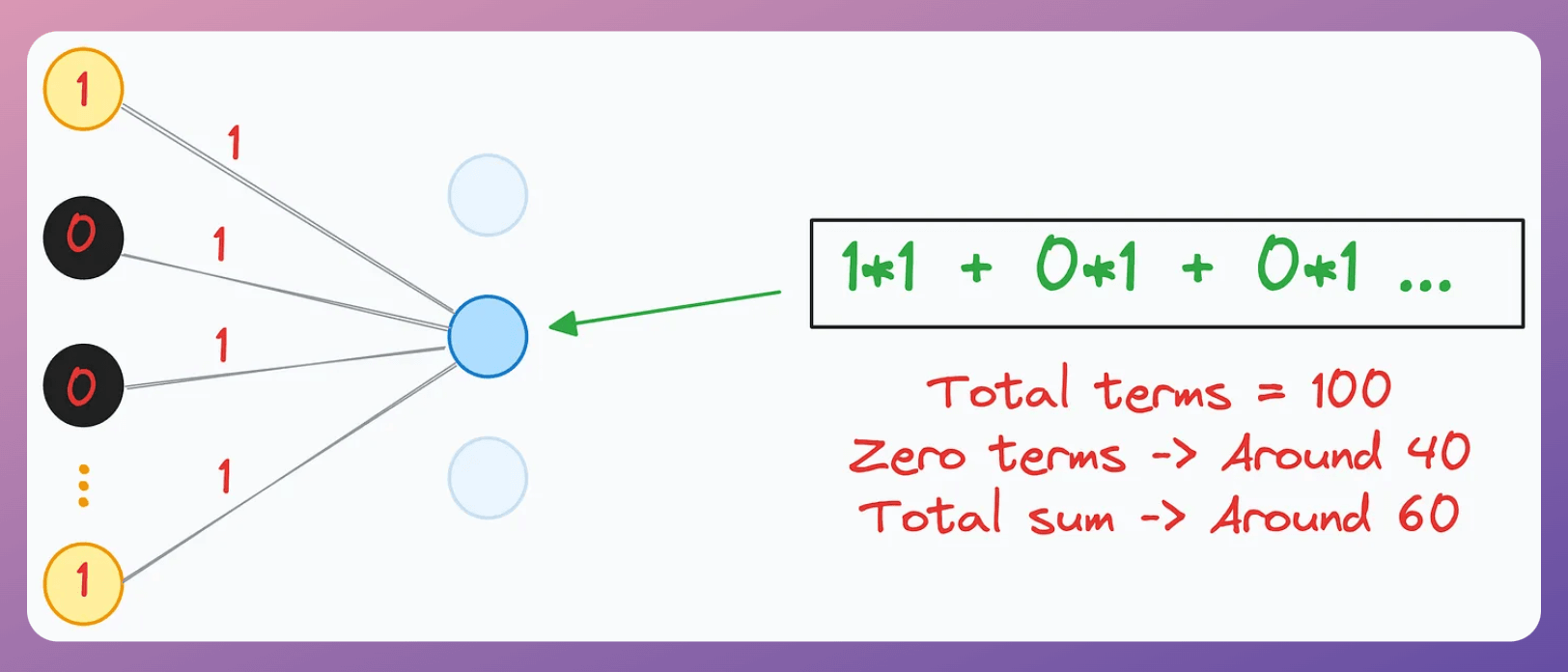
Now, during training, say we had a 40% dropout rate, so roughly 40% of the yellow neuron activations would have been zeroed out.
As a result, the input received by the blue neuron would have been around 60:
But if the same scenario had existed during the inference stage, then the input received by the blue neuron would have been 100 (there wouldn’t be dropout).
Thus, under similar conditions:
The input received during training → 60.
The input received during inference → 100.
Essentially, during training, the average neuron inputs are significantly lower than those received during inference.
This means Dropout affects the scale of the activations, and we need to ensure that the model stays consistent.
To address this, Dropout also scales all activations during training by a factor of 1/(1-p), where p is the dropout rate. For instance, on a neuron input of 60, we get the following (p=40%):
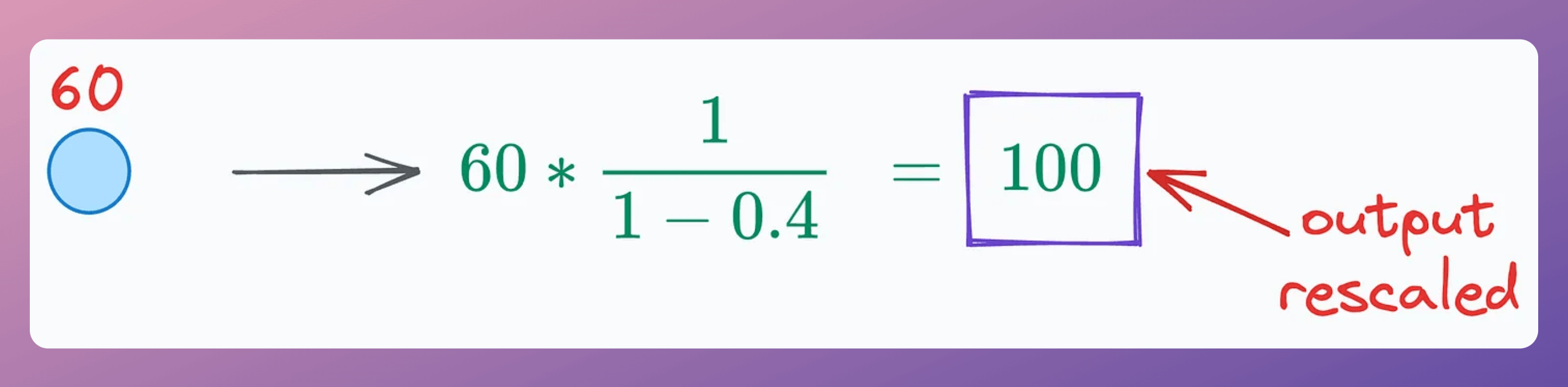
Scaling the neuron brings it to the desired range, which makes training and inference stages coherent.
We can also verify that experimentally.
First, we define a dropout layer:

Next, we create a random tensor and apply dropout to it:

In the above output, notice that the retained values have increased:
The second value goes from 0.13 → 0.16.
The third value goes from 0.93 → 1.16.
and so on…
We can also verify that the retained values match what scaling the input tensor with 1/(1-p) would give:

Doing the same thing in evaluation mode neither drops nor scales as expected:

This scaling step is highly important since it maintains numerical coherence between training and inference stages.
With that, now you know 100% of how Dropout works.
Here are some more missing details that I don’t see people talk about often:
Why Sklearn’s Logistic Regression Has No Learning Rate Hyperparameter?
Gradient descent is a typical way to train logistic regression.

But if that is the case, then why there’s no learning rate hyperparameter (α) in its sklearn implementation:

Moreover, the parameter list has the ‘
max_iter’ parameter that intuitively looks analogous to the epochs.

We have epochs but no learning rate (α), so how do we even update the model parameters using SGD?
Learn this here: Why Sklearn’s Logistic Regression Has No Learning Rate Hyperparameter?
Why Bagging is So Ridiculously Effective At Variance Reduction?
Everyone says we must sample rows from the training dataset with replacement. Why?
Also, how to mathematically formulate the idea of Bagging and prove variance reduction.

Read this to learn more: Why Bagging is So Ridiculously Effective At Variance Reduction?
👉 Over to you: What are some other ways to regularize neural networks?
Thanks for reading!