
How Many Dimensions Should You Reduce Your Data To When Using PCA?
Use this plot to find out.

When using PCA, it can be difficult to determine the number of components to keep. Yet, here's a plot that can immensely help.
Note: If you don’t know how PCA works, feel free to read my detailed post: A Visual Guide to PCA.
Still, here’s a quick step-by-step refresher. Feel free to skip this part if you remember my PCA post.

Step 1. Take a high-dimensional dataset ((x, y) in the above figure) and represent it with uncorrelated axes ((x`, y`) in the above figure). Why uncorrelated?
This is to ensure that data has zero correlation along its dimensions and each new dimension represents its individual variance.
For instance, as data represented along (x, y) is correlated, the variance along x is influenced by the spread of data along y.
Instead, if we represent data along (x`, y`), the variance along x` is not influenced by the spread of data along y`.
The above space is determined using eigenvectors.
Step 2. Find the variance along all uncorrelated axes (x`, y`). The eigenvalue corresponding to each eigenvector denotes the variance.
Step 3. Discard the axes with low variance. How many dimensions to discard (or keep) is a hyperparameter, which we will discuss below. Project the data along the retained axes.
When reducing dimensions, the purpose is to retain enough variance of the original data.
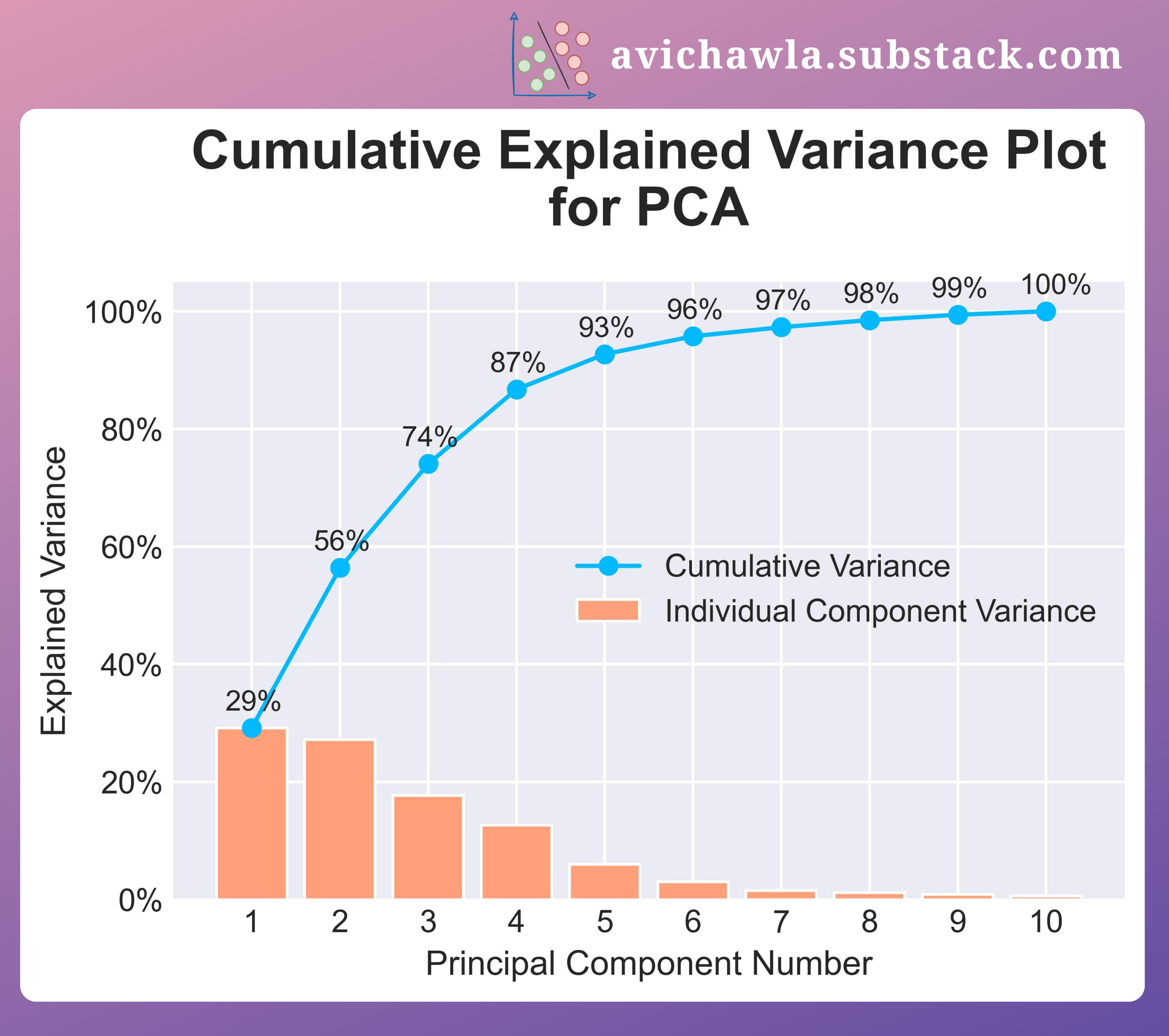
As each principal component explains some amount of variance, cumulatively plotting the component-wise variance can help identify which components have the most variance.
This is called a cumulative explained variance plot.

For instance, say we intend to retain ~85% of the data variance. The above plot clearly depicts that reducing the data to four components will do that.
Also, as expected, all ten components together represent 100% variance of the data.
Creating this plot is pretty simple in Python. Find the code here: PCA-CEV Plot.
Over to you: What other methods do you commonly use to find the number of principal components?
👉 Read what others are saying about this post on LinkedIn.
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
👉 If you love reading this newsletter, feel free to share it with friends!
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.