
How to Actually Use Train, Validation and Test Set
Explained with an intuitive analogy.

Summarise any meeting in just 5 lines of code!
AssemblyAI's LeMUR automatically captures and analyzes meetings, transforming hours of conversation into summaries, action items, and insights—all powered by LLMs.

Here’s how it works:
Add a meeting URL.
Use AssemblyAI's speech-to-text for transcription.
Pass it to LeMUR with your custom prompt template.
Receive a summary and everything you need.
Try it here and get 100+ hours of FREE transcription →
Thanks to AssemblyAI for partnering today!
How to Actually Use Train, Validation, and Test Set
It is conventional to split the given data into train, test, and validation sets.
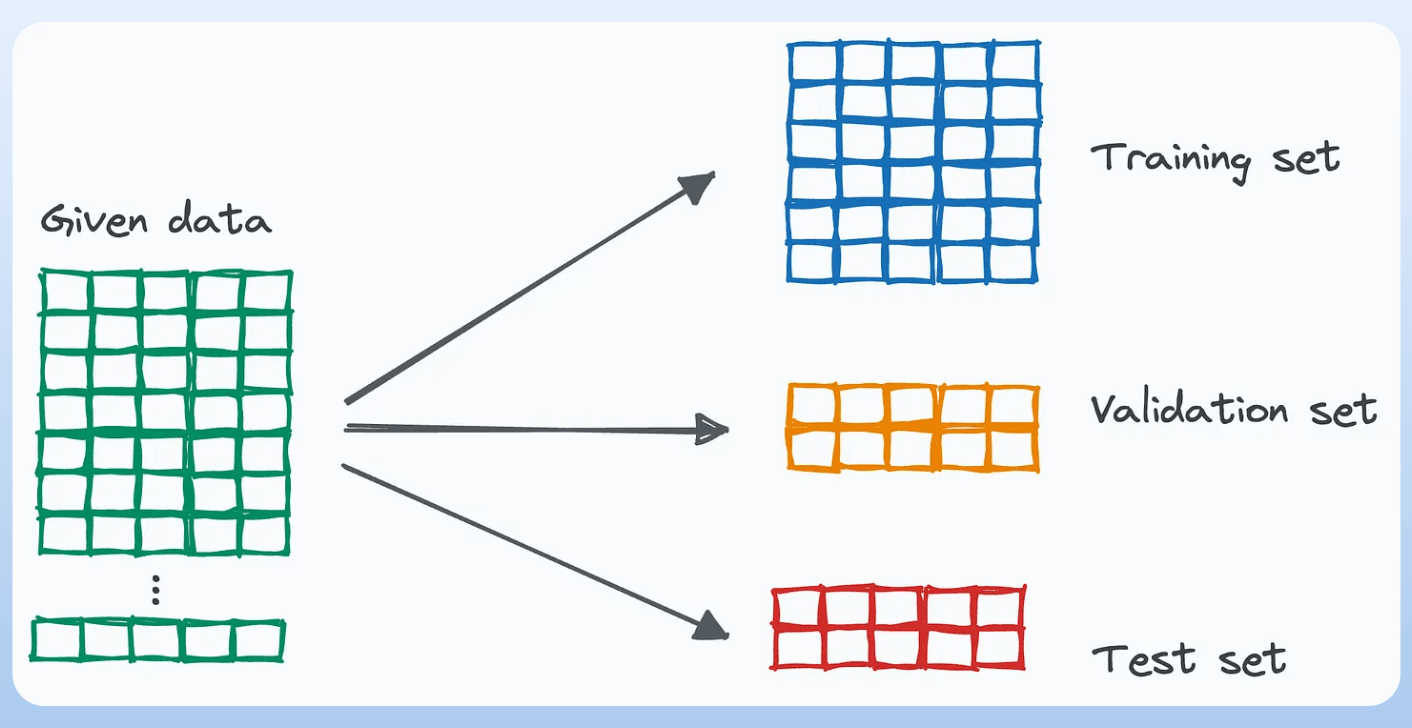
However, there are quite a few misconceptions about how they are meant to be used, especially the validation and test sets.
Today, let’s clear them up and see how to truly use train, validation, and test sets.
Let’s begin!
As we all know, we begin by splitting the data into:
Train
Validation
Test
At this point, just assume that the test data does not even exist. Forget about it instantly.

Begin with the train set. This is your whole world now.

You analyze it
You transform it
You use it to determine features
You fit a model on it
After modeling, you will measure the model’s performance on unseen data.
Bring in the validation set now.

Based on validation performance, improve the model.
Here’s how you iteratively build your model:

Train using a train set
Evaluate it using the validation set
Improve the model
Evaluate again using the validation set
Improve the model again
and so on.
Until...
You reach a point where you start overfitting the validation set.
This indicates that you have exploited (or polluted) the validation set.
No worries.
Merge it with the train set and generate a new split of train and validation.

Note: Rely on cross-validation if needed, especially when you don’t have much data. You may still use cross-validation if you have enough data. But it can be computationally intensive.
Now, if you are happy with the model’s performance, evaluate it on test data.
✅ What you use a test set for:
Get a final and unbiased review of the model.
❌ What you DON’T use a test set for:
Analysis, decision-making, etc.
If the model is underperforming on the test set, no problem.
Go back to the modeling stage and improve it.
BUT (and here’s what most people do wrong)!
They use the same test set again.
This is not allowed!
Think of it this way.
Your professor taught you in the classroom. All in-class lessons and examples are the train set.
The professor gave you take-home assignments, which acted like validation sets.
You got some wrong and some right.
Based on this, you adjusted your topic fundamentals, i.e., improved the model.
Now, if you keep solving the same take-home assignment repeatedly, you will eventually overfit it.
That is why we bring in a new validation set after some iterations.
The final exam day paper is your test set.
If you do well, awesome!
But if you fail, the professor cannot give you the exact exam paper next time, can they? This is because you know what’s inside.
Of course, by evaluating a model on the test set, the model never gets to “know” the precise examples inside that set.
But the issue is that the test set has been exposed now.
Your previous evaluation will influence any further evaluations on that specific test set.
That is why you must always use a specific test set only ONCE.
Once you do, merge it with the train and validation set and generate an entirely new split.
Repeat.
And that is how you use train, validation, and test sets in machine learning.
Hope that helped!
You can learn about 8 more fatal (and non-obvious) pitfalls here: 8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science.
👉 Over to you: While this may sound simple, there are quite a few things to care about, like avoiding data leakage. What are some other things that come to your mind?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn how to build Agentic systems in an ongoing crash course with 11 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.