
How to Actually Use Train, Validation, and Test Sets in ML
...explained visually!

What are RL environments, and how to build them
The real bottleneck in building AI agents that need to reason across multiple steps isn’t the training algorithm.
It’s the environment your agent trains in.
This is because training algorithms like GRPO or PPO are essentially optimizers. They take a reward signal and update model weights to maximize it.
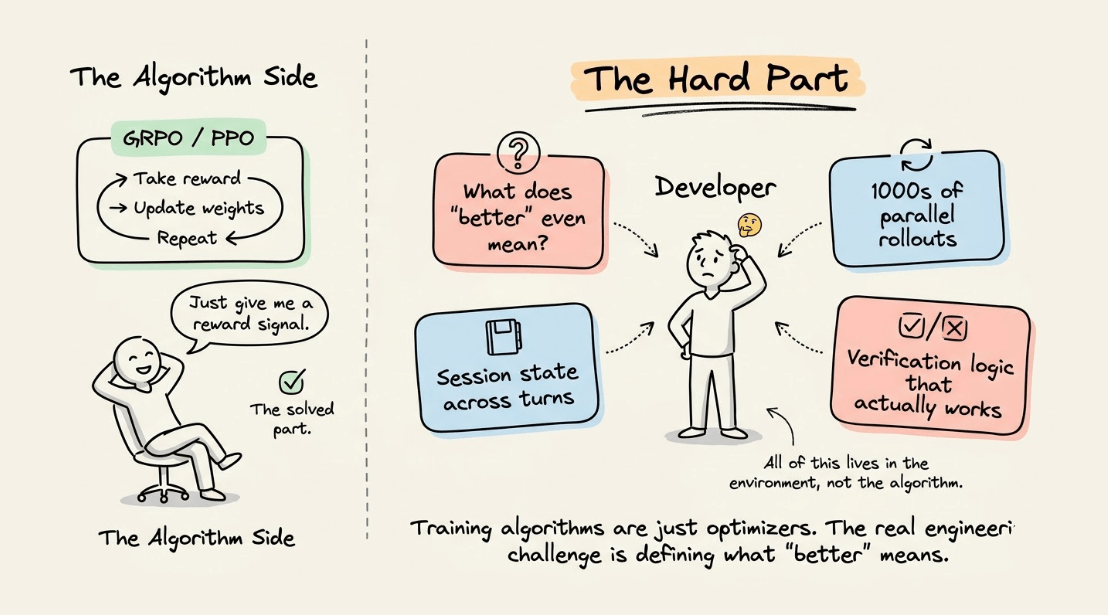
The hard part is everything that comes before that, like defining what "better" actually means for your agent, building the infrastructure to generate thousands of parallel rollouts, managing isolated session state across multi-turn interactions, and designing verification logic that reliably scores agent behavior.
And unlike single-turn fine-tuning, where you just need input-output pairs, agentic RL requires your environment to handle tool calls, maintain state across steps, spin up sandboxed execution contexts, and clean up resources after every rollout.
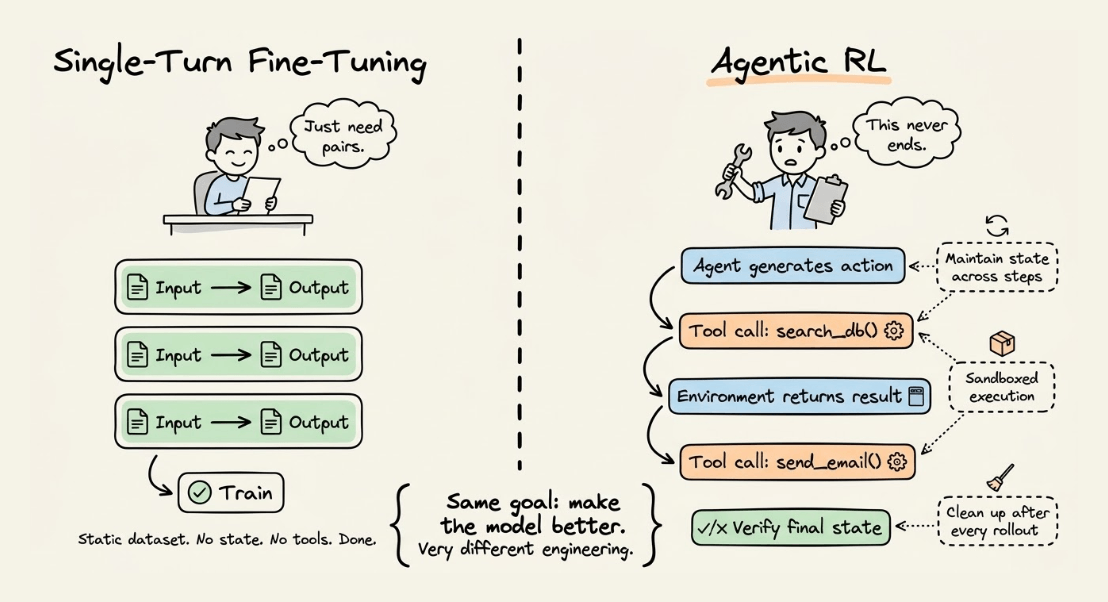
Most RL workflows today tightly couple this logic into the training pipeline, which makes it painful to iterate on environment design without touching the optimizer code. That tight coupling is exactly what slows teams down.
Unsloth and NVIDIA have published a deep dive on building RL environments for agentic AI.
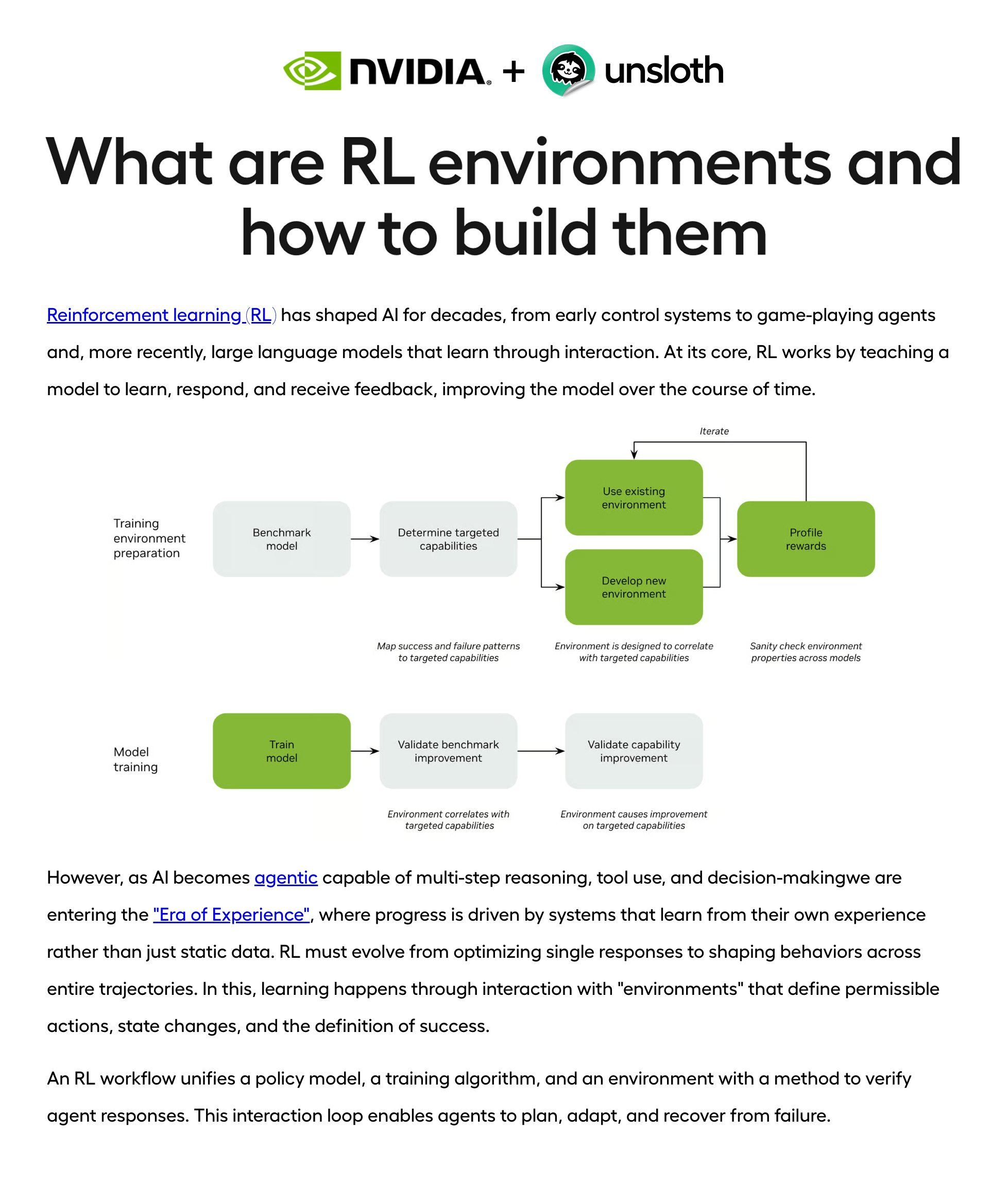
The post covers how NVIDIA NeMo Gym lets you decouple environment logic from training, so you can design verifiable reward signals independently of your optimizer.
It also walks through the full stack of building an environment, including agent servers for orchestrating rollouts, resource servers for maintaining session state, and verification logic for computing rewards.
Unsloth plugs in as the training backend, consuming rollout trajectories and running GRPO to update model weights efficiently.
How to actually use train, validation, and test sets
It is conventional to split the available data into train, test, and validation sets.
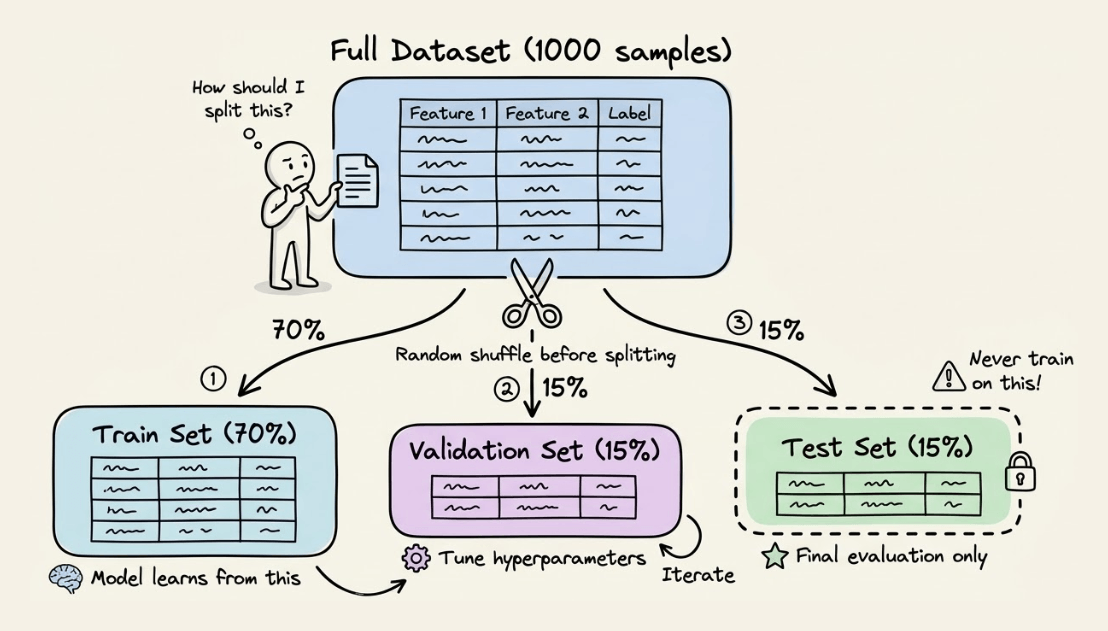
However, there are quite a few misconceptions about how they are meant to be used, especially the validation and test sets.
Today, let’s clear them up and see how to truly use train, validation, and test sets.
Let’s begin!
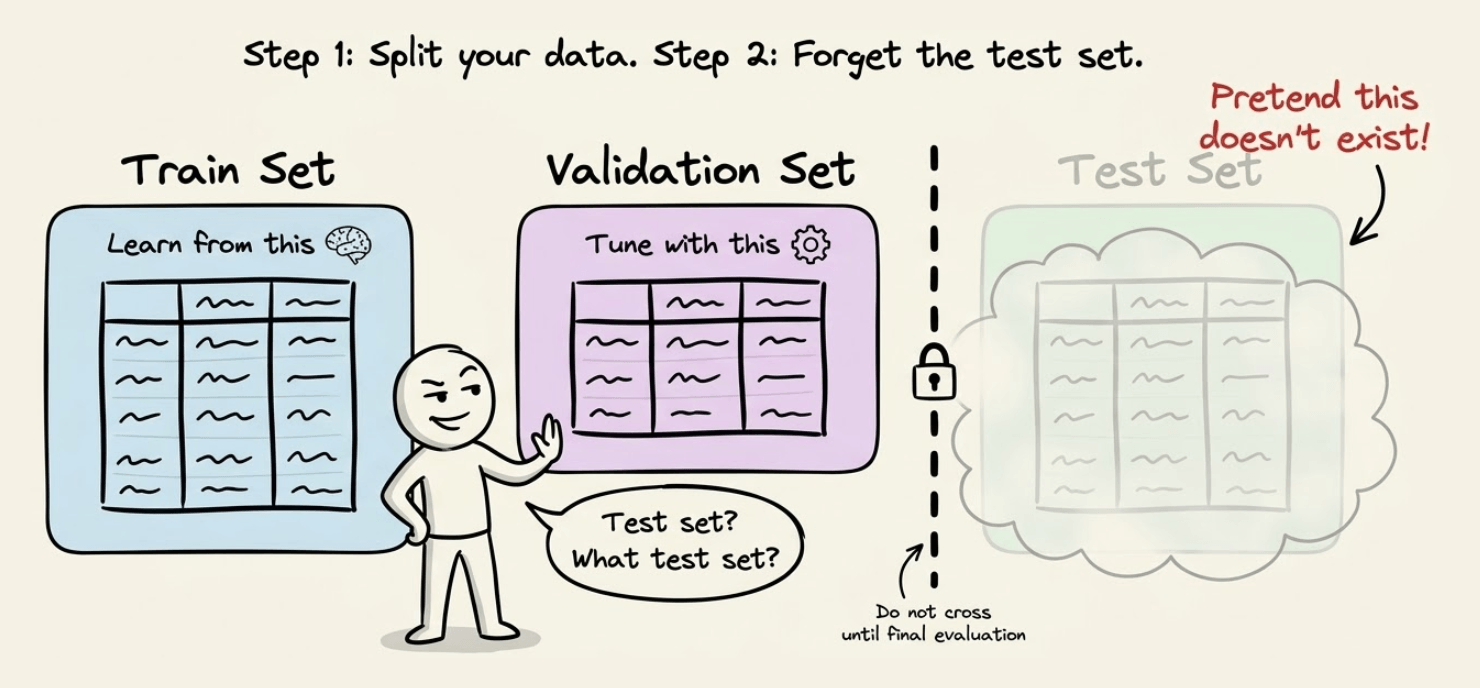
The standard split
As we all know, we begin by splitting the data into:
Train
Validation
Test
At this point, just assume that the test data does not even exist. Forget about it instantly.
Begin with the train set. This is your whole world now.
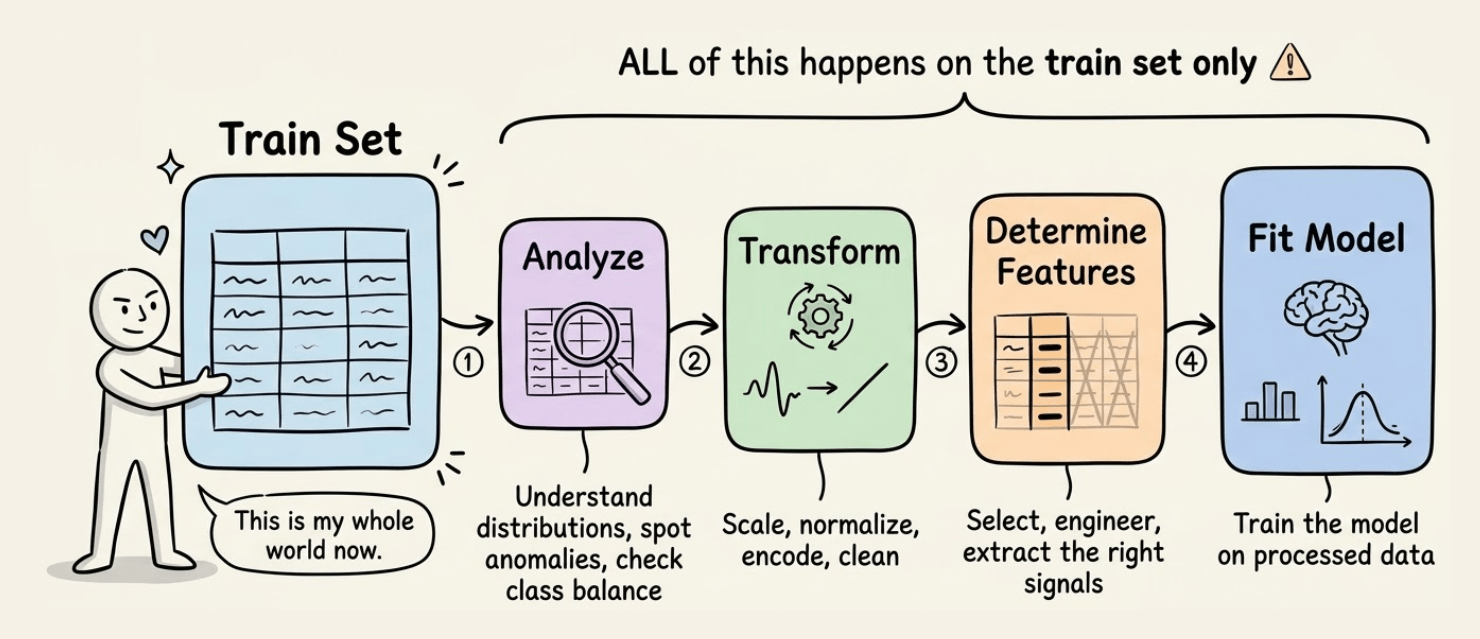
You analyze it
You transform it
You use it to determine features
You fit a model on it
After modeling, you will measure the model’s performance on unseen data.
Bring in the validation set now.
Based on validation performance, improve the model.
Here’s how you iteratively build your model:
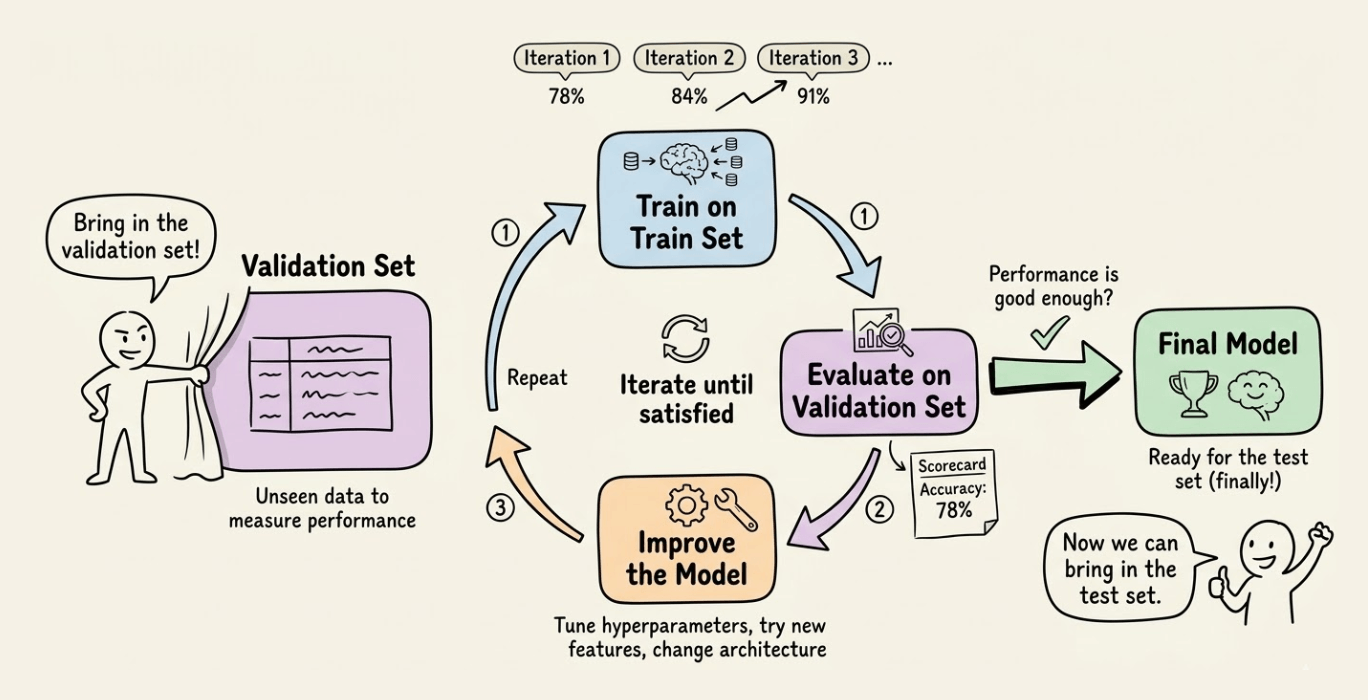
Train using a train set
Evaluate it using the validation set
Improve the model
Evaluate again using the validation set
Improve the model again
and so on.
Until you are satisfied with the model’s performance.
The validation overfitting problem
Here’s something critical that many practitioners miss:
If you repeatedly tune your model based on validation performance over many iterations, you risk indirectly overfitting to the validation set.
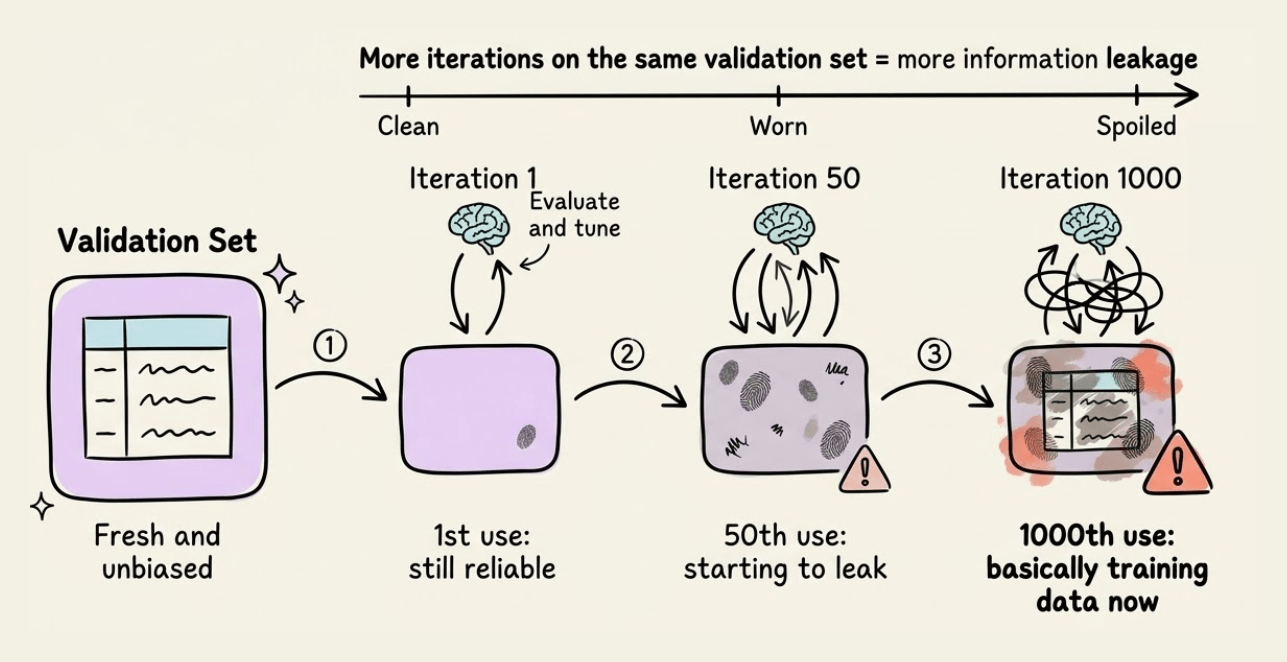
This is because every decision you make based on validation performance leaks information from that set into your model selection process.
Think of it this way: If you try 1000 different model configurations and pick the one with the best validation score, you’ve essentially used the validation set as part of your training process.
The solution: Cross-validation
Instead of relying on a single train-validation split, use k-fold cross-validation.
Here’s how it works:
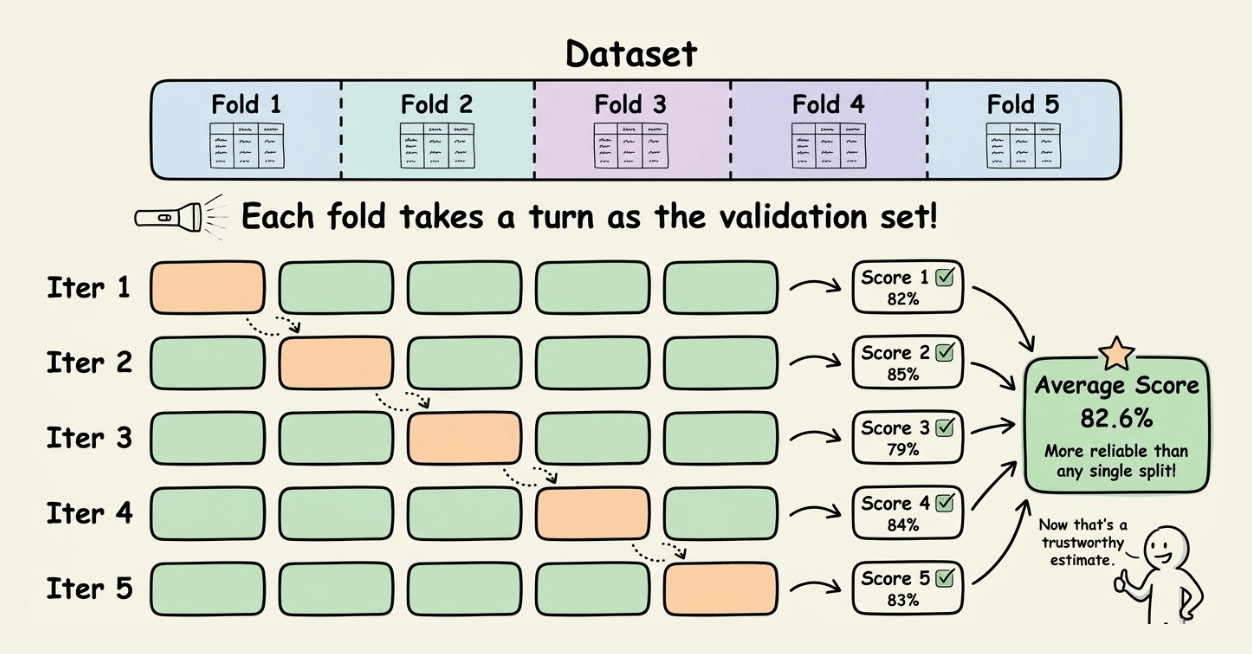
Split your data into k folds (commonly k=5 or k=10).
For each fold, use (k-1) folds for training and use the remaining fold for validation.
Average the performance across all folds.
This gives you a more robust estimate of model performance because:
Every data point gets used for both training and validation
You reduce the variance that comes from a single random split
You get a better sense of how your model generalizes
When to use cross-validation:
When you don’t have much data (highly recommended)
When you want robust performance estimates
When you’re comparing multiple models or hyperparameter configurations
Trade-off: Cross-validation is computationally more expensive since you train k models instead of one.
For rigorous hyperparameter tuning: Nested Cross-Validation
If you’re doing extensive hyperparameter tuning, consider nested cross-validation.
This involves two loops:
Outer loop: Evaluates the overall modeling approach
Inner loop: Tunes hyperparameters
This prevents the hyperparameter tuning process from biasing your performance estimates.

Yes, it’s computationally intensive. But it’s the gold standard when you need unbiased performance estimates.
The test set
Now, if you are happy with the model’s performance on validation (or cross-validation), there’s one more step before final evaluation.
Retrain on all available training data.
Once you’ve selected your best model and hyperparameters via cross-validation, retrain it on the combined train + validation data. This gives your final model more data to learn from before the ultimate test.
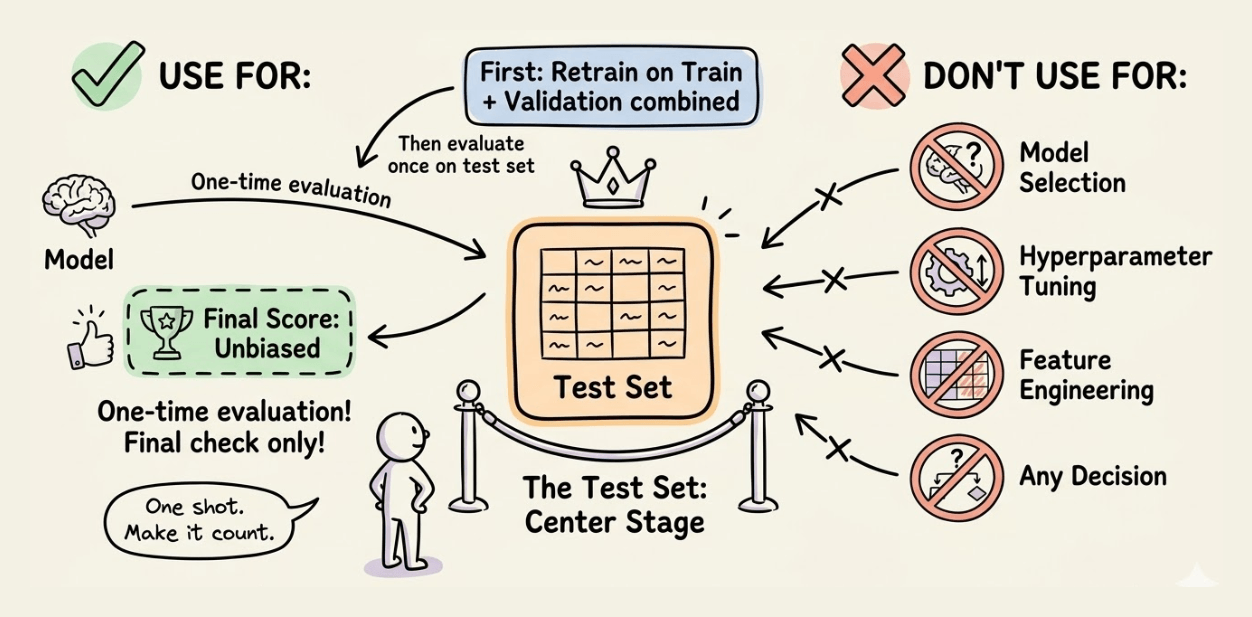
Now, evaluate it on test data.
✅ What you use a test set for:
Get a final and unbiased estimate of the model’s real-world performance
❌ What you DON’T use a test set for:
Model selection
Hyperparameter tuning
Feature engineering decisions
Any decision that influences the model
The classroom analogy
Let’s make this concrete with an analogy.
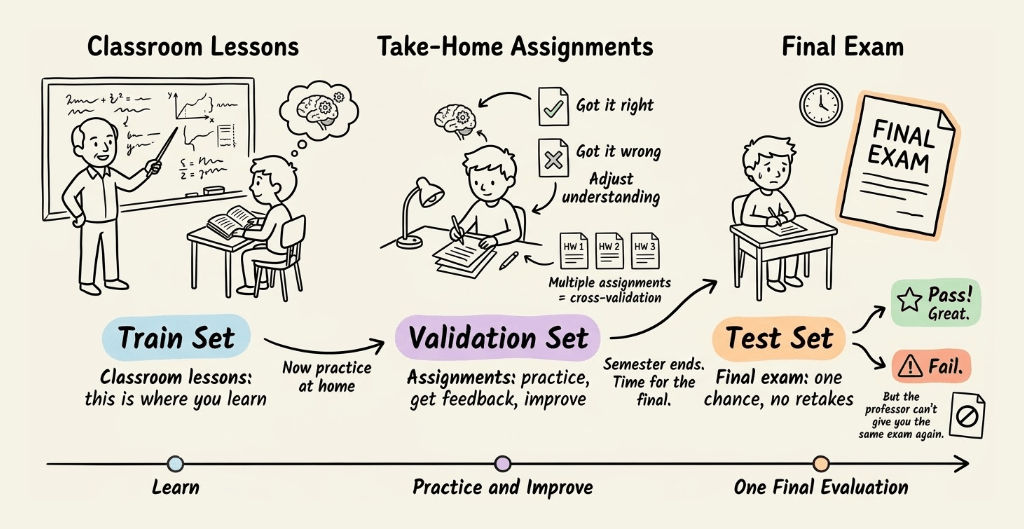
Your professor taught you in the classroom. All in-class lessons and examples are the train set.
The professor gave you take-home assignments, which acted like validation sets.
You got some wrong and some right. Based on this, you adjusted your understanding, i.e., improved the model.
Cross-validation is like having multiple different take-home assignments throughout the semester, giving you a better sense of your true understanding.
The final exam is your test set.
If you do well, great!
But if you fail, the professor cannot give you the exact same exam paper next time because your previous evaluation will influence any further evaluations on that specific test set.
What happens if the model fails on test?
If the model is underperforming on the test set, you have a few options:
Option 1: Go back and improve (but be careful)
You can iterate further, but understand that your test set has now been “exposed.” Any improvements you make with knowledge of test performance technically biases your evaluation.
Option 2: Use a held-out test set from production data
In practice, many teams keep a completely separate holdout that only gets evaluated at major milestones (like before deployment).
Option 3: Rely on cross-validation estimates
If your cross-validation estimates were solid and the test set tells a different story, investigate why. It could indicate:
Distribution shift between train/test
Data leakage somewhere in your pipeline
The test set being unrepresentative
Important considerations often missed
Here are some important considerations that practitioners often miss that are specific to certain data situations.
1) Temporal/Time-Series data: Never use random splits
If your data has a time component, random splits cause data leakage.
Why? You might train on future data and validate on past data, which is unrealistic.
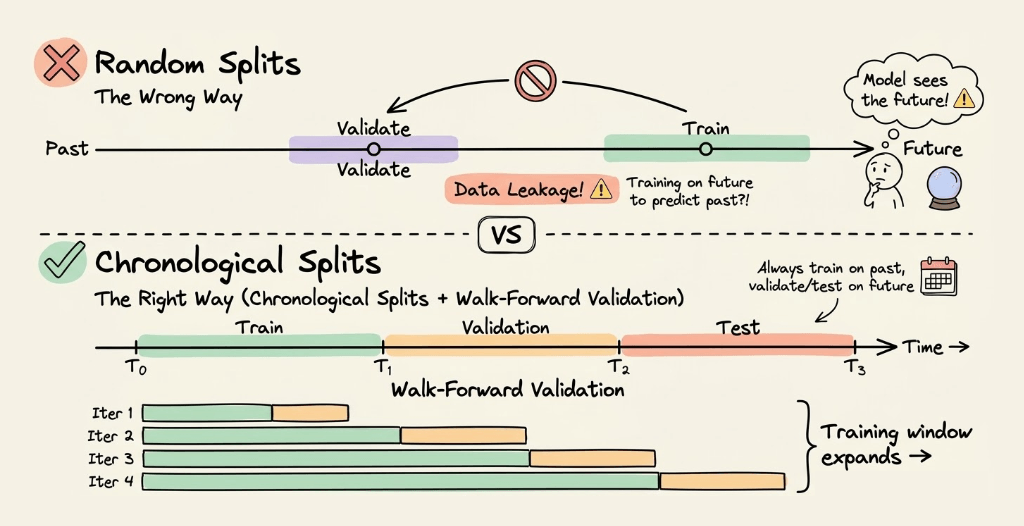
Solution: Use chronological splits.
Train on data from time T₀ to T₁
Validate on data from T₁ to T₂
Test on data from T₂ to T₃
For time series, use time-series cross-validation (also called walk-forward validation), where you progressively expand the training window.
2) Stratification for imbalanced data
If you have a class imbalance (e.g., 95% negative, 5% positive), random splits might give you validation/test sets with very different class distributions.
Solution: Use stratified splits that preserve the class distribution across train, validation, and test sets.

3) Data leakage during preprocessing
This is one of the most common and subtle mistakes.
Wrong approach:

Why it’s wrong: The scaler learned statistics (mean, std) from the test data, leaking information.
Correct approach:

This applies to:
Scaling/normalization
Encoding categorical variables
Imputing missing values
Feature selection
Any transformation that learns from data
4) Group-based splits
If your data has natural groups (e.g., multiple samples from the same patient, multiple transactions from the same user), ensure all samples from one group stay together.
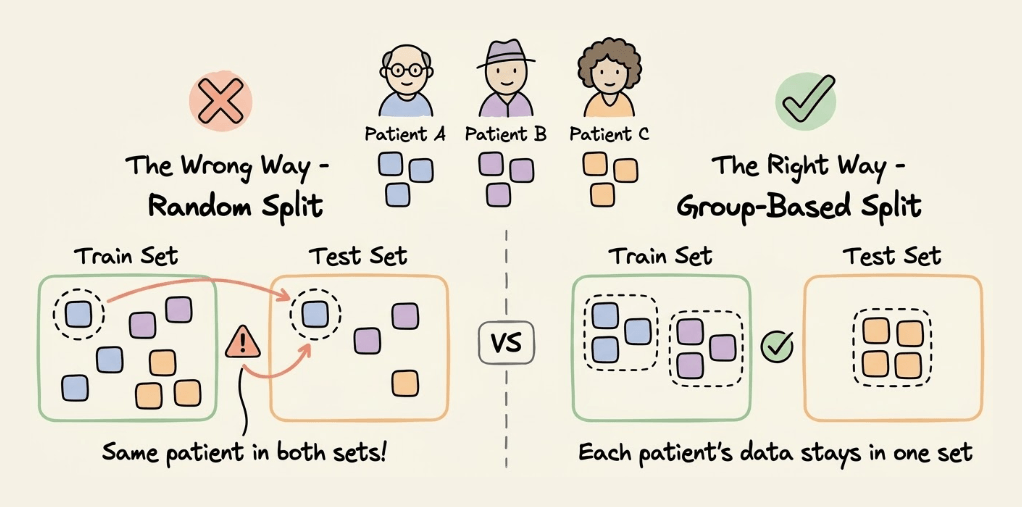
Why? If one patient’s data is in both the train and test, the model might just memorize patient-specific patterns rather than learning generalizable features.
Solution: Use GroupKFold or GroupShuffleSplit from scikit-learn.
A note on fixed test sets (Benchmarks)
In academic ML and standardized benchmarks (ImageNet, GLUE, etc.), the test set is fixed and used by everyone.
This is fine because:
The test set represents a standard evaluation criterion.
You’re not iteratively improving based on test performance.
The goal is comparability across methods.
The key principle remains: the test set should not influence your modeling decisions.
Best practices:
Use cross-validation instead of a single validation split when possible
Use nested cross-validation for rigorous hyperparameter tuning
Never let test set performance influence modeling decisions
Use appropriate splitting strategies (temporal, stratified, grouped) based on your data
Fit all preprocessors only on the training data
And that is how you properly use train, validation, and test sets in machine learning.
Further reading:
👉 Over to you: What other data splitting mistakes have you encountered in practice? Drop your experiences in replies.
Thanks for reading!