Imagine you have an ordinal categorical feature. You want to measure its correlation with other continuous features.
Ordinal feature: Categorical data with a natural ordering in categories
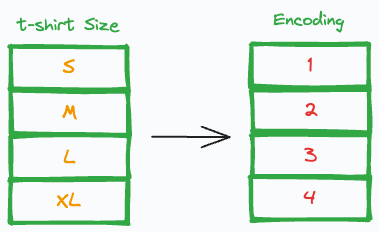
Before proceeding with the correlation analysis, you will encode the feature, which is a fair thing to do.
Encoding ordinal data
Yet, unknown to many, the choice of encoding can largely affect the correlation results.
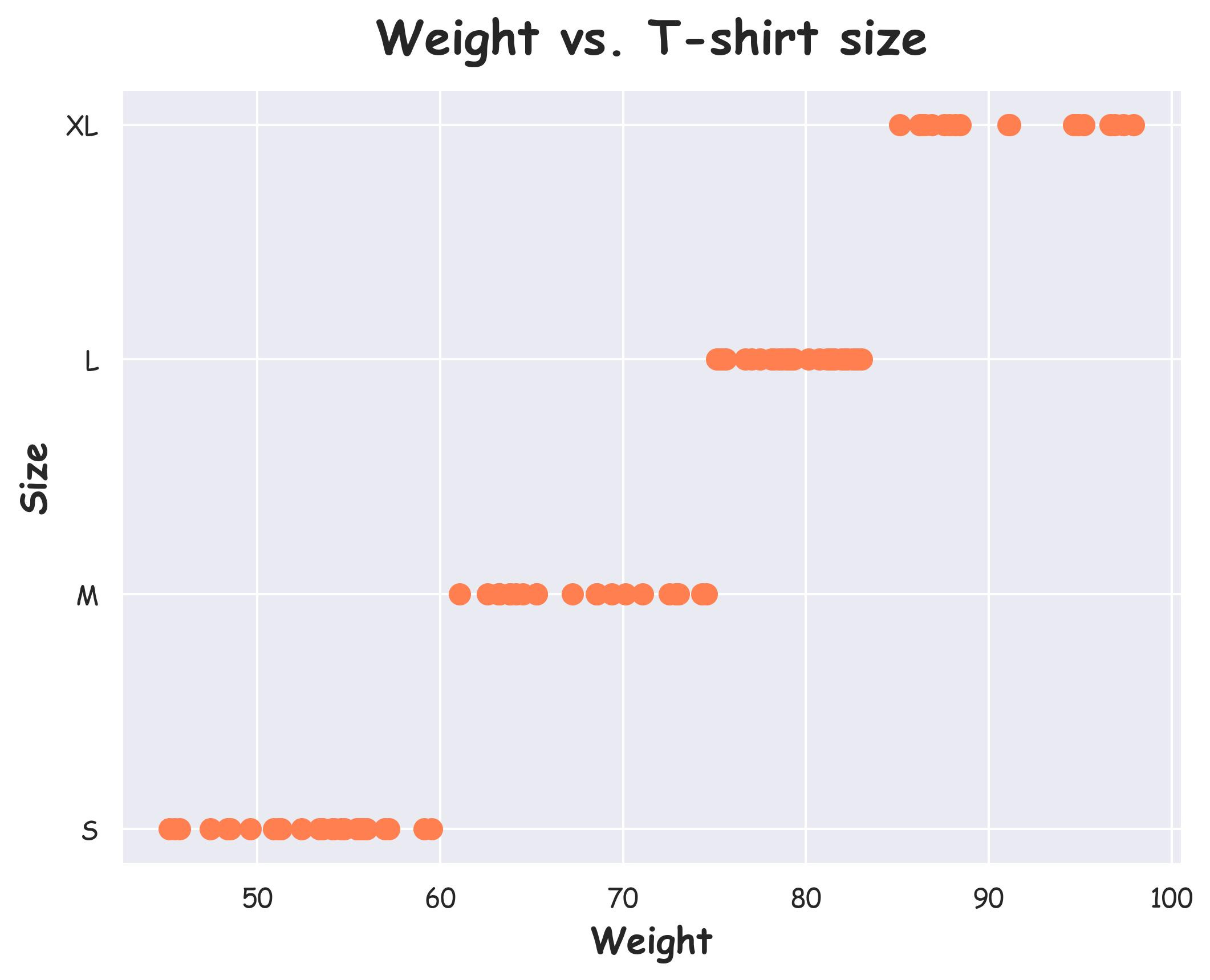
For instance, consider the dataset below:
Weight vs. t-shirt size data
Here, we have:
An ordinal categorical feature: t-shirt size (S, M, L, XL).
A continuous feature: weight.
If we look at it graphically, there does exist a monotonic relationship between the two features.
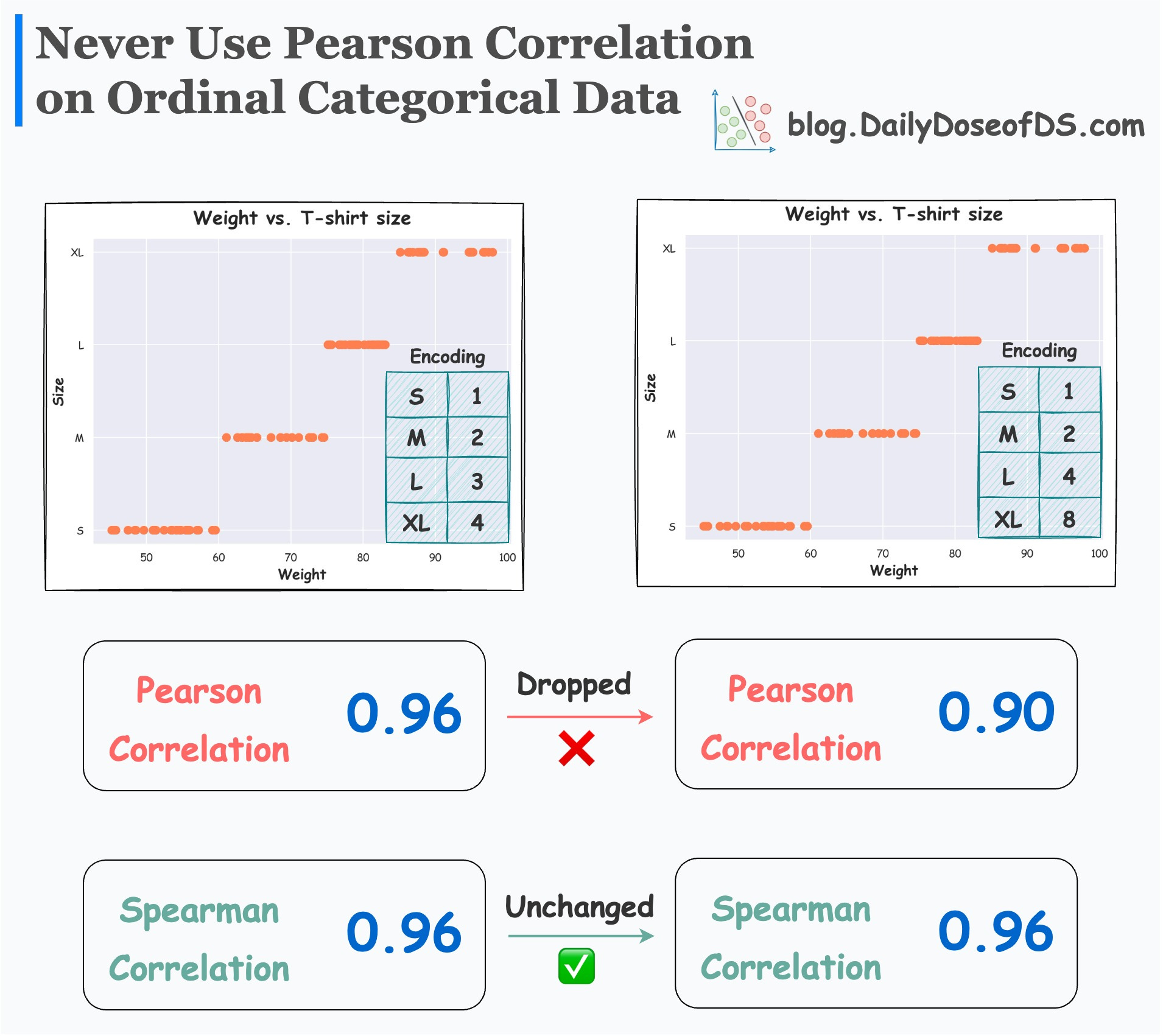
However, as depicted below, altering the categorical encoding affects the Pearson correlation.
In the left plot, we have the following encoding → S(1), M(2), L(3) and XL(4).
In the right plot, we have the following encoding → S(1), M(2), L(4) and XL(8).
It is clear that the Spearman correlation is a better alternative to assess the monotonicity between ordinal and continuous features.
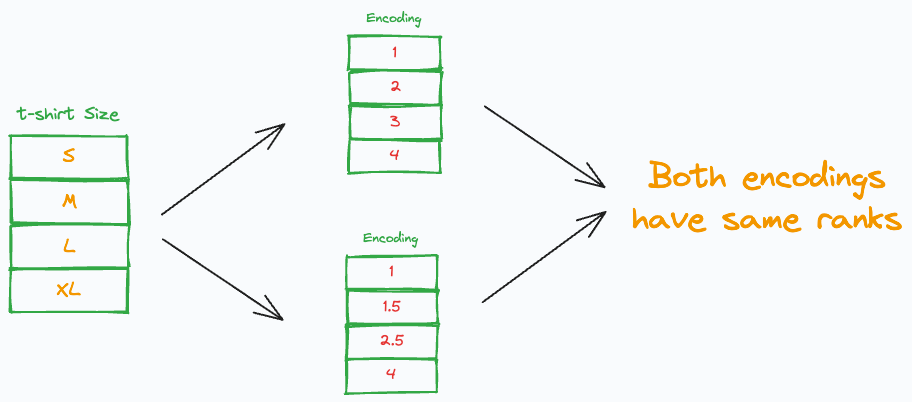
It always remains the same, irrespective of the choice of categorical encoding. This is because the Spearman correlation is rank-based.
Different ordinal encodings result in the same Spearman correlation
It operates on the ranks of the data, which makes it more suitable for such cases of correlation analysis.
Using Spearman correlation is pretty simple as well. For instance, if you are using Pandas, just specify the desired correlation measure as follows:
👉 Over to you: What are some other measures to determine the correlation between categorical data and continuous data?
Thanks for reading Daily Dose of Data Science! Subscribe for free to learn something new and insightful about Python and Data Science every day. Also, get a Free Data Science PDF (550+ pages) with 320+ tips.
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.
The button is located towards the bottom of this email.
Thanks for reading!
Whenever you are ready, here’s one more way I can help you:
Every week, I publish 1-2 in-depth deep dives (typically 20+ mins long). Here are some of the latest ones that you will surely like: