
How to build a RAG app on AWS!
...explained step-by-step with visual.

GPT-5.1 is now available in Factory Droid!
GPT-5.1 is designed for active collaboration. Great for brainstorming, planning, writing, quick architectural decisions, and pair-programming when you want a model actively in the loop.
GPT-5.1-Codex excels at long-running agentic coding tasks, broad edits, migrations, and PR level changes.
Both models perform well on adaptive reasoning and code quality, and are now available with a free trial of Factory (the frontier software development agent).
Start building with Factory here →
Thanks to Factory for partnering today!
How to build a RAG app on AWS!
The visual below shows the exact flow of how a simple RAG system works inside AWS, using services you already know.
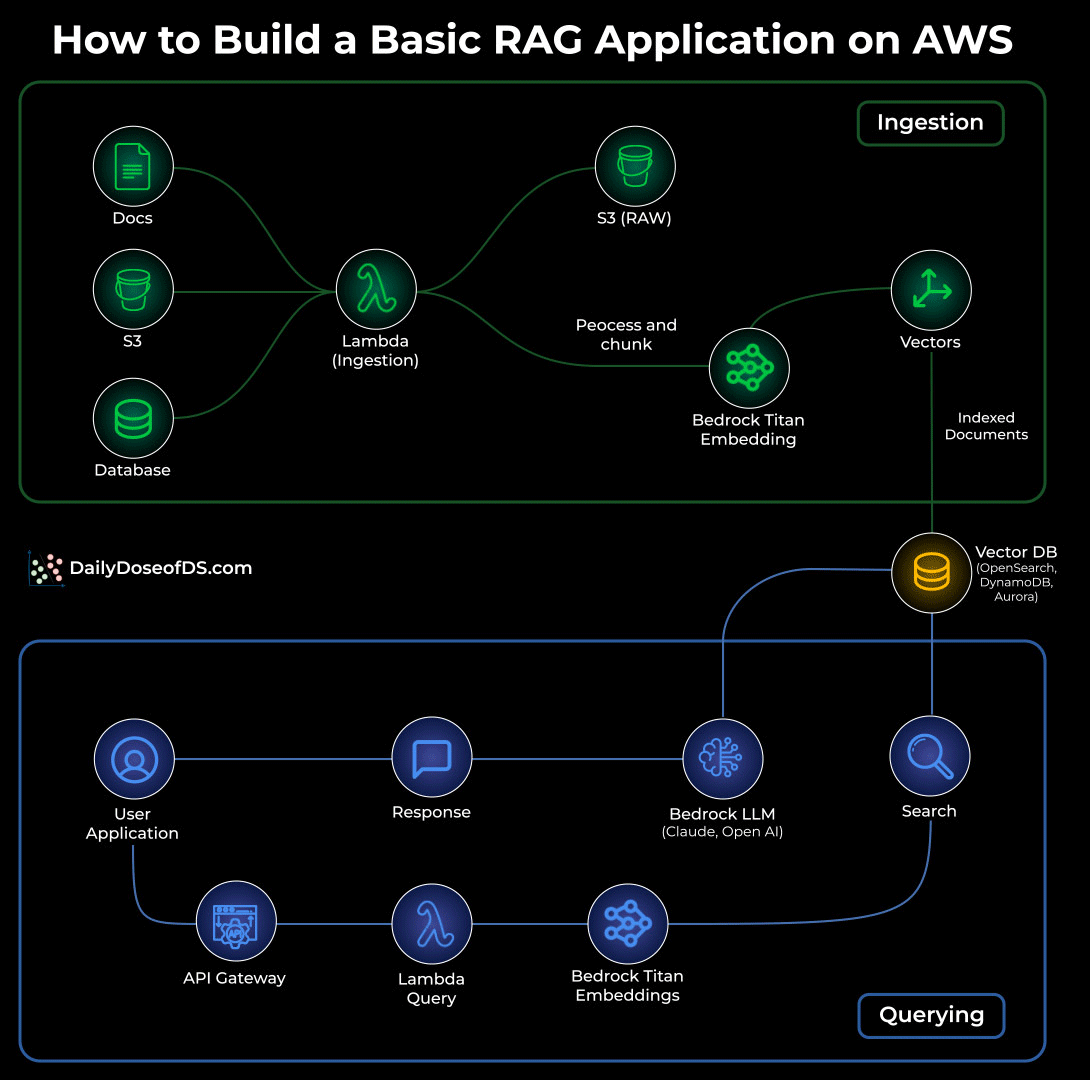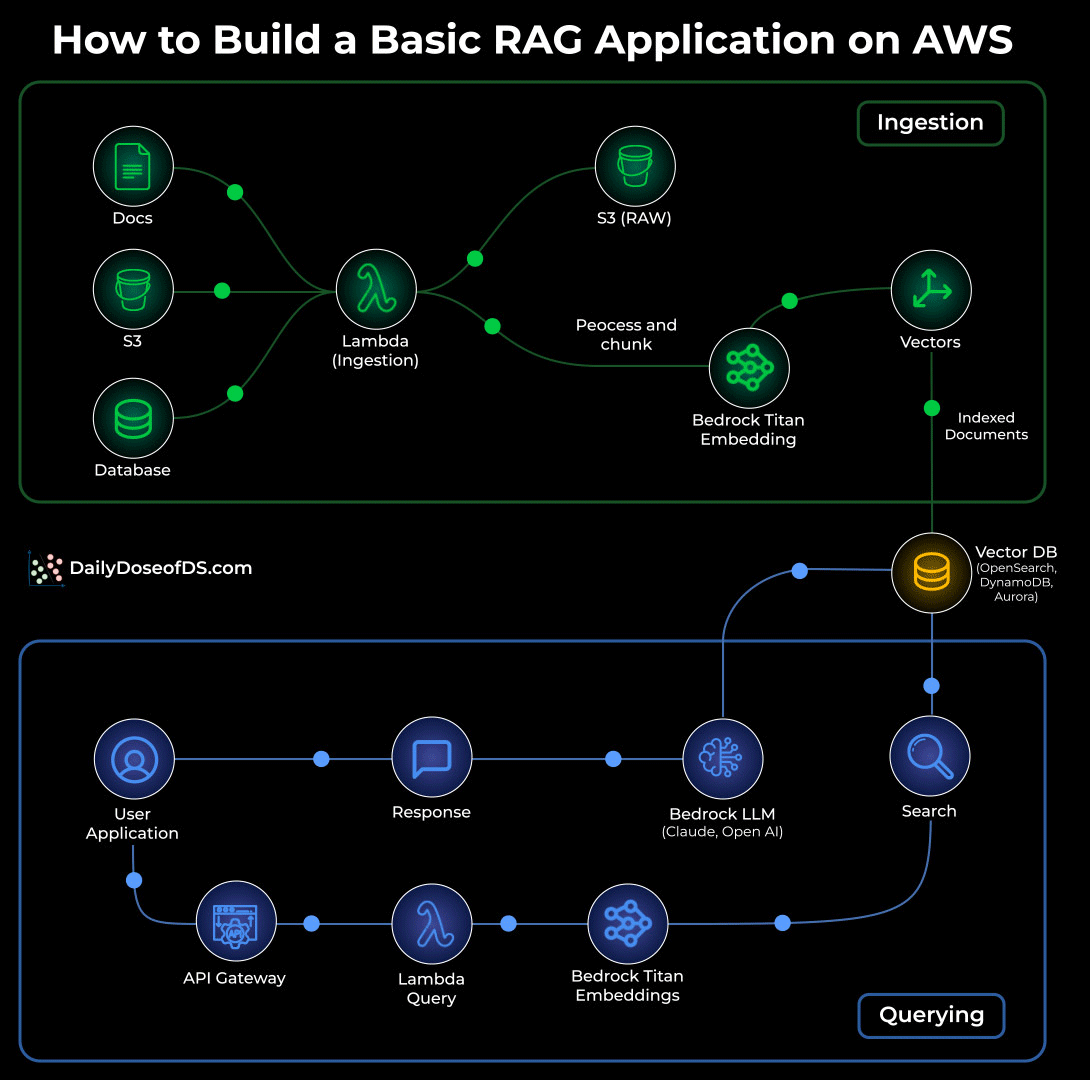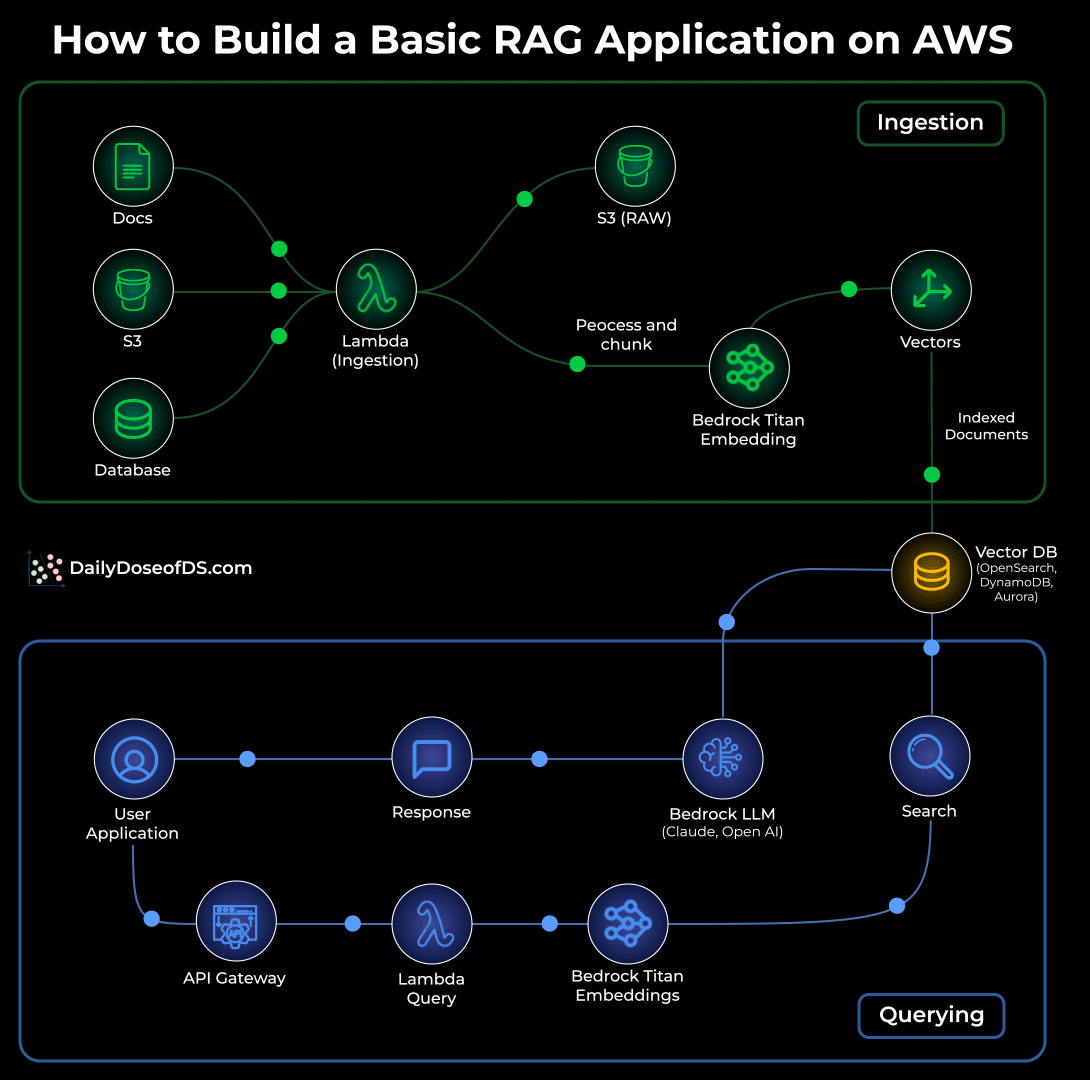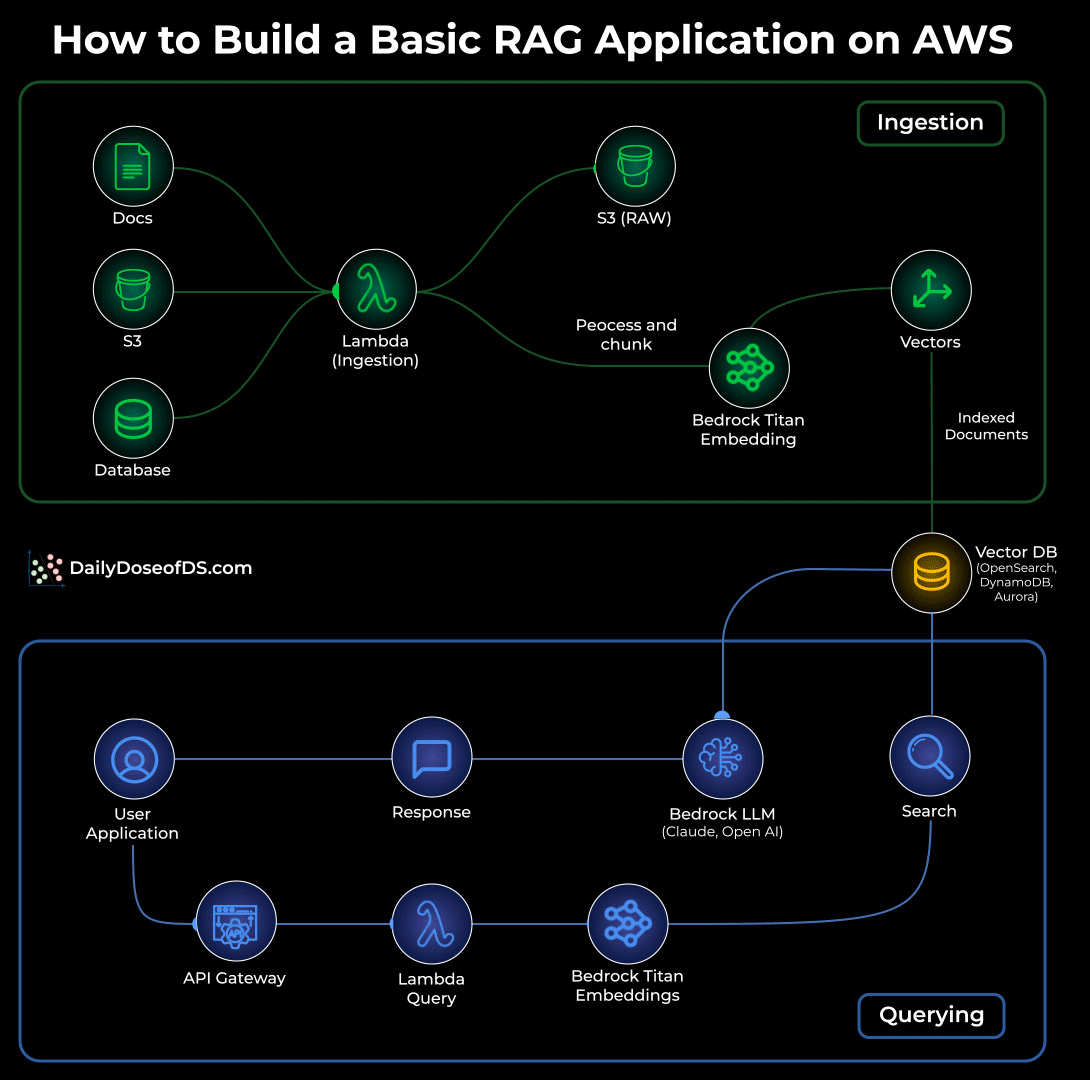
At its core, RAG is a two-stage pattern:
Ingestion (prepare knowledge)
Querying (use knowledge)
Below is how each stage works in practice.
Ingestion: Turning raw data into searchable knowledge
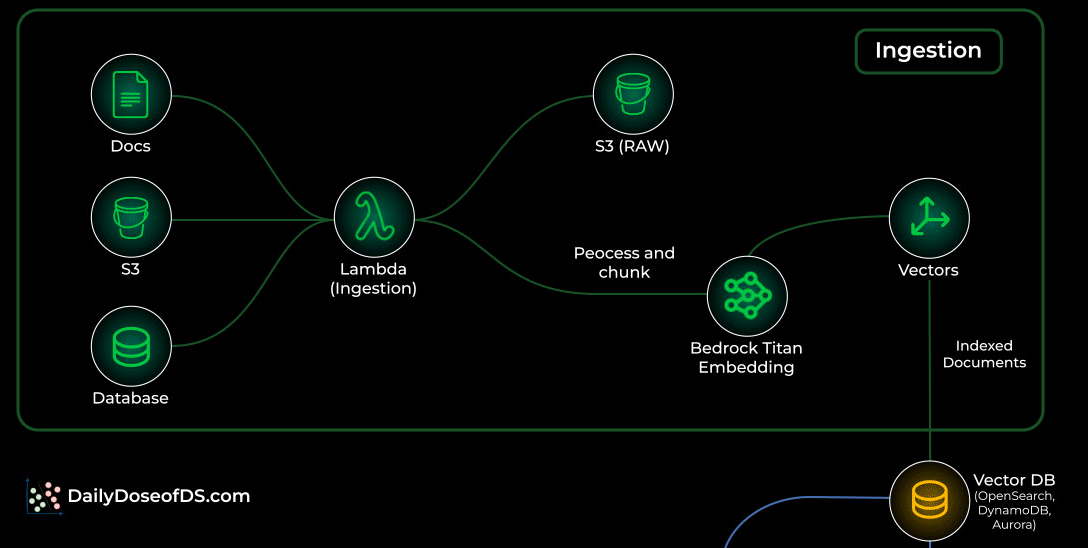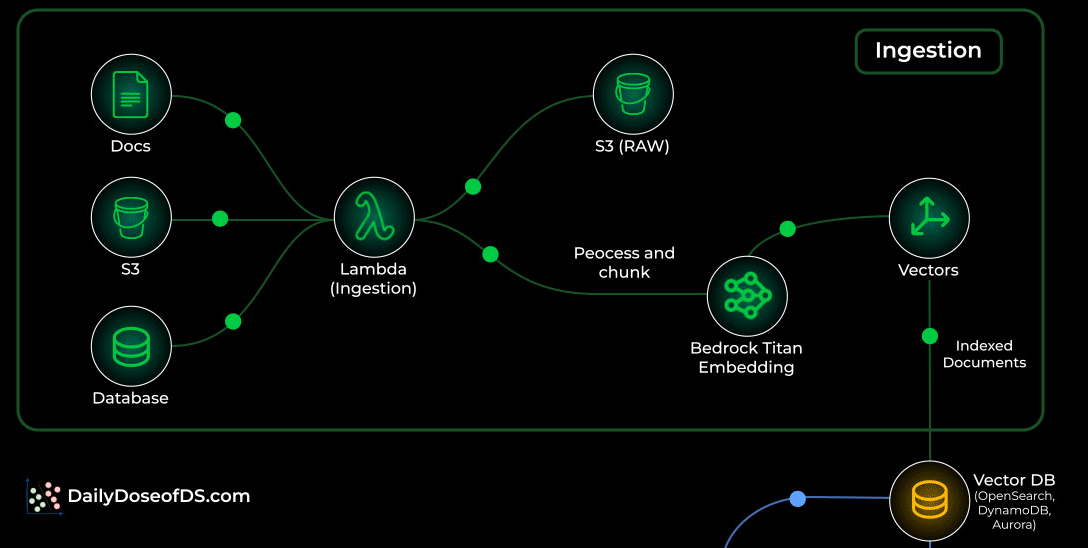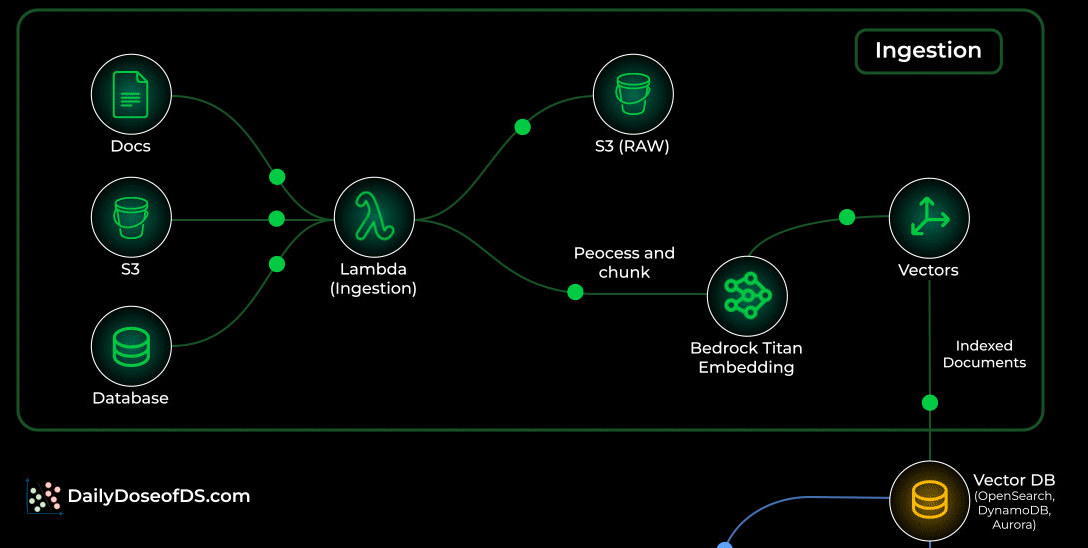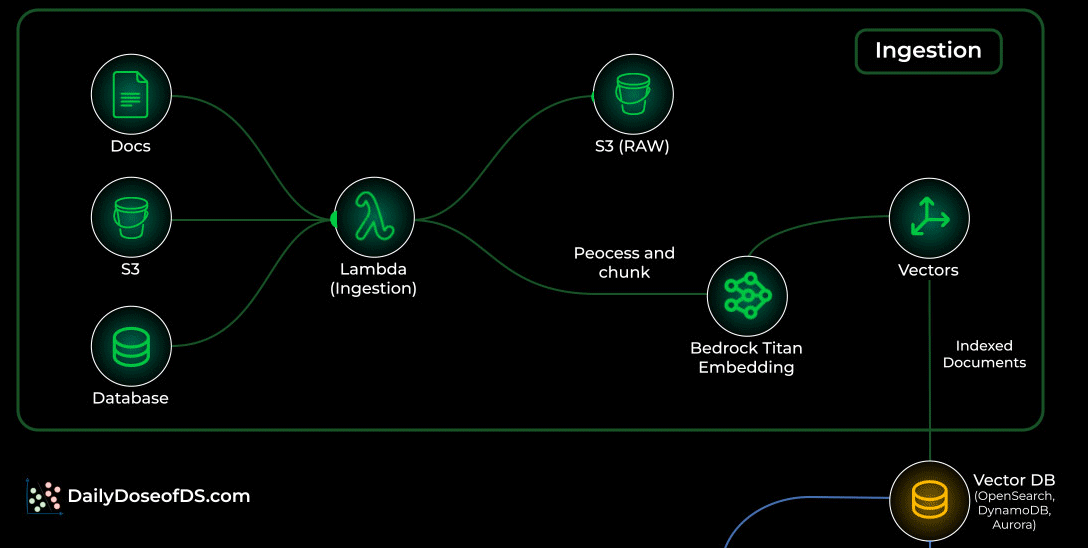
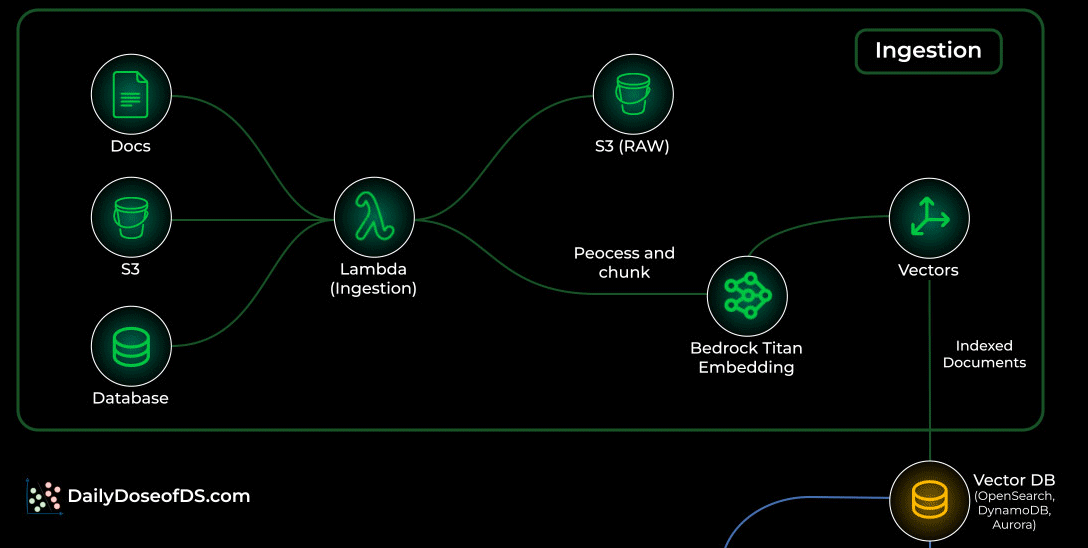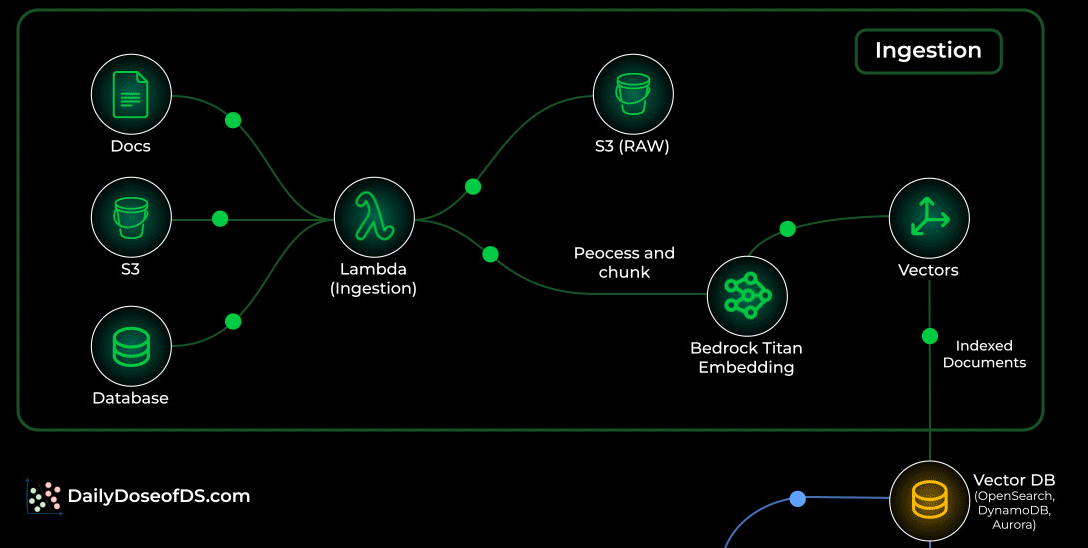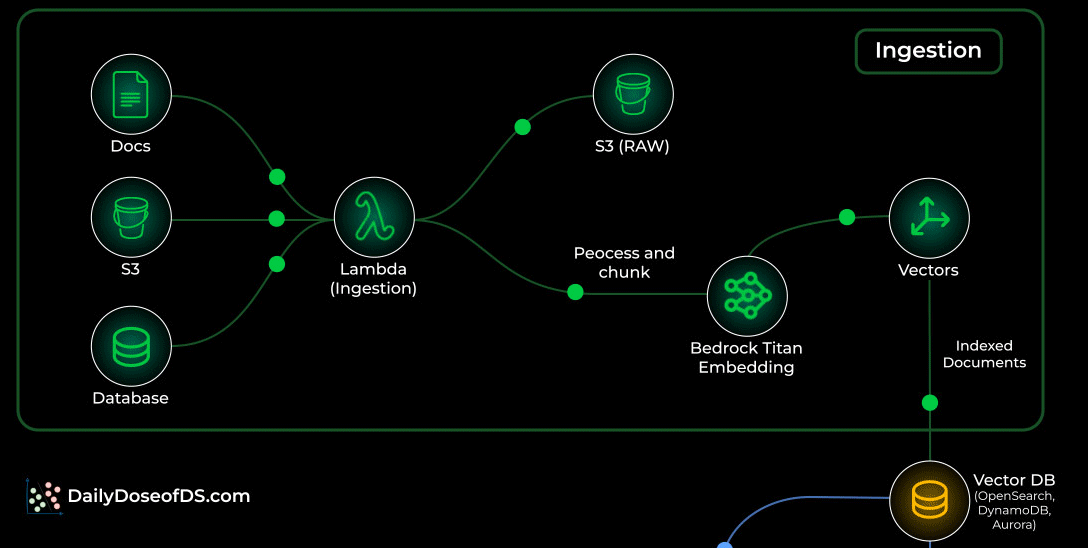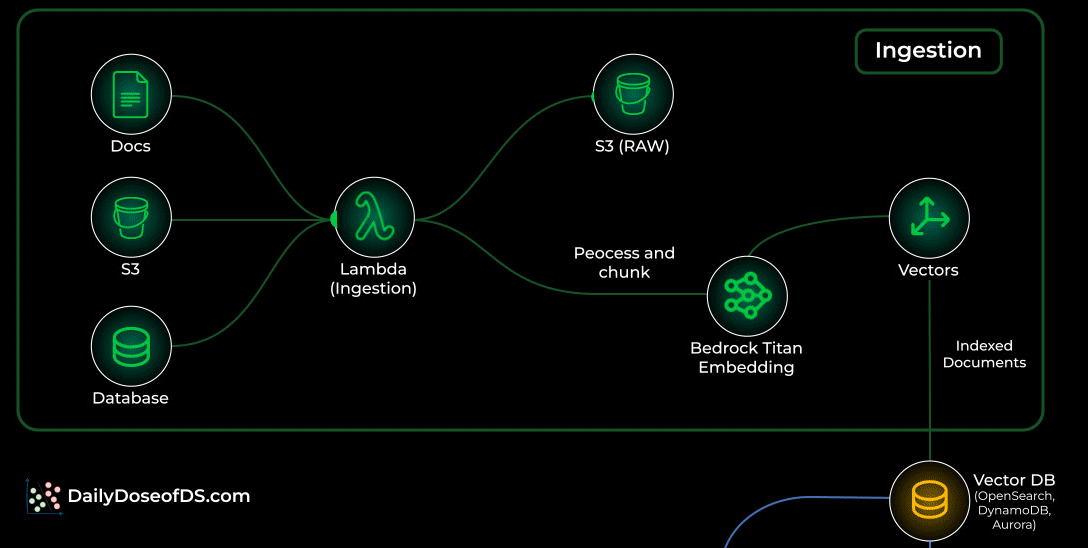
Your documents live in S3 or any internal data source.
Whenever something new is added, a Lambda ingestion function kicks in.
It cleans, processes, and chunks the file into smaller units that the model can understand.
Each chunk is embedded using Bedrock Titan Embeddings.
The embeddings are stored in a vector database like OpenSearch Serverless, DynamoDB, or Aurora.
This becomes your searchable knowledge store.
This stage can run continuously in the background, keeping your knowledge fresh.
That said, you need to be strategic about how you reindex your data.
For instance, if you are fetching data from a document and only one character was updated in it, you don’t want to reprocess the entire document every time.
So smart diffing, incremental updates, and metadata checks become important to avoid unnecessary cost and keep ingestion efficient.
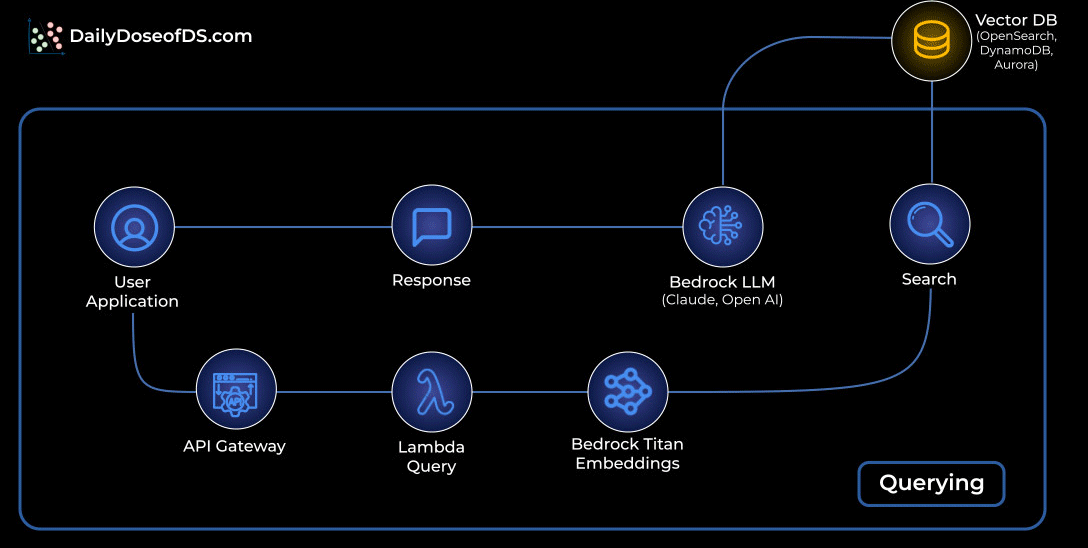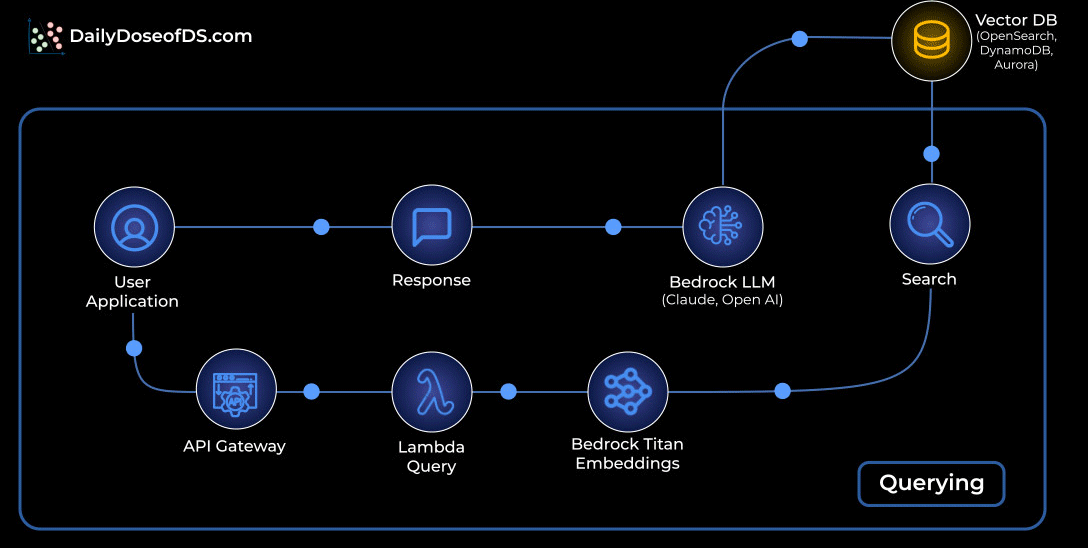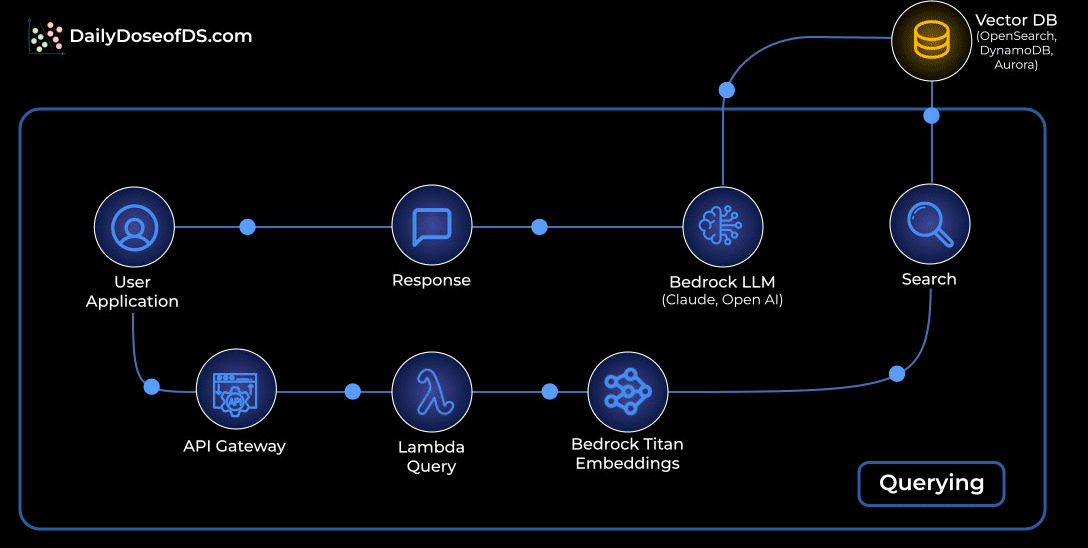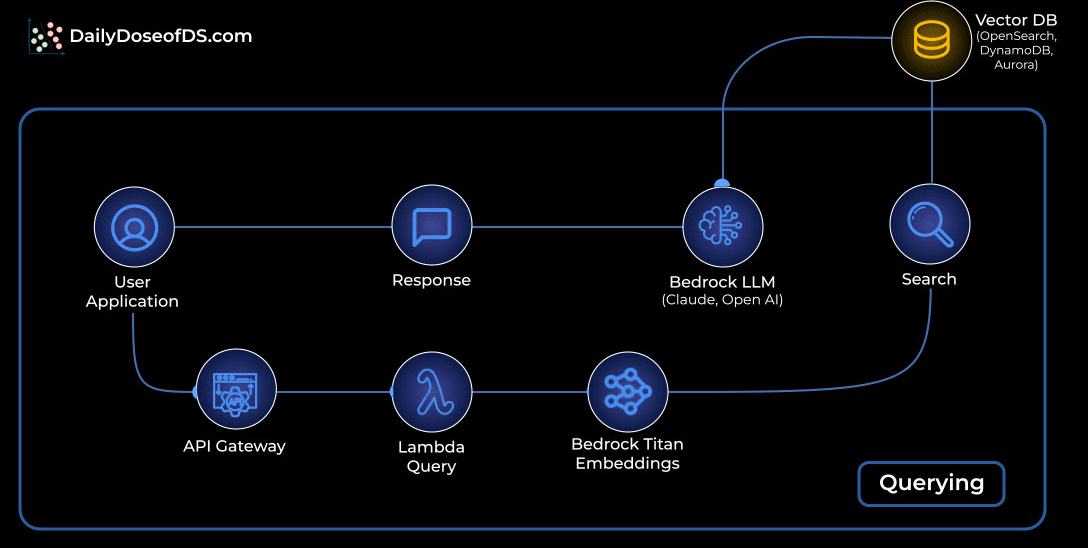
Querying: Retrieving and generating answers:
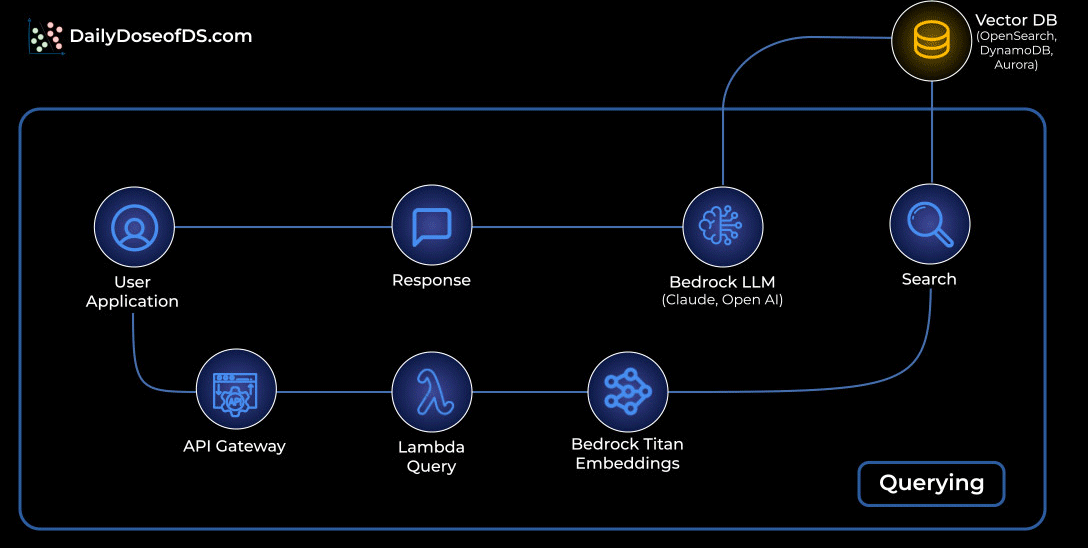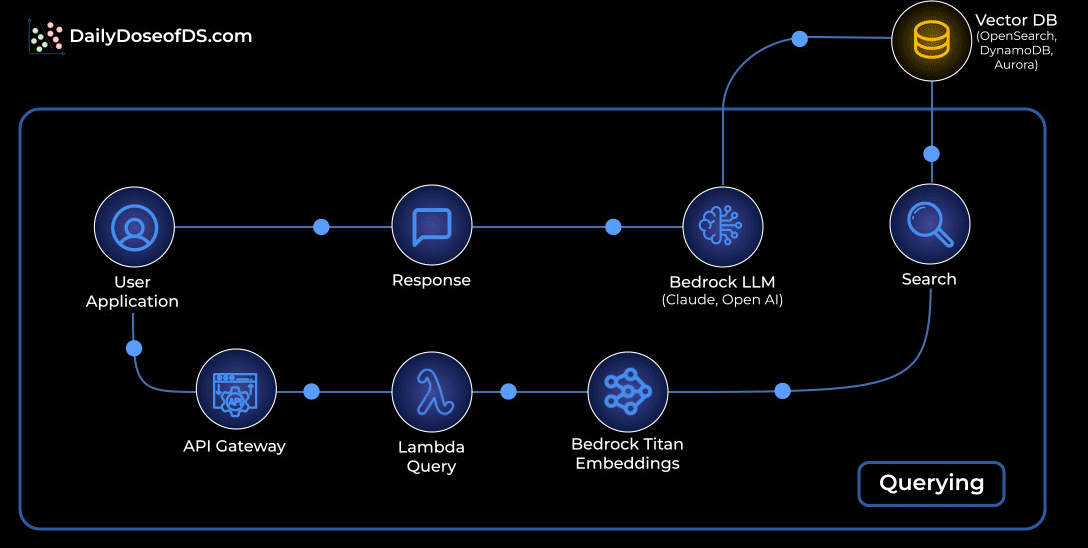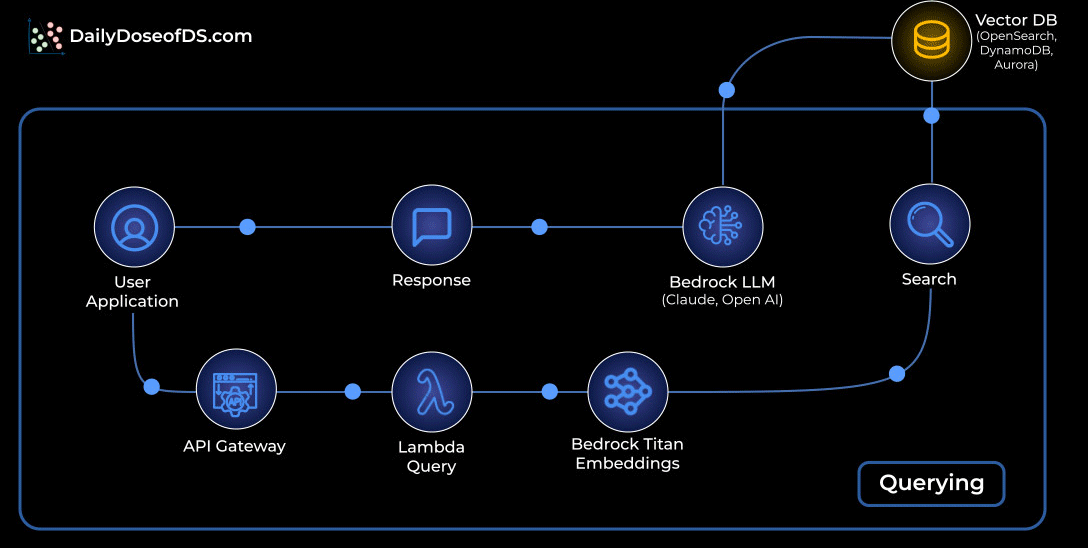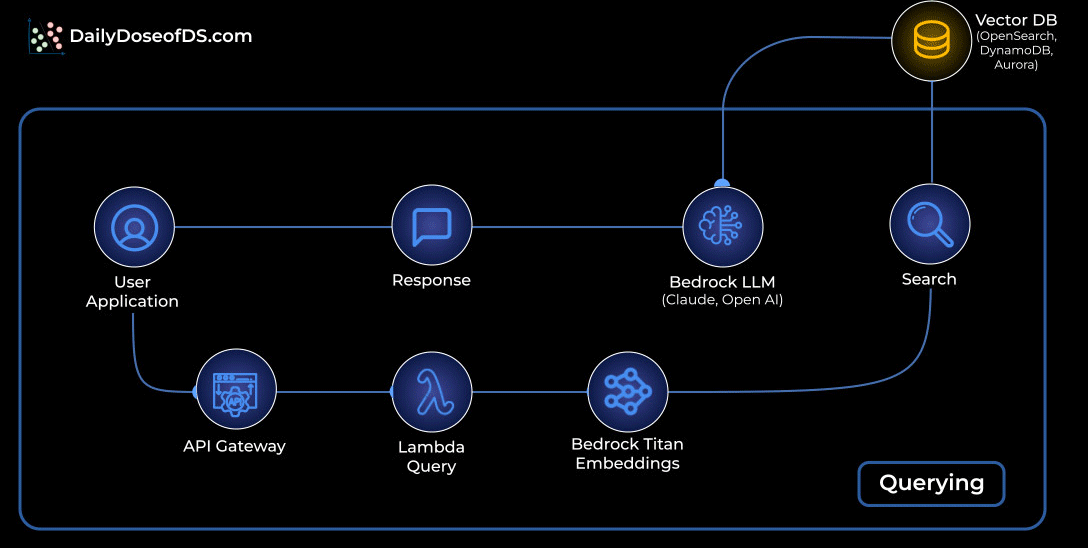
A user asks a question through the app.
The request flows through API Gateway into a Lambda query function.
The question is embedded with Bedrock Titan Embeddings.
That embedding is matched against your vector database to fetch the most relevant chunks.
Those chunks are passed to a Bedrock LLM (Claude or OpenAI) to craft the final answer.
The response travels back to the user through the same API path.
This pattern ensures the LLM is grounded in your actual data, not model guesses.
This setup is the most basic form of RAG on AWS, but the pattern stays the same even as your system grows.
You can add better chunking, smarter retrieval, caching layers, orchestration, streaming responses, eval pipelines, or multi-source ingestion, and the architecture still holds.
Here’s a visual that depicts 8 RAG architectures:
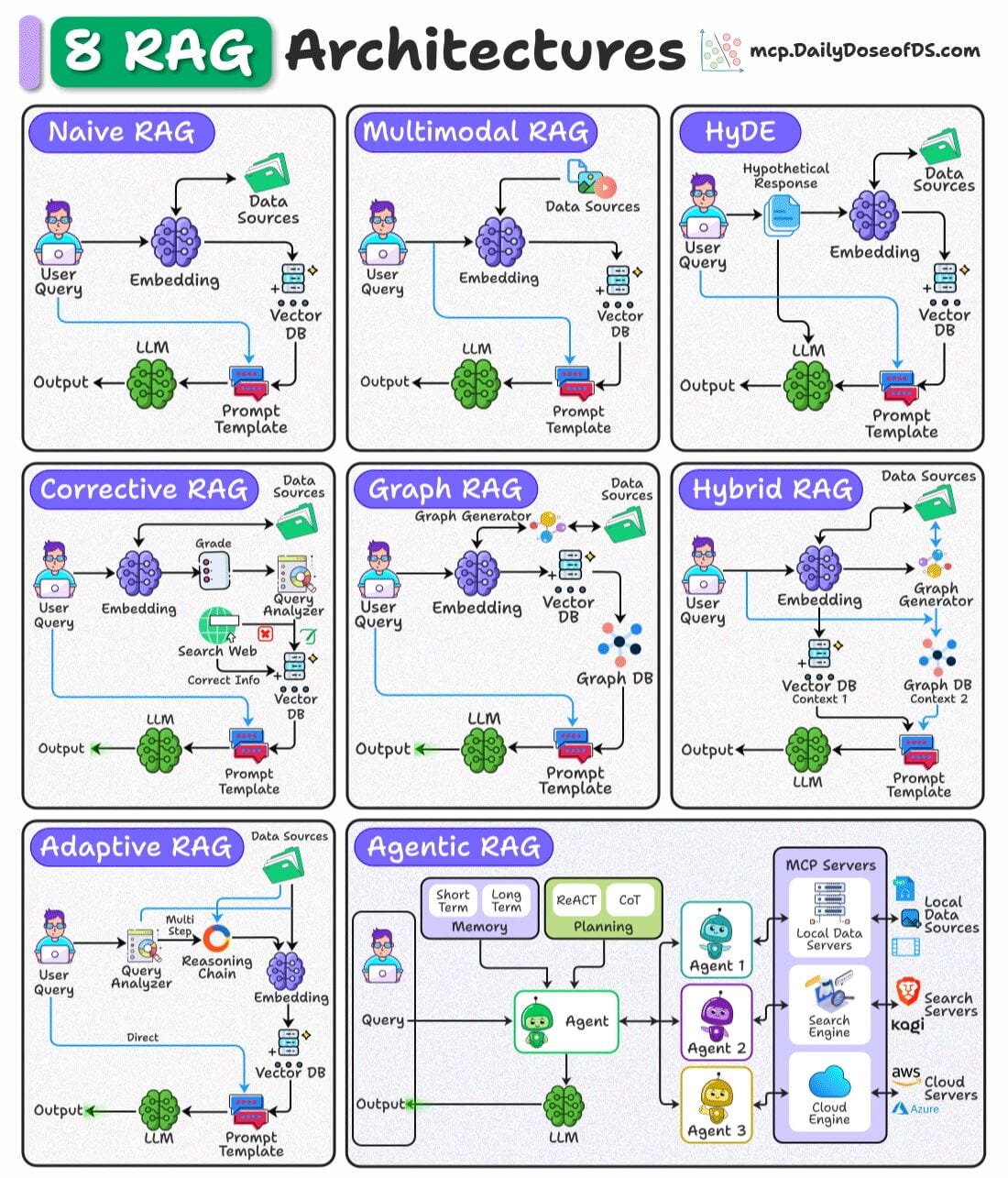
On a side note, we did a beginner-friendly crash course on RAGs recently with implementations, which covers:
👉 Over to you: What does your RAG setup look like?
Thanks for reading!