
How to Create the Elegant Calendar Plot in Python?
A richer alternative to line plot.

Calendar maps are a pretty cool way to depict the day-by-day variation in a dataset over a longer period, usually a year.
GitHub is possibly one place where I am sure you must have seen them.

I always wondered how one can create them in Python.
Turns out, there’s a pretty simple way to do it just two lines of Python using Plotly Calplot.
To create a calendar map, we can use the calplot() method from this library.
The input should be a Pandas DataFrame. Each row should represent a date and a corresponding value we wish to depict in the calendar plot, as depicted below:

Done!
Next, we can create a calendar plot as follows:
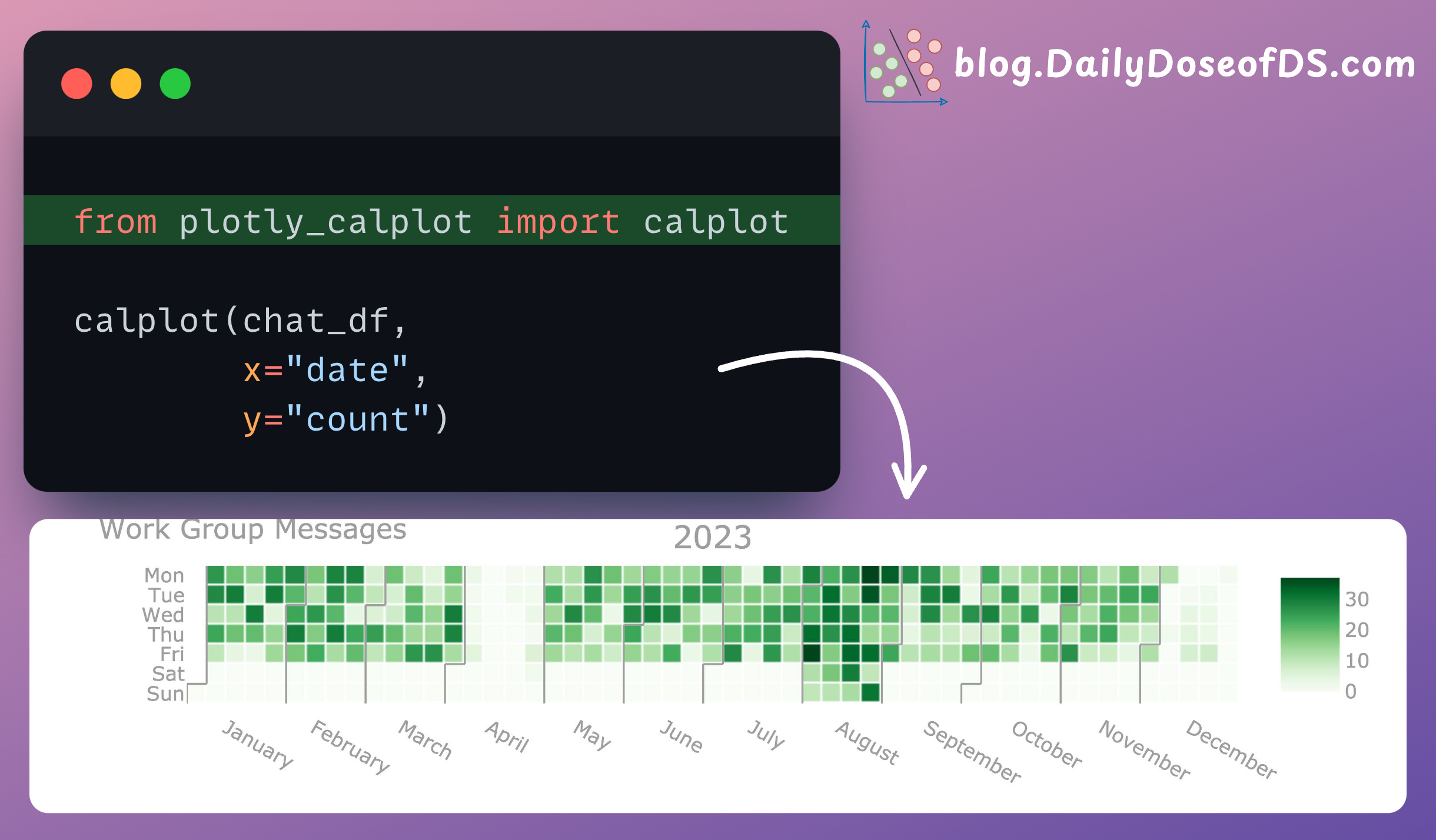
It’s pretty clear that this plot reveals many insights that otherwise would have been difficult to extract with traditional plots or aggregation methods.
This team took a one-month break in April and December. Or, if they are a remote team, they may have met in person during these two months.
They were pretty consistent on a 5-day work policy.
August is when they worked the most.
One of the best use cases of calendar plots is to understand weekly/monthly seasonality in data.
I prepared this Jupyter Notebook for you to get started: Calendar Plot Notebook.
Also, do check out an earlier issue on “8 Classic Alternatives to Traditional Plots”

I will give many ideas on how to replace traditional plots with better plots, and under which situations.
👉 Over to you: What other usages of calendar plots have I missed?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Whenever you are ready, here’s one more way I can help you:
Every week, I publish 1-2 in-depth deep dives (typically 20+ mins long). Here are some of the latest ones that you will surely like:
[FREE] A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 If you love reading this newsletter, feel free to share it with friends!
Simple and concise 🙌
Is the messages_data.csv file available for download?