


How to Detect Multivariate Covariate Shift in Machine Learning Models?
Dealing with some real-world problems of ML models.

Yesterday’s post on covariate shift was appreciated by many of you.
If you are new here or you somehow missed reading it, please read that post before proceeding ahead: Covariate Shift Is Way More Problematic Than Most People Think
In that post, I left you with a question:
How can we detect multivariate covariate shift?
Today, let’s discuss this.
To recap, covariate shift happens when the distribution of data features (covariates) changes over time after model deployment:

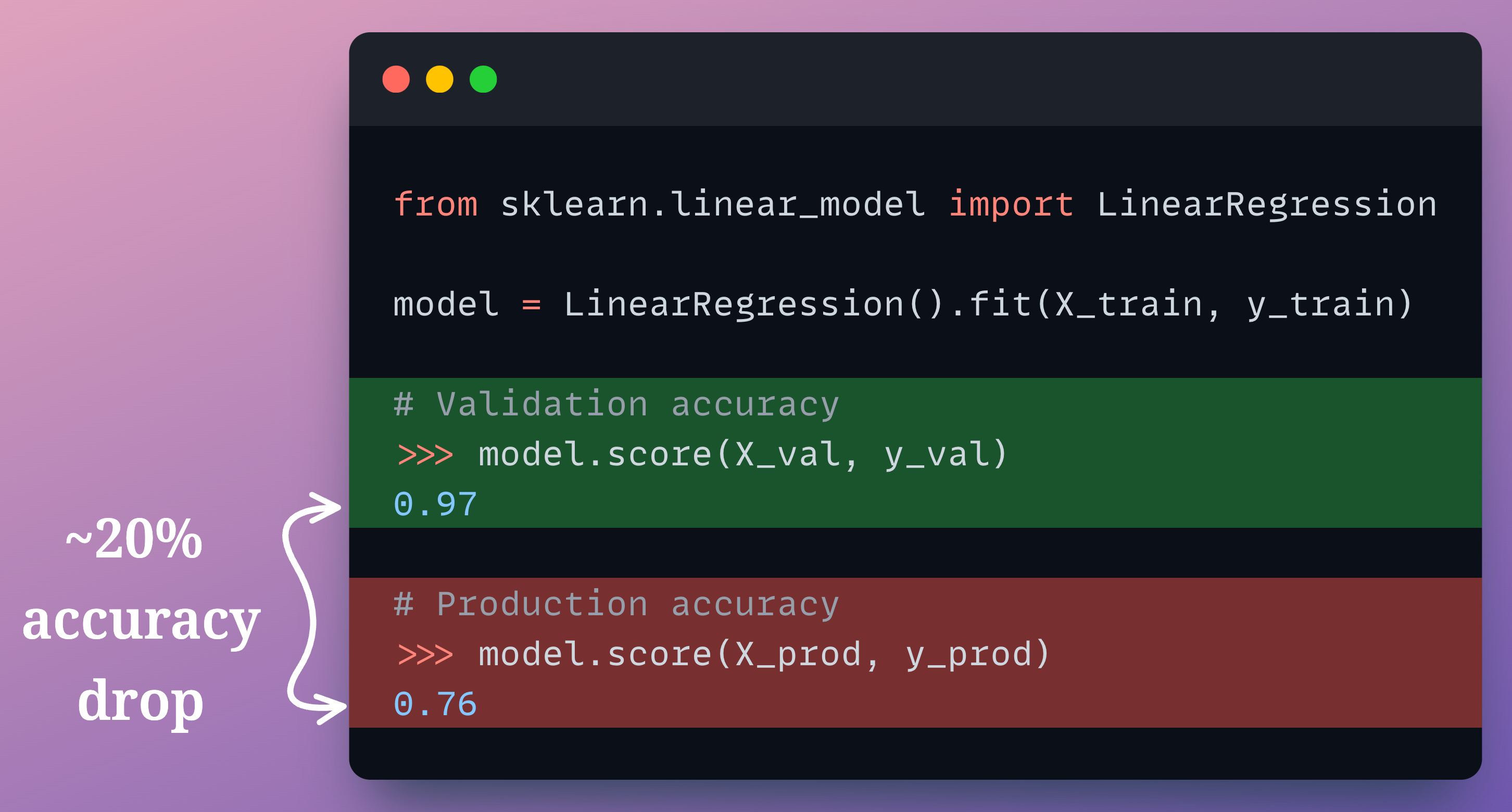
It is a serious problem because we deployed a model that was trained on one distribution.
But gradually, covariate shift steps in and degrades the model’s performance because the production environment starts testing the model on another distribution:
Common approaches to determine covariate shift between training data and production data include:
Comparing their summary statistics — mean, median, etc.
Inspecting differences visually using distribution plots.
Performing hypothesis testing.
Measuring distances between training/production distributions using Bhattacharyya distance, KS test, etc.
But the problem is that these approaches can only detect univariate covariate shift — they only work on one feature at a time.
And as we saw yesterday, real-world models may encounter multivariate covariate shift as well, which is evident from the image below:
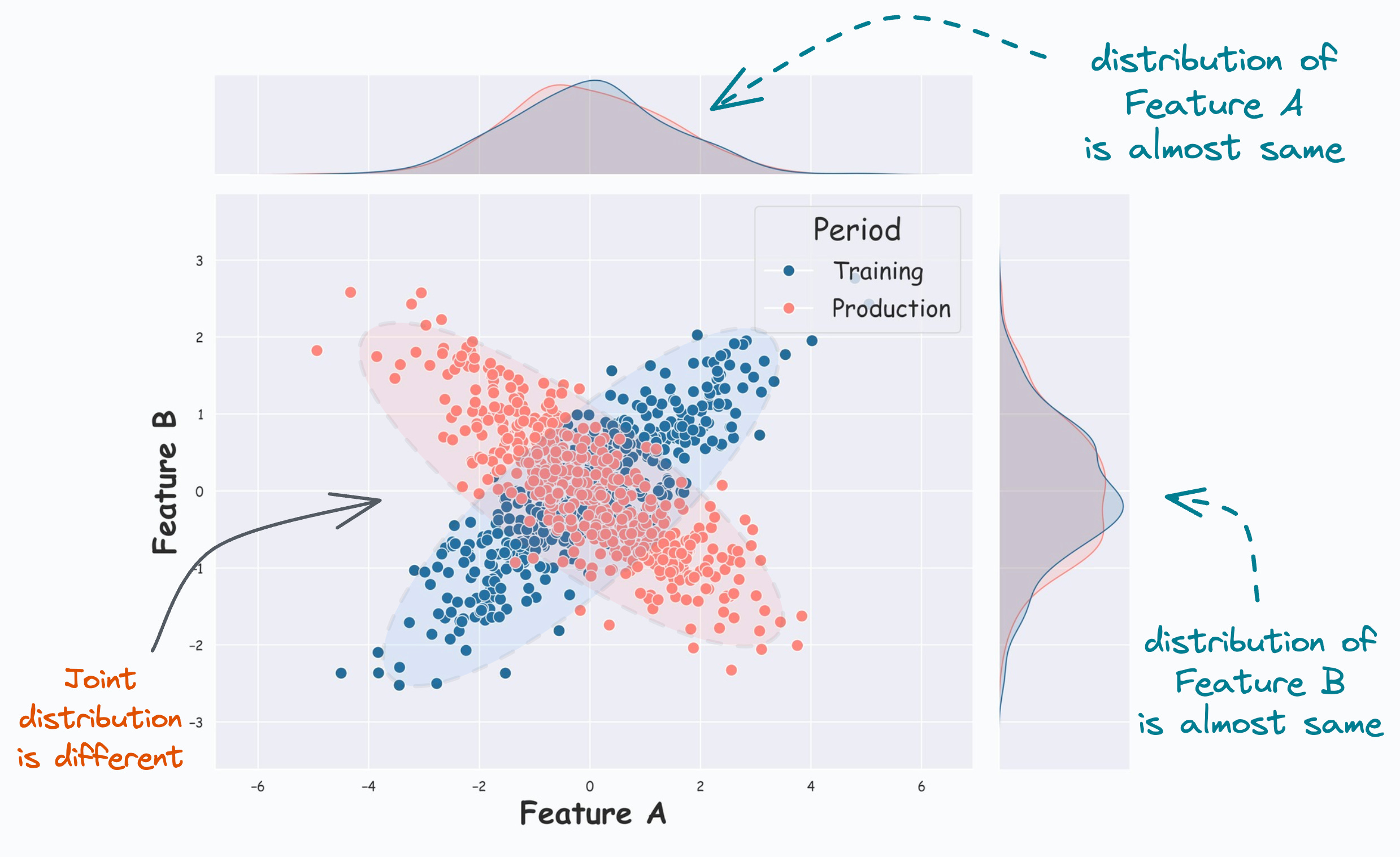
From the KDE plots on the top and the right, it is clear that the distribution of both features (covariates) is almost the same.
But, the scatter plot reveals that their joint distribution in training (Blue) differs from that in production (Red).
So how can we detect multivariate covariate shift?
To begin, it is important to understand that multivariate covariate shift is a big problem, and there is no direct (or single) approach to handle this.
Below, I will share a couple of ideas that I often use myself and have seen others use as well to handle multivariate covariate shift.
Idea #1: Rare possibility of multivariate covariate shift
As long as we are checking two (or even three) features at a time, visual inspection can be used to detect covariate shift.
So here, at times, many simply ignore the possibility of any covariate shift beyond three features.

The rationale is that beyond three features, it is pretty unlikely that:
P(X1), P(X2), P(X3), P(X4),… → all of them individually will almost remain the same.
But their joint distribution P(X1, X2, X3, X4,…) will change.
Thus, it might be fair to limit multivariate covariate shift analysis to just one, two, and three features at a time.
But of course, this may not be always true, which brings us to another idea:
Idea #2: Data reconstruction
This is another cool and practical idea that I used in one of my projects.
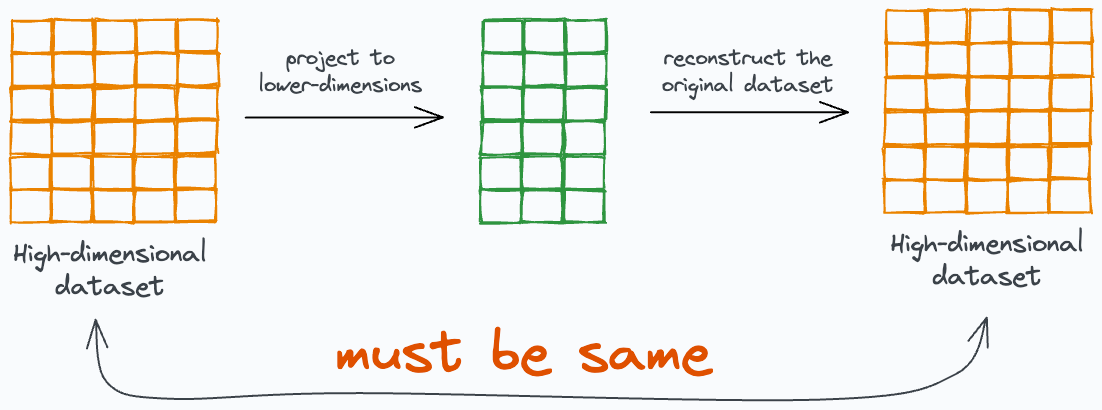
Data reconstruction, as the name suggests, revolves around learning a mapping that projects the data to low dimensions and then reconstructs the original data from the low dimensions.
On a side note, this is precisely what Autoencoders do.
They are a class of neural networks that learn to encode data in a lower-dimensional space, and then decode it back to the original data space.

The objective is to minimize the data reconstruction error.
It’s like asking the model to learn a mapping that:
Takes some data.
Projects the data to low dimensions.
And then gives us the exact input data back.
So here’s what we can do:
Train an Autoencoder on the original training dataset. This will give us the weights for the neural network model that reconstructs the dataset.
Use this model on new data to check multivariate covariate shift:
If the reconstruction loss is high, it indicates that the distribution has changed.
If the reconstruction loss is low, it indicates that the distribution is almost the same.

This makes intuitive sense as well.
But you know, one of the best things about this approach is that it does not need a labeled dataset.
Essentially, Autoencoders aim to reconstruct the dataset without labels.
This is quite useful in real-world models because, as we discussed yesterday, in most cases, the true output predictions on production data are never immediately available.
Instead, they always take some time.
For instance, I remember when I was working on a transactional fraud detection model at Mastercard, a card holder’s issuer bank may take upto 45-50 days to send the fraud label for the transactions that went through Mastercard’s network.
This is a lot of time, isn’t it?
But using Autoencoders, we can still check data reconstruction errors on the unlabeled data.
In fact, we don’t necessarily have to use Autoencoders. It was just an example here.
Other data reconstruction techniques can also be used, such as PCA is one of them.
Nonetheless, when using any data reconstruction approach, it is important to take care of one thing.
Earlier, we discussed that:
If the reconstruction loss is high, it indicates that the distribution has changed.
If the reconstruction loss is low, it indicates that the distribution is almost the same.
But interpreting reconstruction loss can be pretty subjective, and it also needs some context.
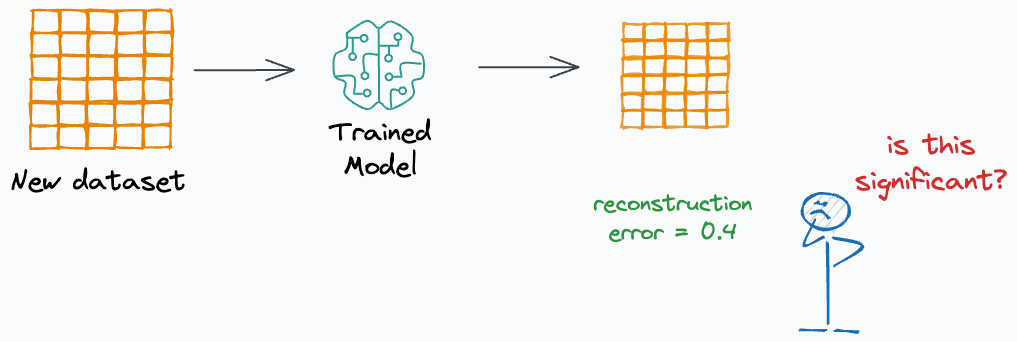
For instance, if the reconstruction loss is 0.4 (say), how do we determine whether this is significant?
Yet again, considering the importance of this topic, I don’t want to rush through it.
We shall continue our discussion on this topic tomorrow.
In the meantime, it’s over to you:
Think about how you would interpret the reconstruction loss to determine whether covariate shift has stepped in or not.
Also, what could be some limitations of data reconstruction approaches for detecting covariate shift?
I would love to hear from you :)
Thanks for reading!
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Why Bagging is So Ridiculously Effective At Variance Reduction?
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Model Compression: A Critical Step Towards Efficient Machine Learning.
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Take 1,000 bootstrapped samples of the current dataset and calculate the reconstruction loss for each. Calculate the mean and stdev. Then, if the reconstruction loss of the new dataset is more than 2 stdev's above the mean, we have data shift.