
How To Improve ML Models with Human Labels
How to NOT let your model improvement efforts go in vain.

Automatic Audio language detection at Superhuman Accuracy with AssemblyAI
AssemblyAI has made several improvements to its automatic language detection (ALD) model and added support for 10 new languages (total 17 languages).
AssemblyAI’s ALD model outperforms Google, AWS, Deepgram, and OpenAI Whisper on 16 of 17 languages.
A demo is shown below:

Import the package, set the API key, and transcribe the file while setting
language_detectionparameter toTrue.Use the transcript object to print the detected language. Done!
AssemblyAI’s speech-to-text models rank top across all major industry benchmarks. You can transcribe 1 hour of audio in ~35 seconds at an industry-leading accuracy of 92.5% (for English).
Sign up today and get $50 in free credits!
Thanks to AssemblyAI for sponsoring today’s issue.
How To Improve ML Models with Human Labels
Consider we are building a multiclass classification model. Say it’s a model that classifies an input image as a rock, paper, or scissors:

For simplicity, let’s assume there’s no class imbalance.
Calculating the class-wise validation accuracies gives us the following results:

Paper class: 97%
Rock class: 82%
Scissor class: 75%
Question: Which class would you most intuitively proceed to inspect further and improve the model on?
After looking at these results, most people believe that “Scissor” is the worst-performing class and should be inspected further.

But this might not be true.
Let’s say that the human labels give us the following results:
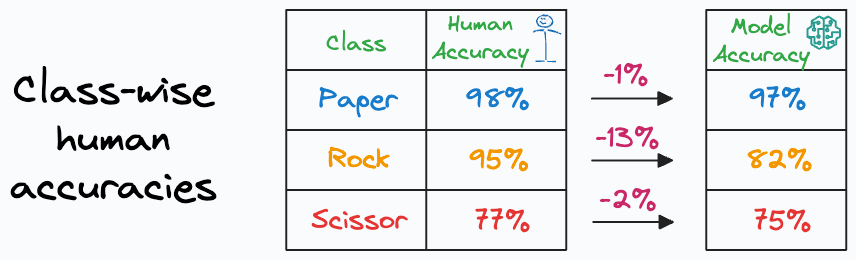
Based on this, do you still think the model performs the worst on the “Scissor” class?
No, right?
I mean, of course, the model has the least accuracy on the “Scissor” class, and I am not denying it.
However, with more context, we notice that the model is doing a pretty good job classifying the “Scissor” class. This is because an average human is achieving just 2% higher accuracy in comparison to what our model is able to achieve.
However, the above results astonishingly reveal that it is the “Rock” class instead that demands more attention. The accuracy difference between an average human and the model is way too high (13%).
Had we not known this, we would have continued to improve the “Scissor” class, when in reality, “Rock” requires more improvement.
Ever since I learned this technique, I have found it super helpful to determine my next steps for model improvement, if possible.
I say “if possible” since many datasets are hard for humans to interpret and label.
Nonetheless, if it is feasible to set up such a “human baseline,” one can get so much clarity into how the model is performing.

As a result, one can effectively redirect their engineering efforts in the right direction.
That said, if the model is already performing better than the human baseline, the model improvements will be guided based on past results.
Yet, in such cases, surpassing a human baseline at least helps us validate that the model is doing better than what a human can do.
Isn’t that a great technique?
👉 Over to you: What other ways do you use to direct model improvement efforts?
For those wanting to develop “Industry ML” expertise:
All businesses care about impact.
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with “Industry ML.” Here are some of them:
Quantization: Optimize ML Models to Run Them on Tiny Hardware
Conformal Predictions: Build Confidence in Your ML Model's Predictions
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning
Model Compression: A Critical Step Towards Efficient Machine Learning
Being able to code is a skill that’s diluting day by day.
Thus, the ability to make decisions, guide strategy, and build solutions that solve real business problems and have a business impact will separate practitioners from experts.
SPONSOR US
Get your product in front of ~90,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
Nice idea to create a benchmark performance !