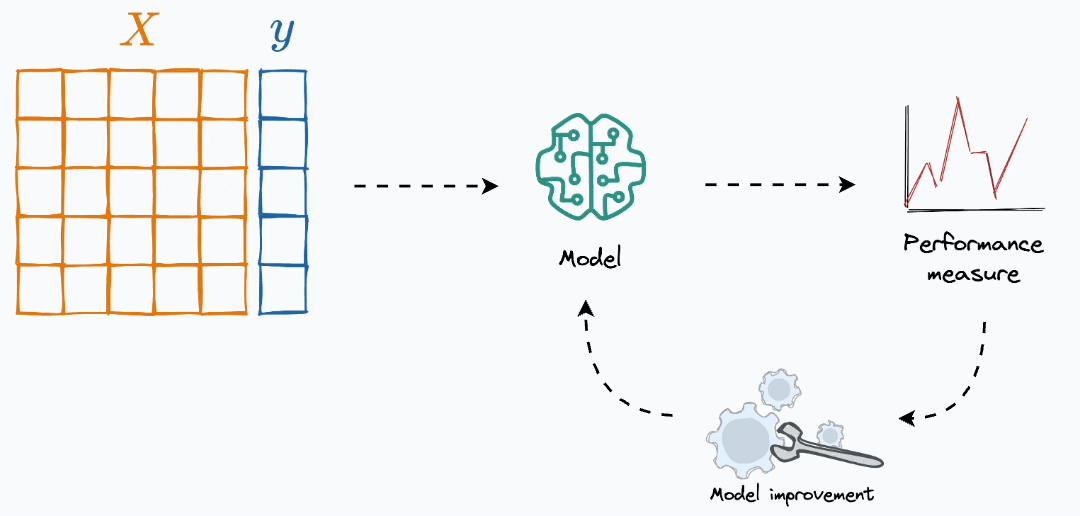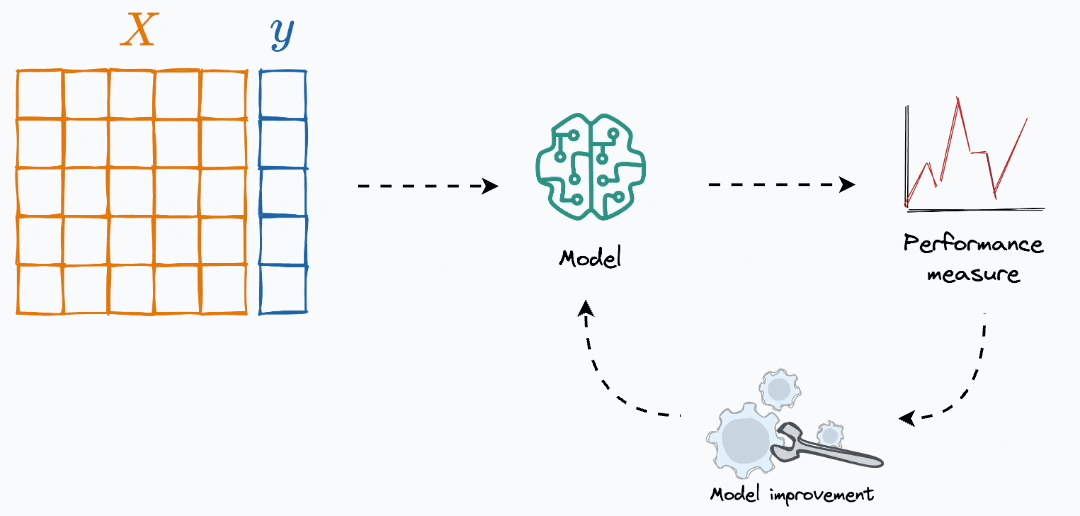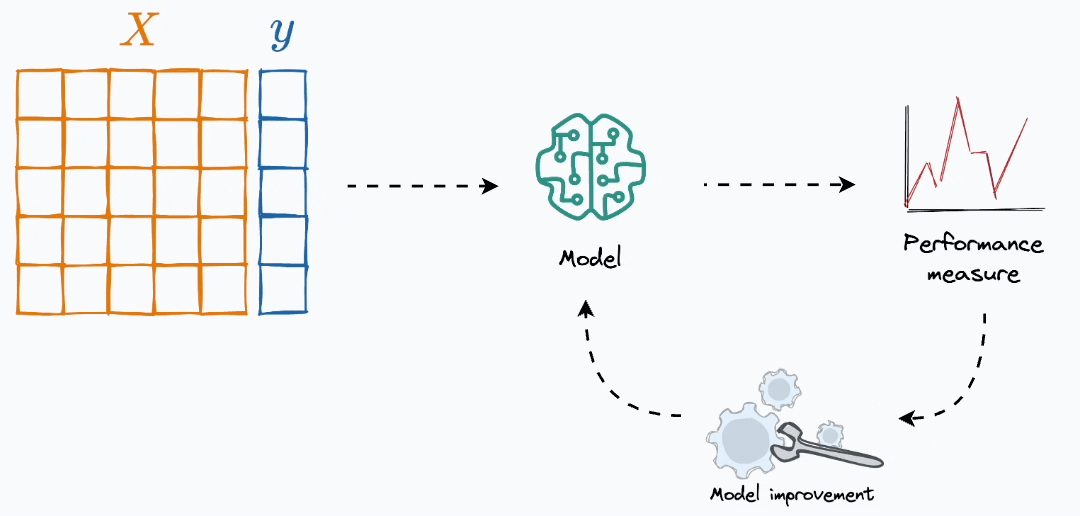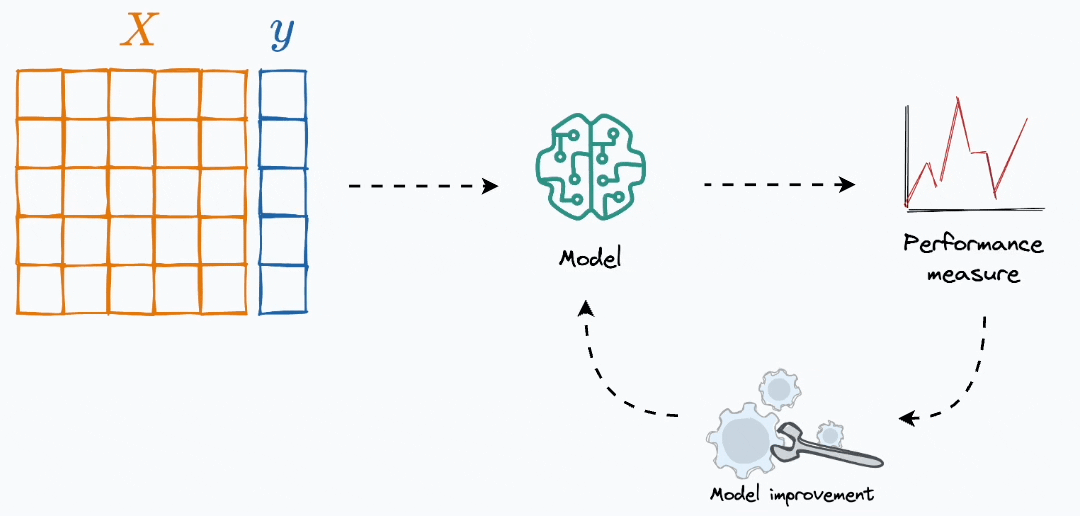
Machine learning model building is typically an iterative process. Given some dataset:
We train a model.
We evaluate it.
And we continue to improve it until we are satisfied with the performance.
Here, the efficacy of any model improvement strategy (say, introducing a new feature) is determined using some sort of performance metric.
Introducing a new feature improved the model, so the technique was effective.
However, I have often observed that when improving probabilisticmulticlass-classification models, this technique can be a bit deceptive when the efficacy is determined using “Accuracy.”
Probabilisticmulticlass-classification models are those models that output probabilities corresponding to each class, like neural networks.
In other words, it is possible that we are actually making good progress in improving the model, but “Accuracy” is not reflecting that (yet).
Let me explain!
Pitfall of Accuracy
In probabilistic multiclass-classification models, Accuracy is determined using the output label that has the highest probability:
Now, it’s possible that the actual label is not predicted with the highest probability by the model, but it’s in the top “k” output labels.
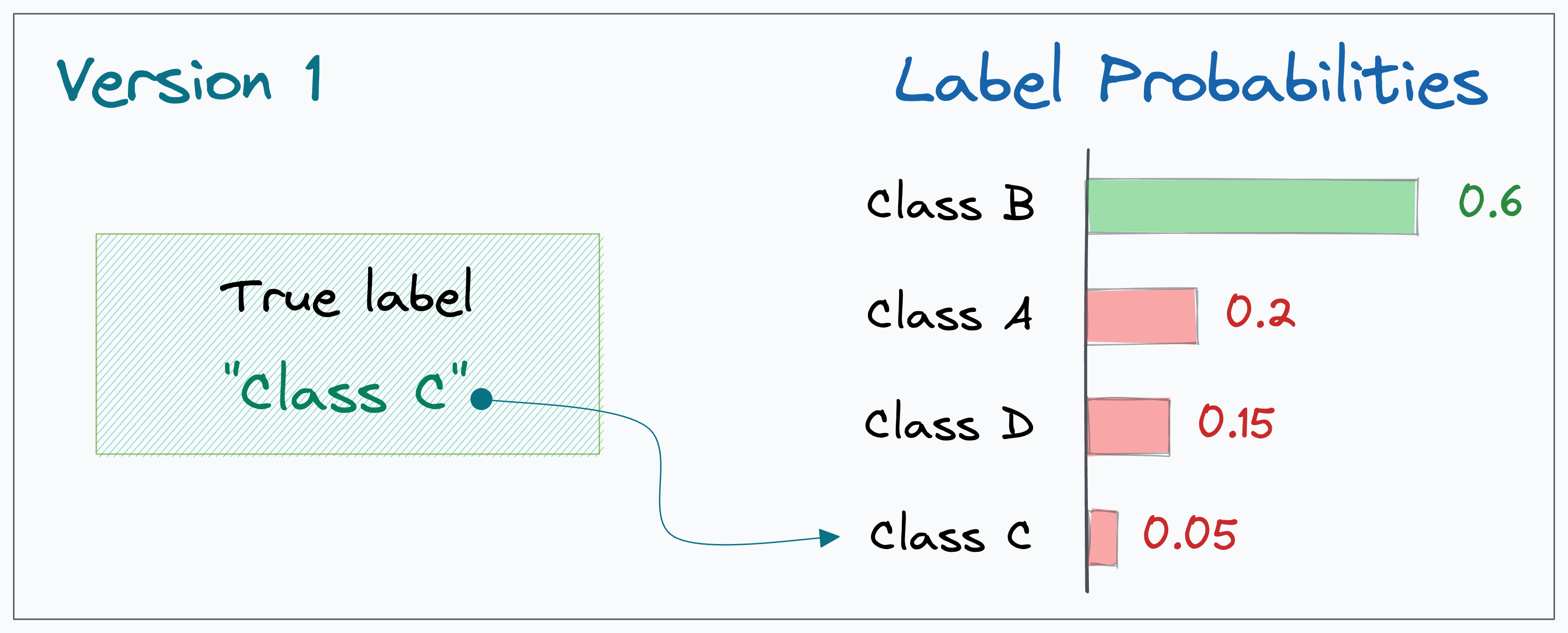
For instance, in the image below, the actual label (Class C) is not the highest probability label, but it’s at least in the top 2 predicted probabilities (Class B and Class C):
And what if in an earlier version of our model, the output probability of Class C was the lowest, as depicted below:
Now, of course, in both cases, the final prediction is incorrect.
However, while iterating from “Version 1” to “Version 2” using some model improvement techniques, we genuinely made good progress.
Nonetheless, Accuracy entirely discards this as it only cares about the highest probability label.
I hope you understand the problem here.
Solution
Whenever I am building and iteratively improving any probabilistic multiclass classification model, I always use the top-k accuracy score.
As the name suggests, it computes whether the correct label is among the top k labels predicted probabilities or not.
As you may have already guessed, top-1 accuracy score is the traditional Accuracy score.
This is a much better indicator to assess whether my model improvement efforts are translating into meaningful enhancements in predictive performance or not.
For instance, if the top-3 accuracy score goes from 75% to 90%, this totally suggests that whatever we did to improve the model was effective:
Earlier, the correct prediction was in the top 3 labels only 75% of the time.
But now, the correct prediction is in the top 3 labels 90% of the time.
As a result, one can effectively redirect their engineering efforts in the right direction.
Of course, what I am saying should only be used to assess the model improvement efforts.
This is because true predictive power will inevitably be determined using traditional model accuracy.
So make sure you are gradually progressing on the Accuracy front too.
Ideally, it is expected that “Top-k Accuracy” may continue to increase during model iterations, which reflects improvement in performance. Accuracy, however, may stay the same for a while, as depicted below:
Top-k accuracy score is also available in Sklearn:
Isn’t that a great way to assess your model improvement efforts?
👉 Over to you: What are some other ways to assess model improvement efforts?
Thanks for reading Daily Dose of Data Science! Subscribe for free to learn something new and insightful about Python and Data Science every day. Also, get a Free Data Science PDF (550+ pages) with 320+ tips.
Whenever you are ready, here’s one more way I can help you:
Every week, I publish 1-2 in-depth deep dives (typically 20+ mins long). Here are some of the latest ones that you will surely like:
Log loss is the gold standard in this case. The top k accuracy is still discontinuous with respect to the predicted probabilities, so it still obscures the changes in model performance. However, the log loss varies continuously as the predicted probabilities change.









Log loss is the gold standard in this case. The top k accuracy is still discontinuous with respect to the predicted probabilities, so it still obscures the changes in model performance. However, the log loss varies continuously as the predicted probabilities change.