
How To Simplify ANY Data Analytics Project with DoubleCloud?
Kick off analytics projects in minutes instead of days.

The outcome of any typical data analytics project is to make some key business decisions by extracting insights.

This task sounds simple.
However, the life of a data analyst is quite complicated, mainly due to the technical difficulties they face at every stage of their analytics project.
Today, I want to tell you about DoubleCloud, a platform specifically designed to streamline all data analytics projects by addressing the challenges we will discuss shortly.

More specifically, in this post, I will:
Share some challenges in data analytics projects.
Explain how DoubleCloud solves them and streamlines the entire project.
Do a practical demo of DoubleCloud.
Share my opinion about DoubleCloud.
Let’s begin!
The challenge
There are typically four steps in a big-data analytics project:
Step 1) Launch a cluster
Here, we specify the service we want to use, like ClickHouse, Kafka, Spark, etc.

You can think of it like launching a Jupyter notebook and specifying whether we will analyse data using Pandas or Polars (of course, this is a bit hypothetical example and was just used to explain the point).
Moving on…
Just like Pandas/Polars are interfaces, so are the services mentioned above.
Thus, we must add a computational resource, which could be a cloud provider such as AWS, Google Cloud, or Azure.
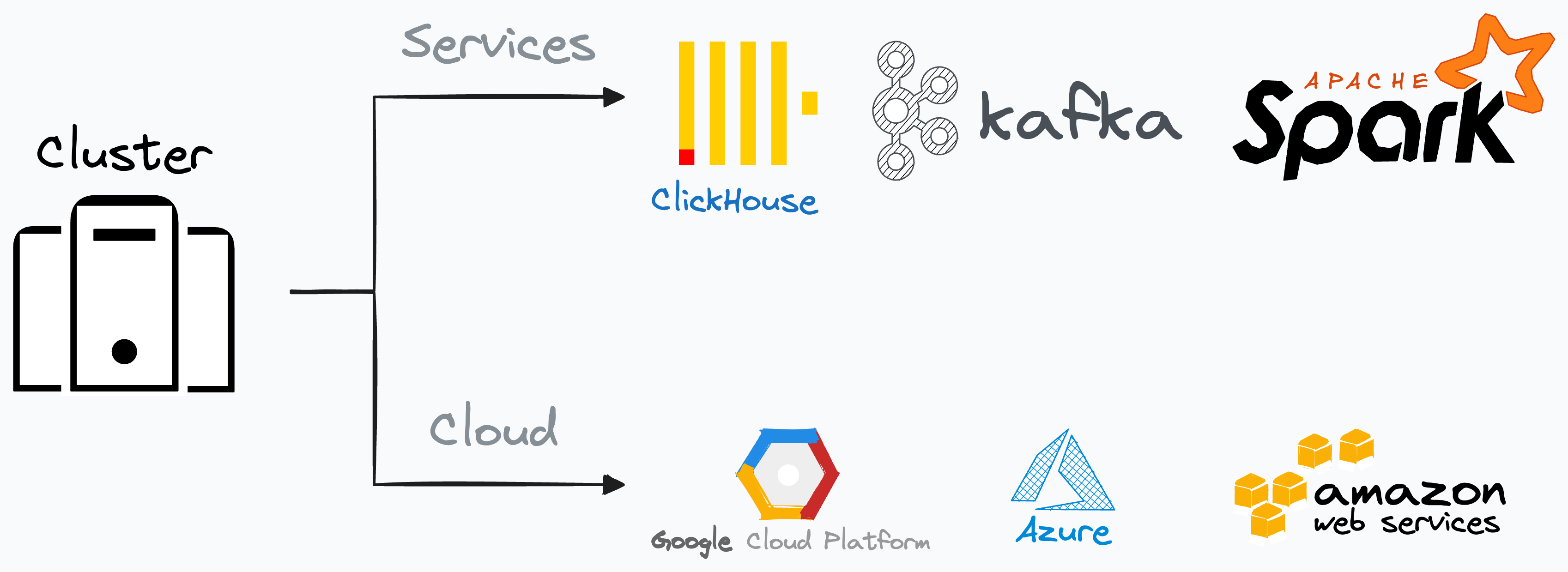
This creates our cluster.
Step 2) Connect to a database
The data we wish to analyze could be available in any data source like Amazon S3, Snowflake, MongoDB, etc.
So in this step, we connect the cluster to that specific data source.

Step 3) Analyse the data
By now, the service, the computational infrastructure, and the data source(s) are ready.
In this step, we analyze the data and gather insights.
Step 4) Visualise the data
Finally, we present these insights as visualizations using tools like PowerBI, Tableau, etc.

That’s the typical blueprint of a data analytics project.
Notice that in the above discussion, we mentioned so many technologies at every step.

Yet, there are still many many more tools that are commonly used by data analysts.
The challenge is that every combination of tool stacks typically involves manual and distinct integration procedures.
For instance:
(ClickHouse → GCP → S3 → Power BI) has a configurational setup.
(Spark → Azure → Blob → Tableau) has a different configurational setup.
And so on.
This takes up plenty of time to switch between services when needed as there are no standard integration protocols.
The Solution — DoubleCloud
DoubleCloud resolves the above challenges.
Simply put, DoubleCloud is a platform that streamlines the entire data analytics workflow by integrating various tool stacks used across different steps.
It does this by abstracting away all the underlying integration-related technicalities.
To simplify a bit, it’s like selecting any technology of your choice from a dropdown, as depicted below:

This way, data analysts can do the only thing they are supposed to — analyze data and uncover insights without messing with the integration challenges at all.
DoubleCloud takes care of that.
Isn’t that cool?
DoubleCloud Demo
The demo below can be done with a free DoubleCloud account, which you can create here.
They provide $300 trial credits, which will be more than sufficient.
Here’s the workflow:
We will create a cluster with ClickHouse service and AWS as the cloud provider.

We have a parquet file in an Amazon S3 bucket. To connect it to DoubleCloud, we shall:
Create a database in ClickHouse.
Initiate a DoubleCloud Transfer from Source (S3 Bucket) to Target (Database created in the step above).
Visualise it.
To save time, I have already set up an S3 Bucket: “doublecloud-demo-bucket”. We shall be using this.
Assuming you have already created a DoubleCloud account, the first step is to create a cluster as follows:
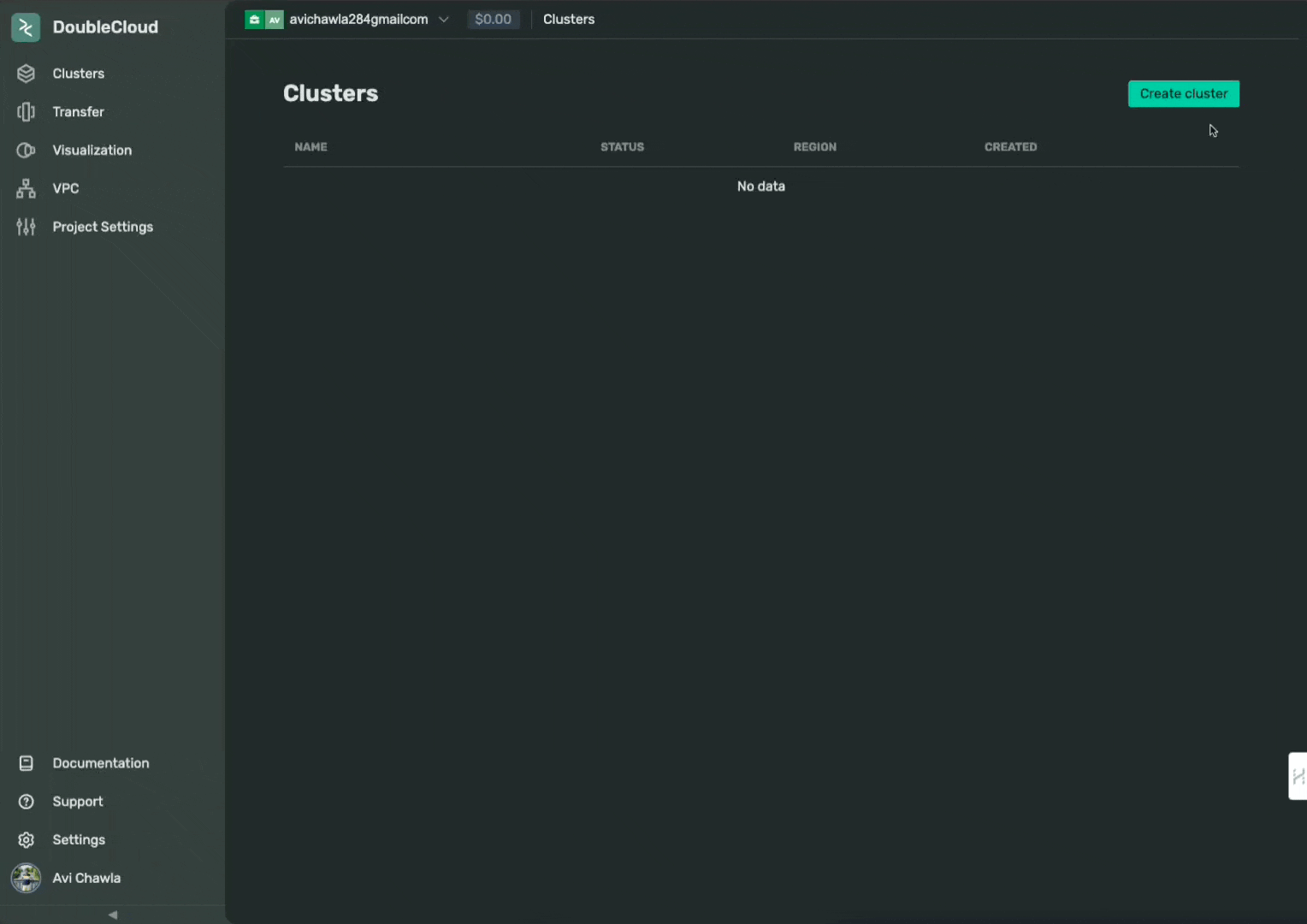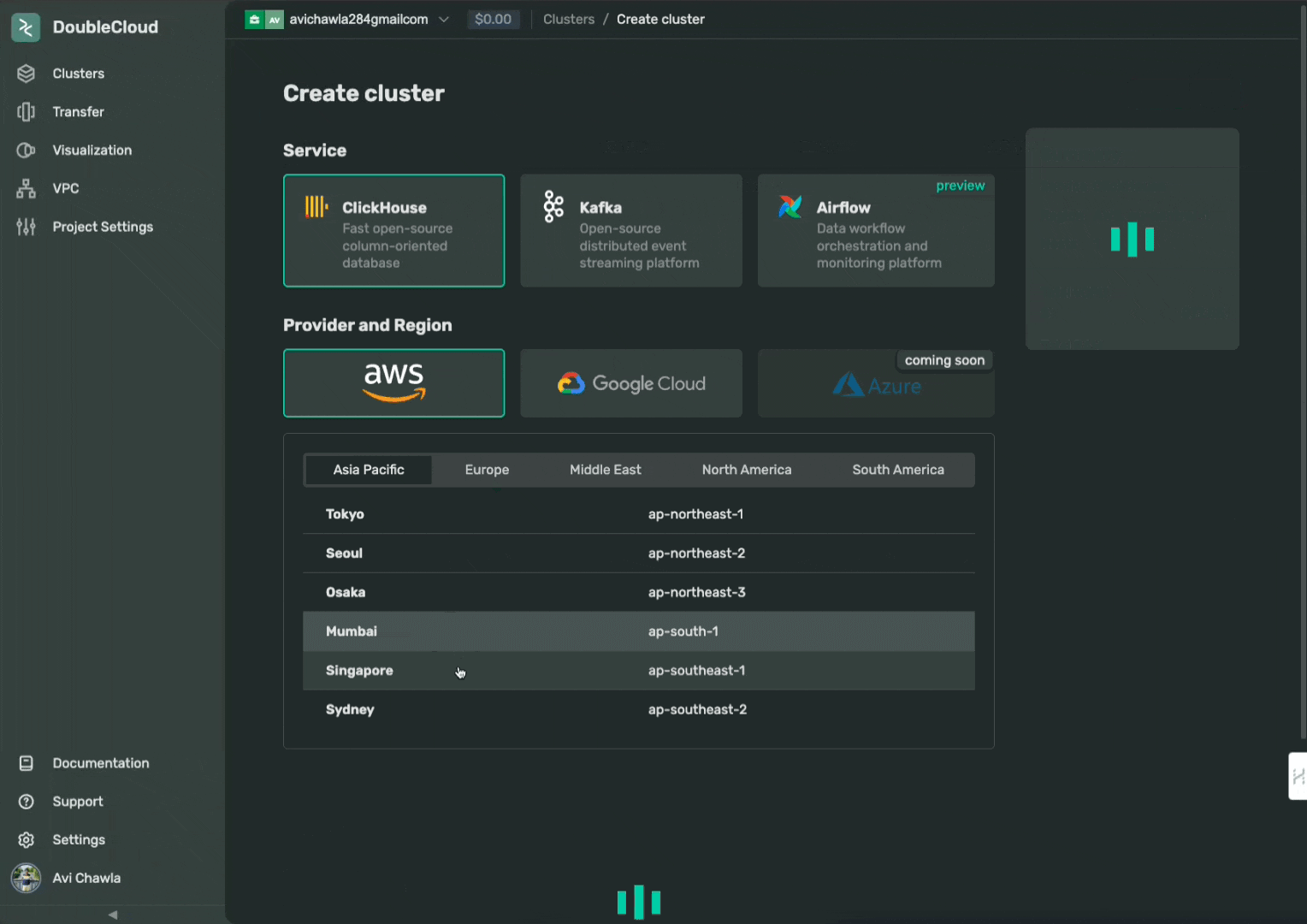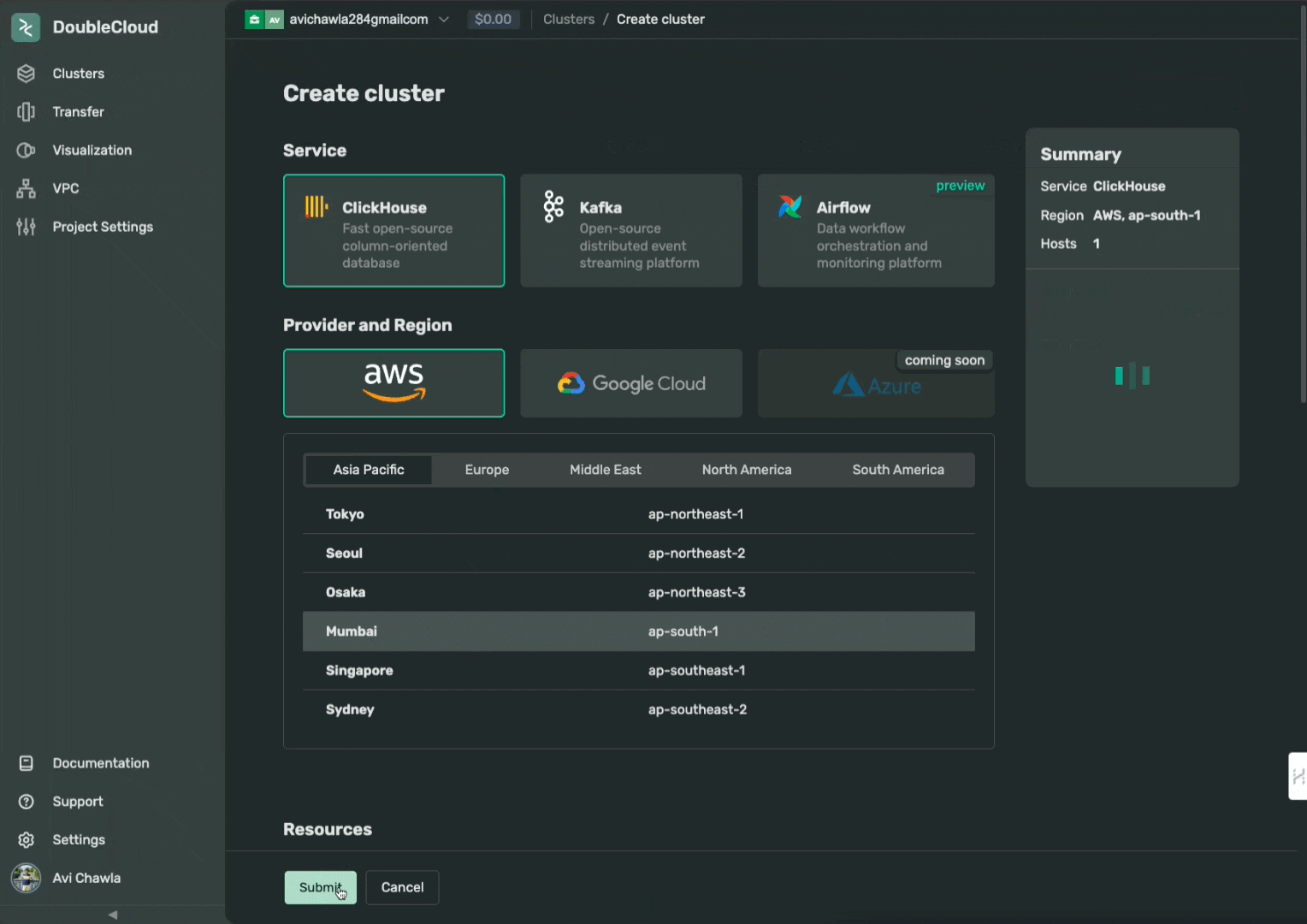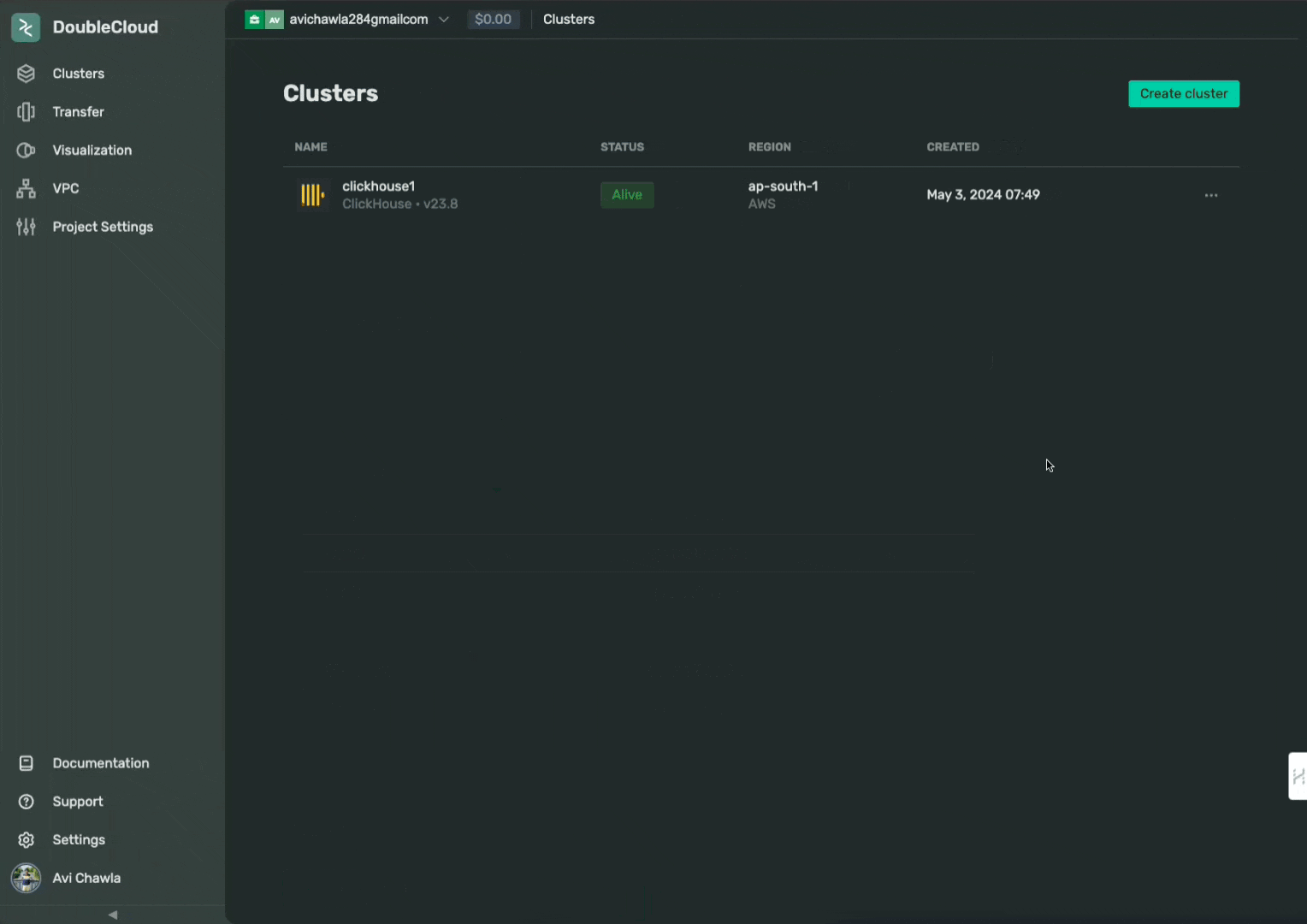
Next, click on the cluster created above, copy the password, and open the “SQL CONSOLE” as depicted below:

This will open a ClickHouse window. Complete the steps shown below to create a database:

create database `doublecloud-demo` on cluster '{cluster}'We can verify the database has been created by running “show databases”:

Perfect!
Next, we will create a new transfer. This will transfer the data from the S3 bucket to the ClickHouse database.

Select “SOURCE” and specify the following fields (which are self-explanatory):
SOURCE TYPE → Object Storage
NAME → doublecloud-demo-source
Bucket → doublecloud-demo-bucket
Data format → Parquet
Table → employee_dataset
Click Submit.
Next, select “TARGET” and specify the following fields:
TARGET TYPE → ClickHouse
NAME → doublecloud-demo-target
Managed cluster (a dropdown) → clickhouse1 (this is the cluster we created earlier)
Database → doublecloud-demo (this is the database we created earlier)
Click Submit.
At this point, you must see the following on the Transfer window. Specify the NAME and click Submit.

Finally, activate the transfer:
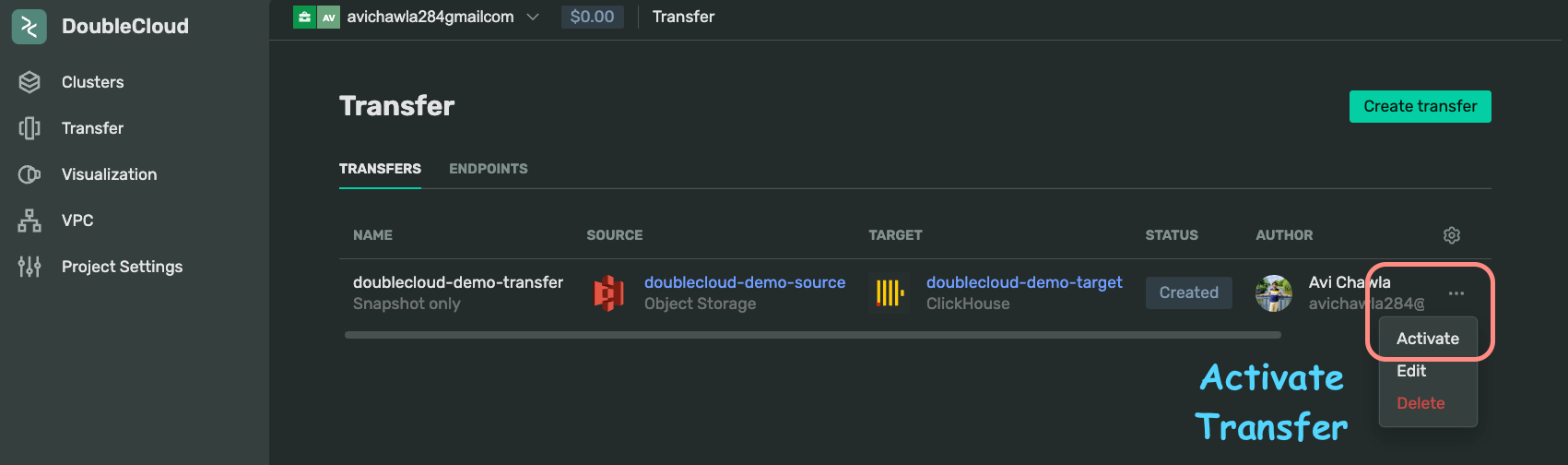
Done!
[OPTIONAL] Here, if you want, you can go back to the ClickHouse console and verify that the table has been created from an S3 source:

select * from `doublecloud-demo`.employee_dataset limit 5;Now, we can move to the last step — visualization.
Open the visualization section and create a workbook. Let’s name it doublecloud-demo-viz.

After creating a workbook, do the following in the next window:
First, create a connection as follows:
Click Create Connection → ClickHouse → Select Cluster from dropdown → Enter username and password from the cluster page (under Credentials section) → Create Connection
Next, create a dataset as follows:

Done!
You can now create a single chart (Create Chart option) or a Dashboard (Create Dashboard option).

Wasn’t that super easy?
A departing note
Data analytics projects can take days just to kick off due to the integration challenges I mentioned above.
Data analysts must thoroughly test their pipelines for issues and fix them before creating dashboards, which is not their actual job.
The thing I love about DoubleCloud is that it standardizes the entire workflow of a data analytics project.
As a result, one can replicate the steps we discussed above for:
Any supported service
Any supported cloud provider
Any supported data source
This reduces the time to kick off a data analytics project from days to just a few minutes (or hours).
For instance, it took me just 7-10 mins to set up the demo I shared above.
I read on their website that DoubleCloud’s customers like:
LSports reduced query speed by 180x compared to MySQL.
Honeybadger experienced a 30x boost compared to Elasticsearch.
Spectrio cut costs by 30-40% compared to Snowflake.

Isn’t that impressive?
That said, one thing to note is that they are yet to integrate Azure. But it is expected pretty soon.
I love DoubleCloud’s mission of supporting data analysts in building end-to-end data analytics projects without worrying about any challenges.
They are solving a big problem with existing tools, and I’m quite eager to see how they continue!
You can get started with DoubleCloud here: DoubleCloud.
🙌 Also, a big thanks to DoubleCloud, who very kindly partnered with me on this post and let me share my thoughts openly.
👉 Over to you: What are other pain points of data analytics projects?
Thanks for reading!
Very interesting insight.
This is awesome but can all organizations especially start-ups afford it?