
How to Use kNNs for Imbalanced Datasets
2 techniques, explained visually.

Massive update for AI devs working on self-hosted stacks
MongoDB just rolled out Search and Vector Search in public preview for both Community Edition and Enterprise Server. This is huge if you prefer running your own infra.

Until now, anyone building semantic search or RAG needed a mix of Elasticsearch, a separate vector DB, and an ETL pipeline to keep everything in sync.
Now you can drop all that complexity.
MongoDB gives you full-text search, fuzzy search, semantic search, and vector search right inside your database.
Two things stand out:
You can build and test AI apps locally for free: Community Edition now ships with vector indexing and hybrid search, so you can prototype without the cloud.
Your search index and operational data stay perfectly aligned: Native vector search removes the sync tax that comes from juggling multiple external systems.
This is a serious upgrade for developers building RAG systems, agent memory layers, or semantic search features on bare metal or self-hosted infra.
You can try the quick start here →
Thanks to MongoDB for partnering today!
How to use kNNs for imbalanced datasets
kNN is highly sensitive to the parameter k.
To understand this, consider this dummy 2D dataset below (the red data point is a test instance we want to generate a prediction for using kNN and k=7):
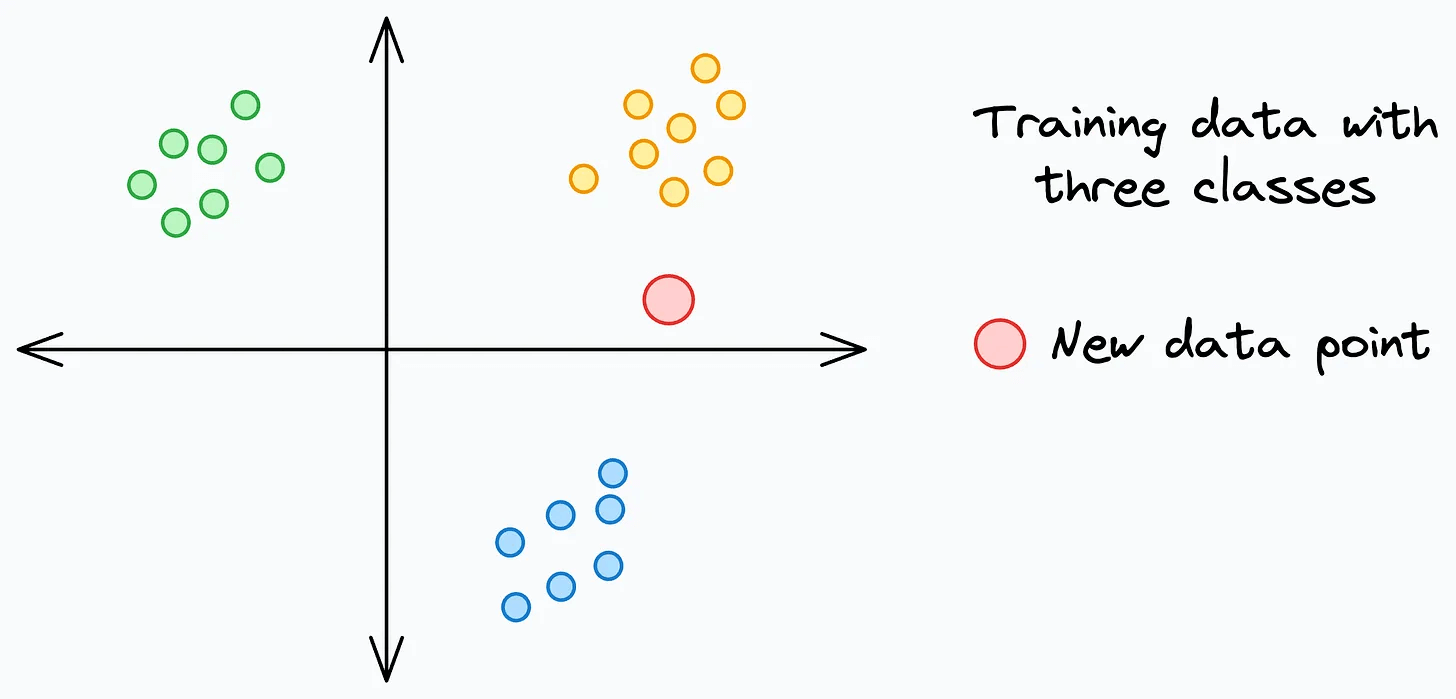
Generating a prediction will involve:
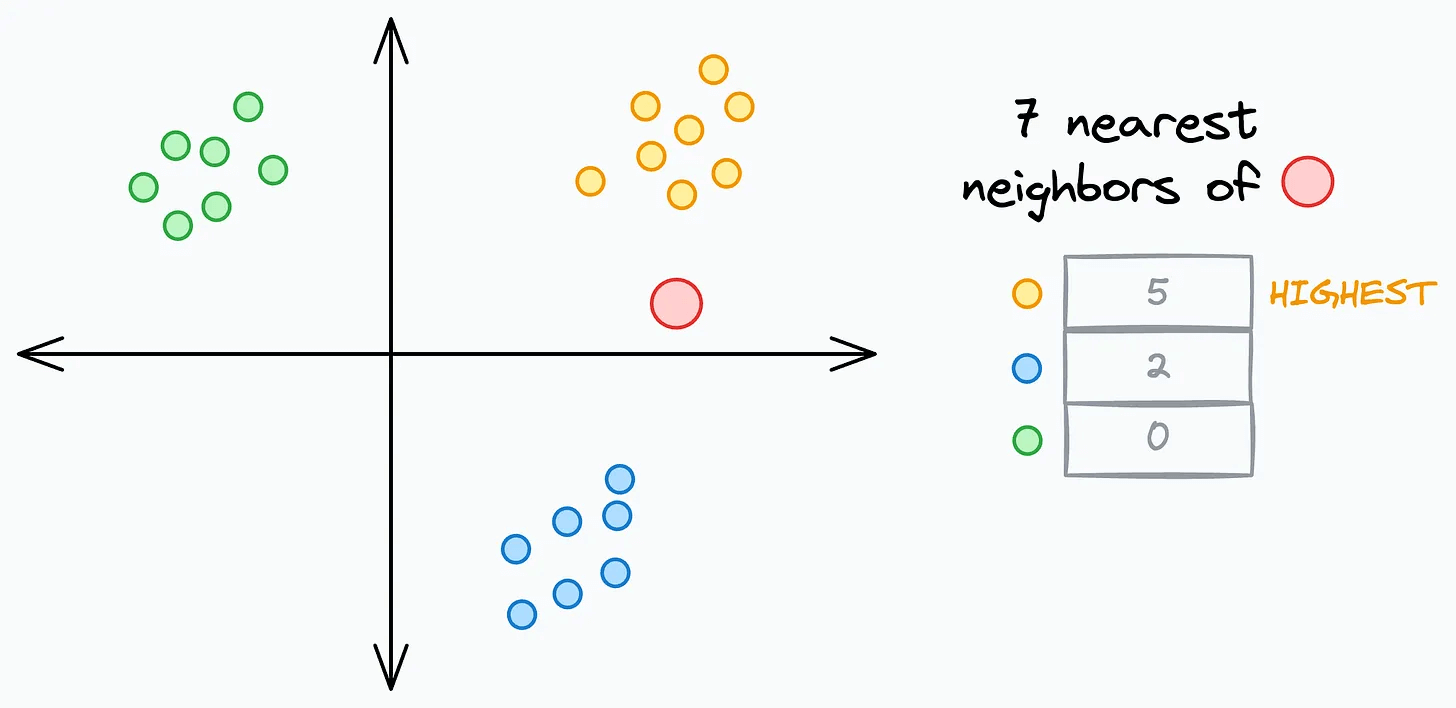
counting its
7nearest neighborsassigning it to the class with the highest count among those 7 neighbors.
The problem with Step 2 is that it is entirely based on class contribution. So the class that maximally contributes to the k nearest neighbors is picked.
But this fails when you have imbalanced datasets.
For instance, with k=7, the red data point below can NEVER be assigned to the yellow class, no matter how close it is:
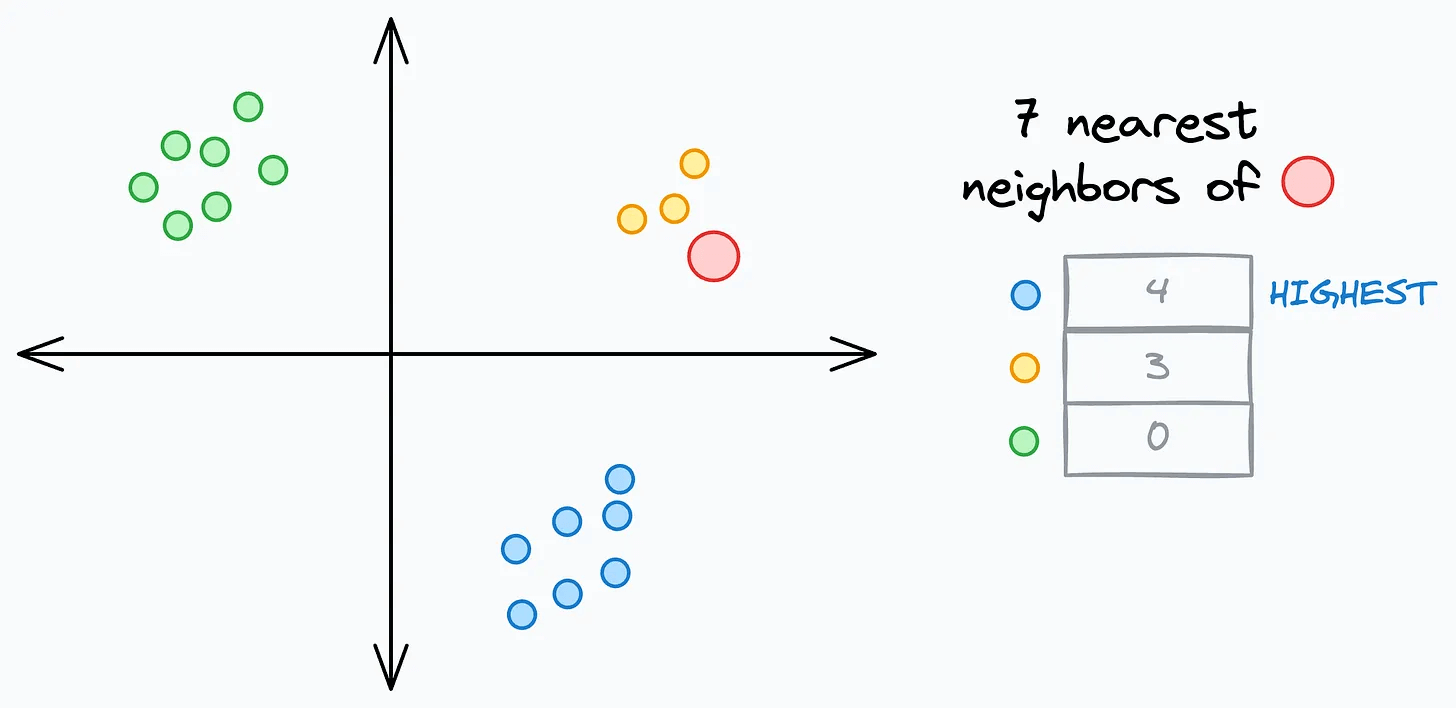
There are two ways to address this.
Solution #1: Used distance-weighed kNN
Distance-weighted kNNs are a robust alternative to traditional kNNs, that consider distance to the nearest neighbor for classification.
For instance, below, the green data point gets classified as red with traditional kNN (k=7), despite being closer to the blue cluster:
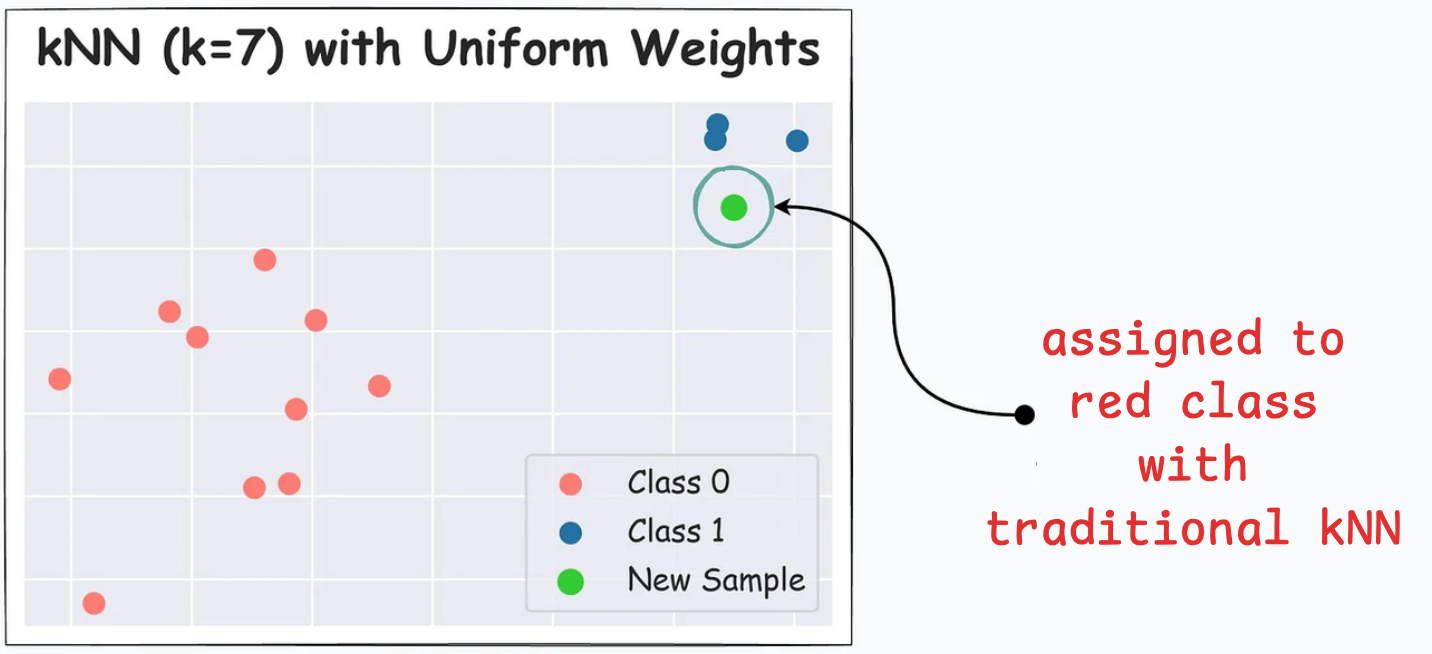
But the same data point gets classified as blue with distance-weighed kNN:
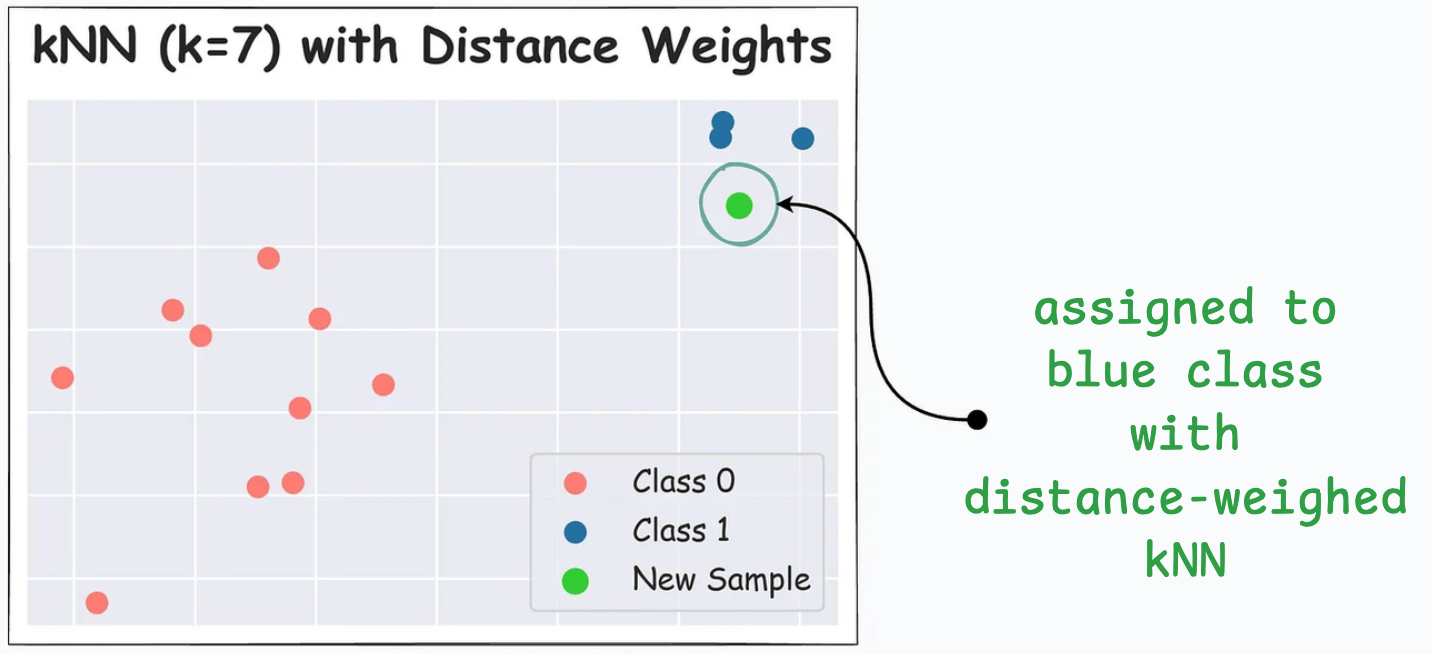
That said, it is not the default option in implementations like sklearn, so make sure to enable it:

Solution #2: Dynamically update the hyperparameter k
Recall the above dataset again:
Here, you may argue that one must refrain from setting the hyperparameter k to any value greater than the minimum number of samples across all classess.
But there’s a problem with it.
Setting a super low value of k is usually not ideal in extremely imbalanced datasets:
Setting a globally low k (say, 1 or 2) leads to suboptimal performance since it does not holistically evaluate the nearest neighbor patterns compared to what a large value of k can do.
But we just discussed above that setting a large value of k, also leads to the domination problem.
Both problems can be solved by dynamically updating the hyperparameter k based on the situation.
More specifically, there are three steps in this approach.
For every test instance:
Set a standard value of
kas we usually would and find theknearest neighbors.Next, for all classes that appear in the
knearest neighbors, find the total number of training instances they have.

Update the value of k to:
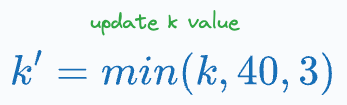
Now perform majority voting only on the first k’ neighbors only.
Here’s why this makes sense:
If a minority class appears in the top
knearest neighbor, the update rule will reduce the value ofkso that the majority class does not dominate.If a minority class DOES NOT appear in the top
knearest neighbor, it will likely not update the value ofk(because k would be the smallest value during the the update process) and do a holistic classification.
The only shortcoming is that you wouldn’t find this approach in any open-source implementations.
Some further reading:
We covered 8 fatal (yet non-obvious) pitfalls and cautionary measures in data science here.
We discussed 11 uncommon powerful techniques to supercharge your ML models here.
👉 Over to you: What are some other ways to make kNNs more robust when a class has few samples?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.