
Identify Drift using Proxy-Labelling
An intuitive way to detect drift.

Almost all real-world ML models gradually degrade in performance due to a drift in feature distribution:
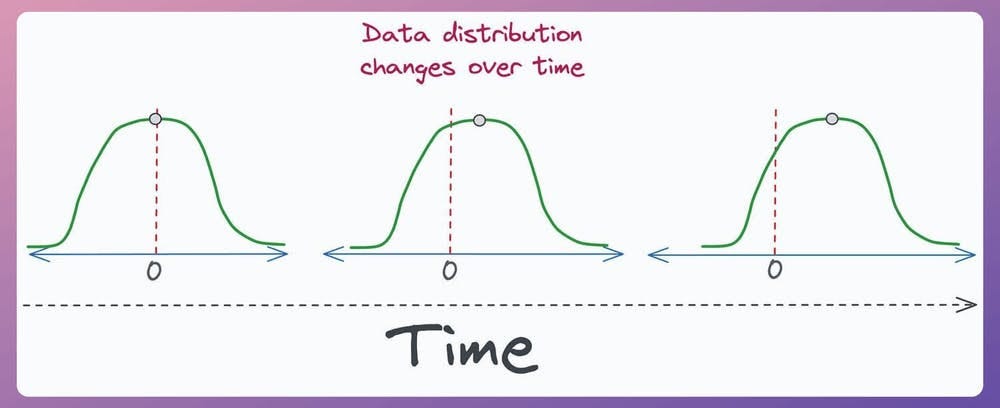
It is a serious problem because we trained the model on one distribution, but it is being used to generate predictions on another distribution in production.
The following visual summarizes a technique I often use to detect drift:

There are four steps:
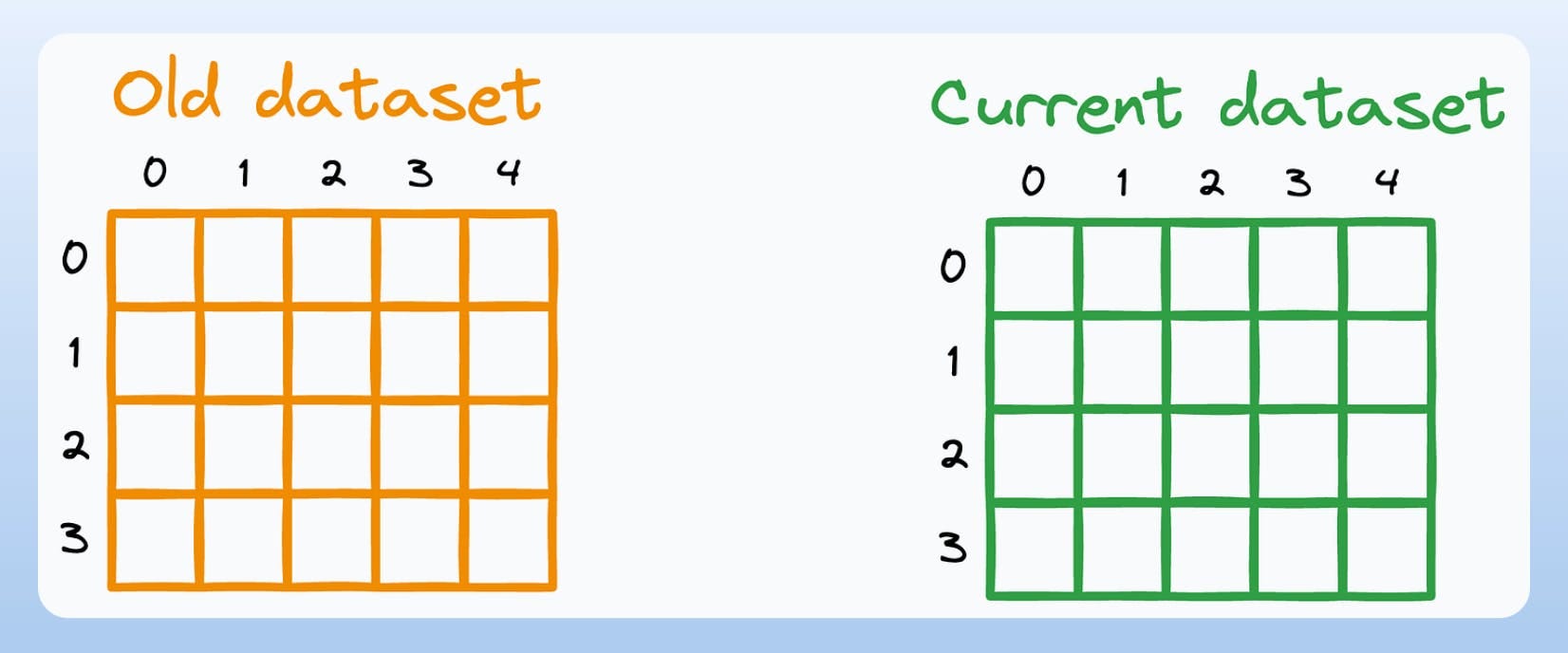
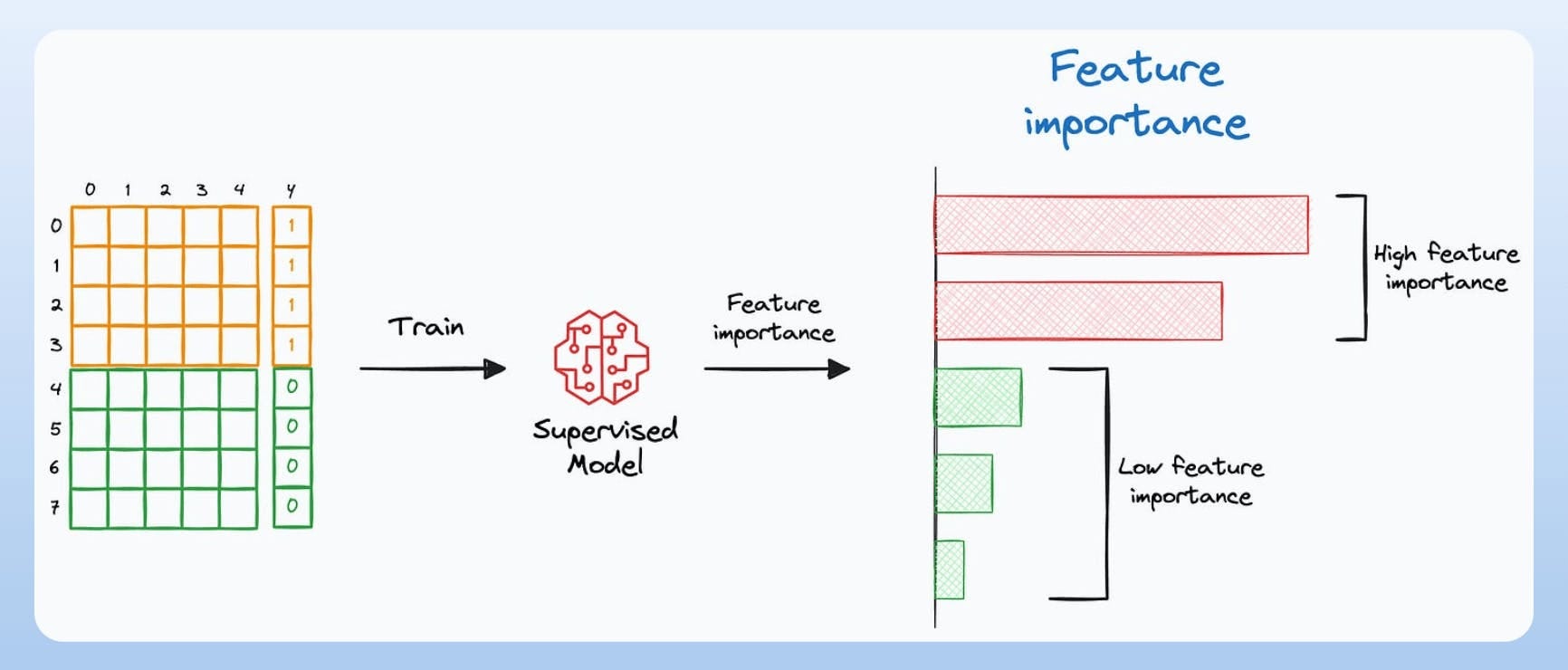
Step 1) Consider two versions of the dataset—the old version (one on which the model was trained) and the current version (one on which the model is generating predictions):
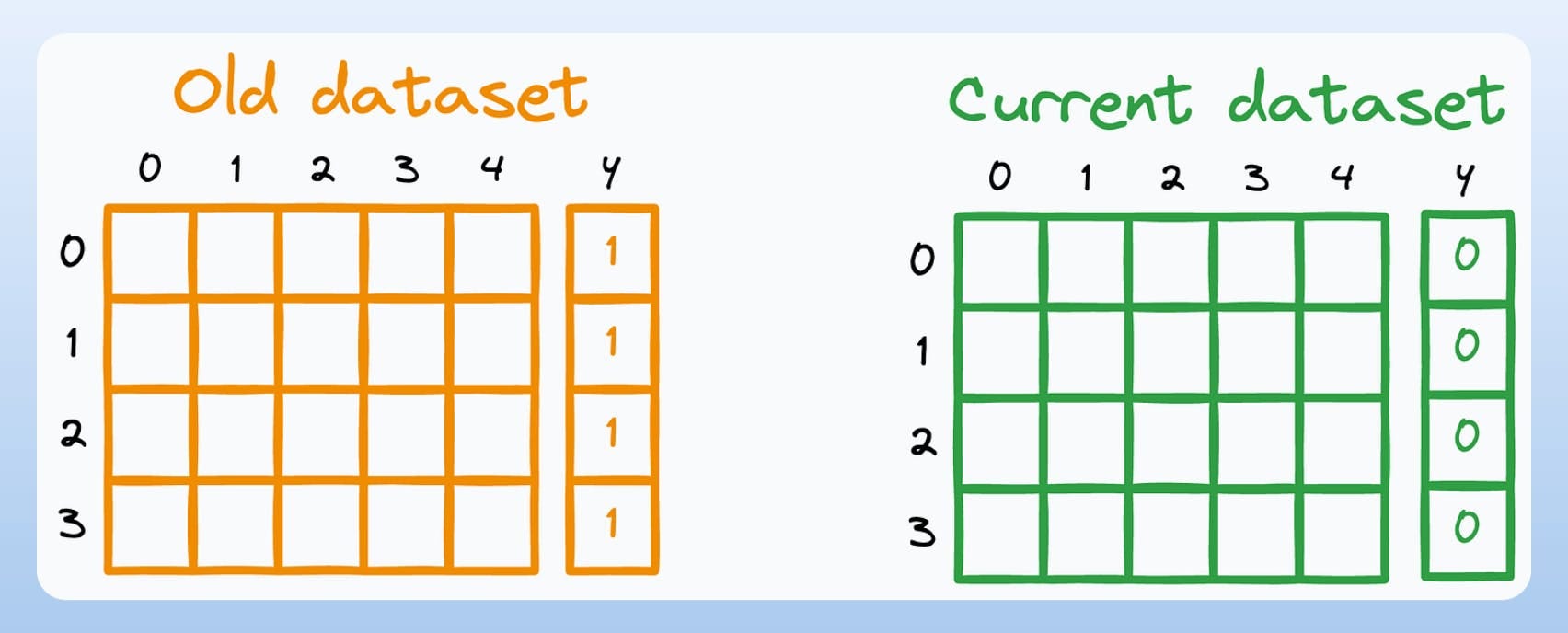
Step 2) Append a
label=1column to the old dataset andlabel=0column to the current dataset.
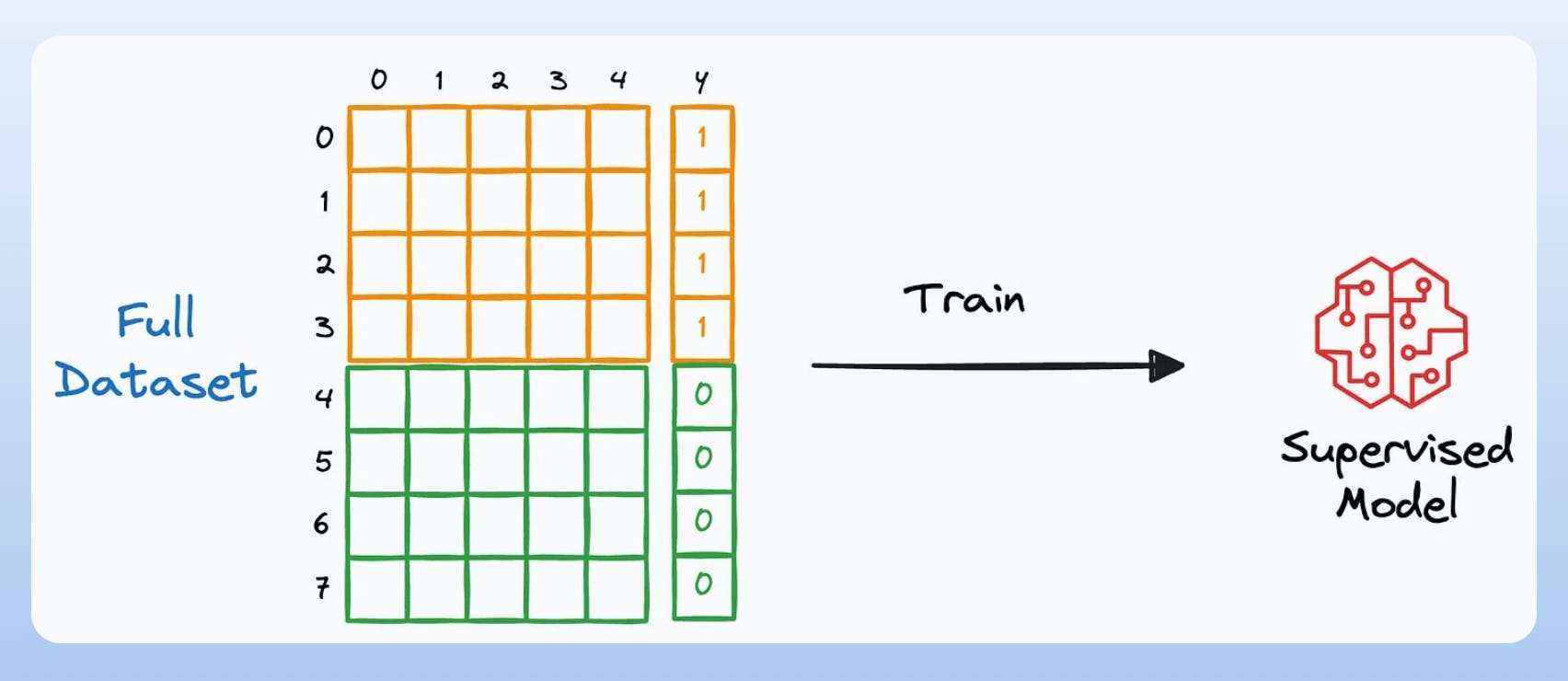
Step 3) Now, train a supervised learning classification model on the combined dataset that predicts the appended column:
Step 4) Measure feature importance
The choice of the classification model could be arbitrary, but you should be able to determine feature importance.
Thus, I personally prefer a random forest classifier because it has an inherent mechanism to determine feature importance:
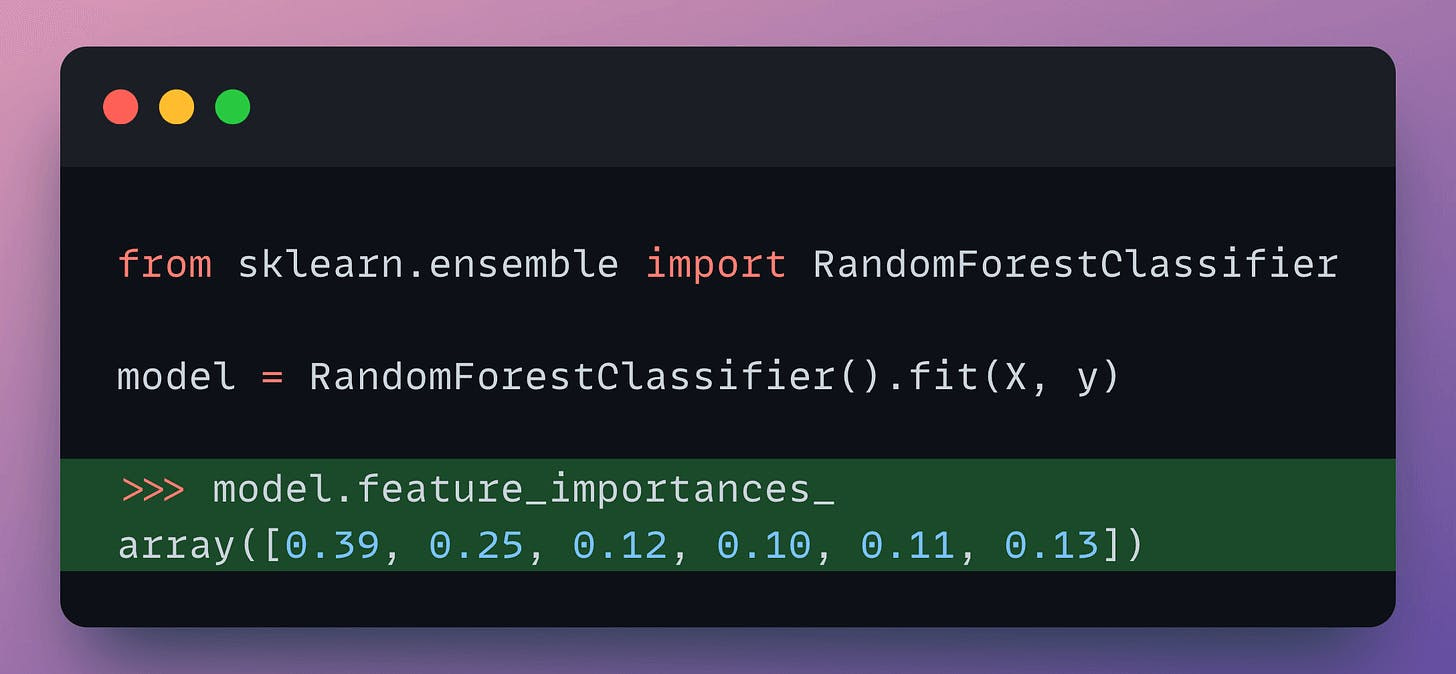
That said, it is not necessary to use a random forest.
Techniques like shuffle feature importance (which we discussed here) illustrated below can be used as well on typical classification models:
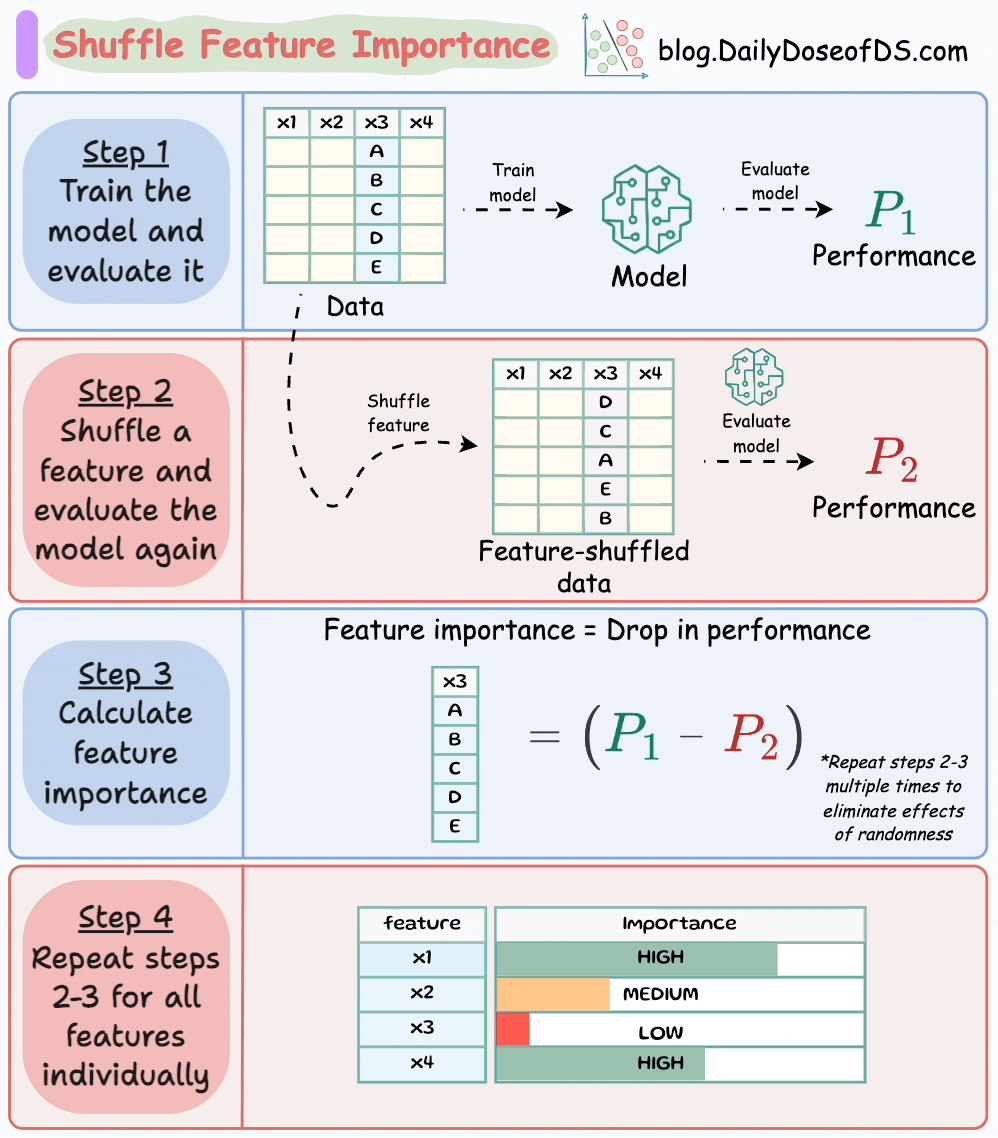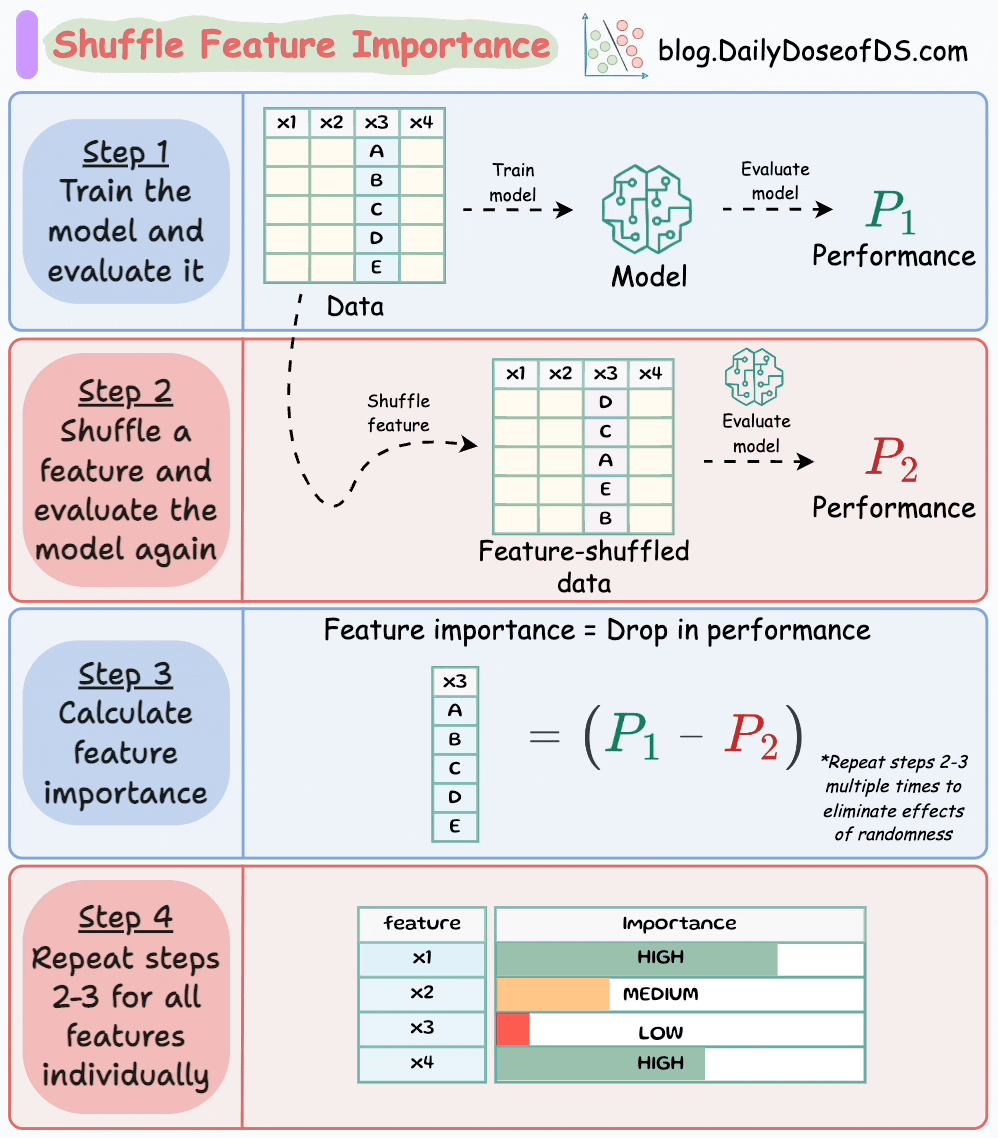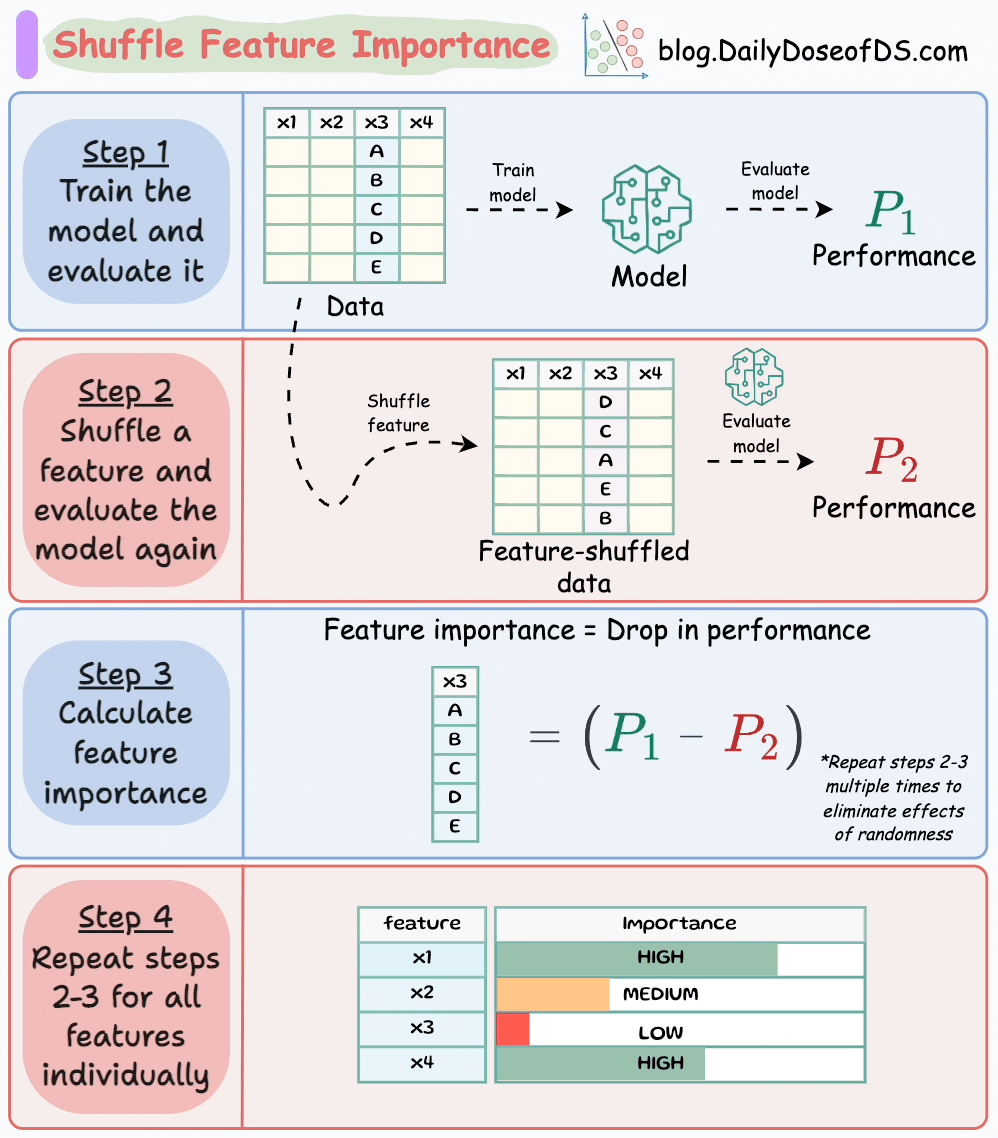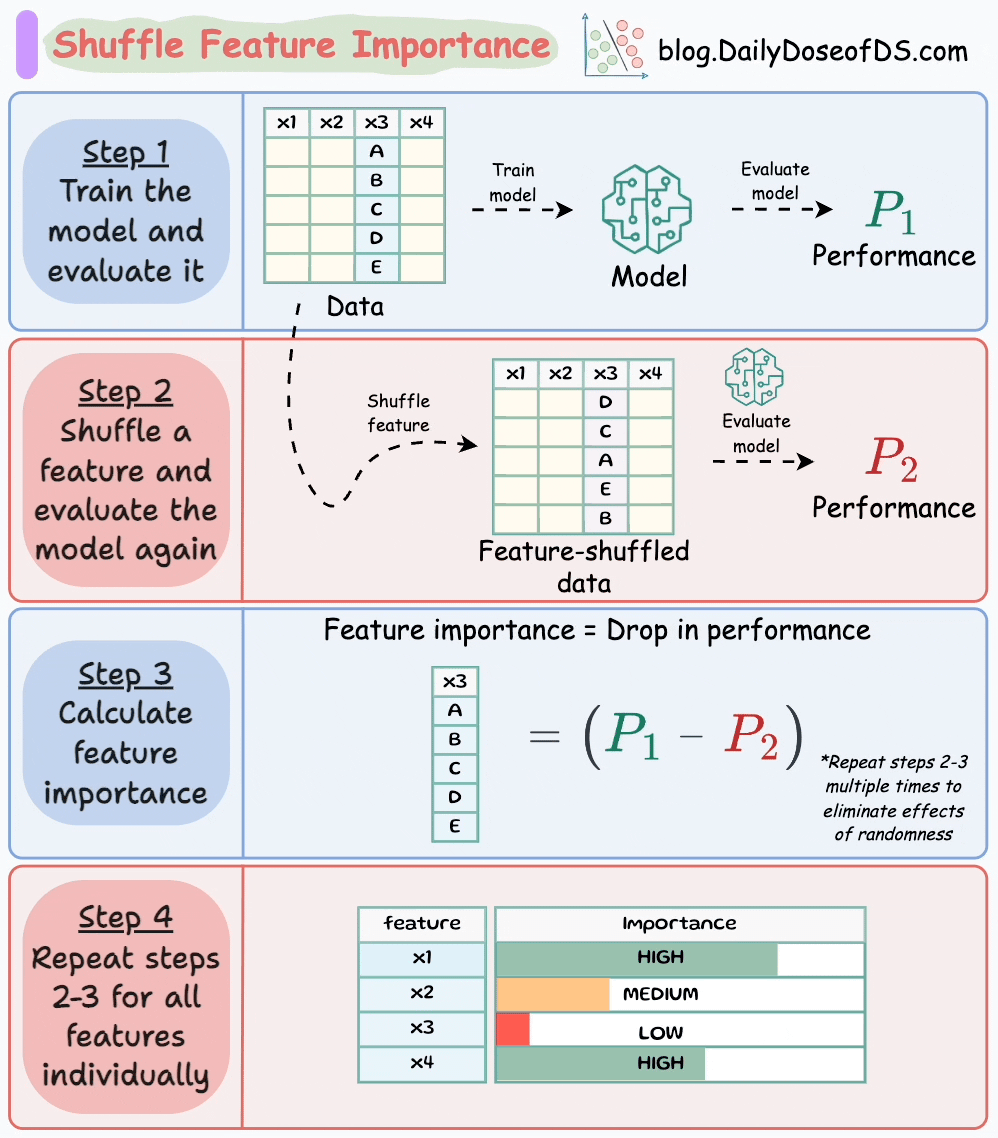
Moving on…
If the feature importance values suggest that there are features with high feature importance, this means that those features have drifted.
Why?
This is because if some features can reliably distinguish between the two versions of the dataset, then it is pretty likely that their distribution corresponding to label=1 and label=0 (conditional distribution) are varying.
If there are distributional differences, the model will capture them.
If there are no distributional differences, the model will struggle to distinguish between the classes.
This idea makes intuitive sense as well.
Of course, this is not the only technique to determine drift.
Autoencoders can also help. We discussed them here in a recent newsletter issue.
👉 Over to you: What are some other ways you use to determine drift?
P.S. For those wanting to develop “Industry ML” expertise:

We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn how to build real-world RAG apps, evaluate, and scale them: A crash course on building RAG systems—Part 3 (With Implementation).
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality.
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 110,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.