
Identify Fuzzy Duplicates at Scale
A clever technique to optimize the deduplication algorithm.

Announcement
Starting tomorrow, we won’t be publishing new issues on Sundays. Every week, you’ll hear from us 6 days a week—Monday to Saturday.
Let’s get to today’s post now.
Identify Fuzzy Duplicates
Data duplication is a big problem that many organizations face.
Methods like df.drop_duplicates() in Pandas work well when you have exact duplicates.

But what if the data has fuzzy duplicates?
Fuzzy duplicates are those records that are not exact copies of each other, but somehow, they appear to be the same. This is shown below:

The Pandas method will be ineffective since it will only remove exact duplicates.
So what can we do here?
A naive solution
Let’s imagine that your data has over a million records.
One way could be to naively compare every pair of records, as depicted below:

We can formulate a distance metric for each field and generate a similarity score for each pair of records.
But this approach is infeasible at scale.
For instance, on a dataset with just a million records, comparing every pair of records will result in 10^12 comparisons (n^2).
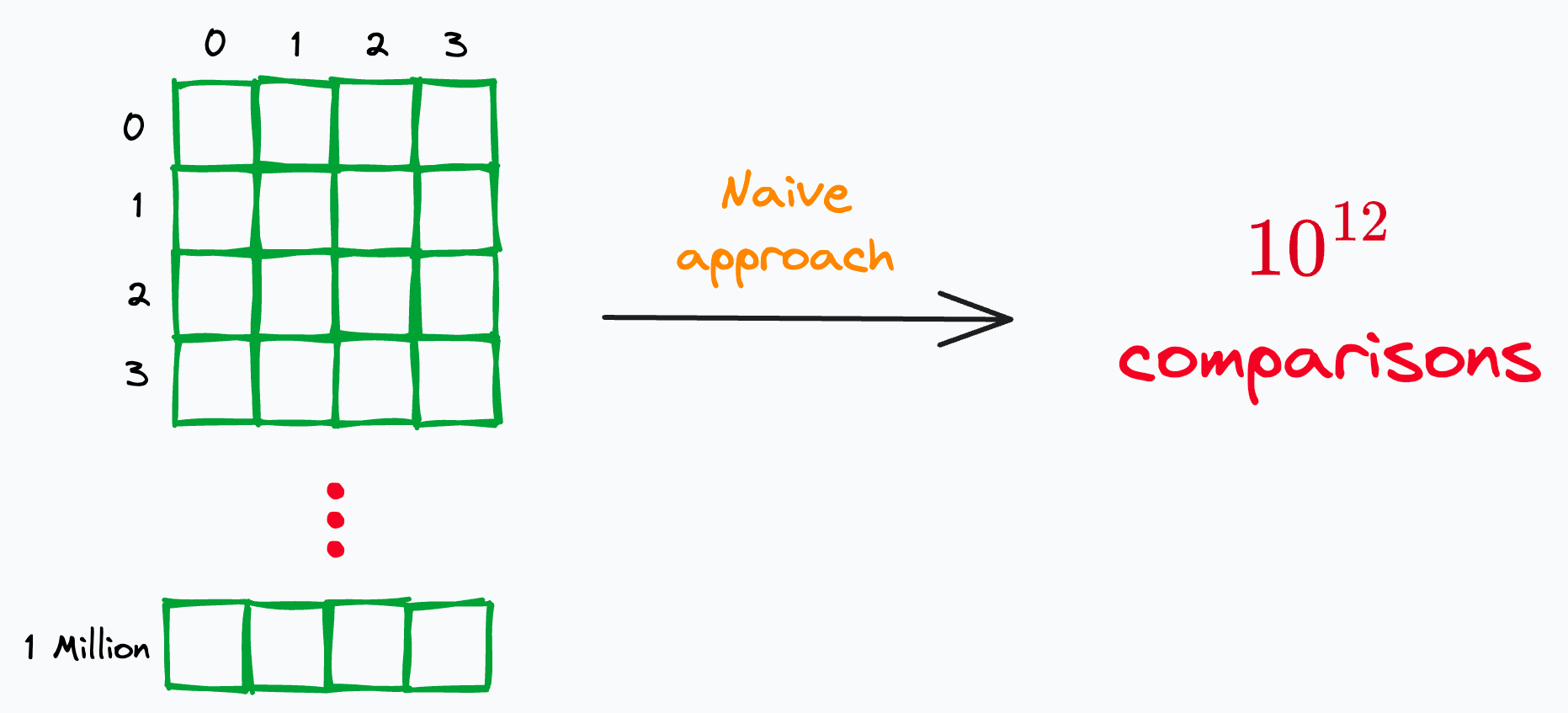
Even if we assume a decent speed of 10,000 comparisons per second, this approach will take ~3 years to complete.
Can we do better?
A special property of duplicates
If two records are duplicates, they will certainly possess some lexical (or textual) overlap.
For instance, consider the dataset below:

Here, comparing the name “Daniel” to “Philip” or “Shannon” to “Julia” makes no sense since There is literally no lexical overlap.
Thus, they are guaranteed to be distinct records.
Yet, the naive approach will still compare them.
We can utilize this “lexical overlap” property of duplicates to cleverly reduce the total comparisons.
Bucketing duplicates
Segregating the data into smaller buckets by applying some rules can help.
For instance, consider the above dataset again. One rule could be to create buckets based on the first three letters of the first name.

Thus, we will only compare two records if they are in the same bucket.
If the first three letters are different, the records will fall into different buckets. Thus, they won’t be compared at all.
After segregating the records, we would have eliminated almost 98-99% of unnecessary comparisons that would have happened otherwise.
The figure “98-99%” comes from my practical experience on solving this problem on a dataset of such massive size.
Finally, we can use our naive comparison algorithm on each individual bucket.

In fact, once the data has been bucketed, you can also build an LLM-driven approach.
The optimized approach can run in just a few hours instead of taking years.
This way, we can drastically reduce the run time and still achieve great deduplication accuracy.
Of course, we would have to analyze the data thoroughly to come up with the above data split rules.
But what is a more wise thing to do:
Using the naive approach, which takes three years to run, OR,
Spending some time analyzing the data, devising rules, and running the deduplication approach in a few hours?
That said, duplicate detection engines are also needed in NLP systems, which assess whether two contexts convey the same meaning.
This is especially observed in community-driven platforms (Stackoverflow, Medium, Quora, etc.). For instance, Quora shows you questions related to the question you are reading answers for.
Pairwise context similarity scoring is a fundamental building block in several NLP applications, not just duplicate detection—RAGs, for instance.
We recently released a 2-part series on this.
It goes through the entire background in a beginner-friendly way, the challenges with traditional approaches, optimal approaches, and implementations.
Read part 1 here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Read part 2 here: AugSBERT: Bi-encoders + Cross-encoders for Sentence Pair Similarity Scoring – Part 2.
👉 Over to you: Can you further optimize the fuzzy duplicate detection approach?
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 105,000+ data scientists and machine learning professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience
Great idea.