
Implement "Attention is all you need"
...from scratch using PyTorch.

10x faster scraping with Firecrawl v2
Firecrawl’s latest v2 endpoint now provides 10x faster scraping, semantic crawling, news & image search, and much more.
In the snippet below, we scraped images from the web related to Penguins:

This is new since scraping is usually limited to just text-based scraping.
You can use it to:
Get specific multimodal data and fine-tune LLMs.
Build computer vision datasets for several tasks.
Scrape news/event photos for media monitoring, etc.
Thanks to Firecrawl for partnering today!
Implement "Attention is all you need"
This is the paper that revolutionized AI!
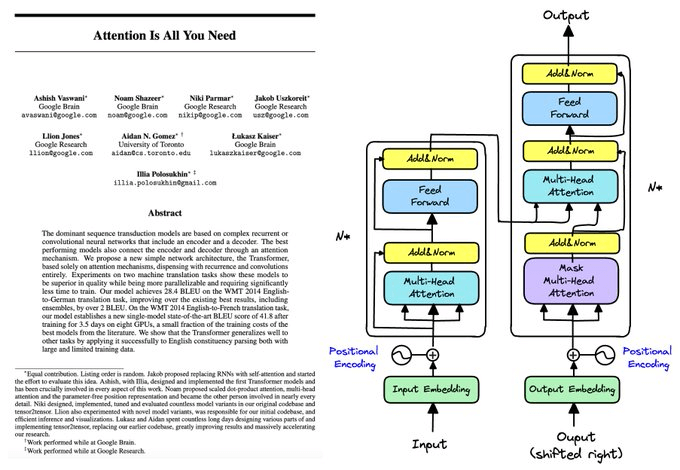
Today, let’s implement:
The complete Transformer architecture
Multi-Head Attention mechanism
Encoder-Decoder structure
Positional Encoding
Everything in clean, educational Python code!
This activity will help you understand the internal intricacies of the architecture.
We implemented Llama 4 from scratch, which is a mixture of experts, in this article →
It covered:
Character-level tokenization,
Multi-head self-attention with rotary positional embeddings (RoPE),
Sparse routing with multiple expert MLPs,
RMSNorm, residuals, and causal masking,
And finally, training and generation.
Let’s dive in!
Here's the full Transformer model that we'll build piece by piece!
Notice the key components:
Encoder & Decoder stacks
Multi-head attention layers
Position-wise feed-forward networks
Positional encoding
Now let's break it down!
1️⃣ The Two Main Components:
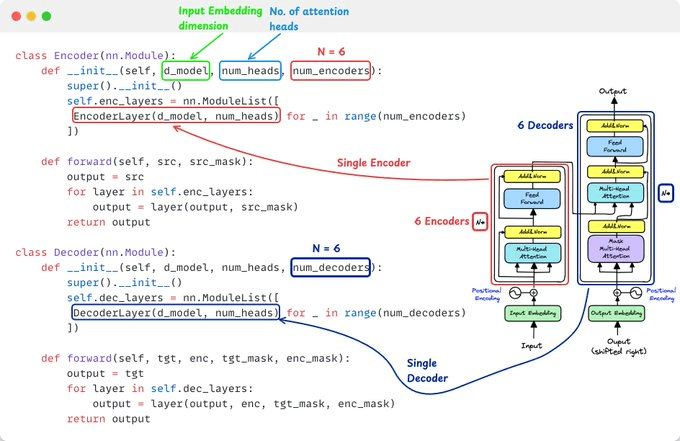
Encoder: Processes the input sequence (e.g., English sentence)
Decoder: Generates the output sequence (e.g., Spanish translation)
The architecture has 6 identical blocks of each.
Next, we implement the individual encoder/decoder block...
2️⃣ Encoder Layer: Self-Attention + FFN
Each encoder layer has two sub-layers:
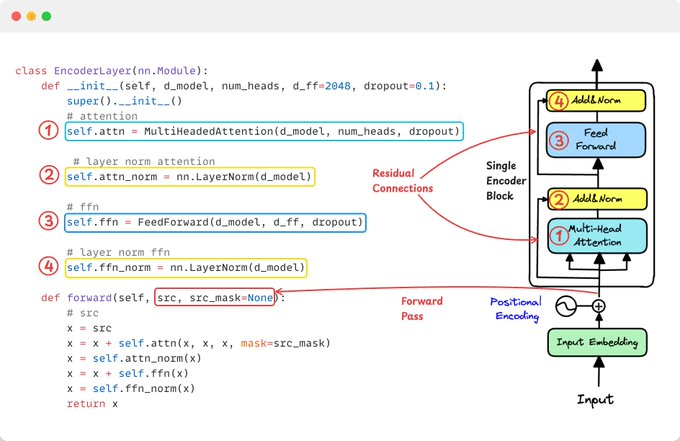
Multi-head self-attention (looks at input sequence)
Position-wise feed-forward network
…with residual connections and layer normalization around each.
3️⃣ Decoder Layer:
Decoder layers have three sub-layers:
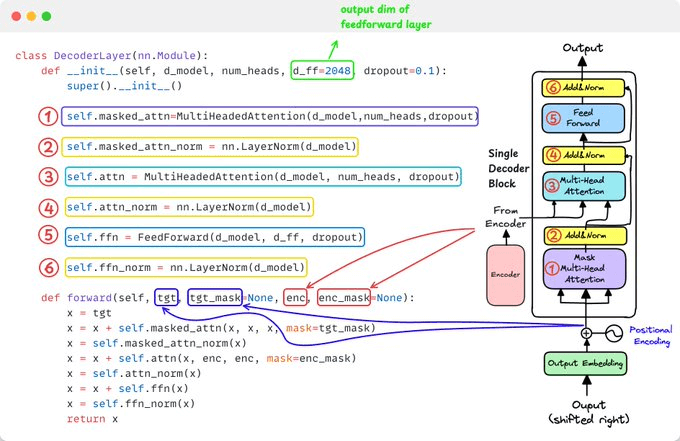
Masked self-attention (can't see future tokens)
Encoder-decoder attention (cross-attention with encoder)
Position-wise feed-forward network
This is where generation happens!
With the encoder and decoder set, let's explore their sublayers, starting with Multi-Head Attention blocks.
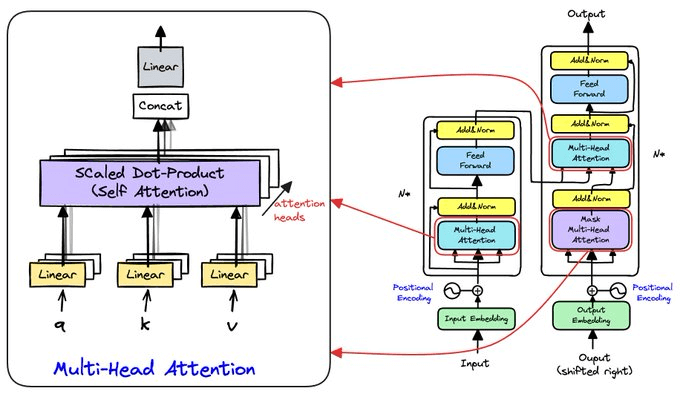
As depicted above, these have parallel attention heads, with the number of heads as a hyperparameter.
On the left is a zoomed-in view of the multi-head attention block.
4️⃣ Multi-Head Attention: Parallel Processing
More heads mean more parameters and greater flexibility to learn patterns:
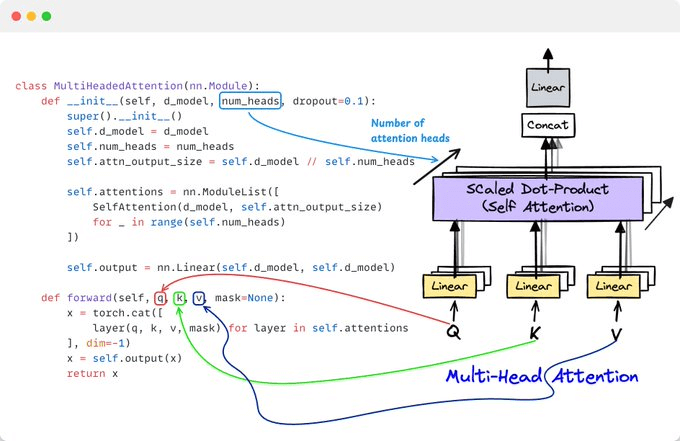
Head 1: Subject-verb relationships
Head 2: Adjective-noun relationships
Head 3: Long-range dependencies
…then concatenate all outputs!
5️⃣ The Heart: Self-attention
This is THE key highlight of this architecture!
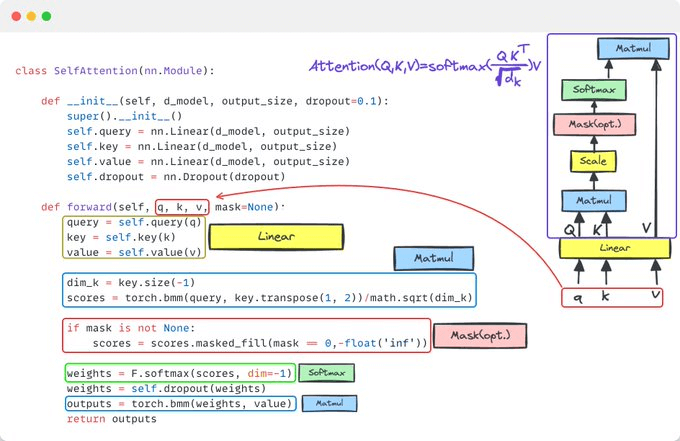
The famous formula: Attention(Q,K,V) = softmax(QK^T / √d_k)V
Q (Query): "What am I looking for?"
K (Key): "What information is available?"
V (Value): "What information to return?"
6️⃣ Feed-Forward Networks
After attention, each position gets processed independently!
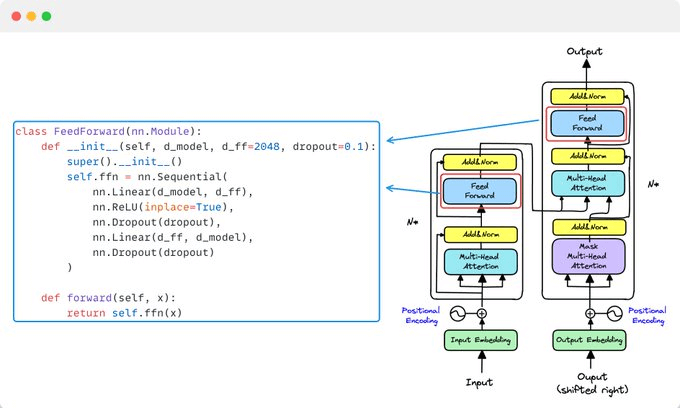
FFN(x) = max(0, xW₁ + b₁)W₂ + b₂
Simple but powerful:
Linear transformation → ReLU → Linear transformation
7️⃣ Positional Encoding: Teaching Position
Since attention has no inherent sense of order, we need to inject position information!
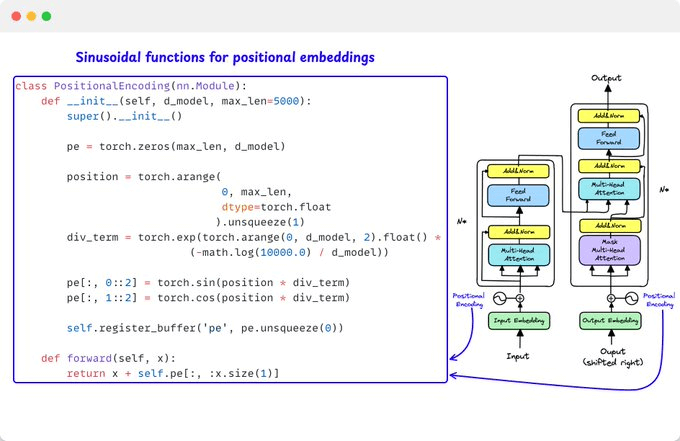
It's done using sinusoidal functions, which creates unique patterns for each position!
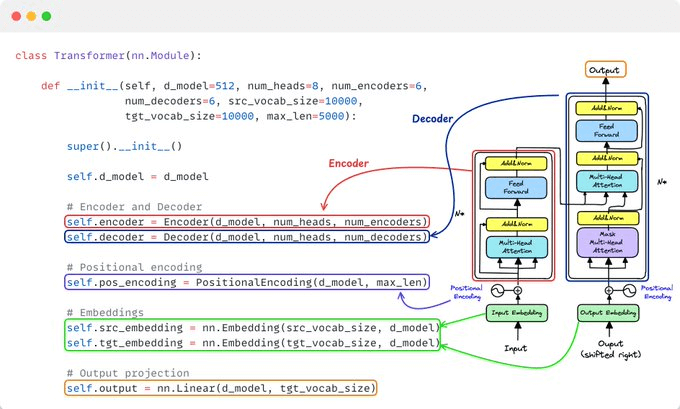
Finally, we bring all of this together in the forward pass of our transformer.
This is the forward pass of the main Transformer class we defined earlier.
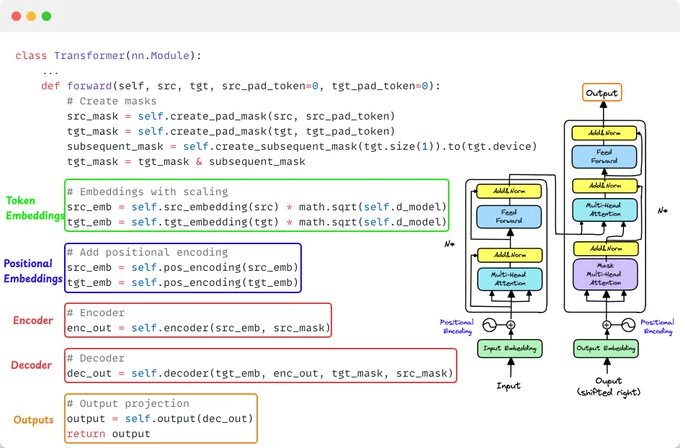
The original paper tackled sequence-to-sequence translation like:
English ↔ Spanish translation
English ↔ German translation
Let's briefly look at how it works during training and inference phases.
8️⃣ Training
For English↔Spanish translation:
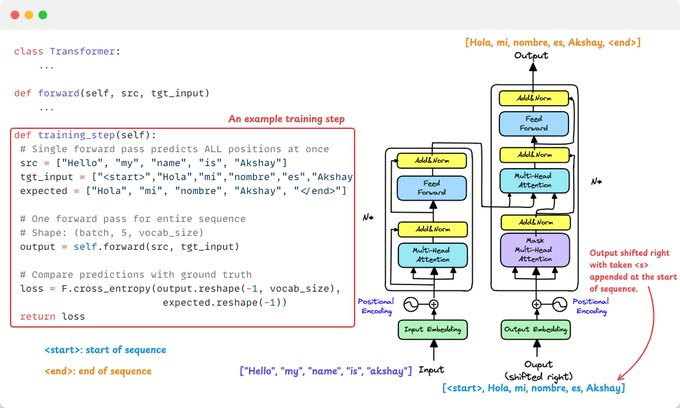
Encoder encodes the English sentence.
Decoder gets the Spanish target shifted right (teacher forcing).
Predictions are compared to the true Spanish output with cross-entropy loss.
Here’s why we shift right:
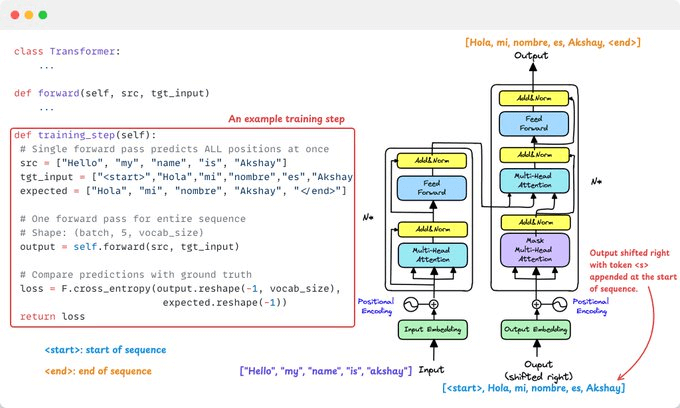
Shifting right feeds the decoder the previous correct token (e.g., <start> + target[:-1]) to focus on history for next-token prediction.
This allows autoregressive modeling by predicting the next token using all prior ones while training all positions in parallel using masking.
9️⃣ Inference: Autoregressive Generation
During inference, we generate step-by-step (autoregressive)!
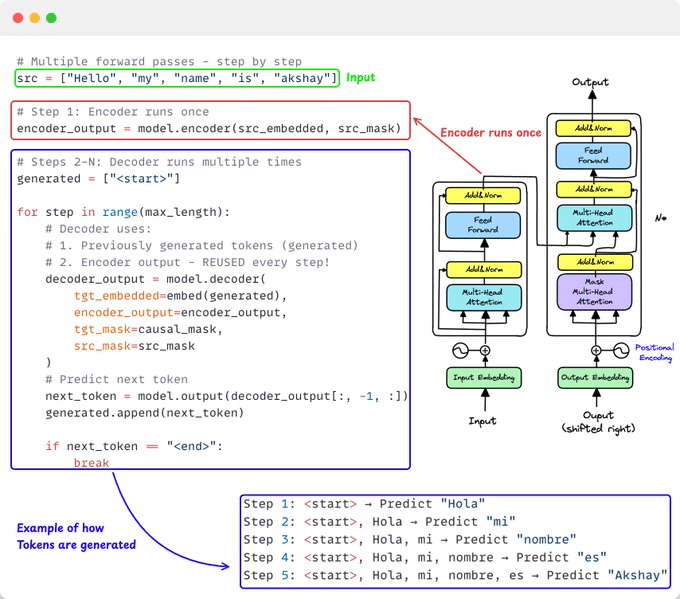
Encoder runs once, decoder runs multiple times:
Step 1: <start> → "Hola"
Step 2: <start>, Hola → "mi"
And so on...
Each step uses previous predictions!
And that is how you can implement this architecture from scratch.
Hope this helped you understand the architecture better.
Let us know by replying if you’d like to learn how other architectures, like diffusion models, are implemented.
We implemented Llama 4 from scratch, which is a mixture of experts, in this article →
It covered:
Character-level tokenization,
Multi-head self-attention with rotary positional embeddings (RoPE),
Sparse routing with multiple expert MLPs,
RMSNorm, residuals, and causal masking,
And finally, training and generation.
Thanks for reading!
Nice post! A fast overview, but clearly written.