
Implement Knowledge Distillation from Scratch
(must-know to efficiently run ML models in production)

Automated release docs for engineering teams
Doc Holiday solves one of engineering’s most persistent problems: knowledge degeneration.
Every time code ships, the gap between what the product does and what the rest of the company knows widens. Documentation is usually the first thing to fall behind. The support team spends the next sprint answering questions that the last release already answered.
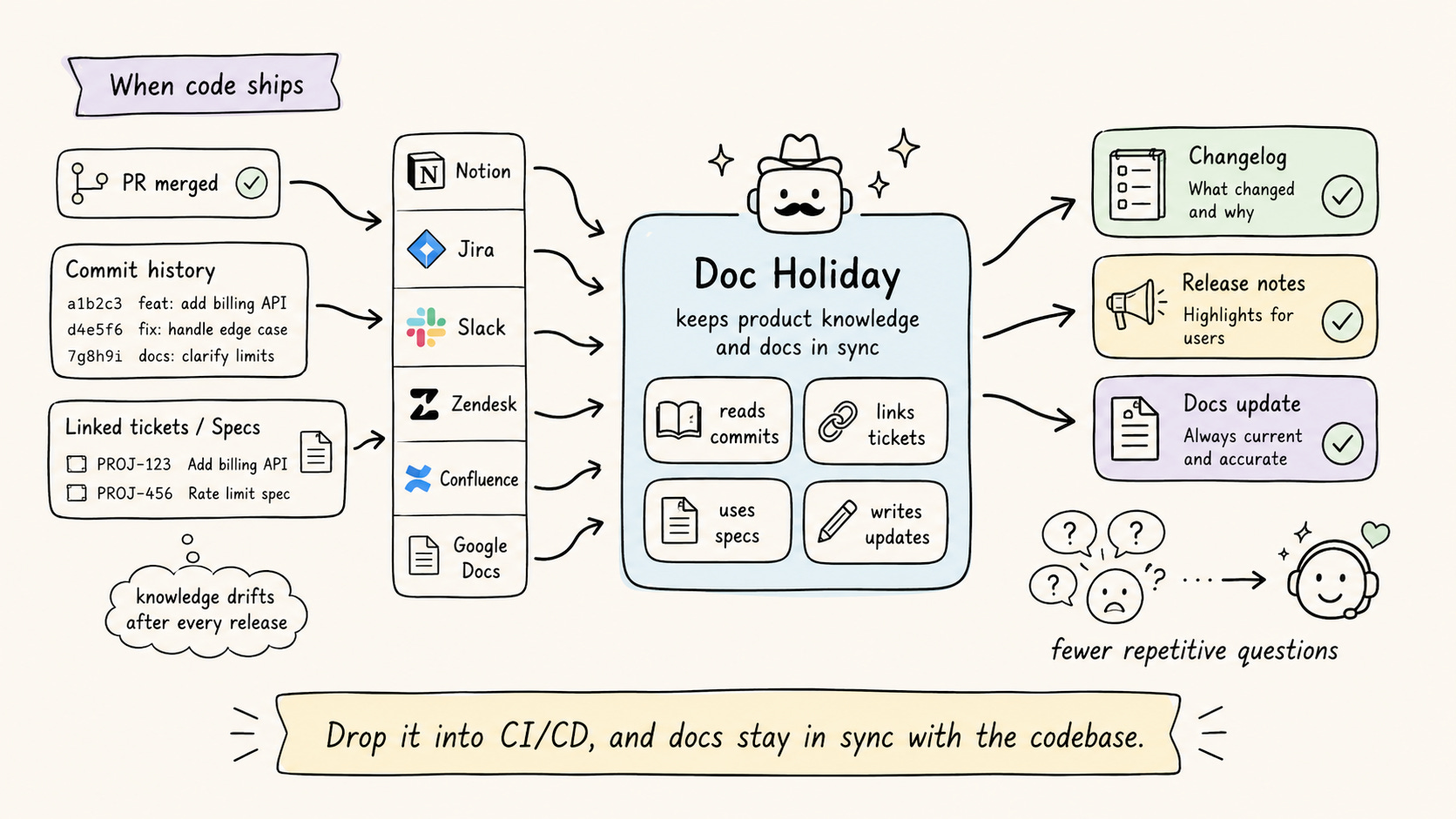
Drop it into your CI/CD pipeline and connect any upstream source, like Notion, Jira, Slack, Zendesk, Confluence, or Google Docs.
When a PR merges, it reads the commit history, linked tickets, and connected specs, then generates the changelog, release notes, and documentation updates automatically.
It keeps documentation in sync with the codebase without adding a step to the release process.
Get started with Doc Holiday here→
Thanks to Doc Holiday for partnering today!
Implement knowledge distillation from scratch.
Model performance is rarely the only factor in determining which model will be deployed.
This is because we also consider several operational metrics, such as:

Inference Latency: Time taken by the model to return a prediction.
Model size: The memory occupied by the model.
Ease of scalability, etc.
Knowledge distillation is a common technique to compress ML models before deployment.
Let’s learn how to implement it!
We implemented 5 more techniques to compress ML models and reduce costs here: Model Compression: A Critical Step Towards Efficient Machine Learning.
What is knowledge distillation?
In a gist, the idea is to train a smaller/simpler model (called the “student” model) that mimics the behavior of a larger/complex model (called the “teacher” model).

This involves two steps:
Train the teacher model as we typically would.
Train a student model that matches the output of the teacher model (there are some other types of knowledge distillation techniques as well).

DistillBERT, for instance, is a student model of BERT.
DistilBERT is approximately 40% smaller than BERT.
But it retains approximately 97% of the BERT’s capabilities.
Next, let’s look at the implementation.
Knowledge distillation implementation
Imagine we have already trained a CNN model on the MNIST dataset:

Its epoch-by-epoch training loss and validation accuracy are depicted below:

Let’s define a simpler model without any convolutional layers:

Since it’s a classification model, it will output a probability distribution over the <N> classes.
Thus, we can train the student to match the probability distribution of the teacher on all samples.
KL divergence (also used to train tSNE) can be used as a loss function.
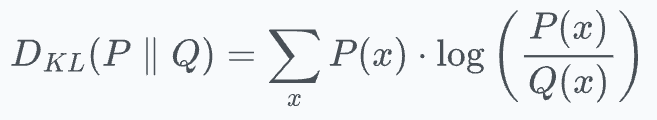
It measures how much information is lost when we use distribution Q to approximate the distribution P.
Thus, in our case:
P→ probability distribution from teacher.Q→ probability distribution from student.
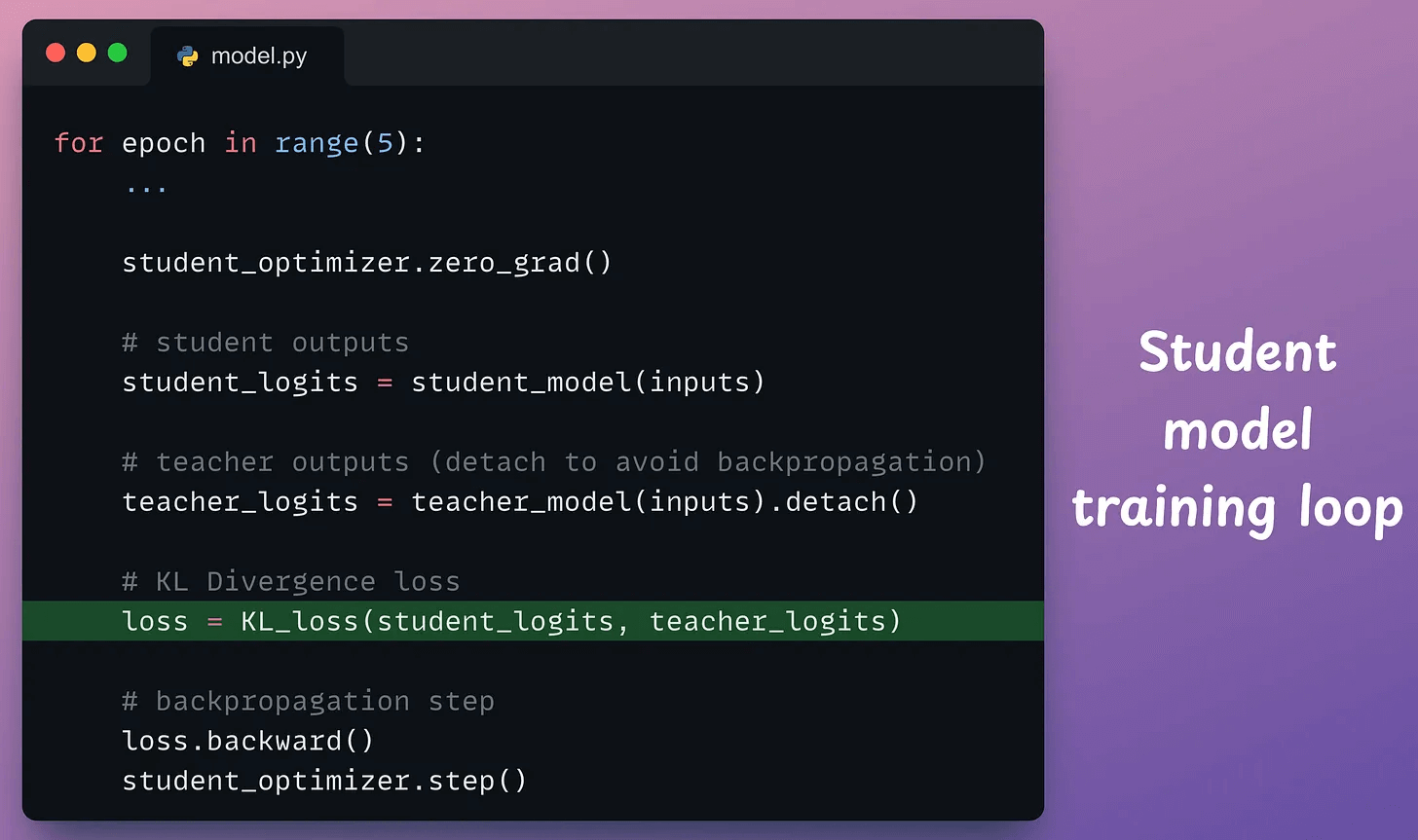
The loss function is implemented below:

Finally, we train the student model:
The following image compares the training loss and validation accuracy of the two models:

The performance of the student model is not as good as the teacher model, which is expected.
However, it is still promising since it’s a simple feed-forward network.
Also, the student model is 35% faster than the teacher model, which is a significant increase in the inference run-time of the model for a 1-2% drop in the performance.

That said, one downside of knowledge distillation is that one must still train a larger teacher model first to train the student model.
This may not be feasible in a resource-constrained environment.
Today, we only covered knowledge distillation.
We implemented 5 more techniques to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
👉 Over to you: What are some other ways to build cost-effective models?
Thanks for reading!