
Implementing DoRA (an Improved LoRA) from Scratch
Full breakdown with code.

We have covered several LLM fine-tuning approaches before.
Today, we are continuing that by discussing DoRA, yet another promising and state-of-the-art technique that improves LoRA and other similar fine-tuning techniques.
Read it here: Implementing DoRA (an Improved LoRA) from Scratch.
These results show that even with a reduced rank (e.g., halving the LoRA rank), DoRA significantly outperforms LoRA:

Why care?
Traditional fine-tuning is practically infeasible with LLMs.
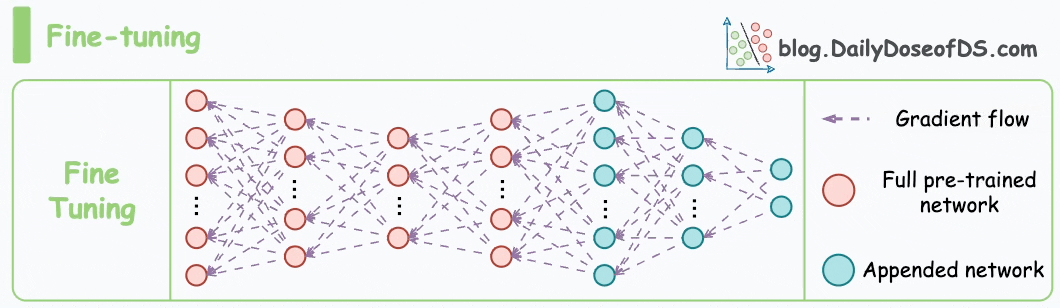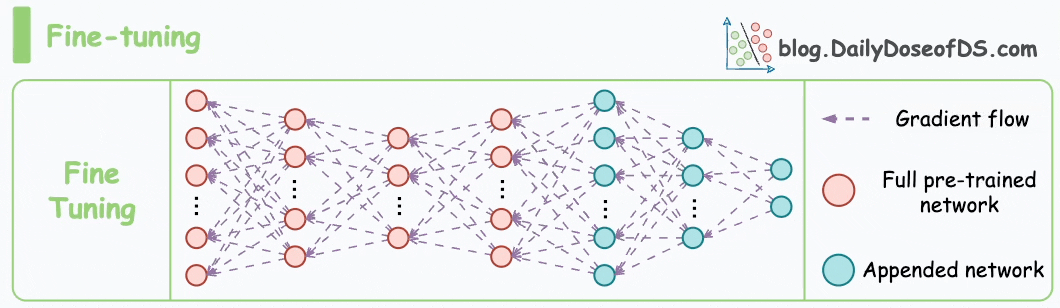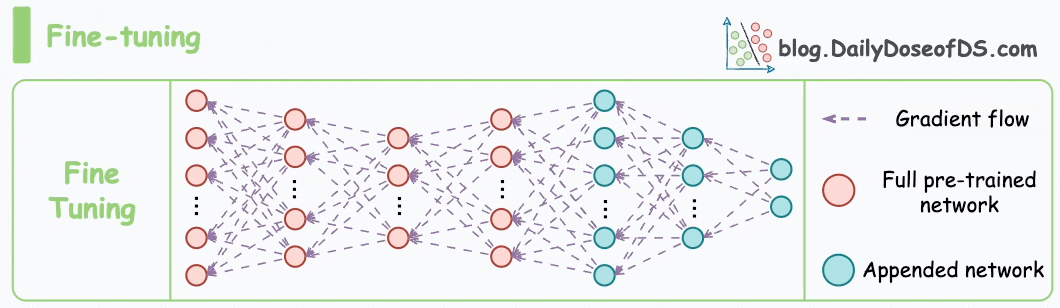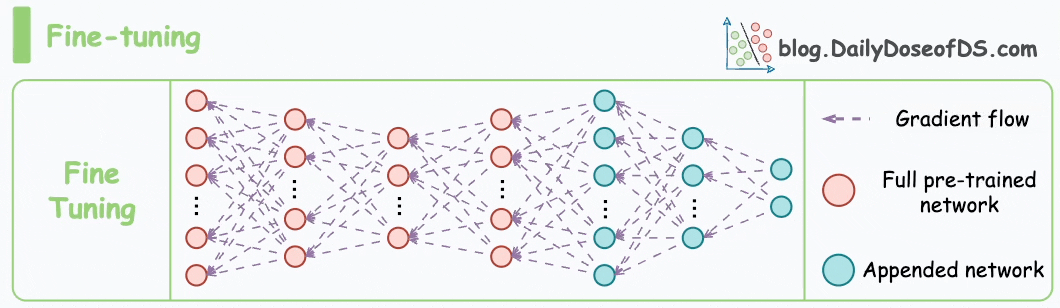
To understand, consider this:
GPT-3, which has 175B parameters. That's 350GB of memory just to store model weights under float16 precision.
This means that if OpenAI used traditional fine-tuning within its fine-tuning API, it would have to maintain one model copy per user:
If 10 users fine-tuned GPT-3 → they need 3500 GB to store model weights.
If 1000 users fine-tuned GPT-3 → they need 350k GB to store model weights.
If 100k users fine-tuned GPT-3 → they need 35 million GB to store model weights.
And the problems don't end there:
OpenAI bills solely based on usage. What if someone fine-tunes the model for fun or learning purposes but never uses it?
Since a request can come anytime, should they always keep the fine-tuned model loaded in memory? Wouldn't that waste resources since several models may never be used?
Techniques like LoRA (and other variants) solved this key business problem.
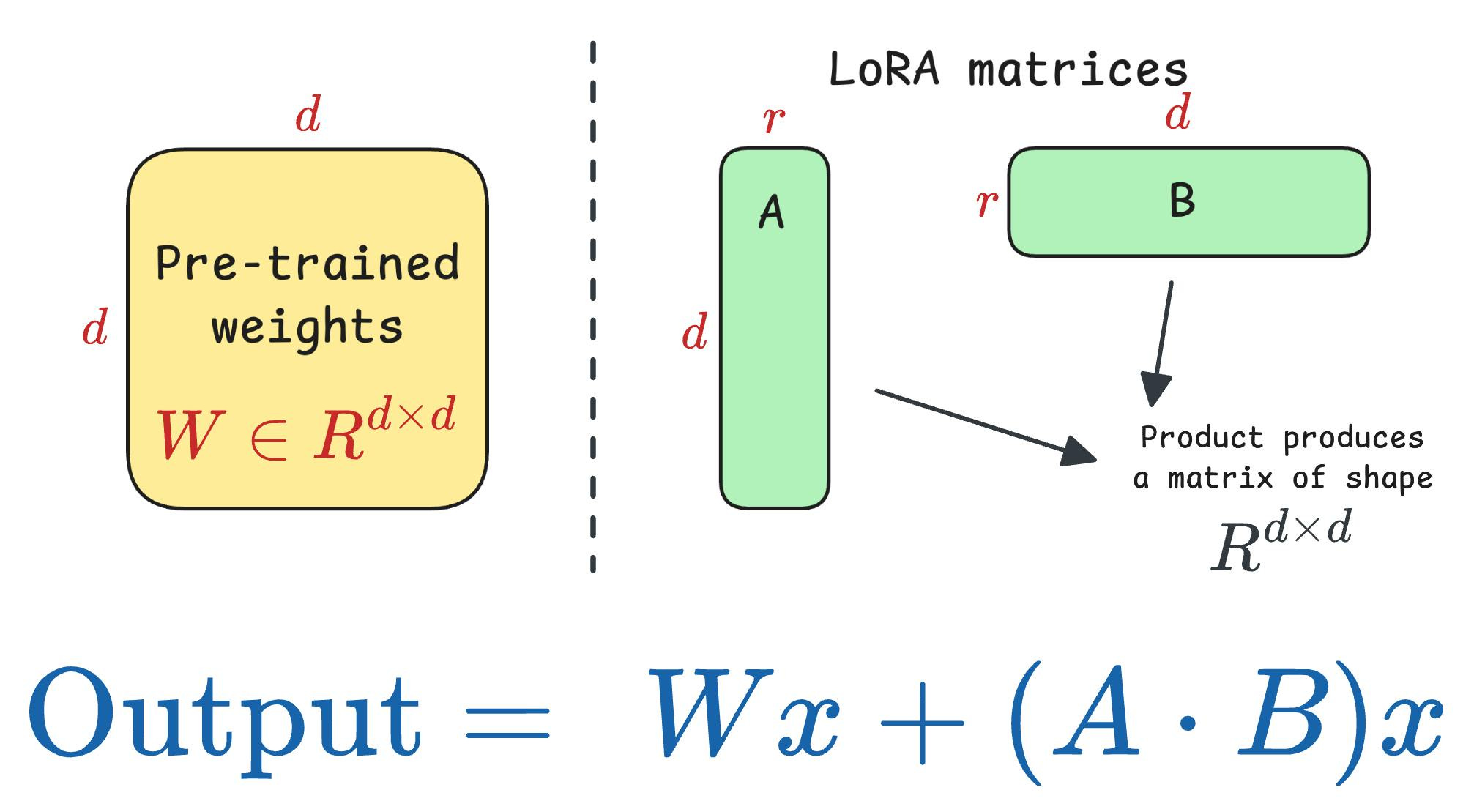
DoRA further optimized this.
So, in the latest article, we are doing an algorithmic breakdown of how DoRA works and observations from LoRA that led to its development.
We also implement it from scratch in PyTorch to help you build an intuitive understanding.
RAG is powerful, but not always ideal if you want to augment LLMs with more information.
Several industry use cases heavily rely on efficient LLM fine-tuning, which you must be aware of in addition to building robust RAG solutions.
Start here: Implementing DoRA (an Improved LoRA) from Scratch.
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.