
Implementing Knowledge Distillation From Scratch
...to compress ML models.

Augment Code: AI Assistant for Real Developer Work
Most AI coding tools are useless.
They only work with small functions or boilerplate code.
But what about the real work—refactoring legacy code, navigating complex repos, or making multi-file changes?

Augment Code is a powerful AI Assistant that’s truly built for developers working with large, evolving codebases—needing an assistant that understands the full context of their projects.
Key features:
Understands your entire codebase—Feels like you’re pairing with a principal engineer who knows your repo inside out.
Works inside your tools—Full support for VSCode, JetBrains, Vim, GitHub, and Slack.
More than autocomplete—AI-powered chat, refactoring, debugging, and multi-file edits.
Here is the full product review guide to learn more.
You can test Augment Code with a free 30-day trial to see its real AI-powered coding capabilities.
Thanks to Augment Code for partnering today!
Implementing Knowledge Distillation
Model performance is rarely the only factor in determining which model will be deployed.
This is because we also consider several operational metrics, such as:

Inference Latency: Time taken by the model to return a prediction.
Model size: The memory occupied by the model.
Ease of scalability, etc.
Knowledge distillation is a common technique to compress ML models before deployment.
Let’s learn how to implement it!
We implemented 5 more techniques to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
What is knowledge distillation?
In a gist, the idea is to train a smaller/simpler model (called the “student” model) that mimics the behavior of a larger/complex model (called the “teacher” model).

This involves two steps:
Train the teacher model as we typically would.
Train a student model that matches the output of the teacher model (there are some other types of knowledge distillation techniques as well).

DistillBERT, for instance, is a student model of BERT.
DistilBERT is approximately 40% smaller than BERT.
But it retains approximately 97% of the BERT’s capabilities.
Next, let’s look at the implementation.
Knowledge distillation implementation
Imagine we have already trained a CNN model on the MNIST dataset:

Its epoch-by-epoch training loss and validation accuracy are depicted below:

Let’s define a simpler model without any convolutional layers:

Since it’s a classification model, it will ouput a probability distribution over the <N> classes.
Thus, we can train the student to match the probability distribution of the teacher on all samples.
KL divergence (also used to train tSNE) can be used as a loss function.
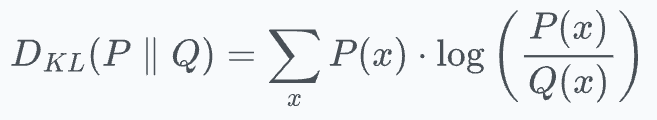
It measures how much information is lost when we use distribution Q to approximate the distribution P.
Thus, in our case:
P→ probability distribution from teacher.Q→ probability distribution from student.
The loss function is implemented below:

Finally, we train the student model:
The following image compares the training loss and validation accuracy of the two models:

The performance of the student model is not as good as the teacher model, which is expected.
However, it is still promising since it’s a simple feed-forward network.
Also, the student model is 35% faster than the teacher model, which is a significant increase in the inference run-time of the model for a 1-2% drop in the performance.

That said, one downside of knowledge distillation is that one must still train a larger teacher model first to train the student model.
This may not be feasible in a resource-constrained environment.
Today, we only covered knowledge distillation.
We implemented 5 more techniques to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
Here’s the code on GitHub: Knowledge distillation notebook.
👉 Over to you: What are some other ways to build cost-effective models?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.