
Implementing LLaMA 4 from Scratch
A line-by-line detailed explainer (with code).

Unlike previous generations, LLaMA 4 doesn’t rely solely on the classic Transformer architecture.
Instead, it uses a Mixture-of-Experts (MoE) approach, activating only a small subset of expert subnetworks per token.
We wrote a detailed 35-minute-long article that details the implementation of Llama 4 from scratch (with code) →
Here’s how Mixture-of-Experts (MoE) differs from a regular Transformer model:
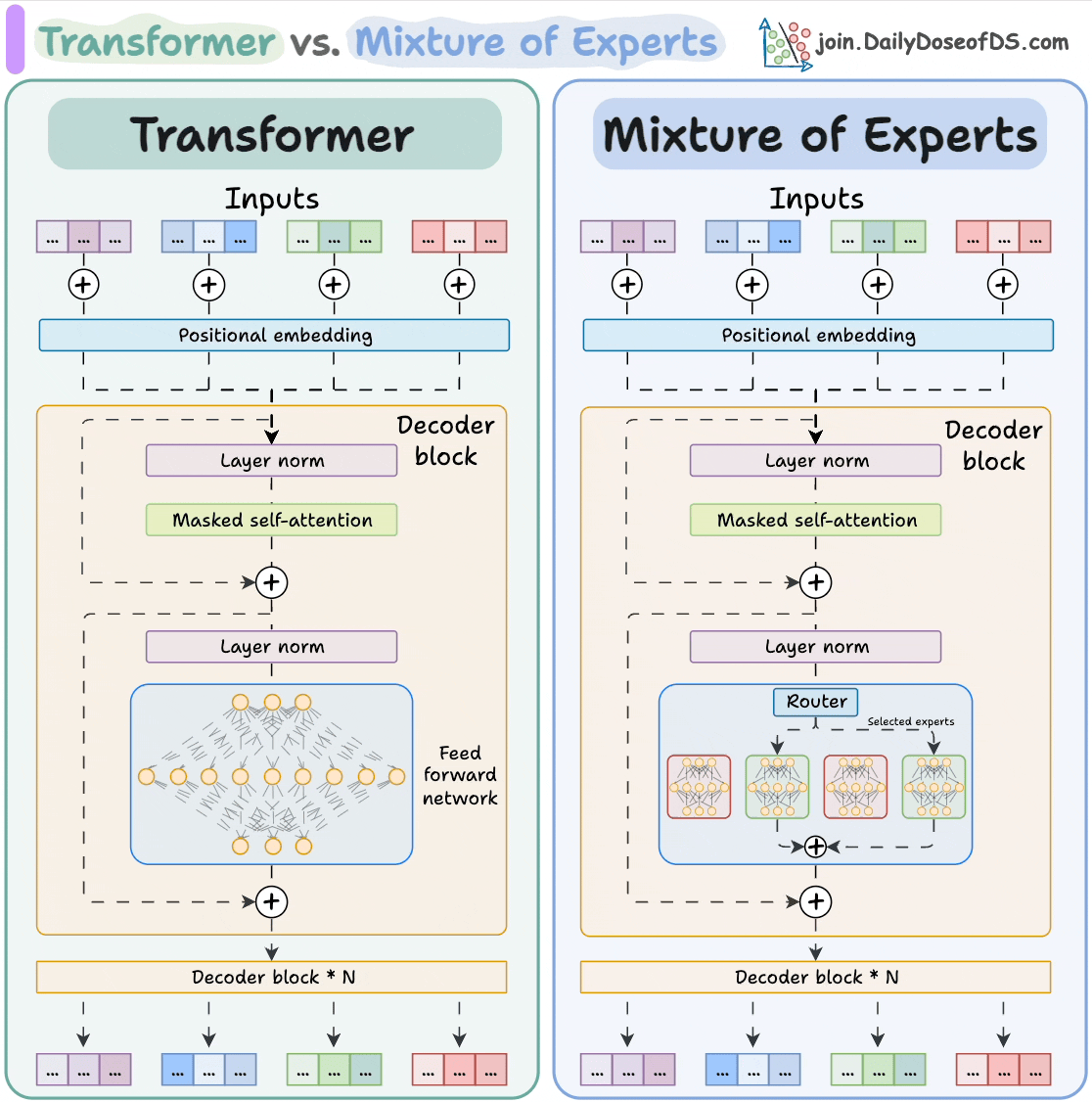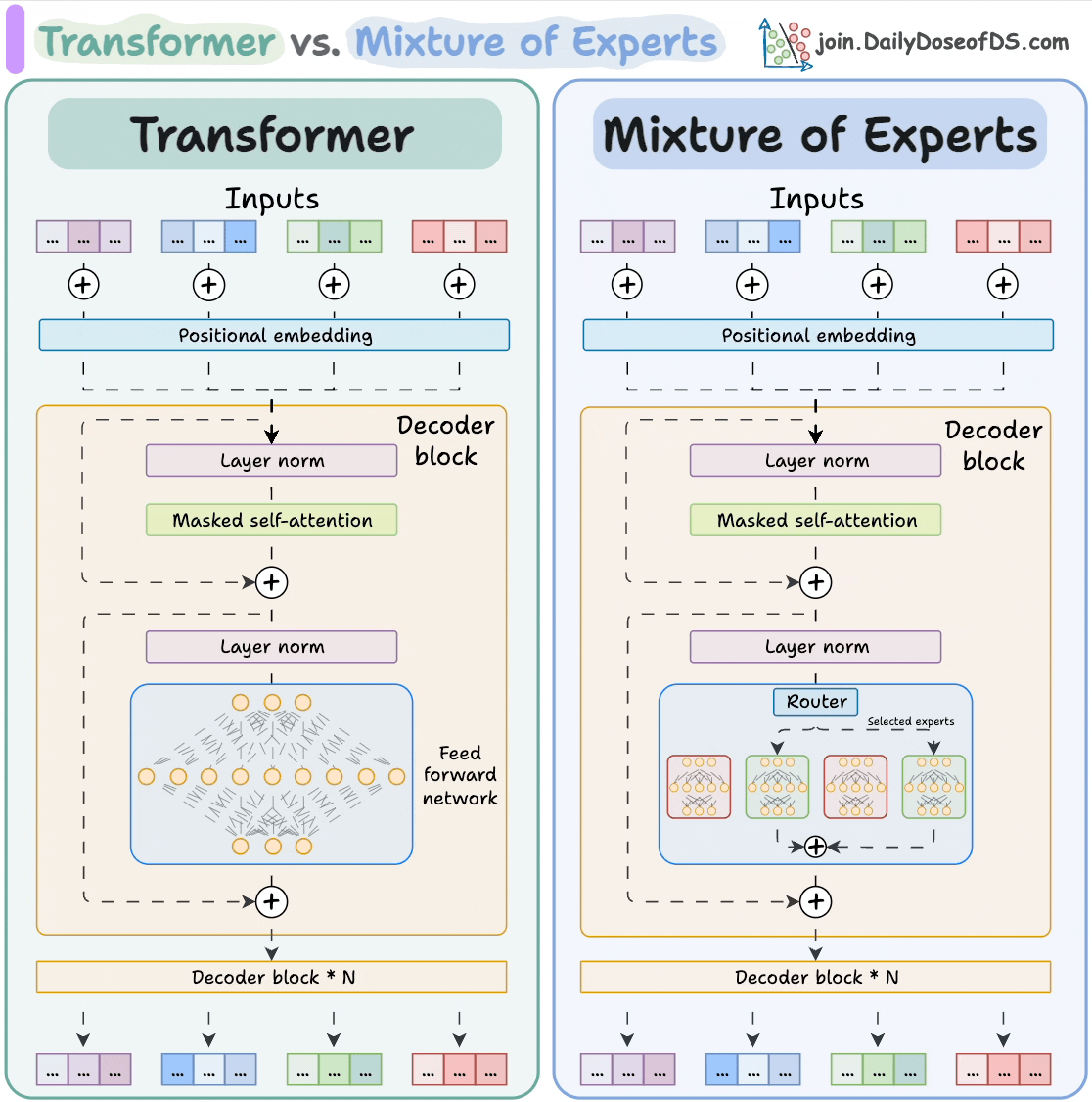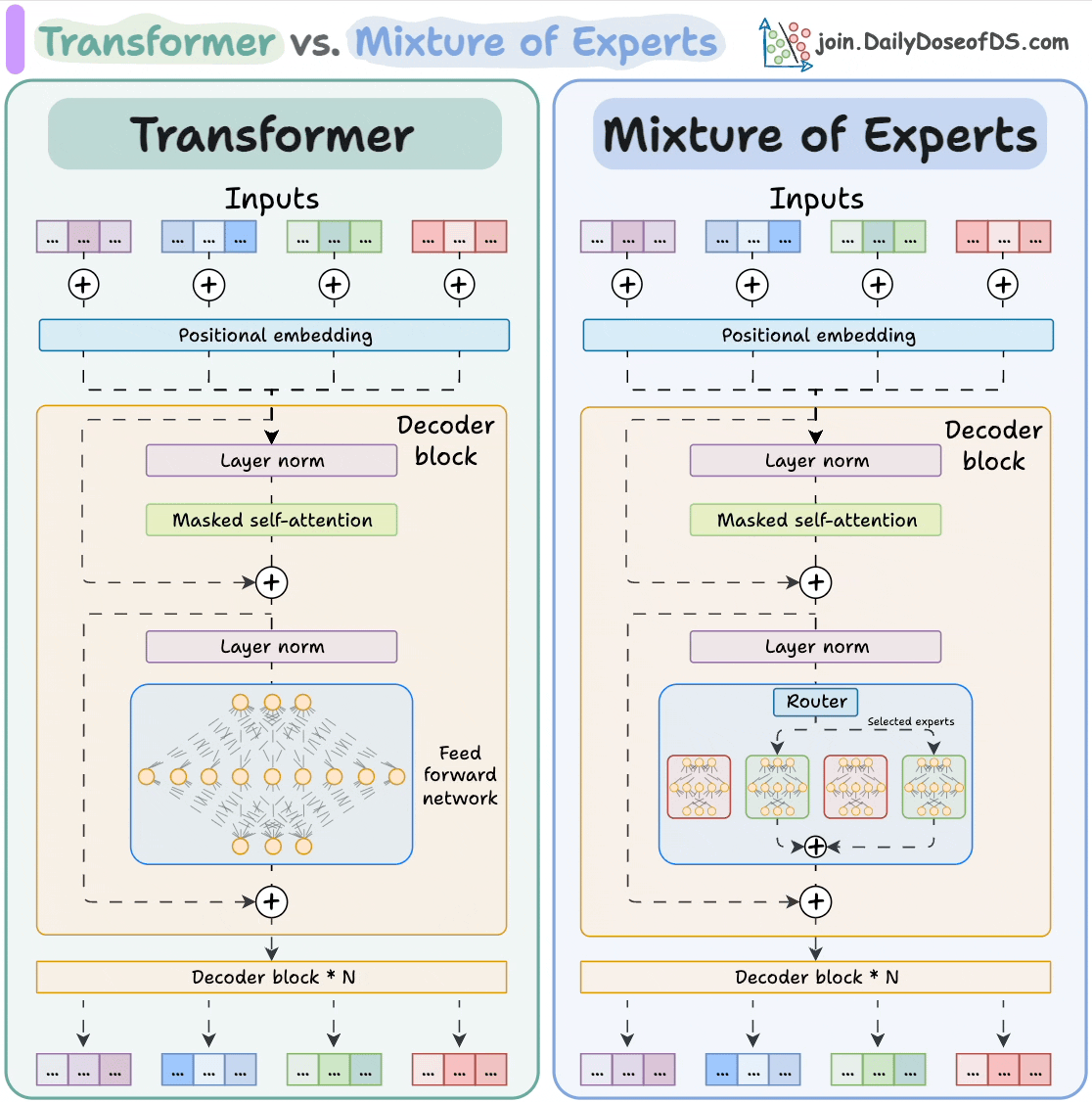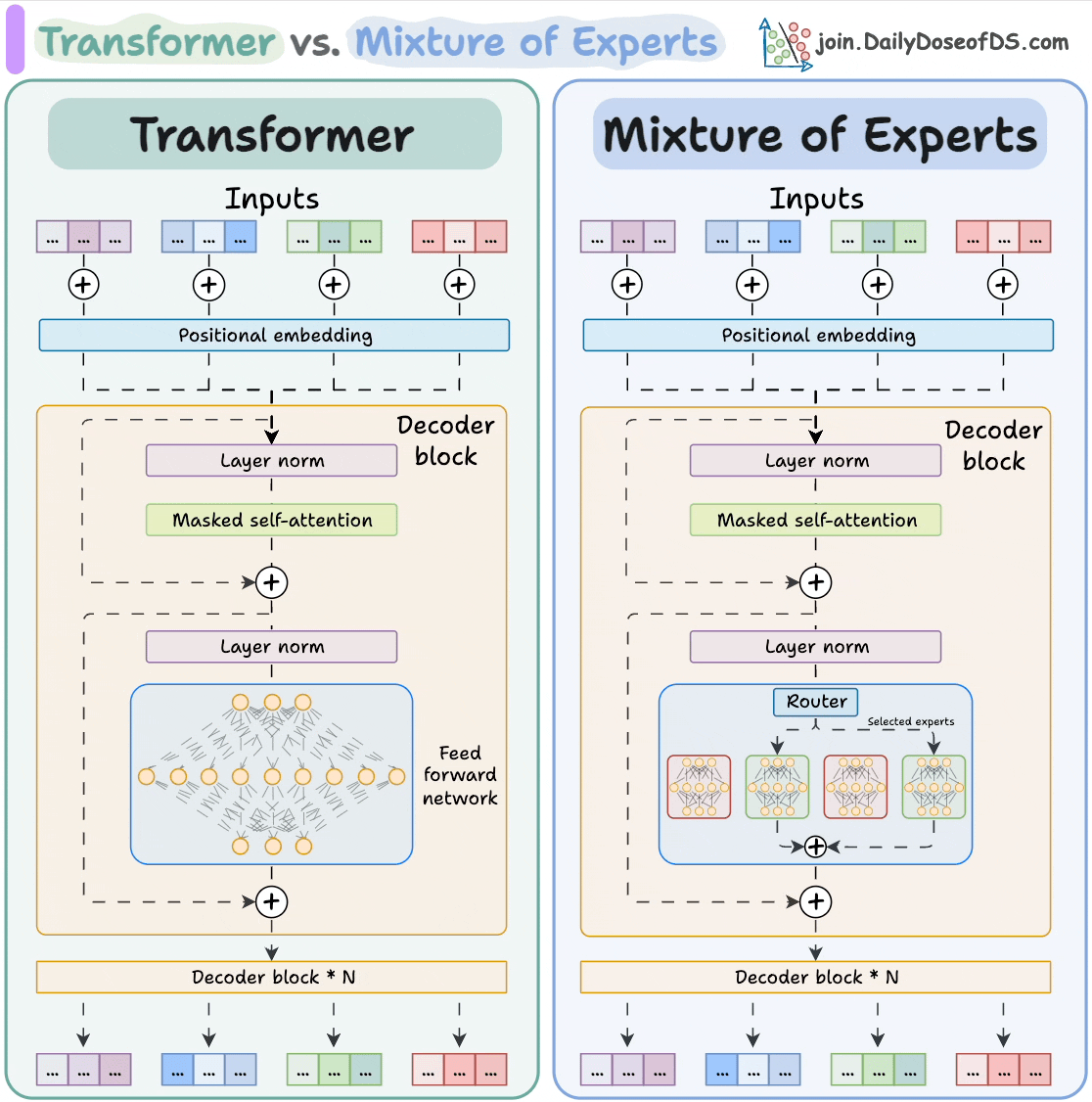
The subnetworks allow the model to scale to hundreds of billions of parameters while keeping inference efficient and cost-effective.
But how does that actually work under the hood?
We answer that by building an MoE-based Transformer from scratch.
It will be a miniature, interpretable version of LLaMA 4, using nothing but Python and PyTorch.
By doing so, we explain the architecture powering modern LLMs like LLaMA 4 and Mixtral, and give you hands-on insight into how experts, routers, and sparse activation work in practice.
We walk through every stage of implementation:
Character-level tokenization,
Multi-head self-attention with rotary positional embeddings (RoPE),
Sparse routing with multiple expert MLPs,
RMSNorm, residuals, and causal masking,
And finally, training and generation.
Along the way, we discuss why MoE matters, how it compares to standard feed-forward networks in Transformers, and what tradeoffs it introduces.
The goal is to help you understand both the theory and mechanics of MoE Transformers, not by reading another paper or GitHub README, but by building one line by line.
Read the detailed issue on Llama 4 implementation here →
Thanks for reading, and we’ll see you next week!