
Implementing LoRA from Scratch for Fine-tuning LLMs
Understanding the challenges of traditional fine-tuning and addressing them with LoRA.

Last week, we did a comprehensive deep dive on vector databases and, towards the end, understood their applicability in LLMs.
Today, we are continuing with LLMs and learning LoRA for fine-tuning LLMs: Implementing LoRA From Scratch for Fine-tuning LLMs.

How it works?
Why is it effective and cost savings over traditional fine-tuning?
How to implement it from scratch?
How to use Hugginface PEFT to fine-tune any model using LoRA.
Read it here: Implementing LoRA From Scratch for Fine-tuning LLMs.
Motivation for LoRA
In the pre-LLM era, whenever someone open-sourced any high-utility model for public use, in most cases, practitioners would fine-tune that model to their specific task.
Note: Of course, it’s not absolutely necessary for a model to be open-sourced for fine-tuning if the model inventors provide API-based fine-tuning instead and decide to keep the model closed.
Fine-tuning means adjusting the weights of a pre-trained model on a new dataset for better performance. This is neatly depicted in the animation below.
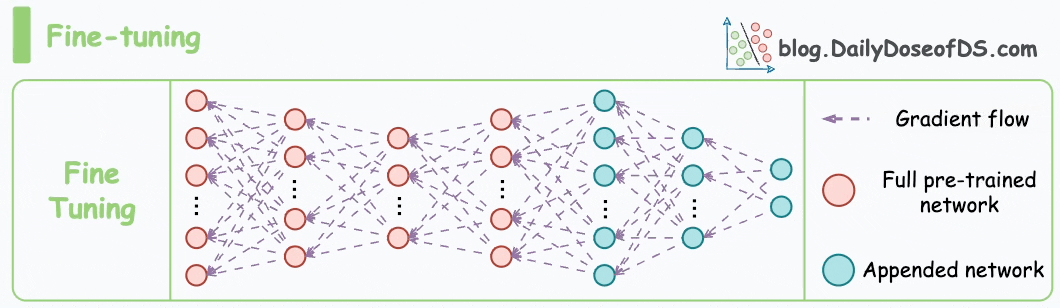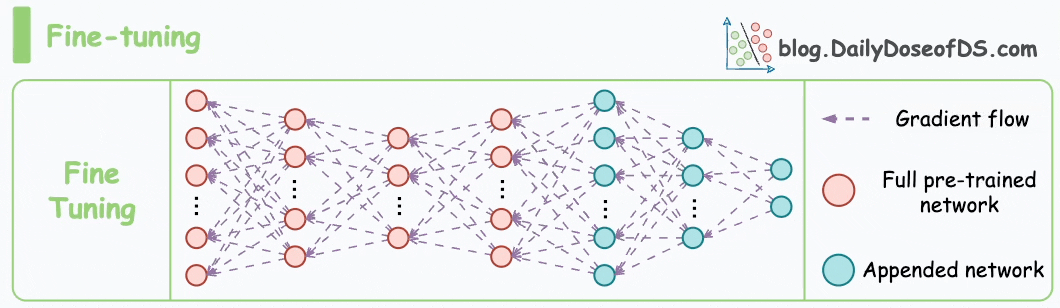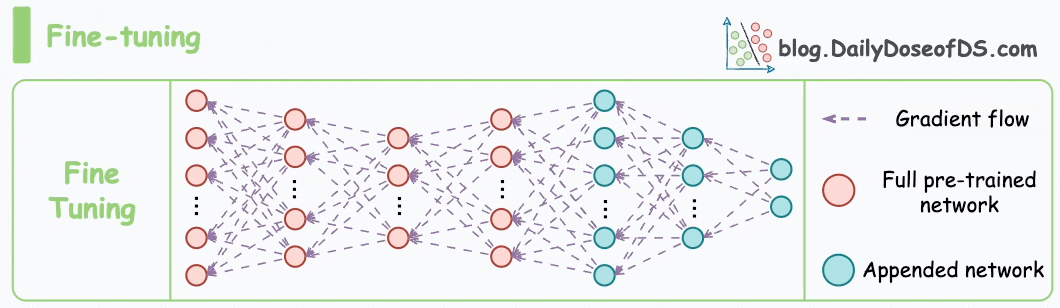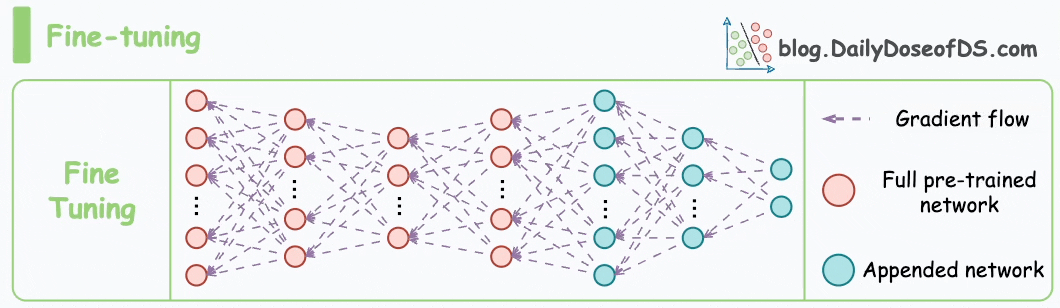
While this fine-tuning technique has been successfully used for a long time, problems arise when we use it on much larger models — LLMs, for instance, primarily because of their size.
Consider GPT-3, for instance. It has 175B parameters, which is 510 times bigger than even the larger version of BERT called BERT-Large:

I have successfully fine-tuned BERT-large in many of my projects on a single GPU cluster, like in this paper and this paper.
But it would have been impossible to do the same with GPT-3.
Bringing in GPT-4 makes it even more challenging:

Traditional fine-tuning is just not practically feasible here, and in fact, not everyone can afford to do it due to a lack of massive infrastructure.
In fact, it’s not just about the availability of high computing power.
Consider this...
OpenAI trained GPT-3 and GPT-4 models in-house on massive GPU clusters, so they have access to them for sure.
They also provide a fine-tuning API to customize these models on custom datasets.
Going by traditional fine-tuning, for every customer wanting to have a customized version of any of these models, OpenAI would have to dedicate an entire GPU server to load it and also ensure that they maintain sufficient computing capabilities for fine-tuning requests.
To put it into perspective, a GPT-3 model checkpoint is estimated to consume about 350GBs.
And this is the static memory of the model, which only includes model weights. It does not even consider the memory required during training, computing activations, running backpropagation, and more.

To make things worse, what we discussed above is just for one customer, but they already have thousands of customers who create a customized version of OpenAI models that are fine-tuned to their dataset.

From this discussion, it must be clear that such scenarios pose a significant challenge for traditional fine-tuning approaches.
The computational resources and time required to fine-tune these large models for individual customers would be immense.
Additionally, maintaining the infrastructure to support fine-tuning requests from potentially thousands of customers simultaneously would be a huge task for them.
LoRA (and QLoRA) are two superb techniques to address this practical limitation.
The core idea revolves around smartly training very few parameters in comparison to the base model:
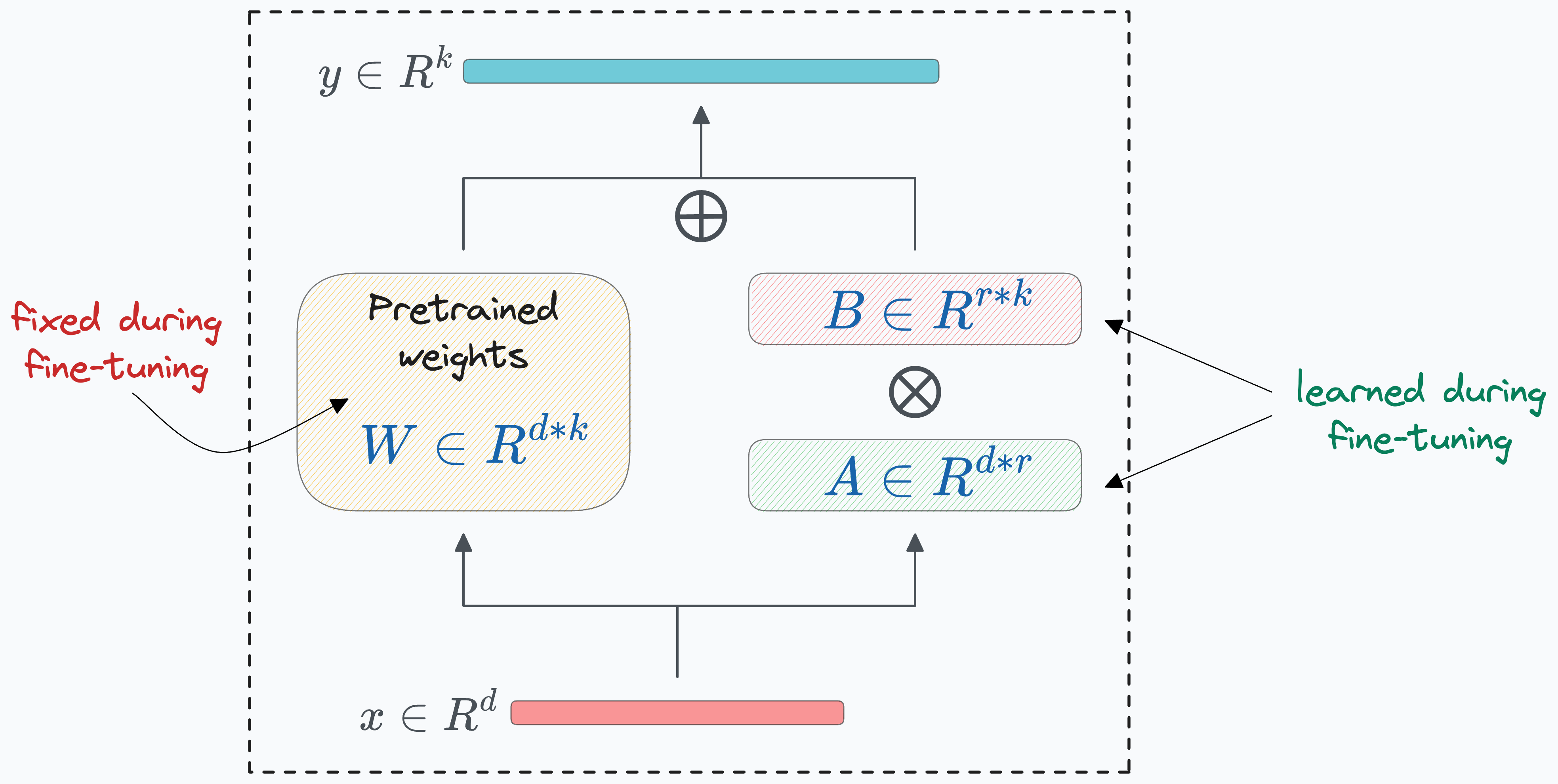
LoRA results show that one can achieve as good performance as full fine-tuning by learning even less than 1% of original parameters, which is excellent.
Read the article here for more details and how to implement it from scratch: Implementing LoRA From Scratch for Fine-tuning LLMs.
Thanks for reading!